上周有位同学复盘他在字节跳动的大模型面试经历,面试官提的几个问题让他印象非常深刻,也直接点出了很多人在设计 Multi-Agent 系统时的常见误区。
面试官问:“你简历写了做过 Multi-Agent 系统,讲一下你们的 Supervisor 是怎么分配任务的?”
他答:“就是 Supervisor 把任务拆分成几个子任务,分别交给不同的 Agent 去做。”
面试官点头,继续追:“那子 Agent 挂了怎么处理?比如网络超时,或者 LLM 调用失败?”
他答:“……会重试。”
面试官又追:“重试几次?等待多久?重试还失败了整个任务就失败了吗?”
他开始语塞。
面试官最后一个问题:“三个 Agent 同时在分析同一家公司,ResearchAgent 说这家公司营收增长,AnalysisAgent 说财务数据显示营收下滑,两个结论矛盾,WriterAgent 写报告的时候怎么合并?”
沉默。
面试官放下笔,说了一句话:“你说的 Multi-Agent,只是把几个 LLM 调用摆在一起,不是真正的 Multi-Agent 系统。”
这句话值得我们认真思考。今天,我们就来把 Multi-Agent 从设计模式到工程实现全部拆开讲清楚。
为什么需要 Multi-Agent——单 Agent 的根本局限
在深入 Multi-Agent 之前,我们必须诚实地承认:单 Agent 不是万能的。
以一个真实的银行对公客户智能咨询助手项目“拓业智询”为例。任务是这样的:客户经理输入一家中小企业的名称,系统需要生成一份完整的贷款风险评估报告,内容涵盖企业工商信息、财务状况、行业竞争格局、宏观市场趋势、历史贷款记录这五个维度。
最初尝试使用单 Agent 实现:一个 ReAct Agent,配上搜索工具、SQL 查询工具、财务数据接口,让它自己规划步骤,顺序执行。但这很快就暴露了三个根本性的问题:
第一个问题:上下文过长,精度下降。
顺序执行五个维度的分析,每个维度检索出来的内容都要塞进上下文。分析到第四个维度时,上下文长度常常超过 30000 token。在这种超长上下文中,LLM 开始出现“中间遗忘”现象:报告的前两个维度分析得很详细,后两个维度的分析却越来越粗糙,甚至出现前后矛盾的结论。这并非模型能力不足,而是长上下文本身的注意力分散问题,学术上称之为“lost in the middle”现象。
第二个问题:任务天然可以并行,但单 Agent 只能顺序执行。
企业财务分析、竞争对手分析、市场趋势分析,这三件事之间没有强依赖关系,完全可以同时进行。但单 Agent 的 ReAct 循环是顺序的:先做 A,再做 B,再做 C。五个维度串行下来,整个任务耗时约 45 秒,用户体验极差。
第三个问题:一个 Agent 很难在所有任务上都表现最优。
检索任务需要 Agent 懂得如何拆解查询词、构造召回策略;数据分析任务需要 Agent 理解财务指标、识别异常;报告生成任务则需要 Agent 具备良好的文字组织能力和结构化输出能力。这三种能力在 Prompt 层面的要求是不同的,甚至可能相互冲突——一个 Prompt 很难同时把三件事都优化到极致。
因此,Multi-Agent 的出发点变得非常清晰:分工、并行、独立上下文。
Supervisor 模式:Multi-Agent 的核心架构
Multi-Agent 有多种架构模式,但在生产环境中应用最广泛的是 Supervisor 模式。
其基本结构是:一个 Supervisor Agent 负责任务分解和全局协调,多个子 Agent 各司其职执行具体任务,最后由一个 WriterAgent(或类似的聚合器)汇总生成最终结果。
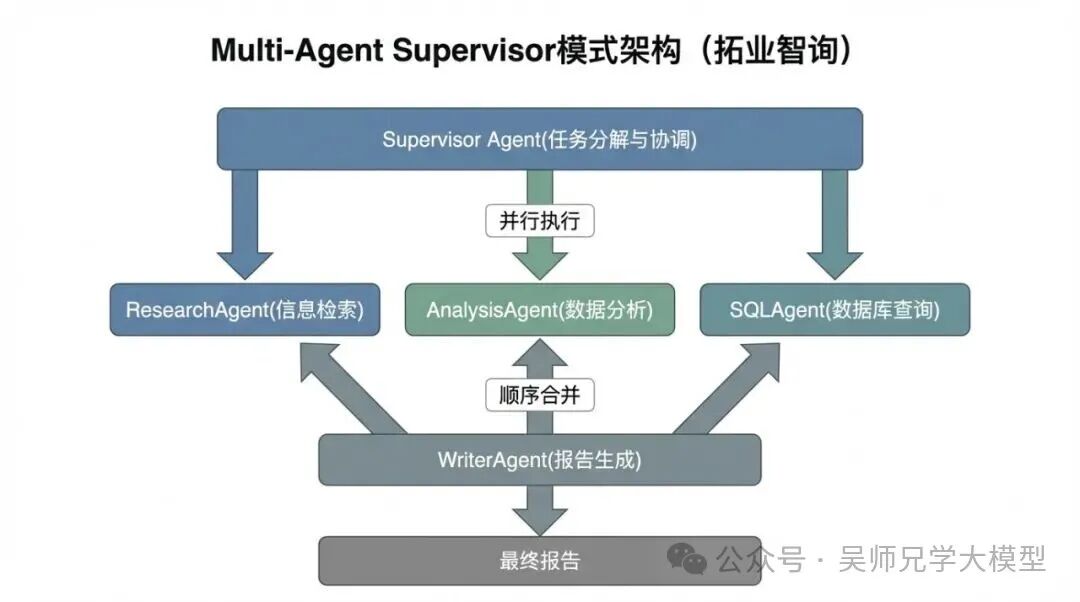
在“拓业智询”项目中,我们使用 LangGraph 实现了这个架构。首先,来看核心的状态定义和 Supervisor 节点:
from langgraph.graph import StateGraph, END
from typing import TypedDict, Literal
class SupervisorState(TypedDict):
task: str # 总任务
subtasks: list[str] # 分解的子任务
agent_results: dict # 各Agent的结果
final_report: str # 最终报告
def supervisor_node(state: SupervisorState) -> SupervisorState:
"""Supervisor:任务分解与分配"""
task = state["task"]
# LLM分解任务为子任务
subtasks = decompose_task(task)
# 返回决策:下一步执行哪个Agent
return {**state, "subtasks": subtasks}
def route_to_agents(state: SupervisorState) -> Literal["research", "analysis", "writer", "end"]:
"""根据状态决定下一个执行的Agent"""
if not state.get("agent_results", {}).get("research"):
return "research"
elif not state.get("agent_results", {}).get("analysis"):
return "analysis"
elif not state.get("final_report"):
return "writer"
else:
return "end"
这里有几个关键的设计决策:
- 为什么用 TypedDict 定义状态? LangGraph 的核心是围绕状态流转来设计工作流的。所有节点(Agent)共享同一个状态对象,每个节点读取自己需要的字段,更新自己负责的字段,然后把更新后的状态传递给下一个节点。使用 TypedDict 的好处在于类型检查(开发阶段就能发现字段拼写错误)和自文档化(State 的结构本身就是一份清晰的文档)。
route_to_agents 函数的作用是什么? 这是 LangGraph 中的“条件边”。工作流通过这个路由函数来决定下一步该走哪条分支。它的返回值对应该流向的下游节点名称。这样,Supervisor 就实现了动态调度:根据当前状态(哪些 Agent 已经完成了任务),决定下一步执行哪个 Agent。
完整的 Graph 构建如下:
def build_supervisor_graph():
graph = StateGraph(SupervisorState)
# 添加所有节点
graph.add_node("supervisor", supervisor_node)
graph.add_node("research", research_node)
graph.add_node("analysis", analysis_node)
graph.add_node("writer", writer_node)
# 设置入口
graph.set_entry_point("supervisor")
# Supervisor根据状态路由到子Agent
graph.add_conditional_edges(
"supervisor",
route_to_agents,
{
"research": "research",
"analysis": "analysis",
"writer": "writer",
"end": END
}
)
# 子Agent执行完毕后回到Supervisor进行下一步决策
graph.add_edge("research", "supervisor")
graph.add_edge("analysis", "supervisor")
graph.add_edge("writer", "supervisor")
return graph.compile()
请注意这里的结构:每个子 Agent 执行完毕后,都会返回 Supervisor,由 Supervisor 再次判断下一步动作。 这正是 Supervisor 模式的核心——决策权始终在 Supervisor 手中,子 Agent 只负责执行,不负责决定下一步做什么。
并行执行:让 ResearchAgent 同时检索多个维度
既然知道了顺序执行的弊端,接下来看并行执行的实现。
在“拓业智询”的场景中,对一家企业的贷款风险评估,ResearchAgent 需要同时检索三个维度:企业工商信息、行业竞争格局、宏观政策环境。这三个检索任务之间没有依赖,天然适合并行。
import asyncio
async def parallel_research(queries: list[str]) -> list[dict]:
"""并行执行多个Research子任务"""
tasks = [research_agent.ainvoke({"query": q}) for q in queries]
results = await asyncio.gather(*tasks, return_exceptions=True)
# 处理失败的子任务
final_results = []
for i, result in enumerate(results):
if isinstance(result, Exception):
print(f"子任务{i}失败: {result},使用降级方案")
final_results.append({"query": queries[i], "result": "检索失败,跳过此部分"})
else:
final_results.append(result)
return final_results
这里有两点值得单独说明:
- *`asyncio.gather(tasks, return_exceptions=True)
的用法。** 如果不加return_exceptions=True,任何一个子任务抛出异常,gather会立刻终止所有子任务并把异常向上抛出。这在生产环境中是不可接受的——一个子任务的失败不应导致所有任务失败。加上该参数后,异常会被当作正常返回值放进results列表,我们可以在后续逐一检查每个结果是否为Exception` 实例,并分别处理。
ainvoke 而不是 invoke。 LangGraph 和 LangChain 的 Agent 都提供了异步调用接口 ainvoke。只有使用异步接口,asyncio.gather 才能真正并发地执行多个任务。如果使用同步的 invoke,即使放入 gather,实际上仍是顺序执行。
实测数据显示,在该项目中,三个检索维度的任务,顺序执行约需 24 秒,并行执行约需 9 秒,提速约 2.7 倍(并非 3 倍,因为有协调开销和资源竞争)。
解决了速度问题,接下来是另一个关键:子 Agent 失败时,整个流程该如何处理?
子 Agent 错误处理:重试 + 降级,缺一不可
这是面试官追问的第二个核心问题。很多人的回答停留在“失败了就重试”,但重试策略本身也需要精心设计。
我们的错误处理策略分为两层:重试和降级。
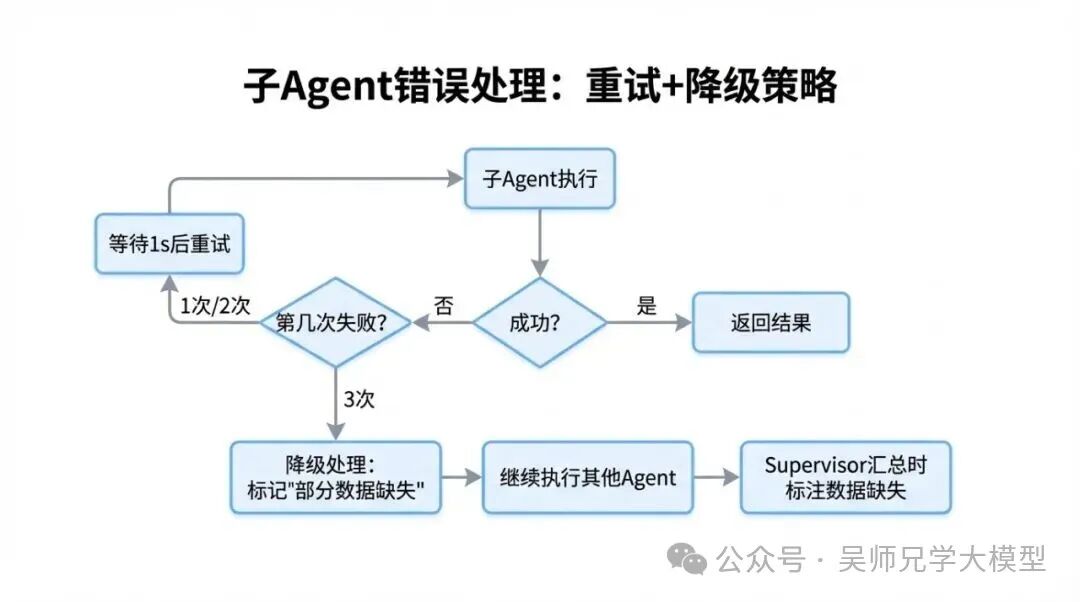
完整实现如下:
import asyncio
from typing import Optional
async def execute_agent_with_retry(
agent,
input_data: dict,
agent_name: str,
max_retries: int = 2,
retry_delay: float = 1.0
) -> dict:
"""
带重试和降级的Agent执行器
- max_retries: 最多重试次数(不含第一次执行)
- retry_delay: 每次重试前等待的秒数
"""
last_exception: Optional[Exception] = None
for attempt in range(max_retries + 1): # 0, 1, 2 共三次机会
try:
result = await agent.ainvoke(input_data)
return {"status": "success", "data": result, "agent": agent_name}
except Exception as e:
last_exception = e
if attempt < max_retries:
print(f"[{agent_name}] 第{attempt + 1}次失败: {e},{retry_delay}秒后重试...")
await asyncio.sleep(retry_delay)
else:
print(f"[{agent_name}] 已重试{max_retries}次,全部失败,触发降级")
# 降级处理:标记数据缺失,不抛出异常,允许流程继续
return {
"status": "degraded",
"data": None,
"agent": agent_name,
"error": str(last_exception),
"message": f"{agent_name}数据获取失败,该部分分析结果缺失"
}
在 Supervisor 层,需要能够感知哪些 Agent 发生了降级:
def supervisor_node(state: SupervisorState) -> SupervisorState:
agent_results = state.get("agent_results", {})
# 检查是否有降级的Agent
degraded_agents = [
name for name, result in agent_results.items()
if isinstance(result, dict) and result.get("status") == "degraded"
]
if degraded_agents:
print(f"警告:以下Agent数据缺失,将继续生成报告但需标注: {degraded_agents}")
# 在state中记录缺失信息,WriterAgent生成报告时需要标注
return {**state, "data_gaps": degraded_agents}
return state
这里最重要的设计原则是:一个子 Agent 的失败,绝不能阻塞整个任务。在银行的业务场景中,宁可生成一份带有“部分数据缺失”标注的报告,也不能让整个系统因为某一个数据源超时而完全报错。客户经理拿到有标注的报告,至少还能参考其他维度做出判断;若只拿到一个系统错误,则什么都做不了。
这也是降级策略的业务逻辑依据——降级不是技术妥协,而是对用户体验的必要保护。
错误处理有了兜底方案,还有一个更棘手的问题:多个 Agent 并行分析得出了相互矛盾的结论,WriterAgent 该如何处理?
结果合并:WriterAgent 怎么处理矛盾的结论
这是面试官的最后一个问题,也是最容易被忽视的工程细节。
三个 Agent 并行分析同一家企业,完全可能得出矛盾的结论。在“拓业智询”中确实出现过:ResearchAgent 通过新闻检索发现某企业最近签了几个大合同,判断营收向好;AnalysisAgent 通过分析企业提交的财务报表,发现应收账款周转率下降,实际现金流紧张。两个结论方向相反。
WriterAgent 的设计必须能处理这类矛盾。核心代码如下:
def writer_node(state: SupervisorState) -> SupervisorState:
"""WriterAgent:合并各Agent结果生成最终报告"""
research_result = state["agent_results"].get("research", {})
analysis_result = state["agent_results"].get("analysis", {})
data_gaps = state.get("data_gaps", [])
# 构建降级说明
gap_notice = ""
if data_gaps:
gap_notice = f"\n\n注意:以下分析模块数据缺失,相关结论请谨慎参考:{', '.join(data_gaps)}"
merge_prompt = f"""
你是报告生成专家。请基于以下各分析模块的结果,生成一份结构化的综合报告:
## 研究发现
{research_result.get('data', '数据缺失')}
## 数据分析
{analysis_result.get('data', '数据缺失')}
{gap_notice}
要求:
1. 合并重复内容,保留关键信息
2. 如有数据矛盾,优先采用数据分析模块的结论(财务数据比新闻检索更客观)
3. 对矛盾点必须明确标注:“研究发现与数据分析存在分歧,建议进一步核实”
4. 生成执行摘要(3-5条核心结论)
5. 如有数据缺失,在对应章节标注“[数据缺失,仅供参考]”
"""
final_report = llm.invoke(merge_prompt).content
return {**state, "final_report": final_report}
这里有一个关键的业务规则:数据分析模块的结论优先于检索模块。这是我们基于具体业务场景制定的优先级——企业提交的财务报表(数据分析的来源)比公开新闻(检索的来源)更具法律效力和客观性,在贷款风险评估场景下应赋予更高权重。
当然,不同业务场景下的优先级规则可能不同。关键在于:优先级规则必须显式地写入 WriterAgent 的 Prompt 中,而不能让 LLM 自行决定。让 LLM 自行决定意味着每次合并的结果可能不一致,这在金融等严谨场景中是不可接受的。
架构细节讲完了,让我们用真实数据来看一下单 Agent 和 Multi-Agent 的差距究竟有多大。
单 Agent vs Multi-Agent:拓业智询的真实数据
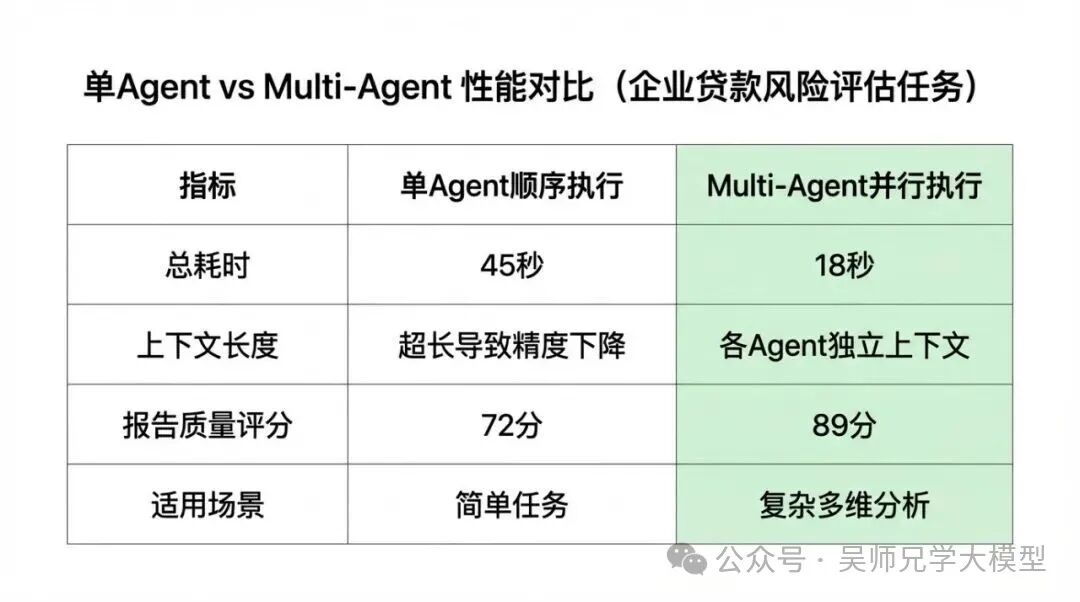
在“拓业智询”项目中,我们对同一批 50 个企业评估任务做了 A/B 对比测试,结果如下:
- 总耗时:单 Agent 顺序执行平均 45 秒,Multi-Agent 并行执行平均 18 秒,提速 60%。
- 上下文长度:单 Agent 到后期分析维度时上下文超过 32000 token,Multi-Agent 各子 Agent 保持独立上下文,最长不超过 8000 token。
- 报告质量评分:邀请 5 名有经验的客户经理对报告进行盲评(1-100 分),单 Agent 平均 72 分,Multi-Agent 平均 89 分,提升 23.6%。
- 适用场景:单 Agent 在简单的单维度查询任务(如“查一下这家公司的注册资本”)上反而更快,Multi-Agent 的优势在多维度复杂分析任务中才能充分体现。
但并行不是越多越好。 这一点值得单独强调。
实验中,我们尝试了 2、3、4、5、6 个子 Agent 并行的方案:
- 2-3 个子 Agent 并行:性能提升最明显,协调开销小。
- 4-5 个子 Agent 并行:性能提升趋于平缓,开始出现 LLM API 的并发限速问题。
- 6 个子 Agent 并行:总耗时反而比 3 个并行的方案更长,原因是 API 限速导致多个请求排队等待。
另外,任务有强顺序依赖时,不能并行。在“拓业智询”中,WriterAgent 必须在所有分析 Agent 完成之后才能运行,因为它需要所有分析结果作为输入——这是典型的顺序依赖,强行并行没有意义。
实战建议:2-3 个子 Agent 并行是大多数场景下的最佳平衡点,既能获得显著的提速效果,又不会因协调开销和 API 限速把收益全部抵消。
面试怎么答 Multi-Agent 架构?
这是本文最实用的部分。当面试官问“你们的 Multi-Agent 架构是怎么设计的”时,不要一上来就讲技术细节。应该先给出一个整体框架,再按层次展开:
第一层:为什么用 Multi-Agent(动机)
“我们做的是银行对公客户风险评估,单 Agent 顺序分析五个维度,上下文过长导致精度下降,且45秒的响应时间用户体验很差。Multi-Agent 让各维度分析并行执行,各 Agent 保持独立上下文,总耗时降到 18 秒。”
第二层:架构是什么样的(设计)
“我们用 LangGraph 实现 Supervisor 模式。Supervisor 负责任务分解和状态管理,三个子 Agent(ResearchAgent、AnalysisAgent、SQLAgent)并行执行,最后由 WriterAgent 汇总生成报告。每个子 Agent 执行完回到 Supervisor,由 Supervisor 决定下一步——决策权始终在 Supervisor 手里。”
第三层:错误处理怎么做的(健壮性)
“每个子 Agent 有独立的重试机制:失败后最多重试 2 次,每次等待 1 秒。重试全部失败则触发降级——标记该模块数据缺失,继续执行其他 Agent。WriterAgent 生成报告时会在缺失部分标注说明。核心原则是一个子 Agent 的失败不能阻塞整个任务。”
第四层:结果合并怎么处理矛盾(细节)
“如果检索结果和数据分析结论矛盾,我们规定数据分析模块优先,因为财务报表比公开新闻更具法律效力。矛盾点会在报告中明确标注,建议人工核实。这个优先级规则显式地写在 WriterAgent 的 Prompt 里,不让 LLM 自行决定,以保证结果的一致性。”
第五层:有什么局限(自我批判,加分项)
“并行不是越多越好。我们测试发现超过 5 个子 Agent 并行时,因 API 限速,总耗时反而比 3 个并行更长。另外,强顺序依赖的任务不能并行,WriterAgent 必须等所有分析完成才能运行。实战下来,2-3 个子 Agent 并行是最佳平衡点。”
能清晰地说到第五层,这道面试题基本就稳了。大多数候选人只能说到第一或第二层,能深入阐述错误处理和结果合并细节的,面试官会认为你真正在生产环境里跑过这个系统,而不只是看过几篇论文。
总结
Multi-Agent 远非简单地把几个 LLM 调用摆在一起。它需要系统性地解决一系列工程问题:任务如何分解、子任务如何调度、子 Agent 失败如何处理、并行结果如何合并、矛盾结论如何裁定。
Supervisor 模式是生产环境中最主流的 Multi-Agent 架构:一个中心化的 Supervisor 掌控全局决策,子 Agent 只负责执行,实现了决策权与执行权的分离。
错误处理的核心是“不阻塞”原则:重试 + 降级,确保一个子 Agent 的失败止步于自身,不会传染给整个系统。
结果合并的核心是“规则显式化”:数据矛盾时谁优先、矛盾如何标注、缺失如何处理,这些规则必须明确写入 Prompt,不能让 LLM 自由发挥。
并行是有上限的:2-3 个子 Agent 并行是大多数场景下的最优解,更多的并行带来的往往是协调开销和 API 限速,而非更快的速度。
希望这篇从实战出发的剖析,能帮助你更好地理解和设计真正的 Multi-Agent 系统。如果你想了解更多关于系统架构或 大模型面试 的实战经验,欢迎在 云栈社区 交流探讨。
 发表于 2026-3-29 04:20:34
|
查看: 99|
回复: 0
发表于 2026-3-29 04:20:34
|
查看: 99|
回复: 0
