高并发是分布式系统架构的核心挑战之一。本文将深入剖析Kafka实现高并发的核心技术,并解析其如何支撑每秒十万乃至百万级的消息吞吐。
理解高并发
在分布式系统中,高并发通常指系统能够同时处理大量用户请求或数据操作的能力。它并非单纯追求单线程的极致速度,而是强调在单位时间内系统能够并行处理的请求数量。
衡量系统并发能力的关键指标包括:
| 指标 |
含义 |
| QPS (Query Per Second) |
每秒查询次数 |
| TPS (Transaction Per Second) |
每秒事务处理量 |
| 吞吐量 (Throughput) |
系统每秒能处理的数据总量(如 MB/s) |
| 延迟 (Latency) |
请求从发出到收到响应所需的时间 |
Kafka的高并发标准
对于Kafka而言,其高并发性能通常体现在消息写入吞吐量上:
- 单机场景:单Broker写入能力超过10万条/秒,即可视为高并发场景。
- 集群场景:整体集群吞吐量达到百万条/秒级别,是典型的大型互联网高并发应用。
不同规模的Kafka集群,其性能表现差异显著:
| 集群规模 |
典型场景 |
并发性能参考 |
| 单机 (1 Broker) |
本地开发/测试 |
5 ~ 10万条/秒 |
| 小集群 (3 Broker) |
中小型业务系统 |
30 ~ 50万条/秒 |
| 中型集群 (6~10 Broker) |
电商、日志采集 |
100 ~ 300万条/秒 |
| 大型集群 (20+ Broker) |
大型互联网平台 |
500万 ~ 千万级 TPS |
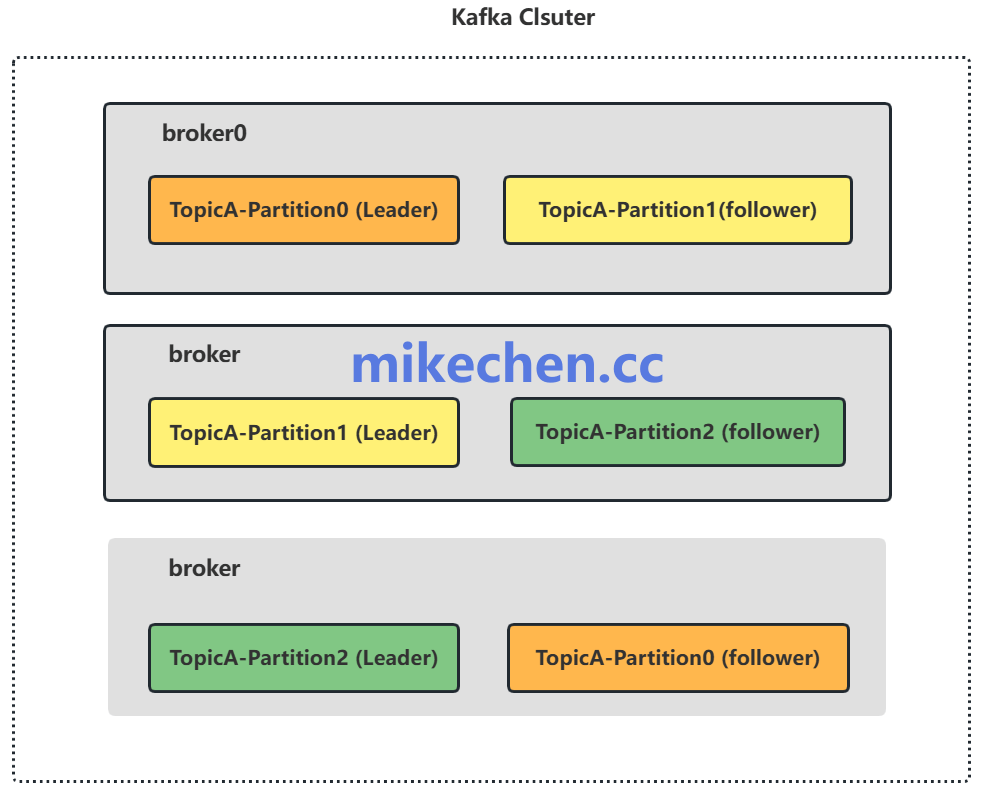
实现高并发的四大核心技术
要实现写入超过10万条/秒的高并发目标,Kafka主要依赖以下四项核心技术。
1. Broker层深度优化
- 增加分区数:更多的分区(Partitions)意味着生产者可以有更多的并行写入线程,这是提升并发度的基础。
- 磁盘顺序写:Kafka摒弃随机写,采用顺序追加写入日志文件的方式,极大地提升了磁盘IO效率。
- Batch批量写入:通过合理配置
batch.size(批次大小)和linger.ms(等待时间)参数,将多个小消息合并成一个批次进行发送,减少网络IO次数。
- I/O线程优化:调整
num.io.threads和num.network.threads参数,提升网络处理和磁盘操作的并行度,这是数据库与中间件性能调优的常见手段。
2. 水平扩展与存储优化
3. 高效的网络与批量传输
生产者客户端采用异步批量发送模式是提升吞吐的关键。以下是一组推荐的高性能配置示例:
# 生产者配置
acks=1 # 在leader写入后即返回确认,兼顾性能与可靠性
linger.ms=10 # 等待最多10毫秒以聚合更多消息到批次
batch.size=32768 # 每个批次最大32KB
compression.type=lz4 # 使用LZ4压缩,减少网络传输数据量
4. 零拷贝技术
零拷贝(Zero-copy)是Kafka实现高吞吐的底层“王牌技术”。它允许数据直接从磁盘通过sendfile系统调用发送到网卡缓冲区, bypass了内核态与用户态之间的多次数据拷贝,大幅降低了CPU开销和上下文切换,显著提升了数据传输效率。
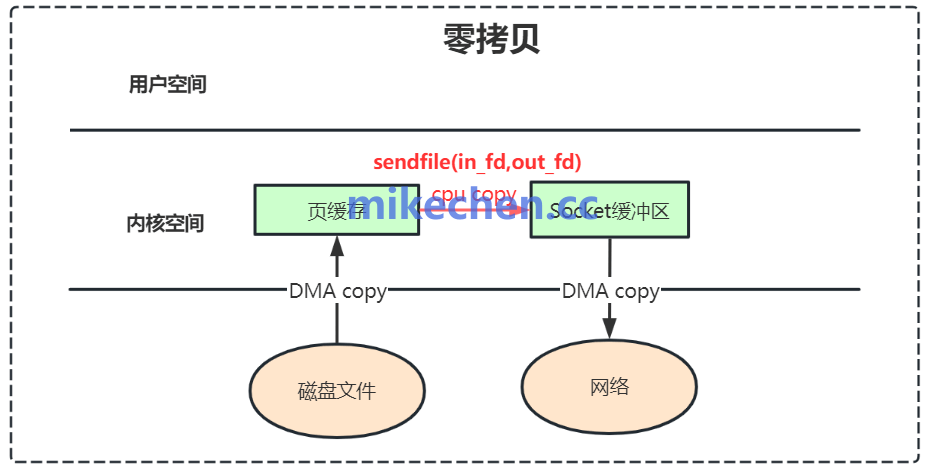 确保运行Kafka的操作系统支持并启用此技术,对于达到极限吞吐至关重要。
确保运行Kafka的操作系统支持并启用此技术,对于达到极限吞吐至关重要。
|  发表于 2025-12-10 05:24:51
|
查看: 208|
回复: 0
发表于 2025-12-10 05:24:51
|
查看: 208|
回复: 0
