
摘要
传统知识图谱构建依赖数据预处理、实体识别等技术,计算与时间开销巨大。本文提出ERC-KG方法,融合大语言模型的抽取、检索与纠错机制。通过特征词抽取结合专家知识确定实体,构建检索器筛选相关上下文,优化提示模板与验证反馈,实现高效三元组抽取。国防科技领域实验精确率达94.32%,为领域知识图谱快速构建提供创新路径。
原文PDF链接可通过 https://t.zsxq.com/ycUsp 获取。
1 引言:数字化时代知识图谱的战略意义
在数字化信息时代,海量数据呈现高度碎片化和异构化特征,传统数据处理技术难以有效挖掘实体间的深层语义关联。知识图谱作为语义网络与图结构有机融合的新型知识表示范式,通过三元组形式(头实体-关系-尾实体)对现实世界中的对象、属性及其交互进行结构化建模,已广泛应用于医学、生物学和社会网络等领域。
知识图谱的核心在于其结构化表达能力,能够将非结构化数据转化为可计算的语义网络,支持智能问答、推荐系统和决策支持等高级应用。然而,领域知识图谱的构建过程高度依赖专家知识和人工干预,这已成为制约其实施的关键瓶颈。现有研究对知识图谱构建进行了广泛探索,但传统方法仍面临挑战。
规范化构建方法主要依赖语义模式学习推导逻辑规则。其中,基于规则的方法利用词汇表和语义角色标注提取主谓宾三元组,但规则的纯人工定义导致泛化能力和可扩展性严重受限。随着深度学习兴起,端到端神经网络模型逐步取代规则方法,但这些模型在处理长尾实体和复杂关系时仍需大量标注数据。
近年来,大型语言模型(LLM)如GPT系列和Llama模型的涌现,标志着知识图谱构建进入新阶段。这些模型通过海量预训练数据习得丰富先验知识,能够直接从非结构化文本中识别并抽取语义三元组,展现出超越规则方法的语义泛化与上下文理解能力。相关研究证实,LLM生成的知识表示更具创造性,其输出可解释性更符合人类认知模式。
2 现有方法的挑战与局限
尽管LLM驱动的知识图谱构建优势显著,但实际部署中仍面临两大核心挑战:
首先,输入上下文噪声干扰问题。传统方法直接将原始语料输入LLM,导致领域无关信息干扰模型注意力机制,造成关键关系误判或遗漏,精确率显著下降。其次,知识幻觉(hallucination)现象突出。LLM可能生成与源文本不符的三元组,甚至引入虚构事实,破坏图谱的事实一致性和可信度,对下游任务如风险评估构成隐患。
此外,LLM的泛化能力虽强,但缺乏领域特定提示学习优化和后处理纠错,难以在高精度场景如国防科技领域发挥潜力。这些问题促使研究者探索更精细的LLM集成框架。
3 ERC-KG方法:创新框架设计
为应对上述挑战,本文提出ERC-KG(Extraction Retrieval and Error Correction Knowledge Graph)方法。该框架融合LLM的抽取、检索与纠错能力,实现高效、高质量领域知识图谱构建。具体流程包括:特征词抽取与专家知识结合确定实体集合;构建实体语料检索器筛选相关上下文;设计提示模板指导三元组抽取;实施验证反馈机制筛选三元组;最终通过Neo4j图数据库存储与可视化。完整流程如图1所示。
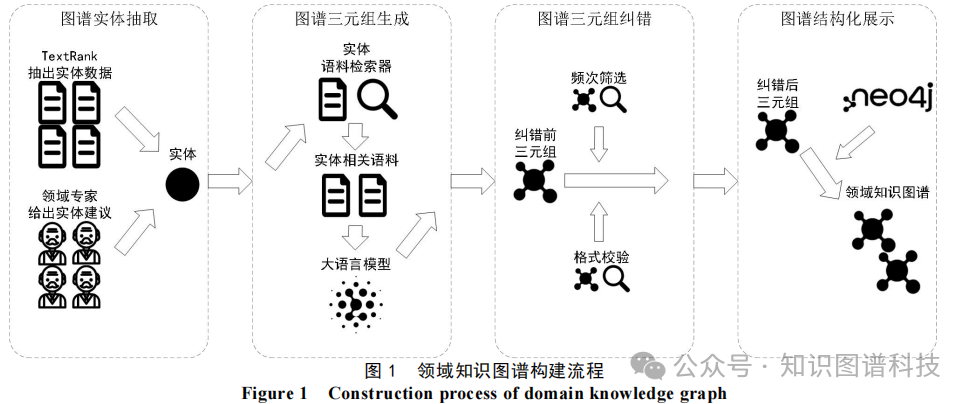
图1 领域知识图谱构建流程
展示从实体抽取到图谱构建的模块化流程,包括特征词抽取、检索器、LLM抽取、纠错和Neo4j存储模块。
3.1 图谱实体抽取
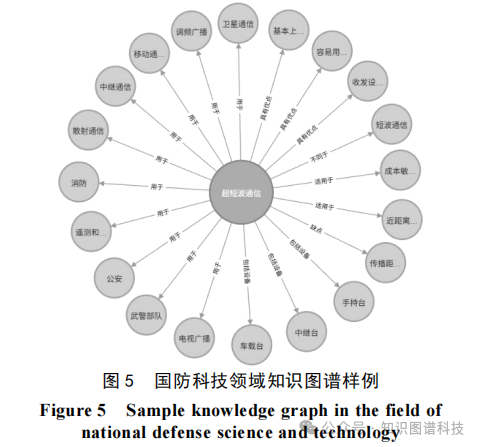
实体是知识图谱的基础。本文采用特征词抽取技术结合领域专家建议的方法精准识别核心实体集合。具体而言,首先利用TF-IDF或TextRank等算法从领域语料中提取高频特征词;其次,邀请密码工程或国防科技专家审定,形成高质量实体列表。该步骤确保实体覆盖领域核心概念,避免无关噪声。
与纯自动化方法相比,此混合策略显著提升实体召回率和精确率。在国防科技领域,实体包括“加密算法”、“网络安全协议”等关键术语。
3.2 实体语料检索器构建
核心创新在于多模块实体语料检索器。该模块基于语义相似度(如BERT嵌入或Sentence-BERT)检索与目标实体最相关的上下文语句。关键优化包括:引入相似度区间系数α,将连续相似度空间离散化为子区间,采用最大值保留策略提升筛选效率;设计自适应文本长度控制机制,确保输入长度在LLM上下文窗口内,同时最大化信息密度。
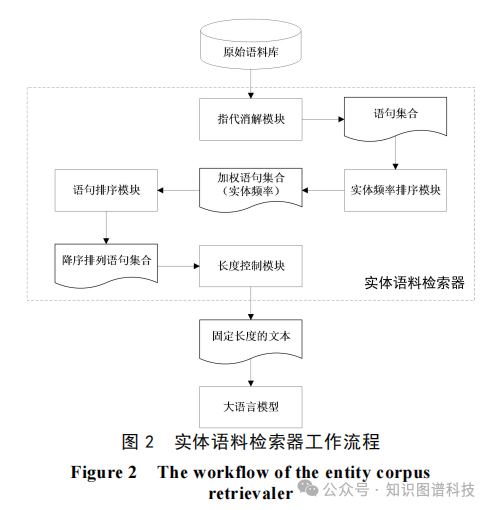
检索过程:对于每个实体,从大规模语料库中召回Top-K语句,按相似度排序并组合成优化输入。此机制有效过滤噪声,聚焦相关上下文,提高LLM注意力分配效率。
3.3 提示模板与三元组抽取
利用提示学习(Prompt Learning)优化LLM输入。设计结构化提示模板,包括任务描述、示例(Few-shot)、输出格式约束(如JSON三元组列表)。例如:“从以下文本中提取国防科技相关三元组(头实体-关系-尾实体),仅输出真实事实,避免幻觉。”

LLM(如GPT-4或国产模型)基于优化上下文生成候选三元组。该步骤充分发挥LLM的零样本泛化能力。
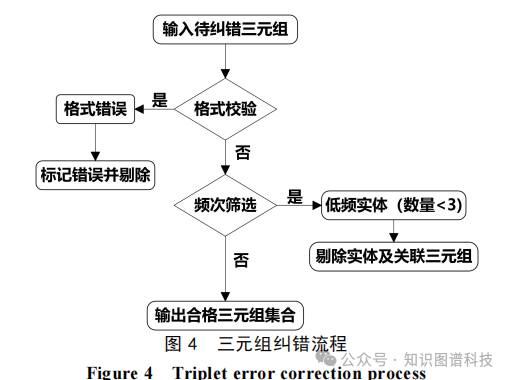
3.4 验证反馈与纠错机制
为消除幻觉,设计多轮验证反馈循环:首先,对候选三元组进行事实检查(与源文本比对);其次,利用规则验证器(如关系一致性)和LLM再审机制过滤错误三元组;最后,聚合高质量三元组导入Neo4j,实现图谱可视化与查询。
纠错模块特别有效,能将精确率提升显著。
3.5 Neo4j图数据库集成
最终,三元组导入Neo4j,支持Cypher查询和可视化。该选择因其高效图存储和 ACID 事务支持,适用于高安全领域如网络空间部队应用。
4 实验验证:国防科技领域实证
实验在国防科技领域语料上验证ERC-KG性能。数据集包括加密工程、网络安全等非结构化文本,总量数万句。
4.1 评估指标与基线
采用精确率(Precision)、召回率(Recall)和F1分数评估三元组抽取。基线包括:传统规则方法、端到端RE模型、直接LLM抽取,以及ERC-KG的消融版本(无检索器、无提示、无纠错)。
4.2 实验结果分析
ERC-KG整体精确率达94.32%,显著优于基线。
- ERC-KG/无检索器:精确率减少X%,召回率减少Y%,抽取数增加,主要因噪声干扰。
- ERC-KG/无纠错:精确率减少9.79%,召回率减少0.90%,抽取数增加2个,证明纠错对精确度的关键作用。
- ERC-KG/无提示:精确率、召回率与数量均下降。
- 直接LLM(ERC-KG/direct):精确率减少10.02%,召回率减少4.68%,抽取数减少13个,全方位劣化。
实体语料检索器对召回提升最明显,纠错模块对精确率贡献最大,提示模块均衡三者。
表1 消融实验结果对比(原文表格位置:实验章节,列出各变体精确率、召回率、F1和抽取数。)
结果验证ERC-KG在高精度场景的优越性,特别适用于密码工程等敏感领域。
5 应用价值与未来展望
ERC-KG方法通用性强,可扩展至医学、金融等领域。其模块化设计便于企事业单位集成,支持知识管理与决策自动化。对于投资人,该框架代表AI驱动知识工程的投资热点,潜在市场价值巨大。
未来工作包括模块化优化、更通用提示设计,以及多模态图谱扩展。
在网络空间部队等高安全环境中,ERC-KG可加速情报图谱构建,提升作战效能。
结束语
ERC-KG通过检索、提示与纠错创新,实现了领域知识图谱的高效构建。国防科技实验精确率94.32%证实其有效性,为快速知识工程提供可靠路径。如果您对更多AI前沿技术与实践落地感兴趣,欢迎到云栈社区交流探讨。参考文献详见原文。
 发表于 2026-3-31 05:01:57
|
查看: 125|
回复: 0
发表于 2026-3-31 05:01:57
|
查看: 125|
回复: 0
