你的系统又“挂”了?先别急着自责。在分布式架构的世界里,故障从来都不是“万一”发生,而是一种必须被正视的“常态”。网络会抖动、服务器会宕机、磁盘会损坏、时钟会漂移……这些事件的发生概率远高于我们的直觉。
一个真正优秀的分布式系统,目标绝非永不故障,而是追求在故障发生时依然能够优雅运行,将影响降到最低。今天,我们就来系统性地拆解容错设计的核心逻辑,聊聊如何将一个“脆弱”的系统,一步步打造成具备“韧性”的堡垒。更多关于系统架构的深入讨论,欢迎在云栈社区交流。
一、故障类型:分布式世界的“三大天灾”
理解故障,是设计容错的第一步。在分布式系统中,故障不是单一的,它通常被分为以下三种经典类型。
1. 崩溃故障(Crash Failure):最“老实”的故障
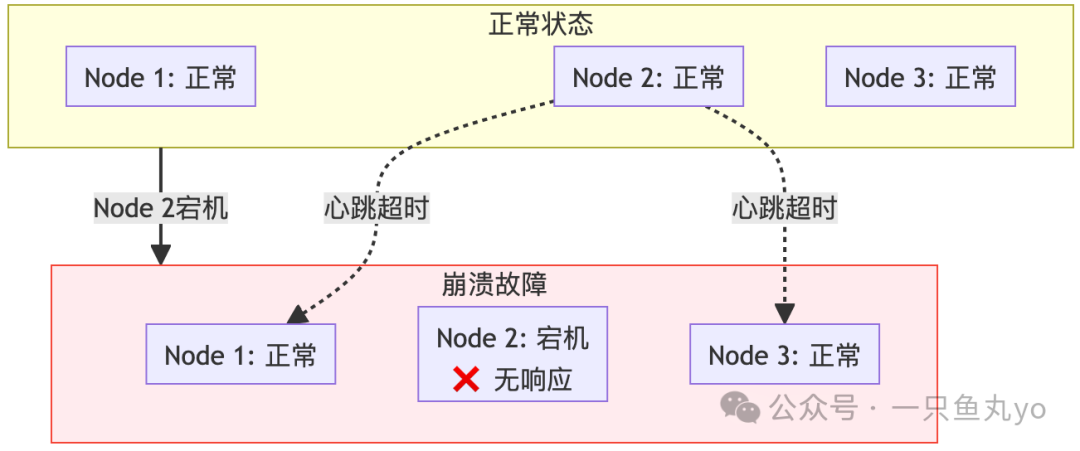
特点:
- 节点完全停止工作,不再发送任何消息。
- 不会发送错误或恶意信息。
- 这是最容易处理的故障类型。
现实案例:
- 服务器突然断电。
- 进程因内存溢出(OOM)被系统终止。
- 网线被拔掉,网络完全中断。
应对策略:超时检测 + 故障转移。通过心跳机制和超时判断节点是否存活,然后将流量切换到健康的备用节点。
2. 拜占庭故障(Byzantine Failure):最“狡猾”的故障
这个名字来源于著名的“拜占庭将军问题”——几位将军需要协同进攻,但其中可能有叛徒会发送互相矛盾的错误指令。
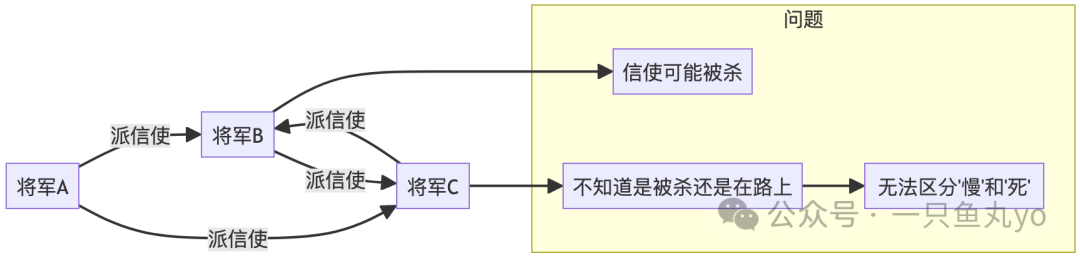
特点:
- 节点可能发送任意消息(错误、矛盾甚至恶意的)。
- 可能选择性响应某些请求,假装正常。
- 可能与其他故障节点串通作恶。
现实案例:
- 软件Bug导致内存数据被意外篡改。
- 硬件故障(如宇宙射线导致的内存位翻转)。
- 节点被黑客攻破,成为恶意攻击的一部分。
应对策略:
- PBFT(实用拜占庭容错算法):需要至少 3f + 1 个节点来容忍 f 个拜占庭节点,共识开销大。
- 区块链中的PoW/PoS:通过经济激励和算力/权益证明来抑制恶意行为。
- 核心认知:拜占庭容错的代价非常高昂,因此在绝大多数企业级内部系统中,我们默认节点是“非恶意的”(即只处理崩溃故障),以换取更高的性能。
3. 网络分区(Network Partition):最“常见”的故障
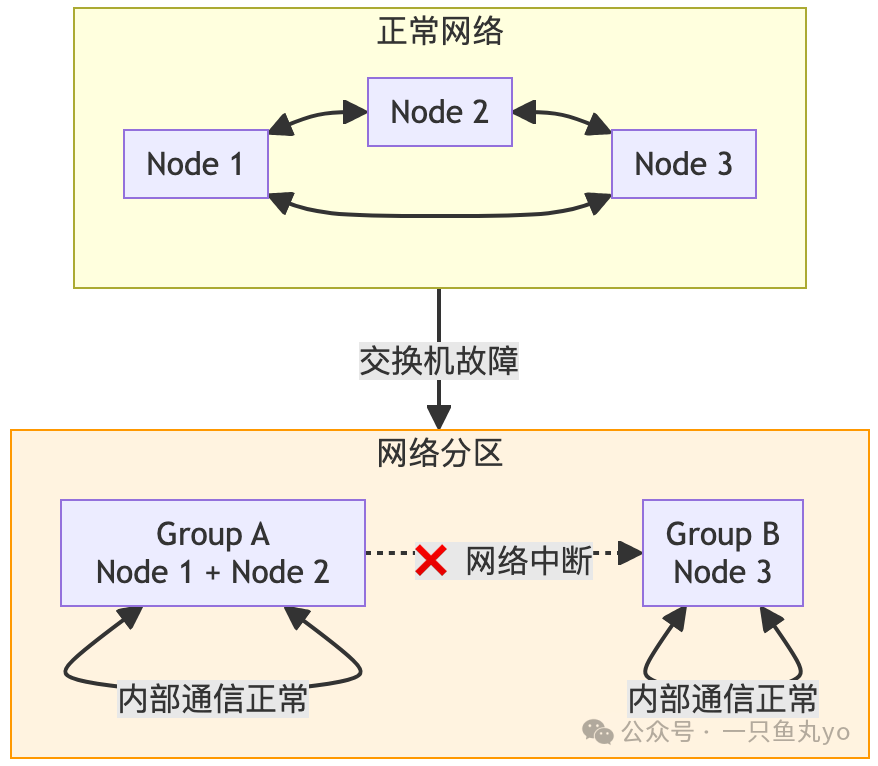
特点:
- 集群被分割成两个或多个无法通信的子集(Partition),子集内部通信正常。
- 这不是节点故障,而是网络故障。
- 根据CAP定理,此时系统必须在一致性(C)和可用性(A)之间做出痛苦抉择。
现实案例:
- 机房之间的光纤被施工挖断。
- 核心交换机配置错误或故障。
- 云服务商的某个可用区(Availability Zone)发生网络隔离。
应对策略:
- 多数派原则(Quorum):只有拥有多数节点的分区才能继续提供服务,防止“脑裂”导致数据不一致。
- 人工介入与降级:明确设计小分区(少数派)的自动降级策略,如变为只读,避免产生脏数据。
二、FLP不可能定理:分布式系统的“命运枷锁”
1985年,Fischer、Lynch和Paterson提出了著名的FLP不可能定理,它给所有分布式系统设计者上了一道“紧箍咒”:
在异步分布式系统中,即使只有一个进程可能发生崩溃故障,也无法设计出一个总能达成共识的完全正确的算法。
通俗解释:
就像那三位将军,他们依靠信使传递消息来决定是“进攻”还是“撤退”。但如果信使可能被截杀(消息丢失),你永远无法确定对方是“还没收到消息”还是“已经死了”。这个等待可能是无限的。
核心困境:
- 你无法可靠地区分“消息延迟”和“节点崩溃”。
- 系统可能为了等待一个永远不会到达的消息而永远阻塞。
工程启示:
- 放弃追求“完美”的容错,转向追求“实用”的容错。
- 必须引入超时机制来打破无限等待,这是工程现实的基石。
- 接受“概率性正确”和“最终一致性”,而非“绝对正确”。
三、超时:故障检测的“唯一可靠手段”
既然无法区分“慢”和“死”,那么在工程实践中,超时就成了我们检测故障唯一且必须依赖的手段。
超时机制的工作原理
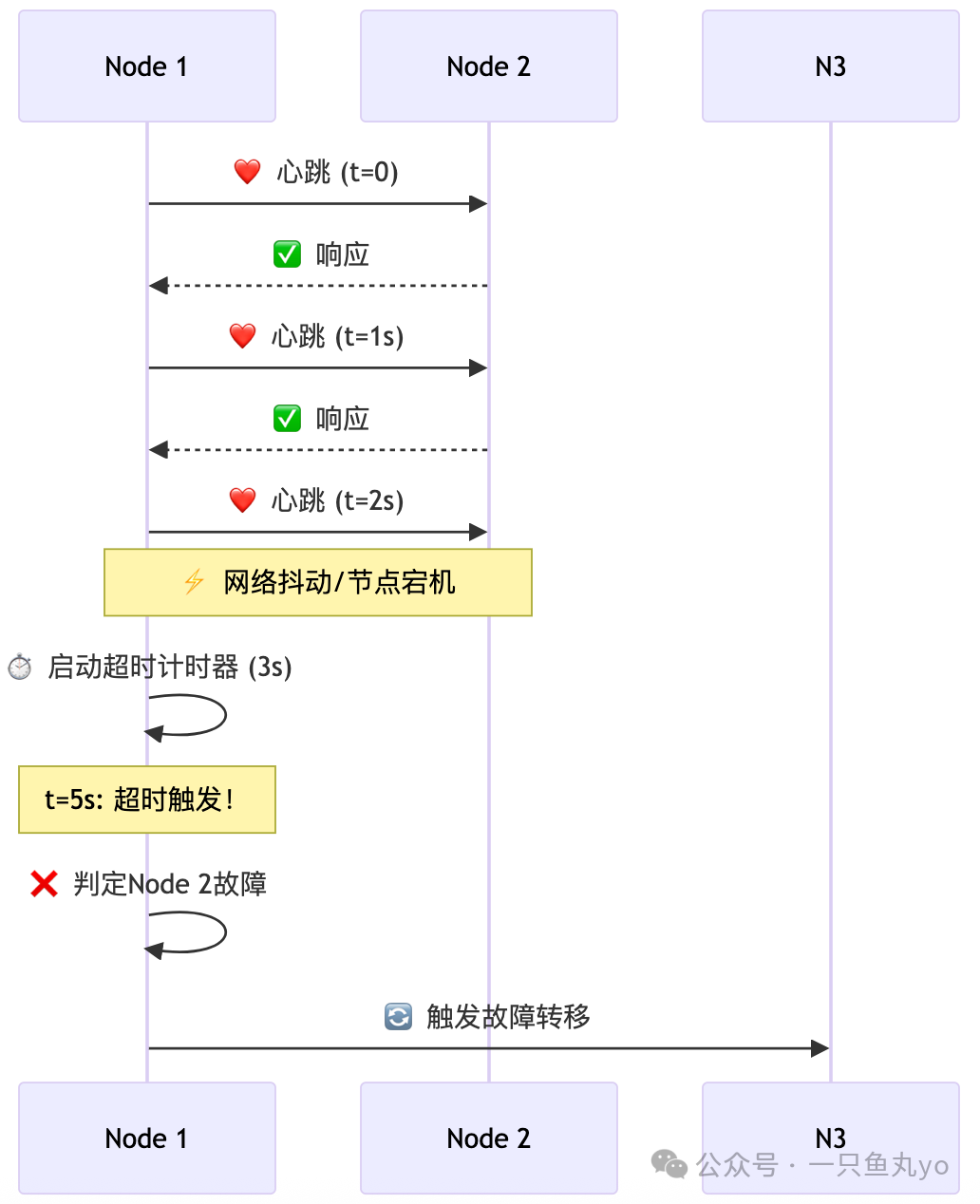
超时时间的设置是一门艺术:
- 太短:导致“误杀”(假阳性)。节点只是暂时慢了一下就被判定死亡,引发不必要的故障转移,可能加剧系统负载。
- 太长:故障检测迟钝(假阴性)。系统需要很长时间才能发现故障,导致恢复时间(RTO)变长,影响可用性。
- 最佳实践:基于历史延迟的P99或P999分位数动态调整。一个常见的经验值是设置为“平均延迟的3到5倍”。
超时的局限性:
- 它根本性地无法区分节点是“响应慢”还是“已死亡”。
- 在网络分区时,健康节点可能因无法通信而被误判为故障。
- 因此,超时常需要与租约(Lease)、世代号(Generation) 等机制结合,以提高状态判断的准确性。
四、构建韧性系统:冗余 + 重试 + 熔断
容错不是单点技术,而是一套组合策略。冗余、智能重试和熔断三者协同,才能编织出真正的韧性之网。
1. 冗余:不要把鸡蛋放在一个篮子里
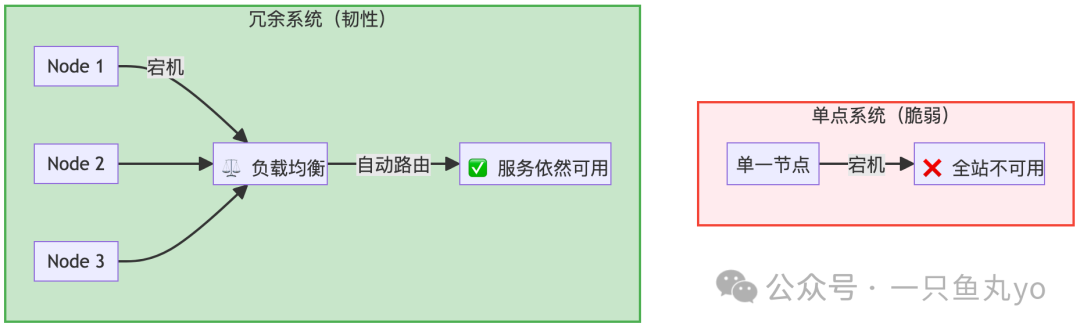
冗余的层次:
- 数据冗余:多副本存储,如Redis的主从复制、HDFS/数据库的3副本。
- 计算冗余:无状态服务多实例部署,通过负载均衡分散流量。
- 网络冗余:多线路、多运营商接入,避免单点网络故障。
- 机房/地域冗余:跨可用区(AZ)、跨地域(Region)部署,防范机房级灾难。
2. 重试:给系统“第二次机会”
重试不能是盲目的,必须是智能的、有策略的。
| 重试策略 |
适用场景 |
关键点 |
| 立即重试 |
瞬时故障(如偶发网络抖动) |
严格限制次数(如1-2次),防止加剧对方压力 |
| 指数退避 |
服务暂时过载 |
延迟时间 = 基数 × (2^重试次数),给服务恢复时间 |
| 随机抖动 |
避免重试风暴 |
在退避时间上增加一个随机值,打散客户端重试峰值 |
| 熔断保护 |
下游服务持续失败 |
与熔断器结合,失败率过高时停止重试,快速失败 |
重试的黄金法则:
- ✅ 只重试幂等操作:如GET查询、基于唯一ID的更新。对于数据库写入等操作,需设计幂等性。
- ✅ 限制重试次数和总耗时:通常3-5次,避免无限重试占用资源。
- ✅ 结合退避与抖动:这是防止“重试风暴”压垮下游服务的标准姿势。
- ❌ 不要重试非幂等操作:如“创建订单”、“支付”等,可能导致重复创建。
3. 熔断:系统的“自我保护机制”
熔断器模式模仿电路保险丝:当电流(请求失败率)过高时,自动熔断以保护整个电路(系统),防止故障蔓延引发雪崩。
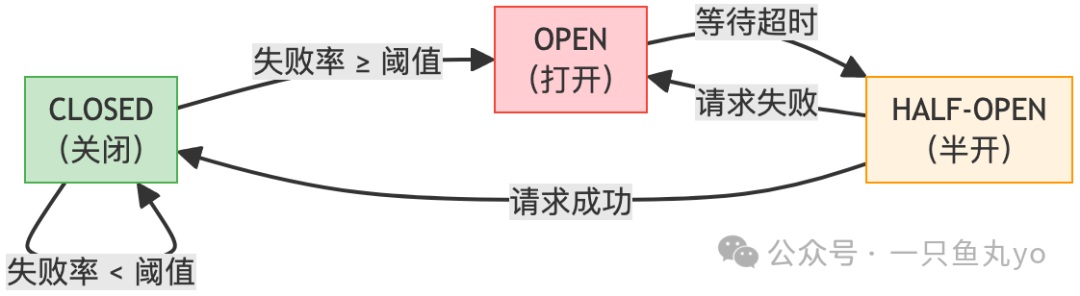
熔断三态:
- CLOSED(关闭):正常状态,请求直接通过。持续监控失败率。
- OPEN(打开):熔断状态,所有请求快速失败(Fail Fast),不再调用下游。经过一个预设的休眠时间后,进入半开状态。
- HALF-OPEN(半开):试探状态。允许少量试探请求通过。如果成功,则关闭熔断器,恢复链路;如果失败,则重回打开状态。
五、Chaos Engineering:主动“找茬”的艺术
等待故障上门太被动。混沌工程(Chaos Engineering) 主张:在可控范围内,主动向系统注入故障,以验证其韧性是否符合预期,并提前发现隐患。
混沌工程四步法
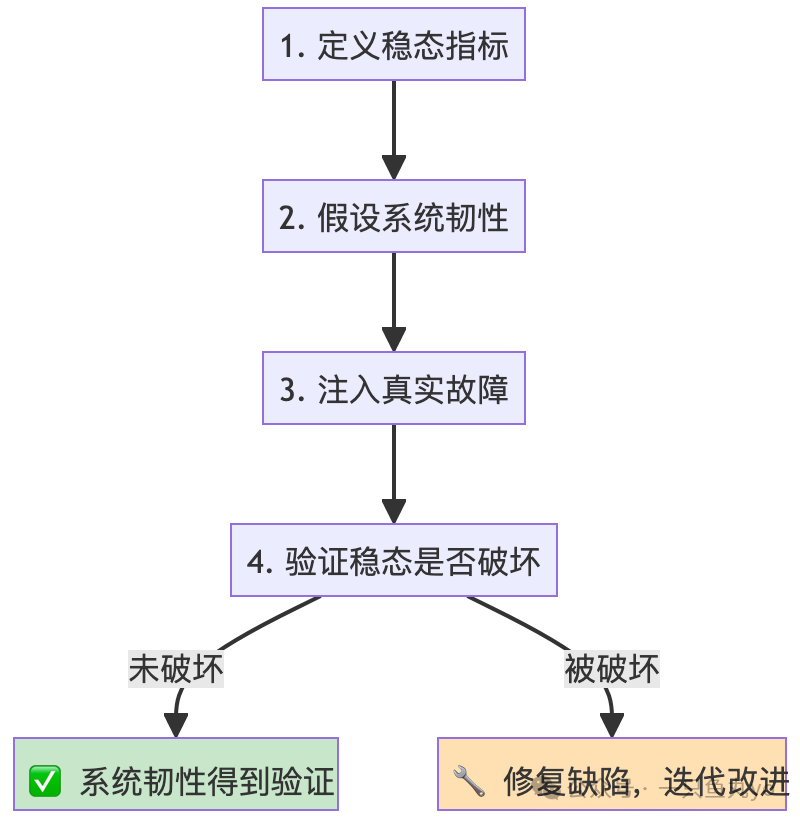
常见故障注入实验:
- 杀死节点/容器:随机终止服务实例,验证服务发现和故障转移是否生效。
- 注入网络延迟/丢包:模拟网络波动,验证超时、重试、熔断策略是否合理。
- 模拟资源压力:制造CPU、内存、磁盘IO高负载,验证服务的限流降级能力。
- 时钟偏移:篡改服务器时间,验证对时间敏感的业务逻辑是否健壮。
工具推荐:
- Chaos Mesh:云原生混沌工程平台,CNCF孵化项目, Kubernetes原生。
- Litmus:另一款Kubernetes原生的混沌工程框架。
- Gremlin:功能全面的商业化混沌工程平台。
核心原则(必须遵守):
- 🔬 在生产或类生产环境进行:但必须严格控制“爆炸半径”,从小范围开始。
- 📊 建立并监控稳态假设:明确注入故障后,系统哪些核心指标(如错误率、延迟)必须保持稳定。
- 🛑 具备快速中止和回滚能力:一旦出现问题,能立即停止实验并恢复。
- 📈 渐进式推进:从单个服务、单类故障开始,逐步扩大范围和复杂度。
六、容错设计的“心法口诀”
最后,让我们用几句口诀来总结分布式系统容错设计的核心思维。这不仅是技术,更是一种哲学:
故障是常态,不是例外
超时是唯一,不是选择
冗余是基础,不是奢侈
重试要智能,不是盲目
熔断是保护,不是放弃
混沌是验证,不是破坏
请记住,我们追求的高可用,从来不是虚幻的“零故障”,而是务实的“故障无感”。当你开始将故障视为系统设计与迭代中不可或缺的一环时,你的架构思维就从“被动救火”转向了“主动防御”。这才是构建健壮分布式系统的真正起点。 |  发表于 2026-4-2 11:36:03
|
查看: 180|
回复: 0
发表于 2026-4-2 11:36:03
|
查看: 180|
回复: 0
