在人工智能飞速发展的当下,代码智能已成为大模型领域竞争最为激烈的赛道之一。从早期的辅助补全到如今具备自主逻辑推理能力的智能体,代码大模型正经历着从“模型”向“能力中心”的质变。
本文将系统梳理代码大模型从2021年起至今的发展历程,深度剖析强化学习在代码推理中的优化机制、循环代码大模型的架构创新、跨语言协同的缩放定律,以及面向工业级应用的仓库级软件工程智能体。通过对IFEvalCode、CodeSimpleQA等前沿评测体系的讲解,展现如何构建具备可验证性、事实性和多轮交互能力的下一代代码智能系统。
01 背景介绍:代码基础模型的发展历史
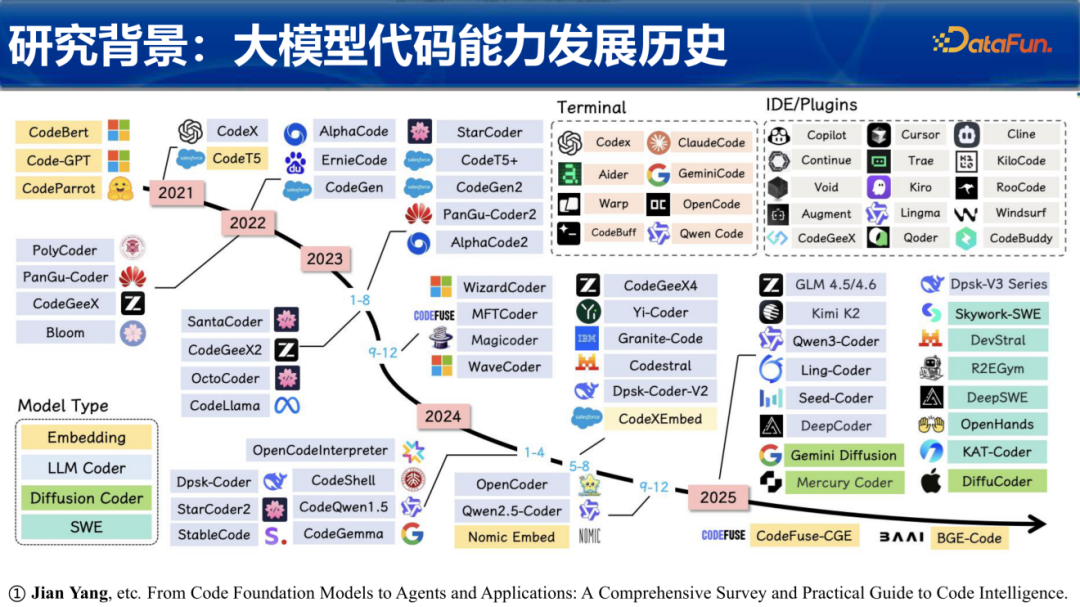
代码大模型的能力演进可以追溯到2021年。在那个阶段,我们看到了CodeBERT、Code-GPT以及OpenAI发布的一系列CodeX前身模型。早期的模型主要聚焦于简单的代码片段补全和基础语法理解。
随后在2022年至2023年,代码智能迎来了爆发期。StarCoder、CodeLlama以及各种针对特定任务优化的模型(如Magicoder、WizardCoder)纷纷涌现。厂商们开始意识到,通用模型在代码任务上的局限性,转而开发全链路开源的基础模型。进入2024年和2025年,代码能力进一步向垂直领域深耕,Qwen(千问)系列、DeepSeek(深度求索)系列、GLM系列以及Kimi K2等模型,不仅在参数量上大幅提升,更在逻辑推理和长文本处理上取得了突破。甚至出现了基于扩散模型的代码生成器以及针对特定工业需求的智能体。
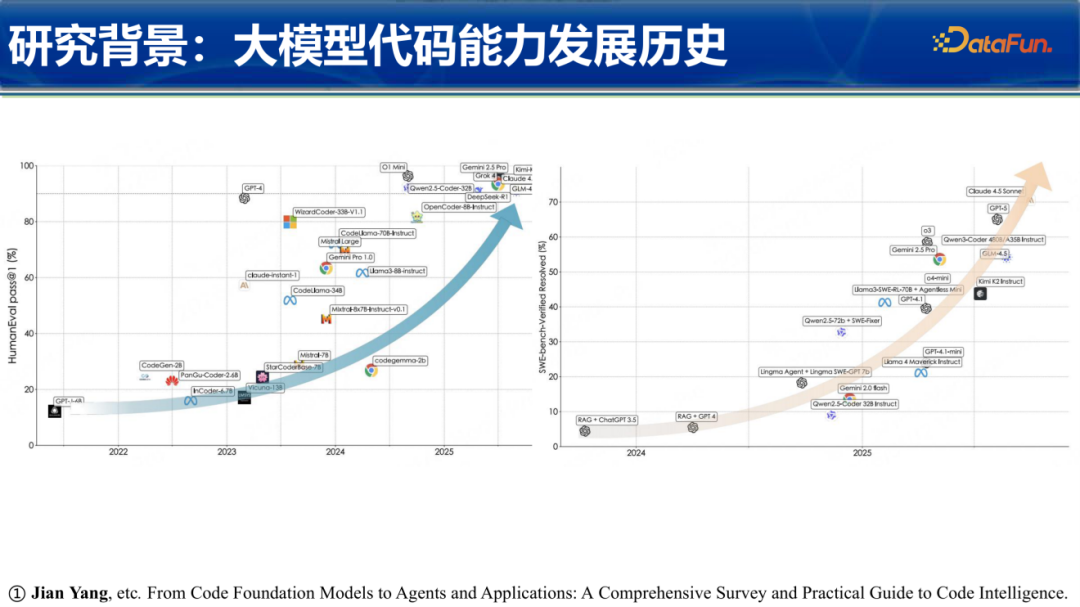
从评估数据来看,学术界常用的HumanEval榜单(主要考察简单的函数级代码生成)已经接近饱和,顶级模型的 pass@1 得分普遍超过了95分。然而,当我们将视角转向更具挑战性的实时软件工程任务(如 SWE-bench)时,会发现模型能力仍有巨大的提升空间。从最初在低水位徘徊,到如今最强模型已经能达到70-80分的水平,代码智能正从“能写短代码”向“能解工程问题”跨越。
02 代码基础模型的核心技术优化
1. 可验证奖励的强化学习优化:Dr. GRPO
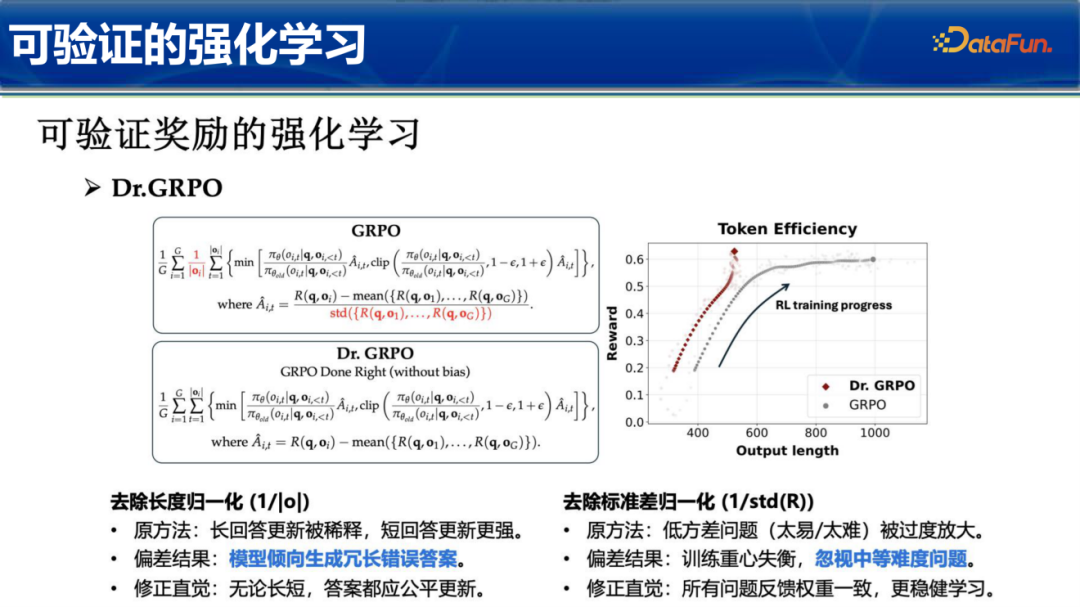
在代码生成任务中,强化学习是提升逻辑一致性的关键。然而,传统的GRPO方法存在偏差。其研究团队提出的 Dr. GRPO(GRPO Done Right) 对此进行了修正。
传统方法中,长度归一化会导致“长回答更新被稀释,短回答更新更强”的问题,这使得模型产生偏差,倾向于生成冗长但可能错误的答案。Dr. GRPO通过去除长度归一化,确保无论答案长短,更新权重都是公平的。此外,针对标准差归一化带来的低方差问题(即太易或太难的问题被过度放大),Dr. GRPO修正了直觉:所有问题的反馈权重应保持一致,从而使学习过程更加稳健。实验证明,这种“修正版”的强化学习极大提升了模型的Token效率和奖励增长曲线。
2. 策略熵(Entropy)在推理中的作用
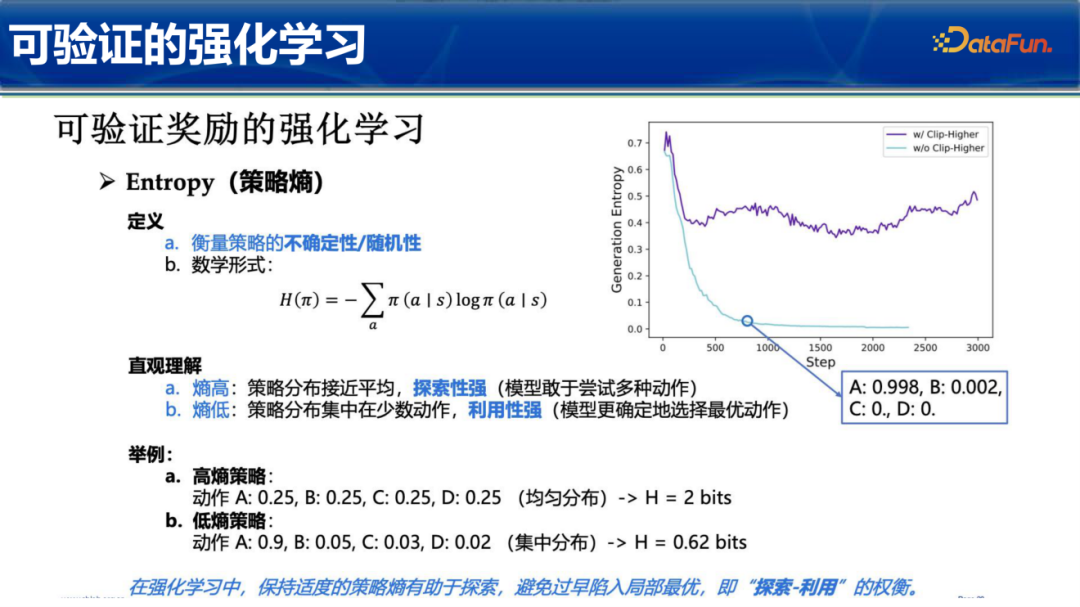
在强化学习中,策略熵 $H(\pi)$ 衡量了策略的不确定性。高熵意味着模型分布均匀,更敢于探索多种动作;低熵则意味着分布集中,倾向于选择当前最优动作。
保持适度的策略熵有助于模型避免过早陷入局部最优,实现“探索-利用”的平衡。如果在训练早期熵下降过快,模型会变得过于贪婪,导致无法发现更优的推理路径。
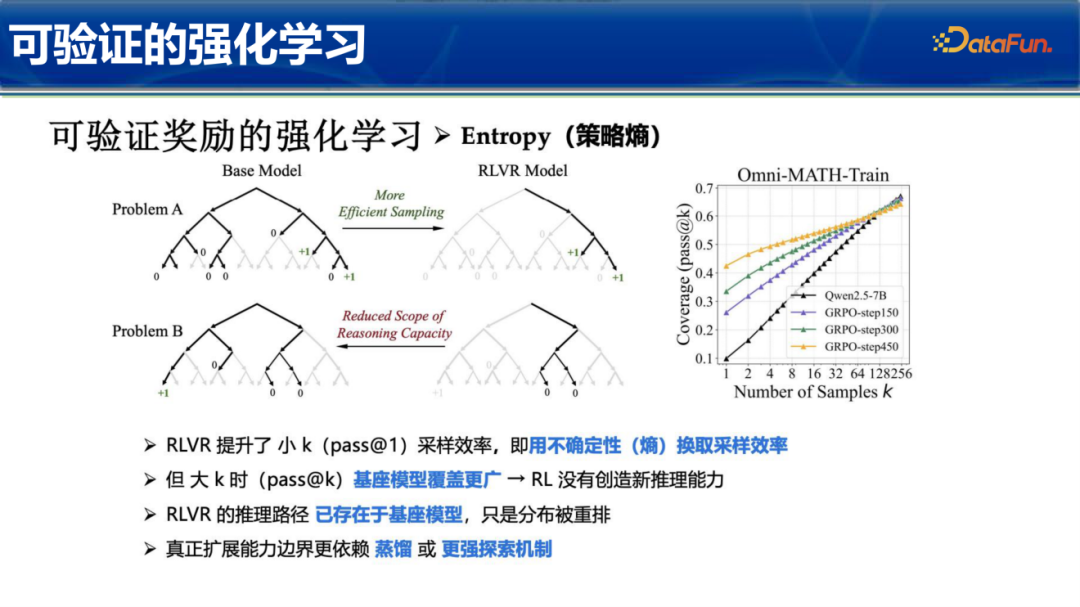
进一步研究表明,强化学习实际上是用不确定性(熵)换取采样效率。虽然RL能显著提升pass@1(即单次生成的准确率),但在覆盖范围上,基座模型往往由于具备更广的分布而表现更好。这揭示了一个深刻的结论:当前的RL更多是在重排推理路径分布,而非创造全新的推理能力。 真正的能力边界扩展,仍高度依赖于蒸馏技术或更强大的探索机制。
3. 离策略学习与SFT+RL的协同

为了弥补RL在极端难题上的乏力,研究团队采用了“离策略学习”策略。在RL训练过程中,穿插少量监督微调。当模型遇到极难问题且RL无法有效探索出解法时,通过收集高质量的Chain-of-Thought解答并存入Buffer,进行阶段性的SFT。这种“难题SFT”能为模型提供额外指导,帮助其跨越推理门槛。
03 代码大模型预训练:缩放定律与语言协同

代码模型的预训练数据配比一直是业内的“黑盒”。研究团队首次系统研究了多编程语言代码预训练的缩放定律。
通过超过1000组实验,研究揭示了不同编程语言之间的“协同增益矩阵”。例如,Python这种现代脚本语言对其他几乎所有语言都有正向增益,而Java或C#等面向对象语言之间则存在极强的互相迁移效应。研究给出了一个核心公式:目标编程语言的损失由模型规模、该语言特有的缩放指数以及来自其他语言的跨语言迁移系数 $\tau_k$ 共同决定。这一发现为训练有效的代码基础模型提供了精确的数据分配指导方案。
04 循环代码大模型:LoopCoder的架构创新
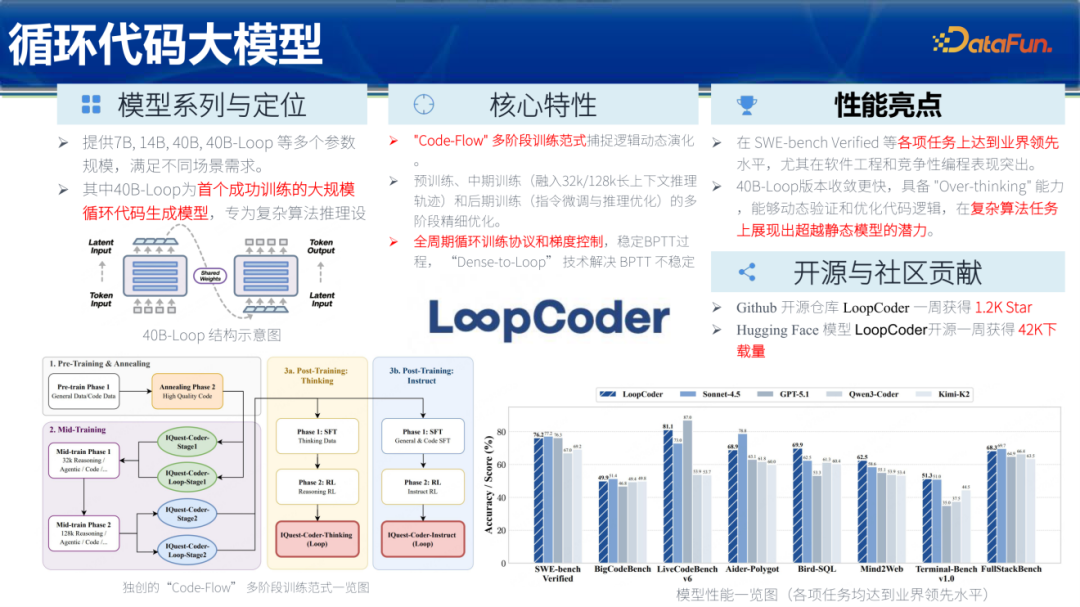
传统的Transformer架构通过叠加Decoder层增加深度。研究团队参考了“循环结构”,推出了 LoopCoder 系列模型。
LoopCoder核心创新在于 “Dense-to-Loop” 技术。通过在一套完整的模型权重中循环迭代两次,模型可以在不显著增加参数量的情况下,获得双倍的逻辑深度。40B-Loop模型在推理时展现出了所谓的“Over-thinking”能力,能够动态验证并优化代码逻辑。在复杂算法和软件工程任务中,LoopCoder展现出了超越静态Dense架构的潜力,收敛速度更快,且在长上下文推理轨迹中表现优异。
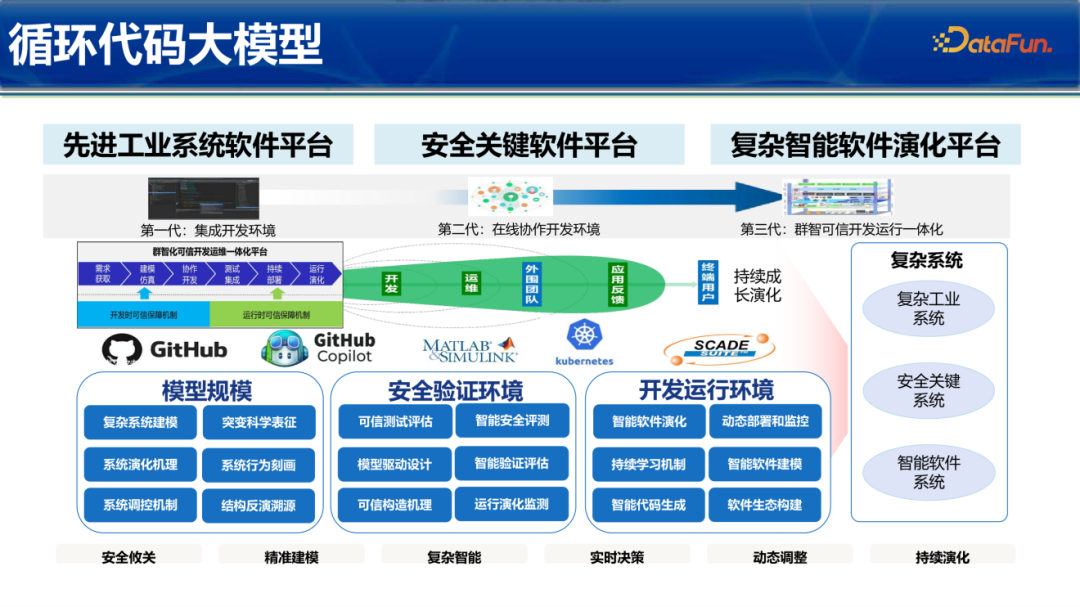
LoopCoder的应用愿景不仅限于简单的代码编写,更在于支撑“第三代:群智可信开发运行一体化平台”。它为复杂工业系统、安全关键软件平台提供了核心推理引擎,实现了从“开发时可信保障”到“运行时动态演化”的全生命周期覆盖。
05 质量与评测:构建严谨的代码评估体系
代码大模型的评估不能仅看HumanEval。研究团队构建了多个维度、工业级的评测框架:
1. 可控生成:IFEvalCode

针对模型指令遵循能力弱的问题,构建了涵盖8种编程语言、中英双语的基准。它要求模型在生成代码的同时,必须严格遵守特定的约束(如:变量名必须是回文、禁止使用特定循环语句等)。
2. 多粒度评测:M²G-Eval
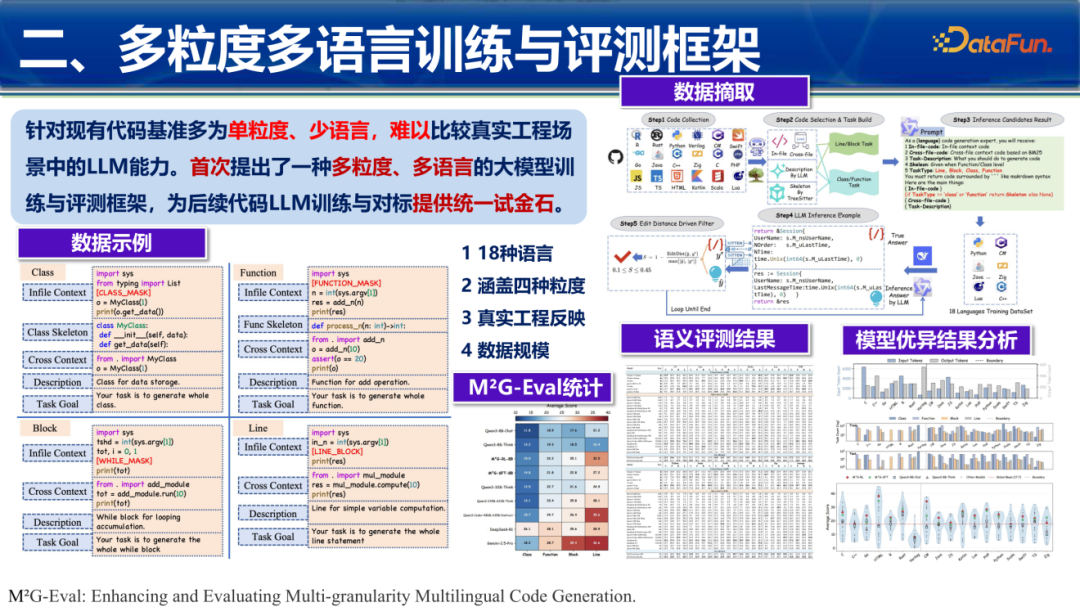
现有的Benchmark多为单函数级别。M²G-Eval首次提出了涵盖行/块级、函数级、类级、文件级甚至是跨文件级的多粒度评测,真实反映了工程场景中LLM的处理能力。
3. 事实性问答:CodeSimpleQA
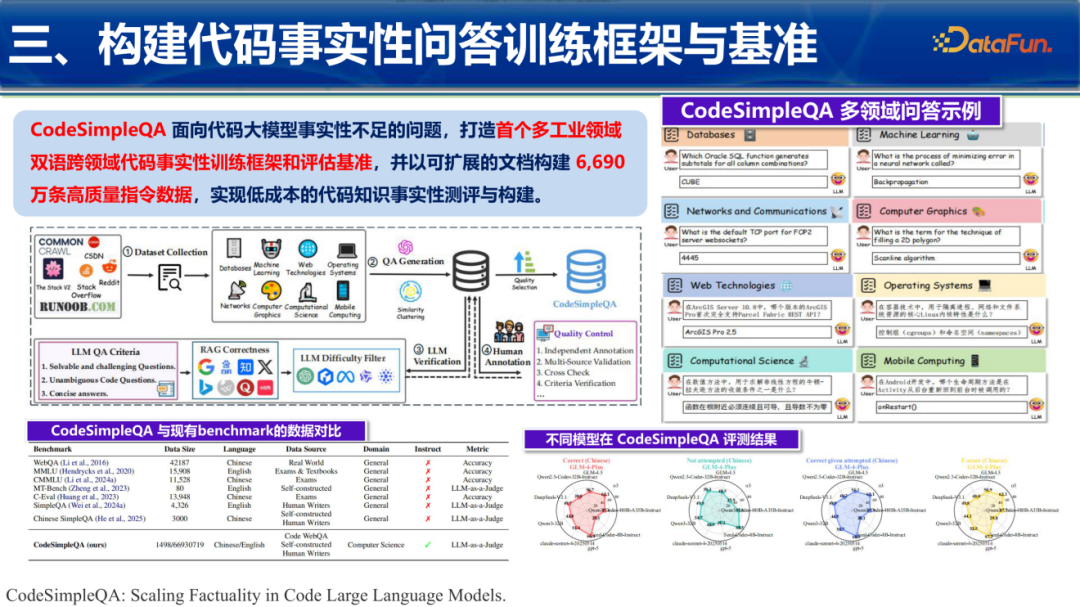
针对大模型“幻觉”严重的问题,团队构建了包含6690万条高质量指令的数据库。涵盖操作系统、网络通信、数据库等领域的硬性知识问答,旨在评估并训练模型在代码事实性上的准确性。
4. 多轮对话:Code-MT-Bench
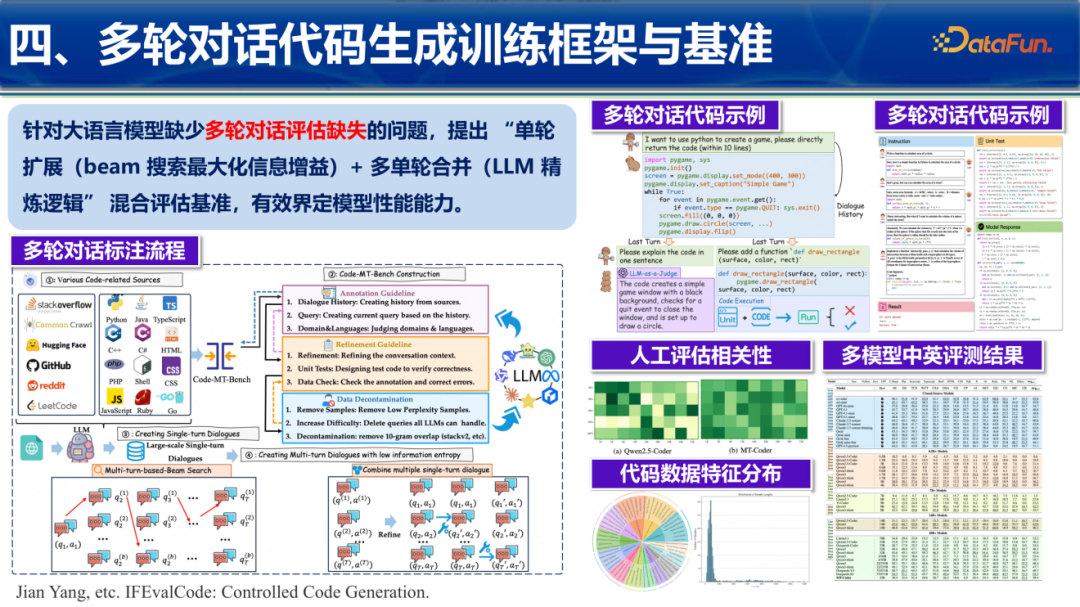
通过束搜索算法扩展单轮生成的对话深度,构建了具备逻辑链条的评估基准,专门考察模型在连续对话中修复Bug、优化逻辑的能力。
06 代码智能体:走向仓库级智能
1. 软件工程智能体的范式演进
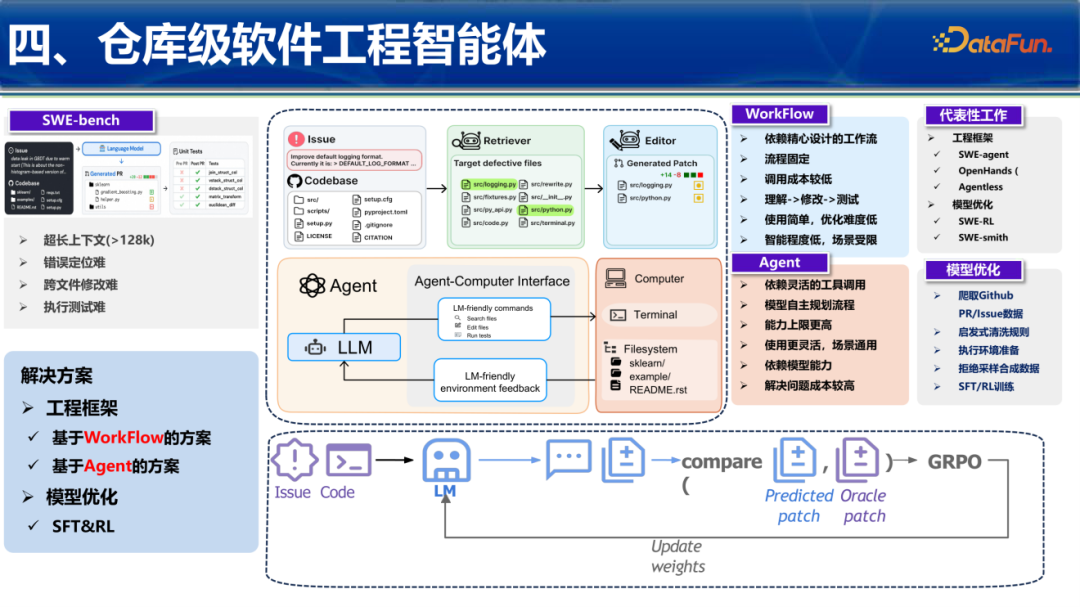
代码智能体的发展路径分为两种:基于工作流和基于自主规划。
- Workflow:依赖精心设计的固定流程,调用成本低,理解难度低,但智能程度受限。
- Agent:依赖灵活的工具调用和自主规划能力,上限更高。
针对仓库级难题,如错误定位难、跨文件修改难等,研究团队提出了将智能体链路通过SFT/RL训练内化到模型中的方案,通过构建RepoReflection等机制,实现模型对运行结果的自我反馈与迭代。
2. 多编程语言智能体协作
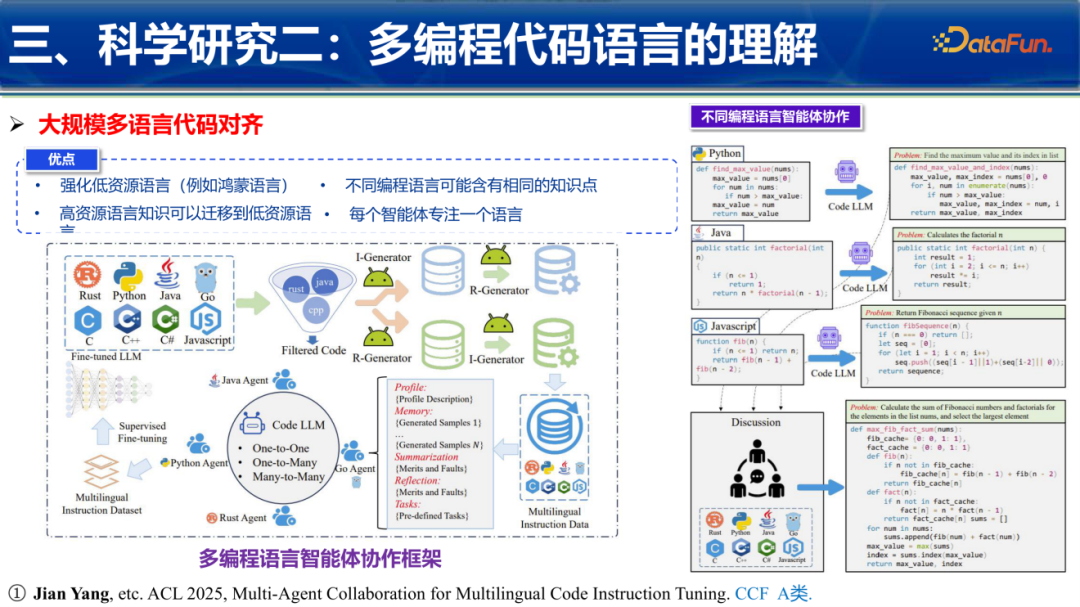
为了处理低资源编程语言的增益问题,提出了“多智能体协作框架”。每个Agent专注一种语言,通过多轮讨论和投票,使得知识从高资源语言向低资源语言迁移。
3. 视觉与多模态代码仿真
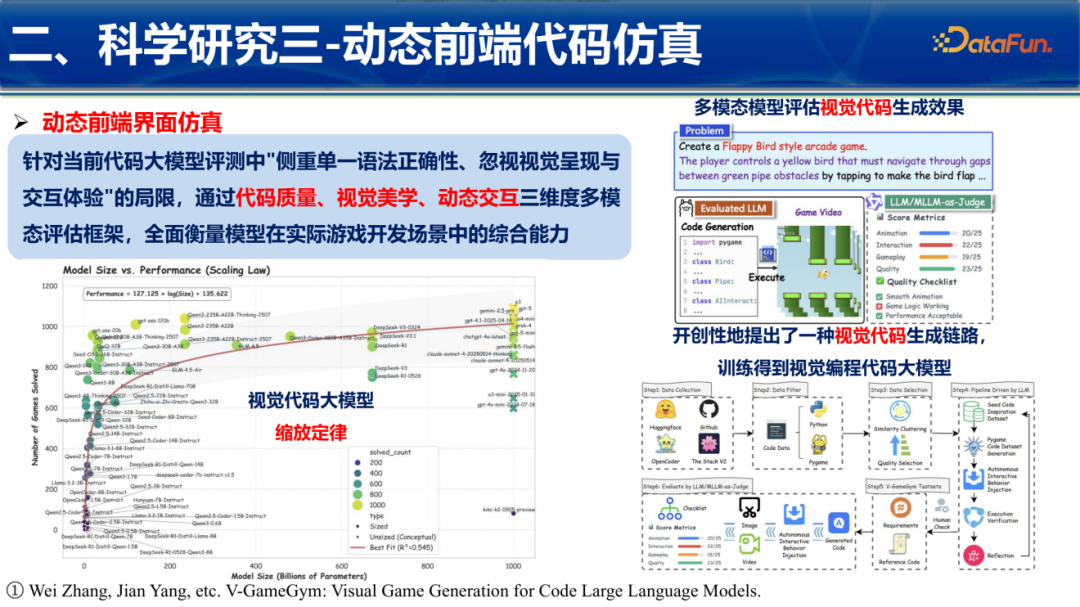
未来的代码模型不应只懂语法,还应具备“视觉呈现”与“交互体验”能力。团队推出了 V-GameGym 框架,通过代码质量、视觉美学、动态交互三个维度评估模型生成动态前端界面的水平。例如,直接生成一个可运行、且画面精美的《Flappy Bird》游戏,并由多模态大模型担任“裁判”进行视觉评分。
07 总结与展望:Qwen-Coder的开源贡献
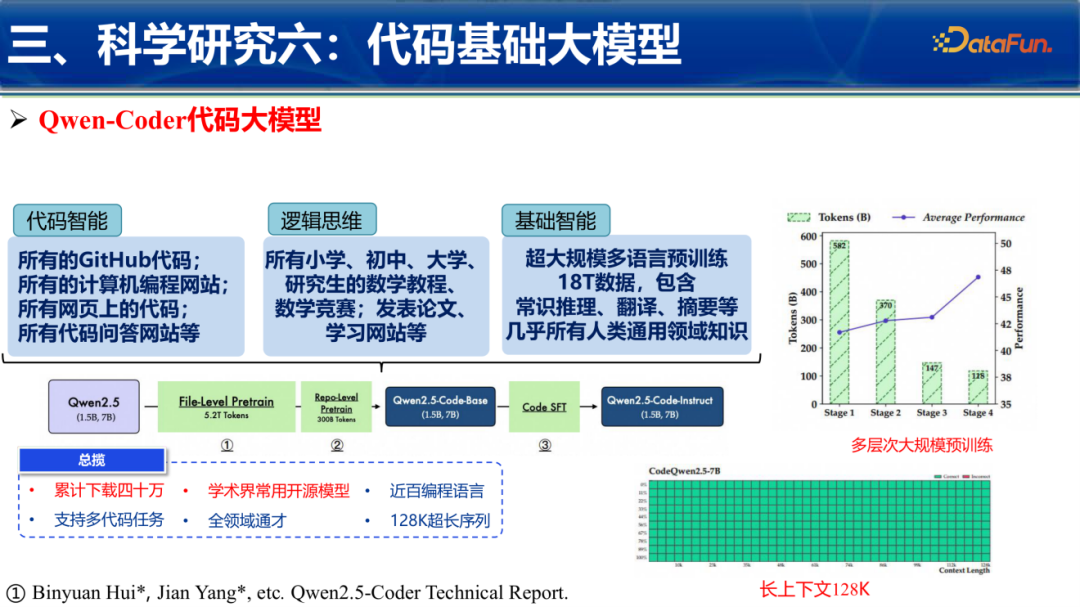
作为第一共同作者开发的 Qwen-Coder(千问代码大模型) 系列,是目前开源社区的佼佼者。Qwen2.5-Coder凭借18T Token的超大规模预训练、128K超长上下文支持,在国内外多个权威榜单上位列第一。
研究不仅提供了模型权重,还通过 OpenCoder 项目完全开源了数据处理全链路。这包括了130条过滤规则、75B代码相关网页Token、以及4.5M高质量微调数据。这种全方位的开源策略,旨在降低行业训练门槛,让“人人都能训练代码大模型”。
从代码补全到逻辑推理,从单行修复到仓库级演进,代码智能正以前所未有的速度重构软件工程。这一系列工作,不仅在算法层面突破了RL优化与模型架构的瓶颈,更在数据生态和评估体系上为全行业树立了基准。对相关技术细节和开源实战感兴趣的开发者,可以在技术社区进行深入探讨。
08 结语与问答 Q&A
Q1:关于RL和SFT的切分,具体的逻辑是怎样的?
A1: 这取决于任务目标。如果是通用能力提升,通常需要50万条以上的数据做“冷启动”。当模型在SFT阶段性能不再显著上升,但仍未触及SOTA天花板时(例如处于60-70分水位),我们会切换到RL。RL擅长在高分段进行微操提点。如果RL出现震荡,我们会重新引入高质量CoT进行SFT。两者是一个循环迭代的过程。
Q2:HTML代码生成的验证如何做?美观度如何量化?
A2: 我们搭建了一个GUI Agent环境。一方面通过代码插桩检测逻辑执行;另一方面通过多模态大模型作为裁判,结合代码层面的CSS规范检查,共同对生成的视觉效果和交互性进行打分校验。
感谢研究团队在代码智能领域的卓越贡献。
 发表于 2026-3-31 18:14:38
|
查看: 192|
回复: 0
发表于 2026-3-31 18:14:38
|
查看: 192|
回复: 0
