
单模型主导的时代,或许真的要结束了。
微软刚刚为Copilot进行了一次关键引擎升级,在其深度研究智能体“Researcher”中正式引入了多模型智能。这意味着,当你使用Copilot进行资料研究时,系统将默认同时调用GPT和Claude两大顶尖模型来协同工作。
这并非简单的模型切换功能。其核心工作流是:首先由GPT负责规划任务、检索信息并起草报告初稿;紧接着,Claude会自动扮演“专家评审员”的角色,基于一套结构化的评价标准对初稿进行逐条审查与批判,最后再将精修后的结果交付给用户。
简而言之,一个模型负责“冲锋”生成内容,另一个模型则负责“挑刺”确保质量。
微软官方表示,这是Microsoft 365 Copilot的深度研究代理“Researcher”迈出的重要一步。Researcher专为处理工作流中的复杂研究任务而设计,此次通过全新的“批判”(Critique)和“智囊团”(Council)两项多模型能力,旨在全面提升研究结果的准确性、深度和可信度。
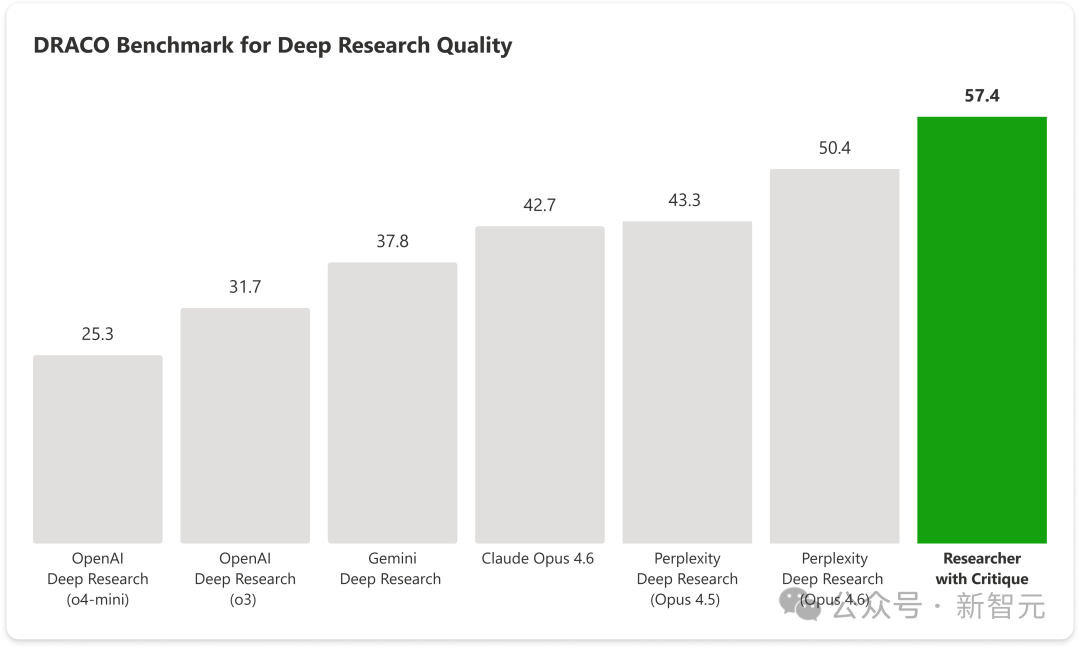
实测效果相当显著。在衡量深度研究质量的DRACO基准测试中,这套“双模型互搏”架构的综合得分,比此前被誉为行业天花板的Perplexity Deep Research(搭载Claude Opus 4.6)高出13.8%。

但这还不是全部。同一天,微软还上线了“Copilot Cowork”,并宣称这是将支撑Claude Cowork的技术平台直接引入了Microsoft 365 Copilot。这已经不是简单的“接了个API”,而是将外部的先进智能体能力深度整合进微软自身的工作系统。
微软的布局意图已相当清晰:不再将赌注押在任何一个单一模型上,而是构建一个能够灵活编排Anthropic、OpenAI等顶尖模型的多模型框架。Copilot正在从一个传统的AI助手,升级为一个面向企业级应用的多模型任务执行与编排系统。
Critique:让AI自己审自己的作业
传统AI研究流程存在一个结构性问题:任务规划、信息检索、内容综合与报告撰写,全部由同一个模型完成。这就好比让运动员同时兼任裁判,产生“幻觉”或偏见几乎难以避免。
微软此次提出的解决方案是:将“生成”与“评估”这两个角色彻底分离。
具体实现上,GPT负责上半场,包括任务规划、迭代检索和起草初稿;Claude则负责下半场,以“同行评审”的身份,依据结构化评价量表对初稿进行审查。这个量表主要聚焦三个维度:
- 来源可靠性评估,审查引用是否权威、可验证;
- 报告完整性,检查是否覆盖了用户请求的所有关键点;
- 严格的证据溯源,要求每一个关键结论都必须锚定到带有精确引用的可靠来源。
关键在于,审阅者的定位是“评审者”而非“第二作者”。它的目的不是替你重写,而是通过提出批判性问题,迫使生成模型产出更高质量的内容。微软365和Copilot企业副总裁Nicole Herskowitz强调:“我们不是简单地在Copilot里塞了多个模型,我们是让客户真正享受到模型协同工作的好处。”
未来,这套机制还可能升级为双向互审,即GPT也能评审Claude生成的内容。目前,Critique模式已成为Researcher的默认设置,用户无需手动开启。这本质上是将运行了数百年的学术同行评审制度,首次工程化地嵌入了AI系统,试图通过架构设计而非单纯依赖模型能力来抑制“幻觉”。
DRACO跑分拆解:13.8%提升的含金量
数据是最有力的证明。DRACO(深度研究准确性、完整性和客观性)基准测试由Perplexity和学术界研究人员于2026年2月推出,覆盖10个领域的100项复杂研究任务。评测采用GPT-5.2作为评委模型,从事实准确性、分析广度和深度、表达质量、引用质量四个维度进行打分。
在采用与基准论文完全一致的评估协议下,搭载Critique的Researcher综合得分实现了显著提升,比此前表现最好的Perplexity Deep Research高出13.88%。
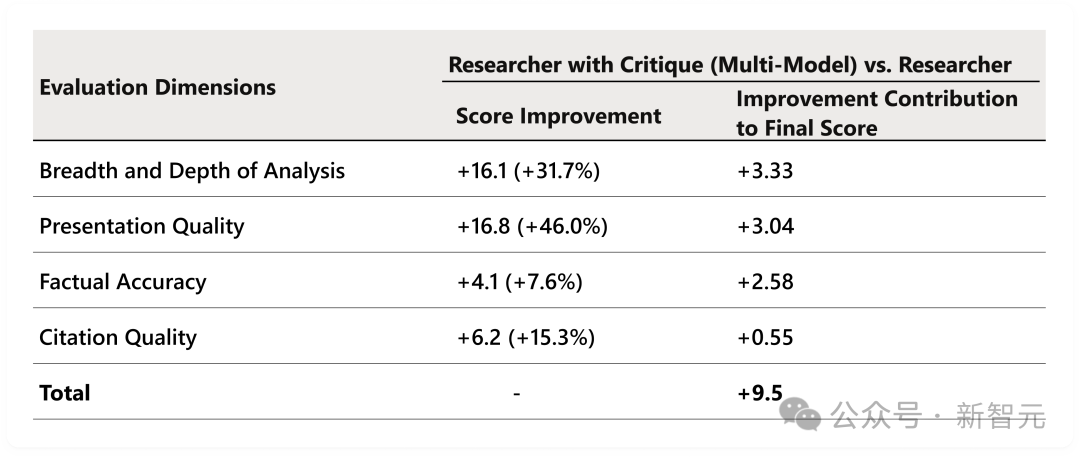
拆解四个评估维度来看:
- 分析广度和深度提升最为明显(+3.33分);
- 其次是表达质量(+3.04分)和事实准确性(+2.58分);
- 引用质量也有稳固提升。
所有维度的提升均具有统计学显著性。其中,分析深度的大幅飙升表明,Critique的核心价值不仅在于纠错,更在于能激发出更全面、更多元化的分析视角。
在深度研究这个竞争白热化的赛道上,13.8%的综合提升代表了一次重要的架构性突破。此前各家模型在性能上咬得很紧,而微软通过多模型协作的框架创新,实现了显著的跨越。
Council:当你需要的不是一份报告,而是一场辩论
Critique解决的是“如何让一份报告更精准”的问题。但在某些决策场景中,用户需要的可能不是一份经过精修的统一意见,而是来自不同视角的激烈碰撞。
这就是“智囊团”(Council)模式的设计初衷。
在模型选择器中切换到“Model Council”后,GPT和Claude会各自独立生成一份完整的报告,并排展示给用户。随后,一个专门的评委模型会对这两份报告进行评估,并生成一份综述(Cover Letter),深入分析双方在哪些观点上达成一致、在何处存在分歧,以及各自带来了哪些独特的见解。
表面上看,这只是从“多选一”变成了“全都看”。但其深层价值在于,它将复杂决策中的信息盲区和不确定性暴露了出来。一个模型可能忽略的事实、另一种分析框架的权重、不同的推理路径……Council模式把这些可能性全部摆到了台面上。
例如,在准备季度战略报告时,你更希望看到一份经过整合的精修稿,还是两位“专家”各执一词、由你来最终判断?
可以说,Critique是“编辑审稿”模式,追求效率与准确性;Council则是“专家会诊”模式,追求决策的全面性与思考深度。这两种模式精准覆盖了企业利用AI进行研究的两类核心场景。
Copilot Cowork:微软将Anthropic的Agent能力深度整合
如果说Critique和Council提升的是研究产出的质量,那么Copilot Cowork旨在改变工作本身的方式。
微软明确表示,Copilot Cowork是“基于Anthropic的Claude Cowork技术平台构建的”。这一定位远超简单的“接入”或“兼容”,意味着更深层次的技术整合。
它的工作流程非常直观:用户只需描述想要达成的目标,Copilot Cowork便会自动制定执行计划,跨越多款办公工具和文档进行逻辑推理与操作,并在推进过程中实时展示进度,允许用户随时介入和引导。
它集成了Claude的能力以及微软的原生功能(如日历管理、每日简报等),能够处理从整理收件箱到准备月度预算审查等各种任务。目前,该功能已通过Frontier计划向早期客户开放。
这意味着,微软与Anthropic的关系已经从“模型供应商”进化到了“技术平台共建”阶段。Cowork几乎是将Claude的智能体(Agent)骨架直接嵌入了Microsoft 365的肌体之中。这无疑是一次架构级别的战略选择。
战略转向:从AI助手到模型编排中心
将上述所有动作串联起来,微软的战略意图已然清晰:它不再押注自己或任何一个单一模型成为最终赢家,而是转向构建一个平台层——无论未来哪家模型胜出,其流量和能力都需要经过微软的“编排中心”。
从深度依赖OpenAI,到将Anthropic的核心技术深度整合进产品线,微软正从“参赛选手”转型为“比赛调度员”。
Critique让GPT和Claude协作,Council让它们竞争,Cowork则让Anthropic的智能体能力直接为Office用户服务。这背后是清晰的平台逻辑,而非模型逻辑。
对开发者和企业而言,一个明确的信号是:未来的竞争力可能不在于绑定某一个最强的模型,而在于如何有效编排和协同多个模型的能力。
当然,市场对此次升级的反应略显平淡,微软股价当日仅微涨,本季度仍面临较大压力。华尔街可能更关注多模型调用带来的成本问题,以及该功能能否真正融入企业日常工作流。
但可以确定的是,这次升级重塑了微软与OpenAI的伙伴关系。OpenAI在微软生态中的角色,已从“唯一的王牌”转变为“牌桌上的重要玩家之一”。对于Anthropic、OpenAI乃至谷歌而言,值得警惕的是:当平台方开始将顶级模型的能力视为可替换、可编排的模块时,模型本身的性能或许就不再是不可逾越的护城河了。
企业级AI正在从“聊天机器人”时代,迈入“智能工作系统”时代。在这个转折点上,决定胜负的关键可能不再是谁家的基准测试分数最高,而是谁能将多个大模型可靠、可审计、高效地编排进真实的企业工作流中。对于关注AI技术和行业动态的开发者而言,这一趋势无疑值得深入思考。欢迎在云栈社区交流你的看法。
参考资料:
 发表于 2026-4-1 01:08:23
|
查看: 171|
回复: 0
发表于 2026-4-1 01:08:23
|
查看: 171|
回复: 0
