视觉语言模型(VLM)的强化学习(RL)训练目前往往局限于几何题、图表分析等特定场景。这种领域上的局限,无疑制约了VLM更广泛能力的探索和提升。
那么,如何拓展VLM的强化学习训练领域呢?复旦大学自然语言处理实验室的研究团队提出的 Game-RL 给出了一个富有创意的答案。
该研究通过合成多模态的可验证游戏数据用于强化学习,成功激发了VLM的通用推理能力,并使其能够泛化到多个完全域外的通用测试基准上。更有趣的是,使用游戏数据进行训练的效果,竟然可以与专门针对几何图表的数据相匹敌。而且,扩展训练所使用的游戏种类和数据量,还能为模型带来持续的性能提升。
这些发现强烈暗示:在游戏环境中进行规模化(scale)的强化学习,很可能成为提升模型通用推理能力的一个重要方向。

论文标题:
Game-RL: Synthesizing Multimodal Verifiable Game Data to Boost VLMs' General Reasoning
论文链接:
https://arxiv.org/abs/2505.13886
项目网站:
https://iclr26-game-rl.github.io
代码仓库:
https://github.com/tongjingqi/Game-RL
数据和模型:
https://huggingface.co/collections/OpenMOSS-Team/game-rl
1. Game-RL:对VLM强化学习训练领域的重要拓展
电子游戏通常具备视觉元素丰富、规则明确且可验证的特点,这使其成为理想的多模态推理数据来源。基于此洞察,研究团队提出了 Game-RL —— 即构造多模态可验证的游戏任务来对VLM进行强化训练。下图展示了所合成的游戏数据中的几个代表性示例。

图1:GameQA 数据集中各游戏类别的代表性任务:3D 重建、七巧板(变体)、数独和推箱子。每个游戏展示两个视觉问答示例,包含当前游戏状态图片、相应问题,以及逐步推理过程和答案。
2. 从游戏代码到训练数据:Code2Logic方法的巧思
为了大规模获取高质量的训练数据,团队提出了一种新颖的 Code2Logic 方法。该方法通过游戏代码,系统化地、自动化地合成可验证的游戏任务数据。
如下图所示,整个流程利用强大的大语言模型(LLM)分三步完成:首先生成游戏代码,接着设计任务及其问答模板,最后构建数据引擎代码。完成后,只需执行这段数据引擎代码,便能自动、批量地生成训练数据,并且能够灵活控制样本的难度和生成的数据量。
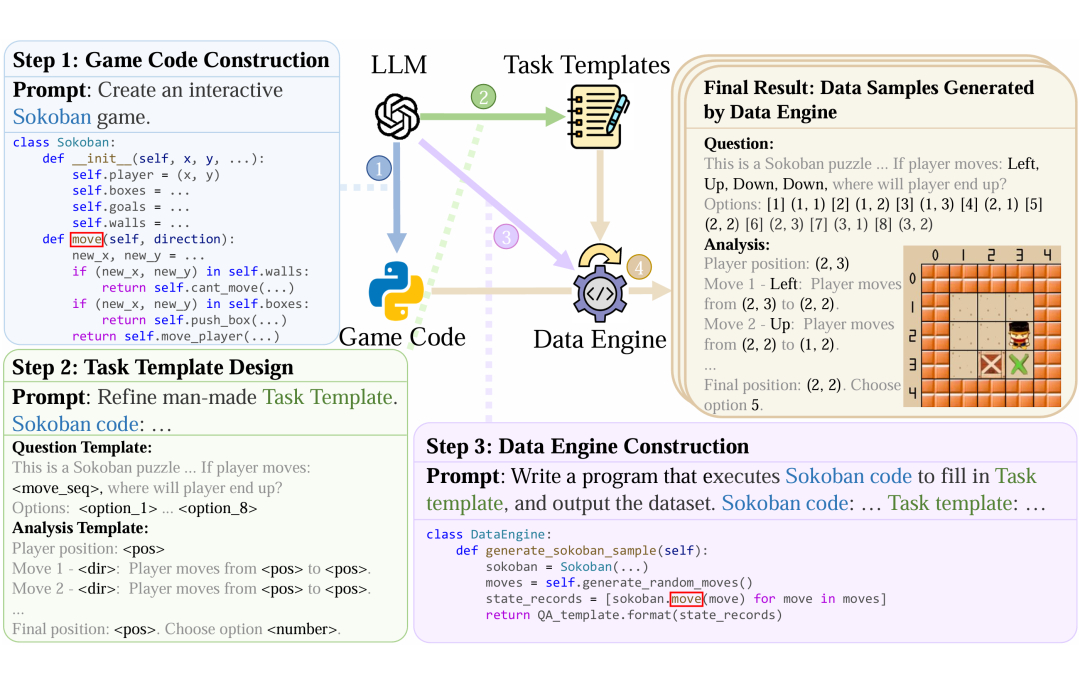
图2:Code2Logic 方法示意图。借助 LLM 通过三个核心步骤将游戏代码转换为推理数据:第一步:游戏代码构建;第二步:游戏任务及其 QA 模板设计;第三步:数据引擎构建。基于前两步构建自动化程序,执行代码即可自动批量生成数据。
3. GameQA:一个丰富的游戏任务数据集
利用上述 Code2Logic 方法构建的 GameQA 数据集,不仅能够用于评测VLM的推理能力,更可作为多模态可验证的游戏任务数据来强化训练VLM。
GameQA 数据集规模可观,包含:
- 4大认知能力类别(如3D空间推理、策略规划等)。
- 30个不同的游戏。
- 158种推理任务。
- 超过14万个高质量的问答对。
此外,数据还进行了精细分级:任务按推理难度分为三级;样本则按视觉输入的复杂度分为三级。
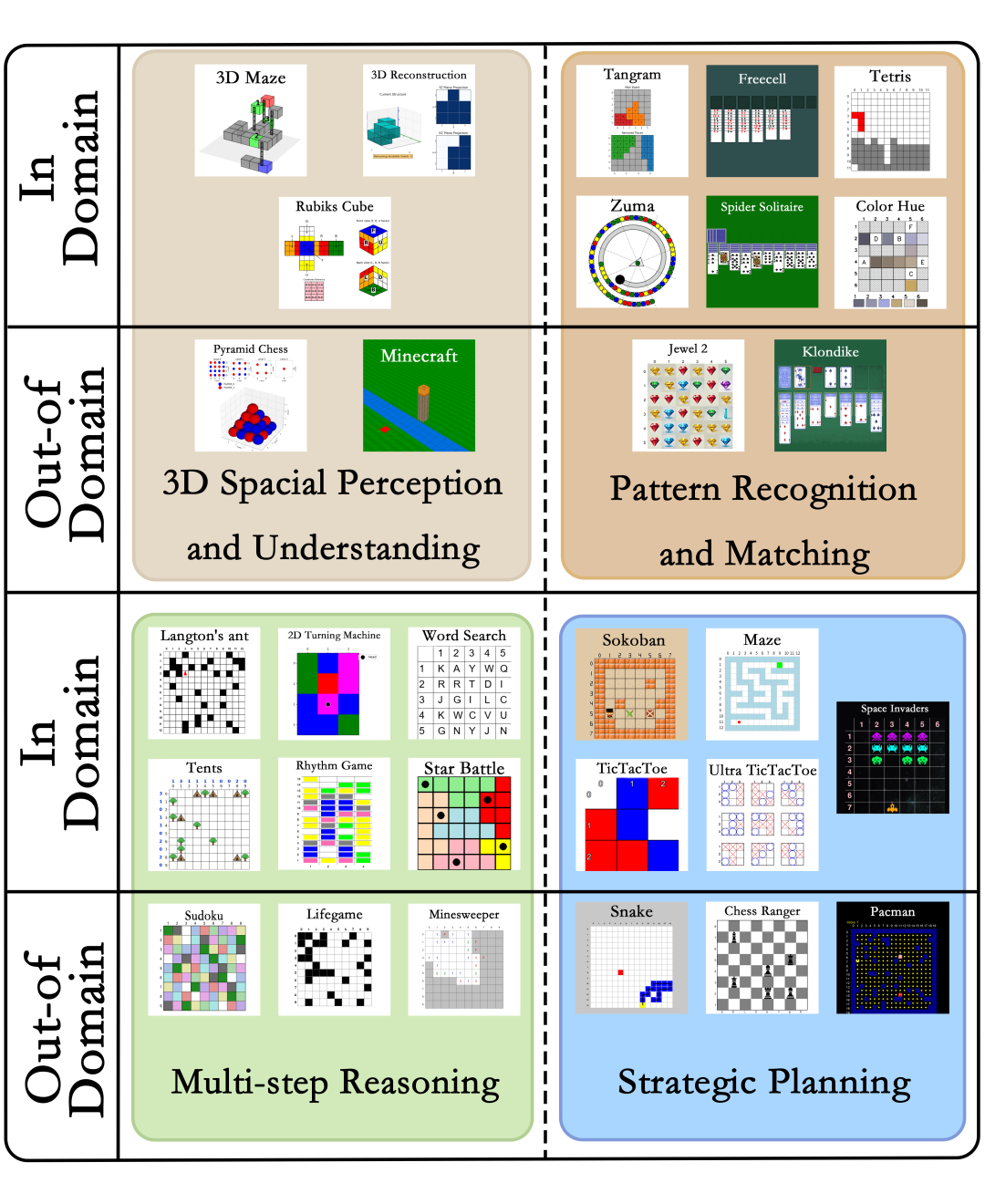
图3:GameQA 包含的 30 个游戏,分为 4 个认知能力类别。其中20个域内游戏用于训练和测试,而10个域外游戏不参与训练,专门用于测试模型在未见游戏场景下的泛化能力。
4. 核心发现一:Game-RL带来了可泛化的通用推理能力提升
研究团队使用 GRPO(Group Relative Policy Optimization)方法在 GameQA 数据集上对多个开源VLM进行训练。结果显示,经过训练的模型在 7个完全域外的通用视觉语言推理基准(如 MathVista, MMBench, MMMU 等)上均取得了显著提升。以 Qwen2.5-VL-7B 模型为例,其平均性能提升了 2.33%。这充分证明了 Game-RL 训练方法具备优秀的跨领域泛化能力。
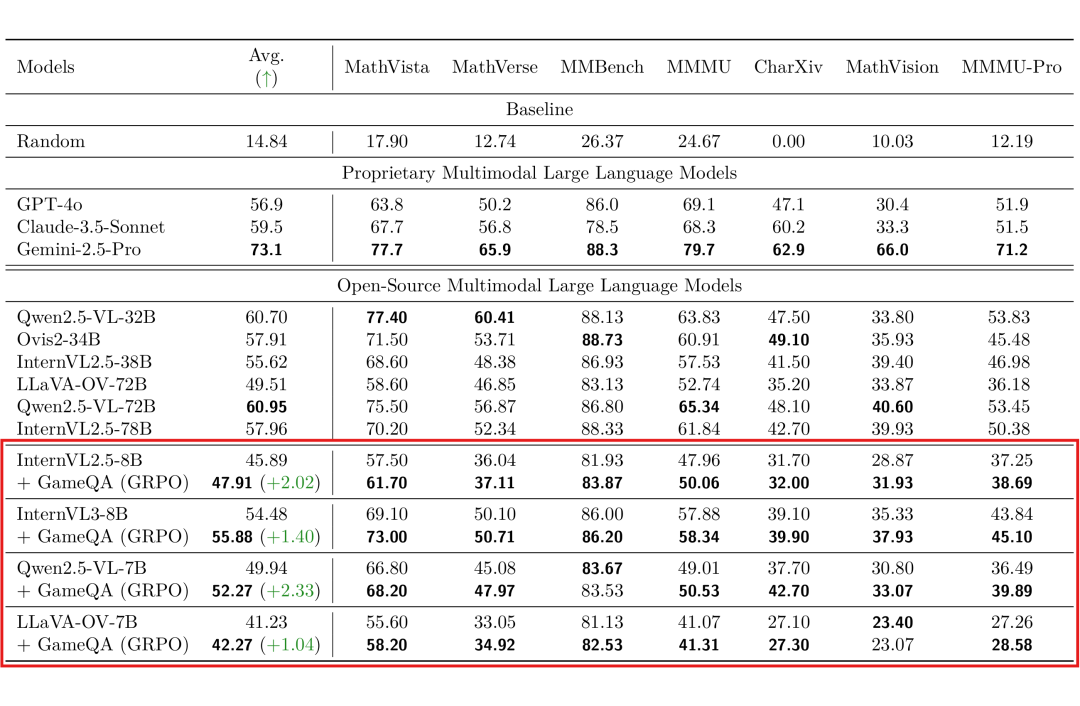
表1:在通用视觉语言推理基准上的评测结果。经过 GameQA (GRPO) 训练后,多个开源VLM模型(如 InternVL2.5-8B, Qwen2.5-VL-7B)在多个基准上均显示出性能提升(+X.XX)。
5. 核心发现二:游戏数据训练效果竟匹敌几何数据
为了评估游戏数据的“竞争力”,研究团队将其与专门的几何与图表推理数据集进行了对比训练实验。令人惊讶的是,GameQA 数据训练出的模型表现,完全可以与后者相匹敌。
如下表所示,尽管 GameQA 的训练数据量更少,且与测试基准的领域不完全匹配,但其训练出的模型在通用基准上的总体表现极具竞争力。更引人注目的是,在 MathVista 与 MathVerse 这两个与几何、函数推理高度相关的基准上,Game-RL 训练带来的提升甚至超过了使用更“对口”的几何数据进行的训练。
这一发现表明,游戏中蕴含的认知多样性和复杂的推理过程,具有强大的通用性和迁移能力。
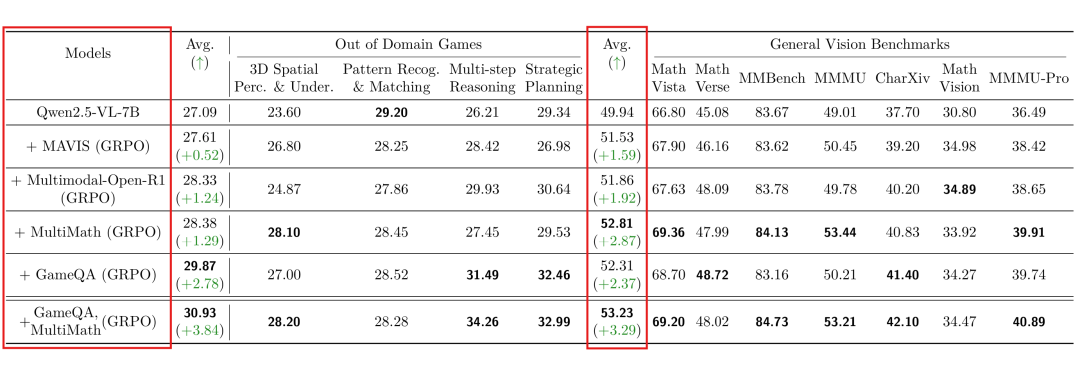
表2:不同训练数据的对比实验。使用5K GameQA样本训练的模型,其表现与使用8K其他多模态推理数据(如MAVIS, MultiMath)训练的模型相当甚至更好。实验还显示,将GameQA数据与MultiMath数据混合训练,能带来进一步的性能提升。
6. 核心发现三:训练数据量和游戏个数的扩展效应(Scaling Effect)
研究进一步探索了规模扩展的影响:
- 数据量的扩展效应:将训练的 GameQA 数据量增加至 20K,实验显示模型在通用推理基准上的表现总体呈持续提升趋势。
- 游戏个数的扩展效应:随着训练所使用的游戏种类增多,模型在域外任务上的泛化效果也相应增强。使用20种游戏进行训练,其提升效果明显优于仅使用4种游戏的配置。
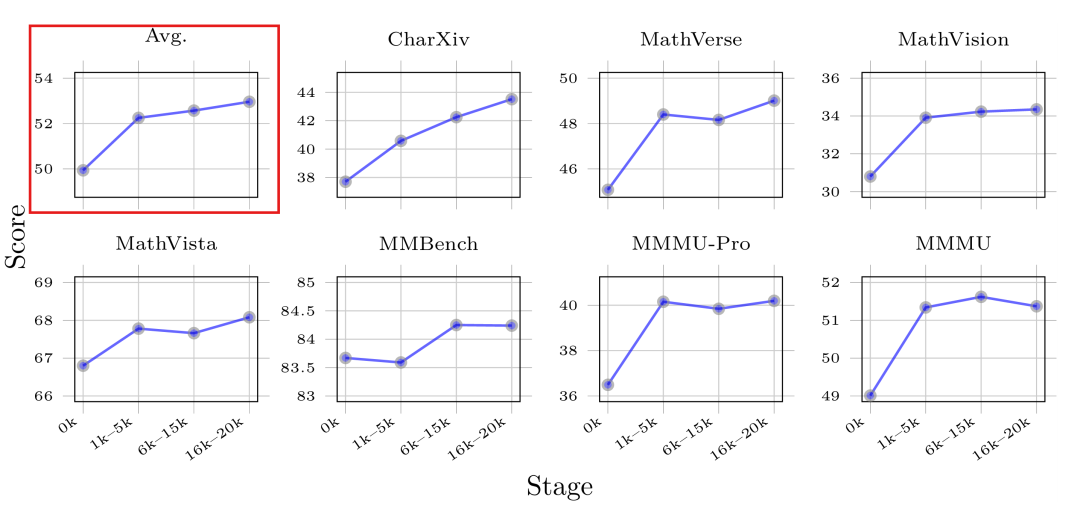
图4:训练数据量的 Scaling Effect。随着训练阶段推进(数据量增加),模型在多个基准上的得分总体呈上升趋势。
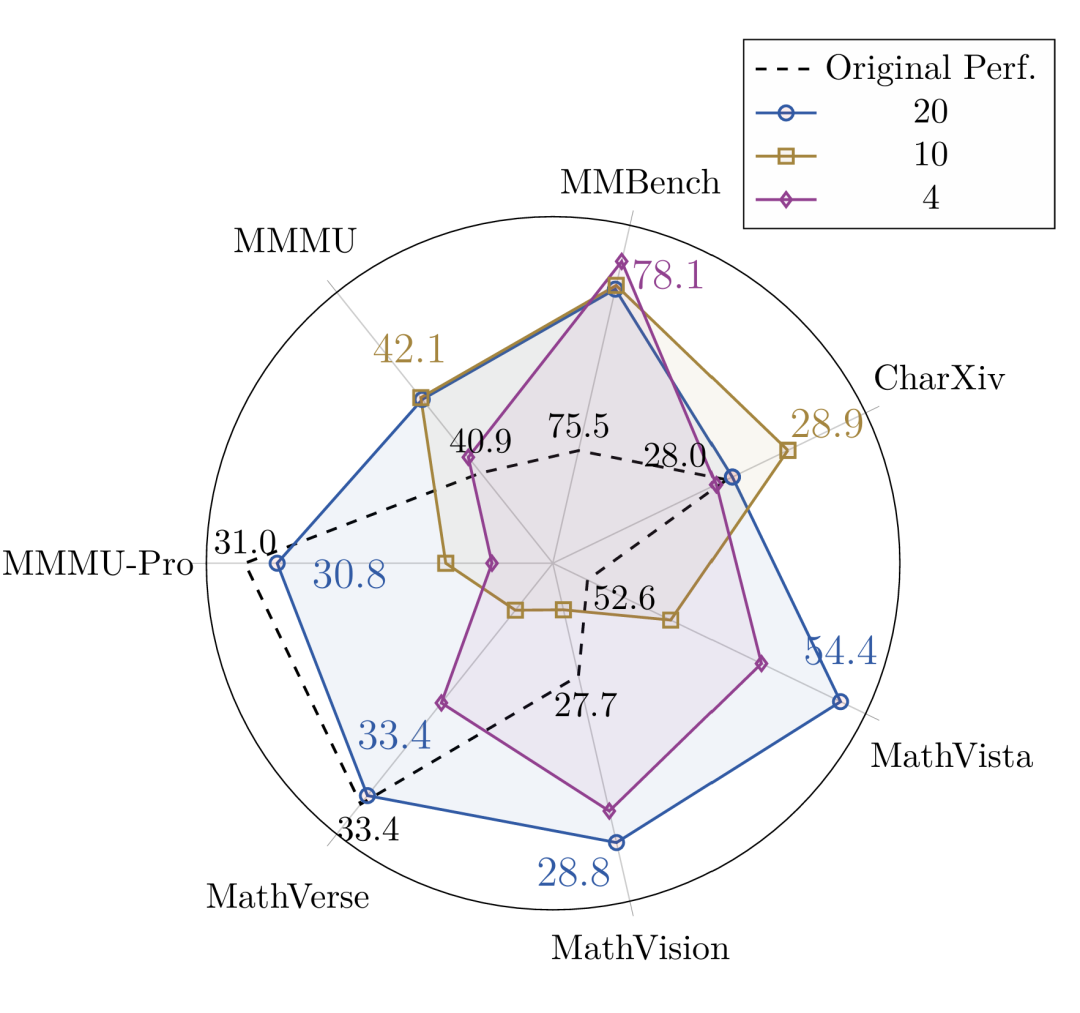
图5:游戏个数的 Scaling Effect。使用20种游戏(蓝色线)的任务进行训练,模型在域外通用基准上的提升幅度,普遍优于仅使用4种游戏(紫色线)的配置。
7. 深度剖析:Game-RL具体提升了模型的哪些能力?
为了更好地理解 Game-RL 究竟如何提升VLM的推理能力,研究团队进行了细致的案例人工分析。结果显示,经过 Game-RL 训练后,模型在视觉感知和文本逻辑推理两个方面均获得了提升。
例如,在下图展示的案例中,训练后的模型能够更准确地从图表中提取关键信息(红色虚线代表的数据序列始终维持在最高值),并做出正确的推理判断,而训练前的模型则出现了明显的感知和推理错误。
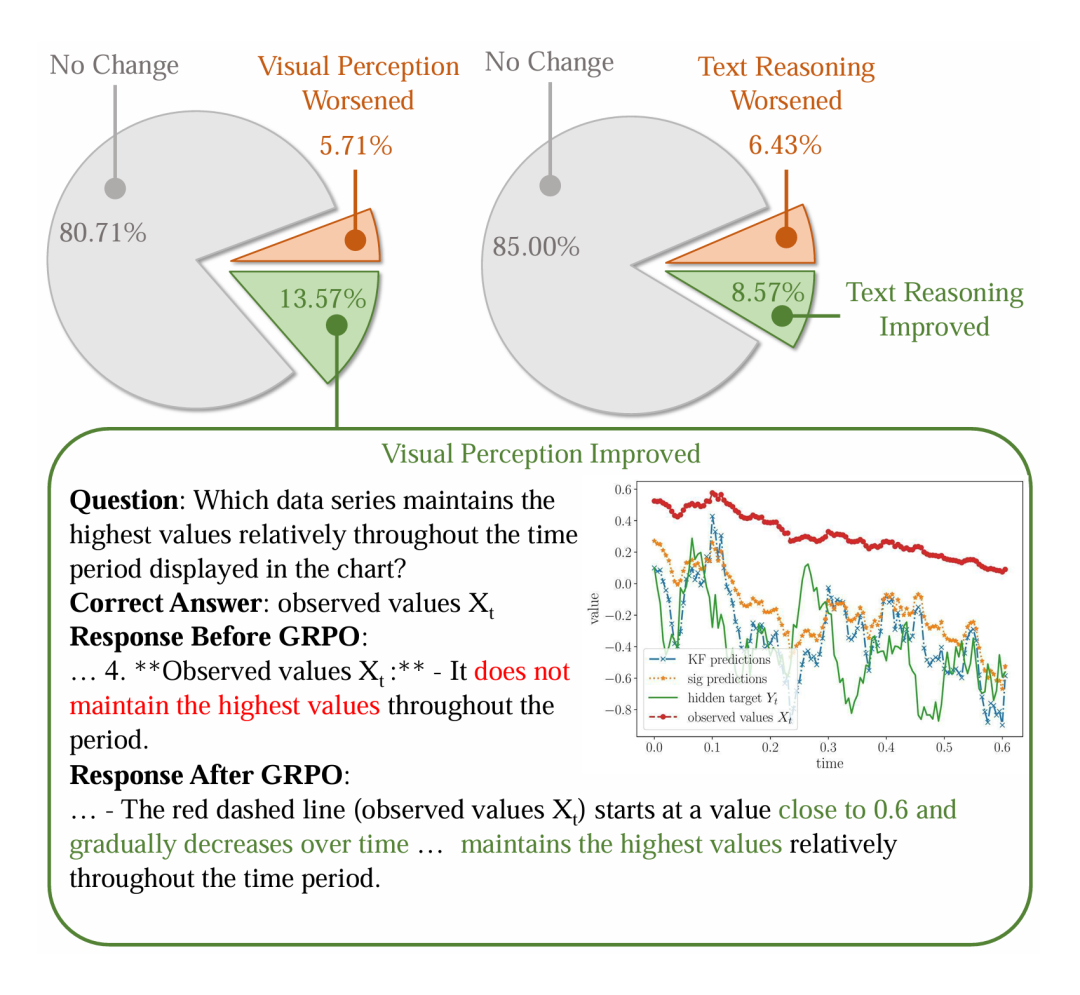
图6:人工定性分析结果。上方饼图显示,在域外基准上,多数样本的视觉感知和文本推理能力保持不变或得到改善。下方是一个具体案例,展示了训练后模型视觉感知能力的提升:能够正确识别图表中“observed values X_t”数据序列始终保持相对最高值。
8. 结论与展望
本研究提出了 Game-RL 框架以及可验证游戏数据合成方法 Code2Logic,并构建了大规模的 GameQA 数据集,成功将VLM的强化学习训练领域拓展至丰富多样的游戏场景。
实验充分证明,Game-RL 能够有效提升VLM的、可泛化的通用推理能力。游戏数据作为一种优质的多模态训练数据源,其训练效果可与传统的几何图表数据相媲美,并且展现出良好的规模扩展效应。
这些结论为未来人工智能的研究指明了新的可能性:在游戏环境中进行规模化的强化学习,是提升模型通用推理能力一个极具潜力的重要方向。对于致力于AI前沿探索的开发者而言,这项研究无疑提供了宝贵的思路和工具。我们也可以在 云栈社区 等开发者平台上继续关注和讨论此类技术的后续发展与应用。
 发表于 2026-4-2 12:09:51
|
查看: 192|
回复: 0
发表于 2026-4-2 12:09:51
|
查看: 192|
回复: 0
