Verilog端口声明写错、CUDA配置出错、嵌入式HAL调用类型不匹配……这些问题的根源或许不是模型“不够聪明”,而是因为当前的通用代码大模型压根没系统性地学习过工业代码。
近日,北航团队联合多家机构正式发布了InCoder-32B。这是一个专门针对工业代码场景打造的基座模型,其最大特点在于其250万条训练样本均产自真实的仿真执行环境,并经过执行验证。模型统一覆盖了芯片设计、GPU内核优化、嵌入式系统、编译器优化与3D建模等多个工业研发方向。目前,其全量权重及多个量化版本已全部开源。
开源地址:
模型定位:为什么需要一个工业代码专用模型?
当前主流代码大模型的训练语料高度集中于Python、JavaScript、TypeScript等通用编程语言,对于Verilog/SystemVerilog、CUDA/Triton、ARM汇编、CadQuery等工业专用语言的覆盖极为有限。有研究统计指出,即使是性能领先的模型,在Triton算子生成上的函数调用成功率也仅有28.80%,在Verilog形式等价性验证中的准确率更是低至33.3%。
基于此,InCoder-32B的设计思路非常明确:与其在通用模型上做“打补丁”式的适配,不如从预训练阶段就将工业代码纳入核心训练框架,同时确保其通用编程能力不发生退化。
技术路线:三阶段Code-Flow训练
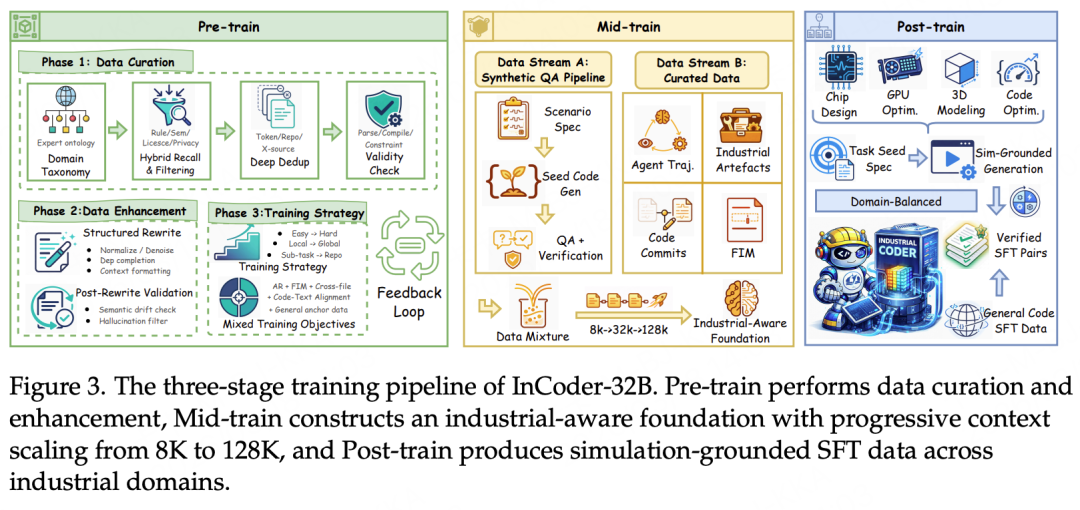
InCoder-32B的训练采用了渐进式的三阶段Code-Flow流水线,旨在让模型从具备通用代码能力逐步过渡到精通工业代码。
Stage 1:预训练与退火。
本阶段使用了4096块GPU进行大规模预训练,共处理了15万亿token。数据来源多样,包括公开代码仓库、从技术文献中经OCR提取的代码片段,以及专业领域网站。数据质量通过严格的许可证过滤、个人身份信息(PII)移除、多级去重以及AST(抽象语法树)级验证和重编译校验来保障。训练目标融合了自回归语言建模与FIM(Fill-in-the-Middle)补全,并通过课程学习策略,使模型从函数级理解逐步过渡到项目级理解。
Stage 2:中期训练。
这一阶段承担了两项核心任务。第一项是上下文窗口的渐进式扩展,从8K逐步扩展至128K。首先从8K扩展到32K,以处理文件级任务;再从32K扩展到128K,以支持扩展调试会话等长上下文工业场景。第二项任务是在数据配比中系统性注入三类合成数据:一是合成工业代码QA对,通过与硬件/系统工程师协作确定场景规格并生成种子代码,再合成经自动验证的问答对;二是智能体轨迹,即遵循“思考-行动-观察”循环的多步调试与修复轨迹,其中包含了来自硬件仿真器、综合工具、编译器等形式化验证引擎的工具反馈;三是工业代码制品,如硬件测试台、时序约束、综合脚本、GPU性能剖析日志和内存检测日志等。
Stage 3:后训练。
本阶段直接使用了前述的250万条经执行验证的工业代码SFT(监督微调)数据进行指令微调。这是InCoder-32B在工业代码领域实现能力突破的直接驱动力。团队同时提供了Instruct(指令遵循)和Thinking(思考推理)两种微调变体,分别对应标准的指令遵循模式和带有分析推理链的生成模式,以满足不同场景的需求。
数据扩展:工业级仿真环境驱动的数据生产
通用的SFT数据集对于工业编码任务几乎毫无帮助,尤其是当代码的正确性必须依赖实际执行结果来判定时。InCoder-32B的核心创新点正在于此:它直接从真实的工业编码任务出发,在模拟生产级的执行环境中,构建了250万条有执行验证结果背书的训练样本。
通用代码或许可以通过单元测试快速判定对错,但工业代码则复杂得多。一个Verilog模块可能在语法上毫无问题,却会在综合阶段因为时序违约而无法流片;一段CUDA内核编译通过且数值正确,但如果吞吐量不达标就毫无实用价值;嵌入式固件在桌面模拟器上运行正常,到了真实微控制器上却可能因为中断优先级冲突而死锁;CAD脚本成功生成了3D实体,但体积偏差超标就意味着零件不可制造。
换言之,工业代码的“正确”必须在其目标部署环境中被证实。这就要求数据生产的基础设施必须还原真实的执行条件,而不能仅仅依赖启发式规则或静态分析。
四套生产级执行环境
团队从零搭建了四套仿真基础设施,每一套都严格对齐了对应领域工程师在日常工作中使用的完整工具链:
- 芯片设计。 容器内集成了Icarus Verilog(行为级仿真)、Verilator(将RTL编译为C++进行周期精确仿真)和Yosys(门级综合)三款开源EDA工具。从仿真到综合的完整前端流程在同一镜像中形成闭环,任何一条训练数据能否通过,取决于它在这三个阶段全部环节的表现,而不仅仅是“编译不报错”。
- GPU内核开发。 在NVIDIA A100集群上直接部署了CUDA和Triton两条编译执行路径。所有内核均在真实GPU硬件上启动和测量性能,性能数据通过CUDA events采集,这与FlashAttention、vLLM等项目的真实开发环境完全一致,确保了训练数据中的性能信号在真实推理部署中同样成立。
- 3D参数化建模。 以OpenCascade内核配合CadQuery Python接口为基础构建。验证过程不仅检查脚本能否执行,还会将生成的实体与参考体分别网格化后进行体积重合度比较。这意味着,即使脚本无报错地执行完毕,只要最终三维形状与设计规格的偏差超过阈值,该数据一样会被标记为失败。
- 嵌入式与汇编优化。 嵌入式方向针对STM32F407微控制器,使用ARM交叉编译器生成固件,并在Renode全系统仿真器上运行。Renode提供了寄存器级精确的外设模型,能暴露实际硬件上才会出现的中断与总线时序问题。x86-64汇编优化则在固定CPU频率、绑定核心亲和性的受控条件下进行原生执行测量,复刻了编译器回归测试的标准方法论。
闭环修复:让“失败”也变成训练信号
有了执行环境之后,数据生产按照四步流程推进。首先,将工业编码任务拆解为结构化指令,明确需求描述、接口签名、目标平台和验证脚本。其次,通过模板扰动和跨语言迁移等手段为每个任务生成一批多样化的候选解。接着,将候选解送入对应的仿真环境进行全链路验证。
关键在于第四步:对于未通过验证的候选解,流水线并非简单丢弃,而是完整捕获失败的上下文信息(如编译器报错、运行时异常、仿真波形差异、性能热点等),然后将这些诊断信息附加到原始失败代码上,驱动模型生成修复版本。最终产出的“失败代码 → 诊断反馈 → 修复代码”完整轨迹本身也作为高质量的训练样本保留下来。这种设计直接模拟了资深工程师的核心工作模式:阅读工具输出、定位问题根因、迭代修复直至通过验证。
经过严格的质量过滤,250万条样本最终被划分为三类:从需求直接到实现的解答型样本、包含完整修复轨迹的缺陷修复型样本,以及在功能正确基础上进一步提升效率或代码结构的优化型样本。
评测结果
InCoder-32B在14个通用代码基准和9个工业代码基准上进行了全方位测试。
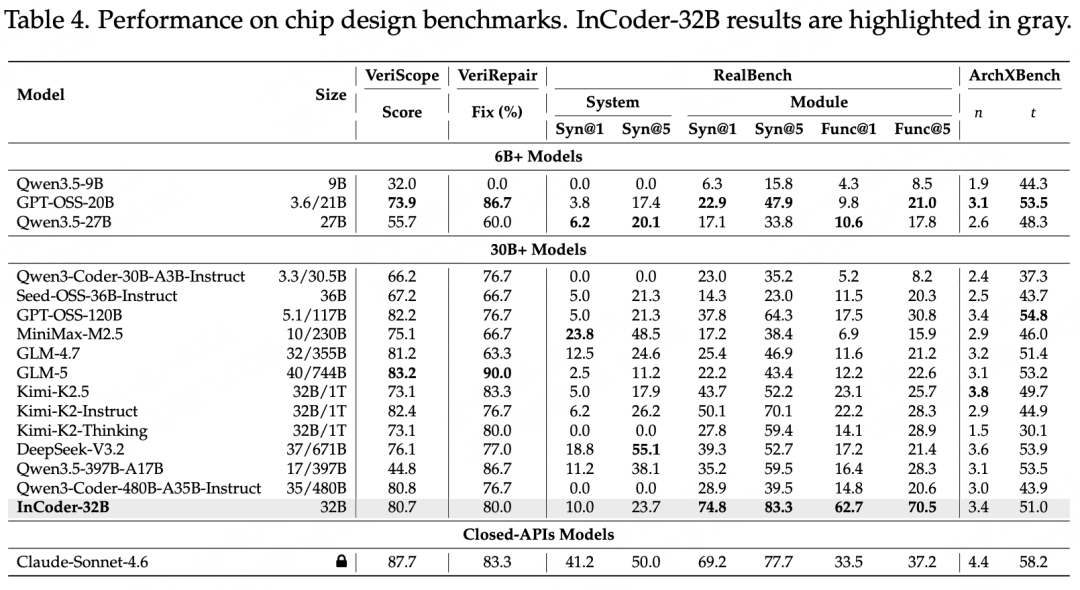
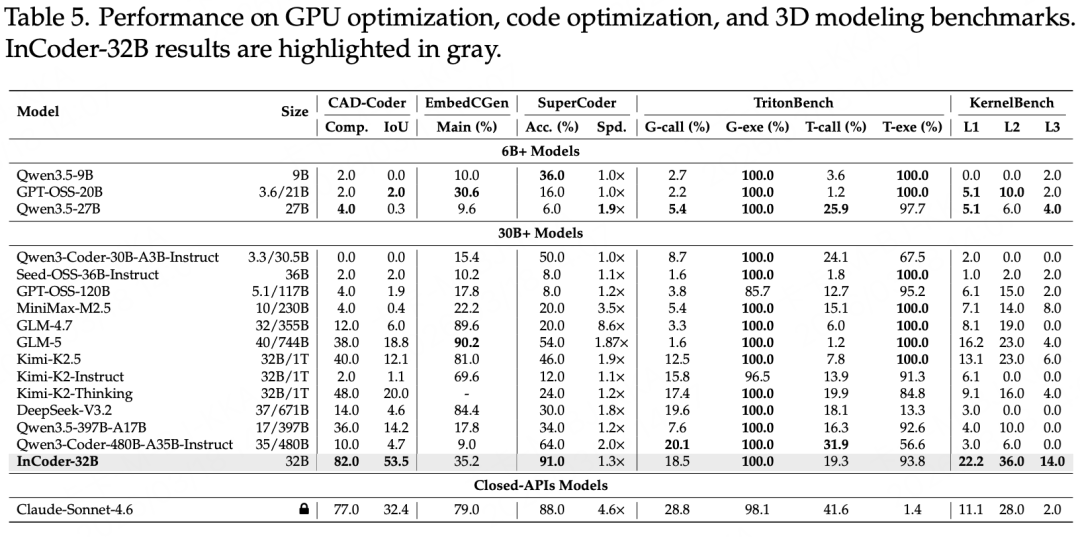
通用代码能力未受损。 模型在HumanEval上的通过率达到94.5%,在MBPP上达到91.8%,在SWE-bench Verified上达到74.8%,在Terminal-Bench v1.0上得分为35.0。这些成绩表明,面向工业场景的专项训练并没有以牺牲通用代码能力为代价。
工业代码全线领先。 在芯片设计方向,其在VeriScope上得分80.7,VeriRepair修复率达到80.0%,RealBench的Syn@1和Func@5分别达到74.8%和70.5%,大幅超越同规模其他模型。在GPU优化方向,KernelBench三个难度级别L1、L2、L3的通过率分别为22.2%、36.0%、14.0%,均为开源模型最佳。在3D建模方向,CAD-Coder编译成功率高达82.0%,IoU达到53.5%,显著超过了闭源模型Claude-Sonnet-4.6的32.4%。在代码优化方向,SuperCoder准确率高达91.0%。
数据规模效应:扩展工业SFT数据是否有效?
为了验证工业代码SFT数据的扩展效果,团队在83M、167M、250M三个token规模节点上进行了系统的消融实验。
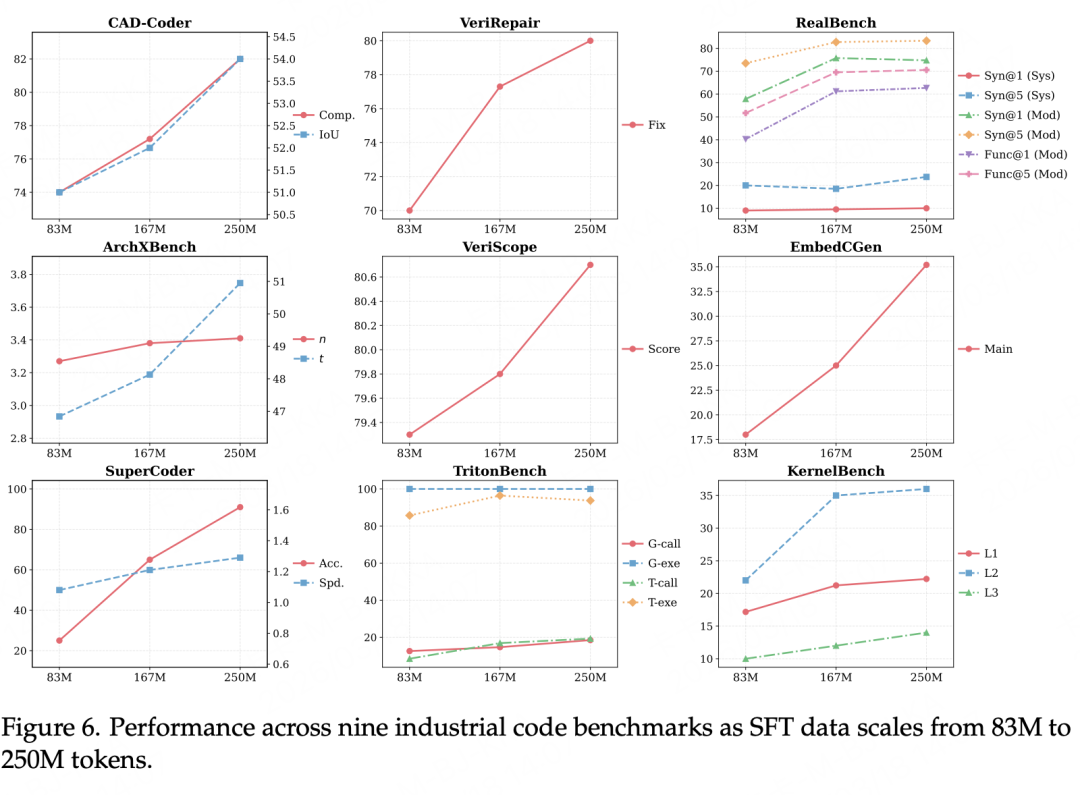
实验结果表明,大多数工业代码基准的性能随着数据规模的增长而持续提升,这证实了规模化工业SFT数据对模型能力具有明确的正向驱动作用。仅有RealBench和TritonBench的个别子指标在250M阶段出现了轻微波动,但整体表现仍高于或接近83M基线,这表明与验证流程强相关的能力可能在较小规模的高质量数据上就已趋于饱和。
模型推理
环境安装
pip install -U "transformers>=4.57.1" accelerate safetensors
推理脚本
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Multilingual-Multimodal-NLP/IndustrialCoder"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
messages = [{"role": "user", "content": "Optimize this CUDA kernel for better memory coalescing."}]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer([text], return_tensors="pt").to(model.device)
with torch.no_grad():
out = model.generate(**inputs, max_new_tokens=2048, temperature=0.6, top_p=0.85, top_k=20)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True))
使用vLLM推理
pip install vllm
# BF16精度推理
vllm serve Multilingual-Multimodal-NLP/IndustrialCoder \
--tensor-parallel-size 4 --max-model-len 32768
# FP8精度推理 (使用量化版本)
vllm serve Multilingual-Multimodal-NLP/IndustrialCoder-32B-FP8 \
--tensor-parallel-size 2 --max-model-len 32768
推荐的采样参数:
| 场景案例 |
temperature |
top_p |
top_k |
max_new_tokens |
| 通用编码 |
0.6 |
0.85 |
20 |
2048 |
| 工业方向 |
0.2 |
0.95 |
— |
4096 |
| 思考变体 |
0.6 |
0.85 |
20 |
8192 |
InCoder-32B的发布为芯片设计、高性能计算、嵌入式开发等领域的工程师提供了一个强有力的AI辅助工具。其开源的权重和详细的技术文档也降低了研究和应用的门槛,对于推动工业软件智能化具有积极意义。更多关于模型架构和训练细节的讨论,欢迎访问云栈社区的相关板块进行交流。
 发表于 2026-3-31 18:19:51
|
查看: 385|
回复: 0
发表于 2026-3-31 18:19:51
|
查看: 385|
回复: 0
