在准备后端面试时,Redis主从复制是一个绕不开的核心考点。理解其原理,不仅能帮助你从容应对面试,更能深入理解分布式数据存储中的数据同步思想。本文将带你掌握Redis持久化机制、主从复制的核心原理以及具体的配置方法。
我们都知道Redis是一个内存数据库。在学习主从同步之前,首先要理解Redis是如何将内存中的数据持久化到磁盘的,这是实现主从数据同步的基础。
Redis持久化
为了确保数据不因进程退出而丢失,Redis提供了两种持久化方案:RDB和AOF。
RDB方式(默认)
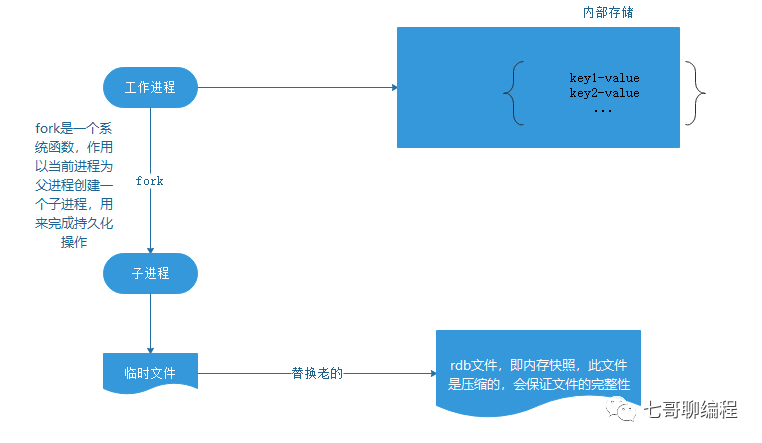
RDB(Redis Database)通过生成内存数据的快照(snapshot)来实现持久化。当满足特定条件时,Redis会自动触发快照并将数据保存到硬盘。
触发快照的时机
- 符合
redis.conf中自定义的快照规则。
- 执行
save 或 bgsave 命令。
- 执行
flushall 命令。
- 首次执行主从复制操作。
原理图
设置快照规则
快照规则在redis.conf文件中配置,以下是一个典型的配置片段:
# Save the DB on disk:
# 下面的配置分别表示:
# 900秒内至少1个键被修改则进行快照
# 300秒内至少10个键被修改则进行快照
# 60秒内至少10000个键被修改则进行快照
save 900 1
save 300 10
save 60 10000
注意事项
- Redis生成快照时不会修改现有的RDB文件,只有在新快照完成后才会原子性地替换旧文件,保证了文件在任何时刻的完整性。
- RDB文件是经过压缩的二进制格式,体积通常小于内存中的数据,便于传输和备份。
RDB优缺点
- 缺点:最明显的问题是可能丢失最后一次快照之后的所有数据修改。需要通过合理设置快照条件来平衡数据安全性和性能。
- 优点:性能最大化。父进程只需
fork一个子进程来处理磁盘I/O,自身可以继续提供服务。当然,如果数据集非常大,fork过程本身可能会比较耗时,导致服务短暂停顿。
AOF方式
默认情况下AOF(Append Only File)持久化是关闭的。开启后,Redis会将每一个写命令追加到文件末尾,从而在重启时通过重新执行这些命令来恢复数据。
开启AOF持久化
修改redis.conf文件中的以下配置:
appendonly yes # 开启AOF
appendfilename “appendonly.aof” # 持久化文件名
dir ./ # 文件所在目录
原理
首先需要了解RESP(Redis Serialization Protocol),这是Redis客户端与服务端通信的序列化协议。
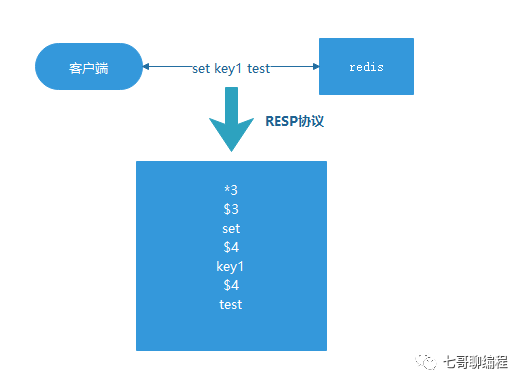
AOF文件中存储的就是经过RESP序列化后的Redis命令。与RDB类似,AOF的写入也通过fork子进程来处理。
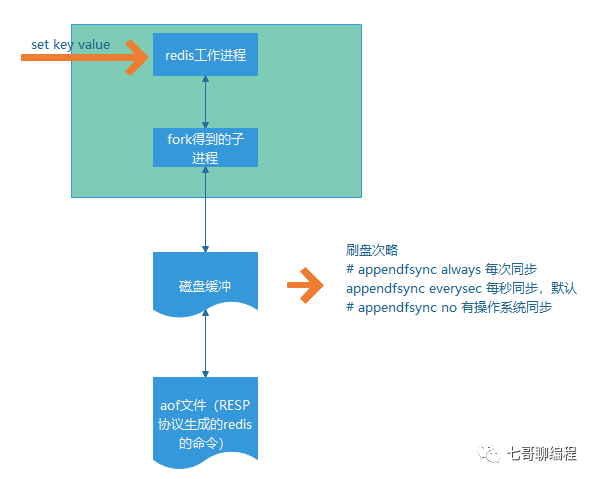
直接记录所有写命令会导致AOF文件迅速膨胀,例如同一个key被多次修改。为此,Redis提供了AOF重写机制来优化文件大小。
AOF重写
例如执行:
set s1 11
set s1 22
优化后,AOF文件中只会保留最终命令 set s1 22。
重写过程是定期创建一个新的AOF文件。在创建过程中,新的写命令会同时追加到旧AOF文件和新AOF文件的缓冲区。一旦新文件创建完成,Redis就会切换到新文件并开始向其追加命令。这个过程保证了即使在重写时发生故障,旧AOF文件仍然完整。
触发重写的条件
在redis.conf中配置:
# 当当前AOF文件大小比上次重写后的AOF文件大小增长超过100%时,触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积大于64MB时,才考虑重写
auto-aof-rewrite-min-size 64mb
如何选择RDB和AOF
这是一个常见的面试题,你可以根据场景进行选择:
- 数据绝对不能丢:结合使用RDB和AOF。
- 纯缓存服务器:使用RDB即可。
- 不建议单独使用AOF,因为恢复速度可能较慢。
- 恢复数据时:优先使用AOF文件恢复(数据更完整),如果没有AOF则使用RDB文件。
Redis主从复制
什么是主从复制?
简单概括就是:主库(Master)可读可写,从库(Slave)只读。主库负责接收写操作,并将数据变化同步到一个或多个从库,从而提升读并发能力和数据可靠性。但需要注意,在主从架构中,如果主库宕机,从库不会自动升级为主库,写服务会中断。
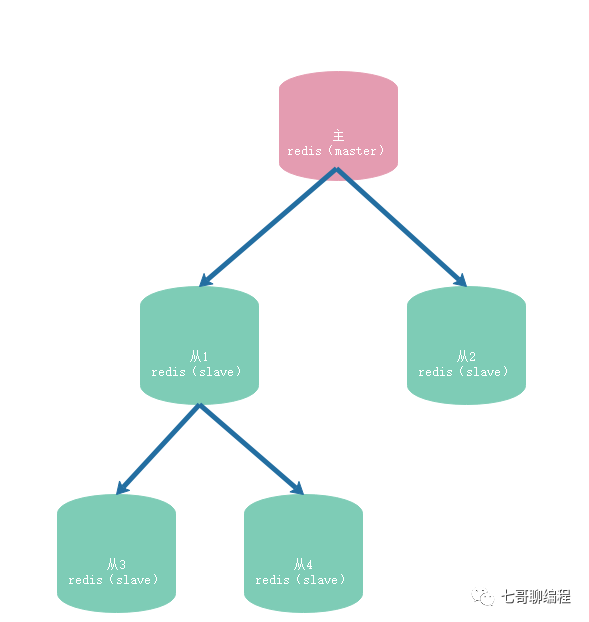
生产环境通常会采用哨兵(Sentinel) 或 Redis Cluster 等具备自动故障转移的高可用性方案,但理解基础的主从原理是深入这些高级方案的前提。
主从配置实战
配置非常简单:
实现原理(PSYNC命令)
Redis 2.8版本后使用PSYNC命令替代早期的SYNC命令。PSYNC支持两种同步模式:
- 全量同步:用于初次复制,主库生成并发送RDB快照文件,同时缓冲快照期间的新写命令,一并发送给从库。
- 部分同步:用于断线重连后的复制。如果条件允许,主库只需发送从库断开期间缺失的写命令即可。

那么,Redis如何智能地判断该用全量还是部分同步呢?这依赖于三个核心概念。
部分同步的三个基石
-
复制偏移量
主从双方各自维护一个偏移量(offset)。主库每次向从库传播N字节数据,自身offset加N;从库每次收到N字节数据,自身offset也加N。通过对比主从offset,可以判断数据是否一致。
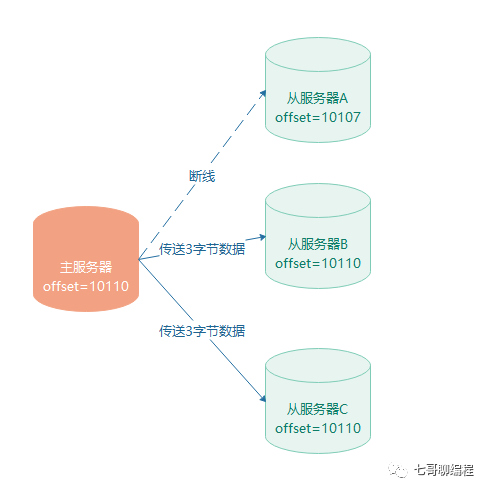
-
复制积压缓冲区
这是主库维护的一个固定大小的FIFO队列。主库传播写命令时,不仅发给从库,还会入队到这个缓冲区,并记录每个字节对应的offset。
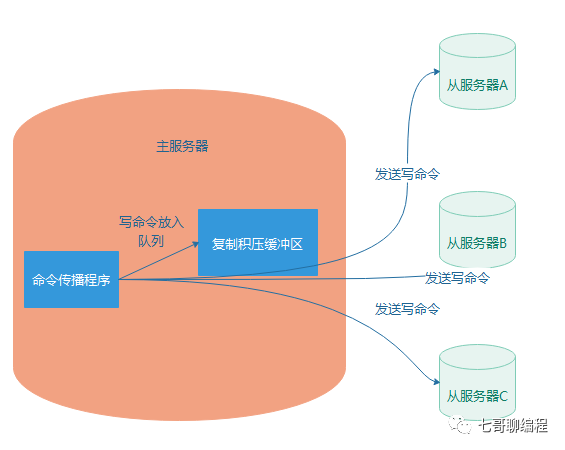

当从库重连并上报自己的offset后,主库检查该offset之后的数据是否还在缓冲区:
- 如果在,则执行部分同步,发送缺失的数据。
- 如果不在(缓冲区已被新数据覆盖),则执行全量同步。
缓冲区大小设置公式:大小 = 2 * (断线平均重连时间(秒) * 主库平均每秒写命令数据量)。通过配置文件中的 repl-backlog-size 选项调整。
-
服务器运行ID
每个Redis实例启动时都会生成一个唯一的40位十六进制运行ID(Run ID)。从库首次复制主库时,会保存主库的Run ID。断线重连后,从库会将之前保存的Run ID发送给当前连接的主库:
- ID相同,说明之前复制的是同一个主库,可尝试部分同步。
- ID不同,说明连接到了新的主库,必须进行全量同步。
PSYNC命令的执行流程
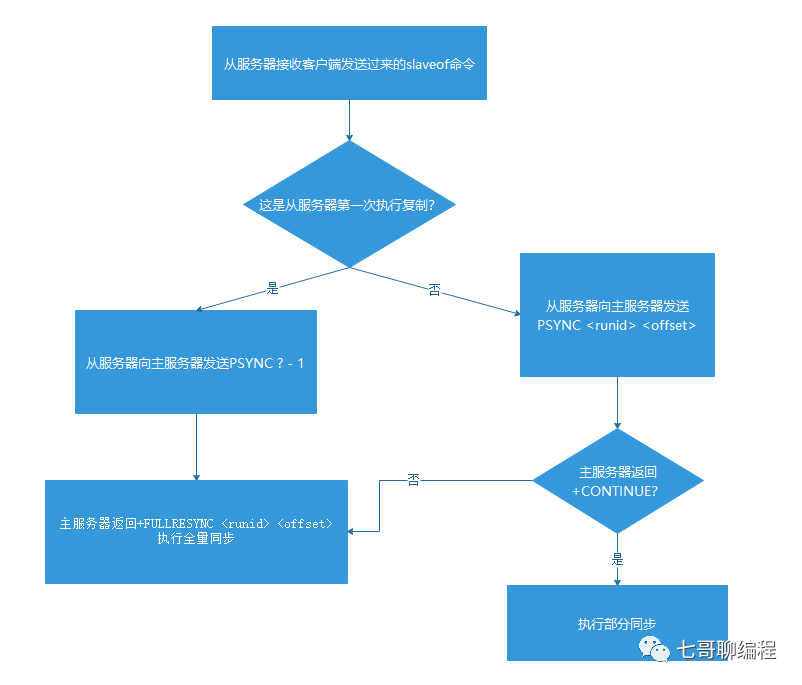
- 从库初次复制,发送
PSYNC ? -1,请求全量同步。
- 从库非初次复制,发送
PSYNC <runid> <offset>。
- 主库根据runid和offset判断,回复
+FULLRESYNC(全量同步)、+CONTINUE(部分同步)或 -ERR(旧版Redis,降级为SYNC)。
全量同步与命令传播
全量同步并非简单地发送一个RDB文件就结束,它是一个严谨的三阶段过程:
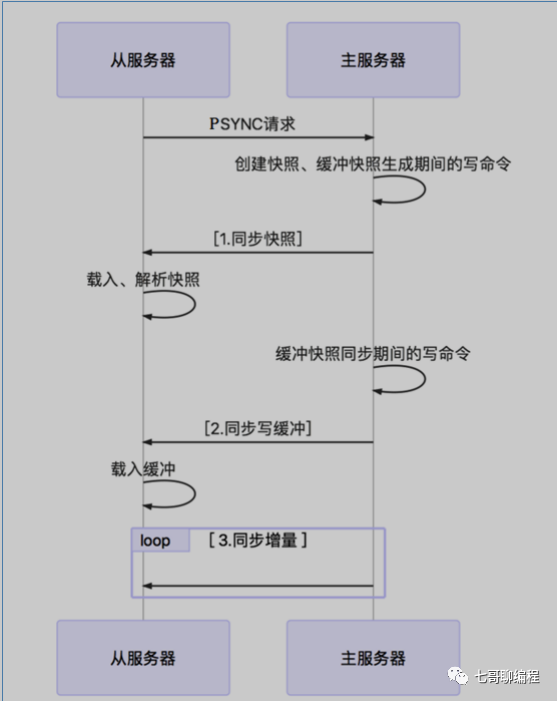
- 同步快照阶段:主库
bgsave生成RDB快照并发送给从库,同时将生成快照期间的新写命令存入缓冲区。
- 同步写缓冲阶段:主库将缓冲区中积压的写命令发送给从库。
- 同步增量阶段(命令传播):之后主库每执行一个写命令,都会异步地发送给从库,进入持续的增量同步状态。

总结
Redis基础主从复制架构虽然不具备自动故障转移能力,但它是理解更高级分布式系统数据同步方案(如哨兵、集群)的基石。其核心在于通过复制偏移量、积压缓冲区和运行ID三者协作,在断线重连时尽可能地采用高效的部分同步,而非每次都进行成本高昂的全量同步。深入掌握这一机制,对构建和优化数据密集型应用大有裨益。
 发表于 2026-4-4 05:51:00
|
查看: 156|
回复: 0
发表于 2026-4-4 05:51:00
|
查看: 156|
回复: 0
