大家好,我是小林。
《图解 Redis》系列文章已持续更新多期,考虑到不少同学正在突击面试,我将核心内容系统梳理为一份聚焦实战、兼顾深度的 Redis 八股文合集:全文共 3 万字 + 40 张原创原理图,覆盖 40+ 高频面试问题,从基础认知到高阶原理层层展开,助你建立完整知识图谱。
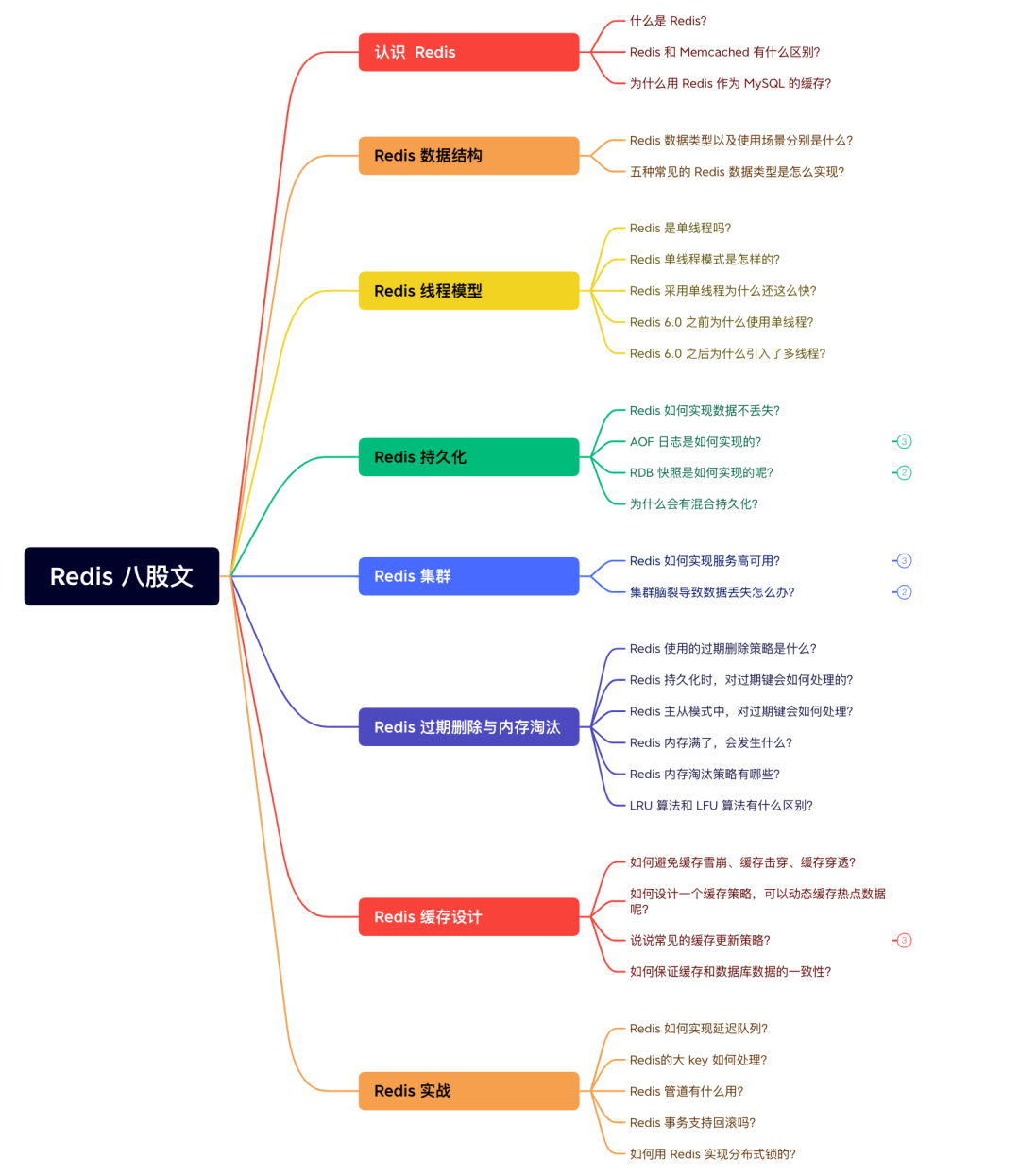
Redis 八股文知识体系导图:涵盖认识 Redis、数据结构、线程模型、持久化、集群、过期淘汰、缓存设计、实战场景八大模块
认识 Redis
什么是 Redis?
我们直接看 Redis 官方介绍:

Redis 是一个开源(BSD 许可)的内存数据结构存储,用作数据库、缓存、消息代理和流引擎。它提供多种数据结构,例如:
- 字符串(String)、散列(Hash)、列表(List)、集合(Set)、有序集合(ZSet)
- 位图(Bitmaps)、超日志(HyperLogLog)、地理空间索引(GEO)、流(Stream)
Redis 内置了复制、Lua 脚本、LRU 驱逐、事务和不同级别的磁盘持久性,并通过 Redis Sentinel 和 Redis Cluster 提供高可用方案。
关键特性提炼如下:
- 读写极快:所有操作在内存中完成,常用于缓存、消息队列、分布式锁等场景;
- 原子操作:对各类数据结构的操作均为原子性(由单线程保障,无并发竞争);
- 功能丰富:支持事务、持久化、Lua 脚本、发布/订阅、集群、内存淘汰、过期删除等;
- 多用途定位:既是高性能缓存,也是轻量级数据库与消息中间件。
✅ 延伸阅读:数据库/中间件/技术栈 —— 深入对比 Redis、MySQL、Kafka、RabbitMQ 等主流中间件选型逻辑。
Redis 和 Memcached 有什么区别?
两者都是基于内存的 KV 存储,但设计目标与能力差异显著:
| 维度 |
Redis |
Memcached |
| 数据类型 |
String、Hash、List、Set、ZSet、Bitmap、GEO、Stream 等 |
仅支持简单 key-value |
| 持久化 |
支持 RDB 快照、AOF 日志、混合持久化 |
无持久化,纯内存存储,重启即丢数据 |
| 集群支持 |
原生支持 Redis Cluster(分片集群)、Sentinel(高可用) |
无原生集群,依赖客户端分片(如 Twemproxy) |
| 高级功能 |
支持事务、Lua 脚本、发布/订阅、布隆过滤器、延迟队列等 |
仅基础增删改查,无扩展能力 |
小结:Memcached 是“极简缓存”,Redis 是“全能型内存平台”。在现代微服务架构中,Redis 已成为事实标准缓存中间件。
为什么用 Redis 作为 MySQL 的缓存?
核心原因在于 Redis 同时具备「高性能」与「高并发」两大优势:
1. Redis 具备高性能
用户首次访问 MySQL 数据较慢(需磁盘 I/O),若将结果缓存至 Redis,后续请求可直接命中内存,毫秒级响应:
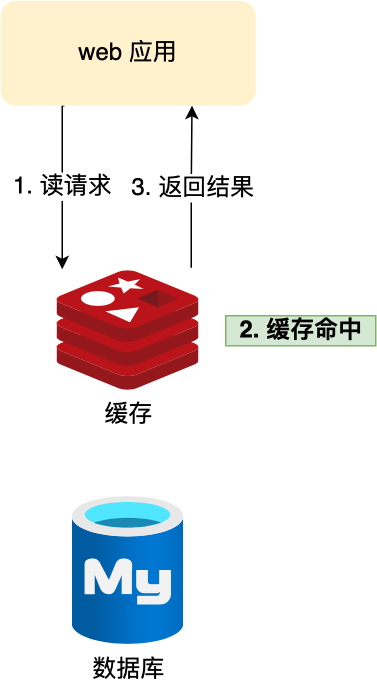
缓存命中路径:Web 应用 → 缓存 → 返回结果;未命中则穿透至数据库
⚠️ 注意:当 MySQL 数据变更时,需同步更新或失效 Redis 缓存,否则引发缓存与数据库双写一致性问题(后文详解)。
2. Redis 具备高并发
单机 Redis QPS(Query Per Second)轻松破 10w,而 MySQL 单机通常难破 1w:
- Redis 单机吞吐 ≈ MySQL 的 10 倍以上;
- 可承载大量读请求,有效分流数据库压力;
- 结合读写分离,实现“热点读走缓存、写操作直连 DB”。
Redis 数据结构
Redis 数据类型及典型使用场景
Redis 提供 5 种基础类型 + 4 种扩展类型,各司其职:
| 类型 |
典型场景 |
示例说明 |
String |
缓存对象、计数器、分布式锁、Session 共享 |
SET user:1001 '{"name":"xiaolin"}' |
Hash |
对象缓存、购物车 |
HSET cart:1001 item1 2 item2 1 |
List |
简易消息队列(需注意无消费组) |
LPUSH queue:order "order_123" |
Set |
去重、共同关注、抽奖活动 |
SADD users:active 1001 1002;SINTER users:a users:b |
ZSet |
排行榜、延时任务、电话簿排序 |
ZADD leaderboard 95.5 "xiaolin";ZRANGE leaderboard 0 9 WITHSCORES |
Bitmap(2.2+) |
用户签到、活跃统计、权限开关 |
SETBIT sign:20231001 1001 1 |
HyperLogLog(2.8+) |
UV 统计(误差率 ~0.81%) |
PFADD uv:home 1001 1002 ... |
GEO(3.2+) |
地理位置服务(附近的人、打车调度) |
GEOADD shops 116.48 39.99 "beijing" |
Stream(5.0+) |
高可靠消息队列(支持消费组、ACK、消息回溯) |
XADD mystream * field value |
✅ 延伸阅读:后端 & 架构 —— 深入理解分布式系统中的缓存策略、一致性协议与高并发设计模式。
五种常见数据类型的底层实现原理
Redis 不同版本底层结构持续演进。下图对比 Redis 3.0(经典《Redis 设计与实现》时代)与当前主流 Redis 7.0 的实现差异:
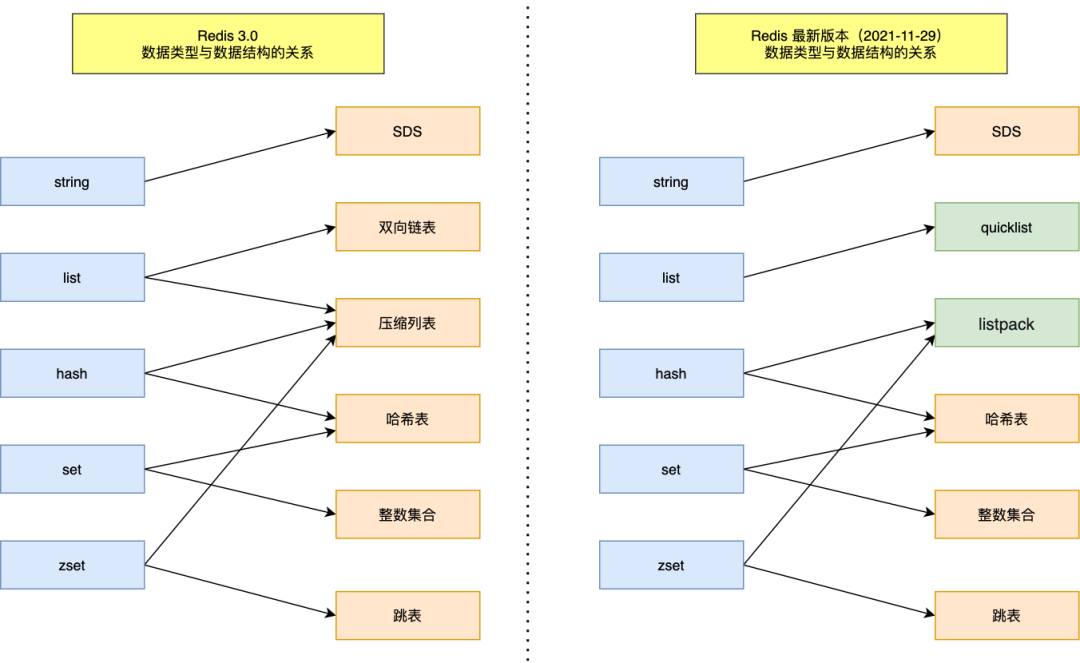
String:SDS(Simple Dynamic String)
- 非 C 原生字符串,避免缓冲区溢出、获取长度 O(1)、二进制安全;
len 字段记录长度,buf[] 存储内容,支持预分配冗余空间。
List:Redis 3.0 使用「双向链表 + 压缩列表」,3.2+ 统一为 quicklist
quicklist = ziplist(压缩列表)组成的双向链表,兼顾内存与性能;- 小列表用 ziplist(紧凑存储),大列表自动转为链表节点。
Hash:Redis 3.0 使用「压缩列表 + 哈希表」,7.0 中 ziplist 已被 listpack 替代
- 小哈希用 listpack(更省内存),大哈希用 dict(哈希表,O(1) 查找)。
Set:整数集合(intset)或哈希表(dict)
- 全为整数且元素 ≤512 个 →
intset(有序数组,节省内存);
- 否则 →
dict(哈希表,支持任意类型)。
ZSet:压缩列表(ziplist)或跳表(skiplist)
- 小有序集合 →
ziplist(紧凑存储);
- 大有序集合 →
skiplist(O(logN) 查询/插入,支持范围查询);
- Redis 7.0 中
ziplist 同样被 listpack 替代。
🔍 注:listpack 是 Redis 7.0 引入的全新紧凑编码结构,替代 ziplist,解决其连锁更新缺陷,提升内存效率。
Redis 线程模型
Redis 是单线程吗?
核心结论:命令执行是单线程的,但 Redis 整体并非单线程程序。
- ✅ 「接收请求 → 解析命令 → 执行读写 → 返回响应」全过程由主线程(event loop) 串行处理;
- ✅ 这是 Redis 实现「原子性」「无锁编程」「高吞吐」的关键设计;
- ❌ 但 Redis 启动时会创建多个后台线程(BIO)与 I/O 线程(6.0+),分别承担耗时任务。
Redis 后台线程(BIO)职责
| 线程名 |
任务 |
触发方式 |
bio_close_file |
异步关闭文件描述符 |
unlink、flushdb async 等 |
bio_aof_fsync |
AOF 文件刷盘(fsync) |
appendfsync everysec 模式下 |
bio_lazy_free |
异步释放大对象内存 |
UNLINK、FLUSHALL ASYNC 等 |
💡 实践建议:删除大 key 时务必用 UNLINK 替代 DEL,避免主线程阻塞。
Redis 6.0+ 的 I/O 多线程(非命令执行线程!)
启用 4 个 I/O 线程(含主线程共 4 个)
io-threads 4
- 官方建议:4 核 CPU → `io-threads 2~3`;8 核 → `io-threads 6`;**线程数 < CPU 核数**。
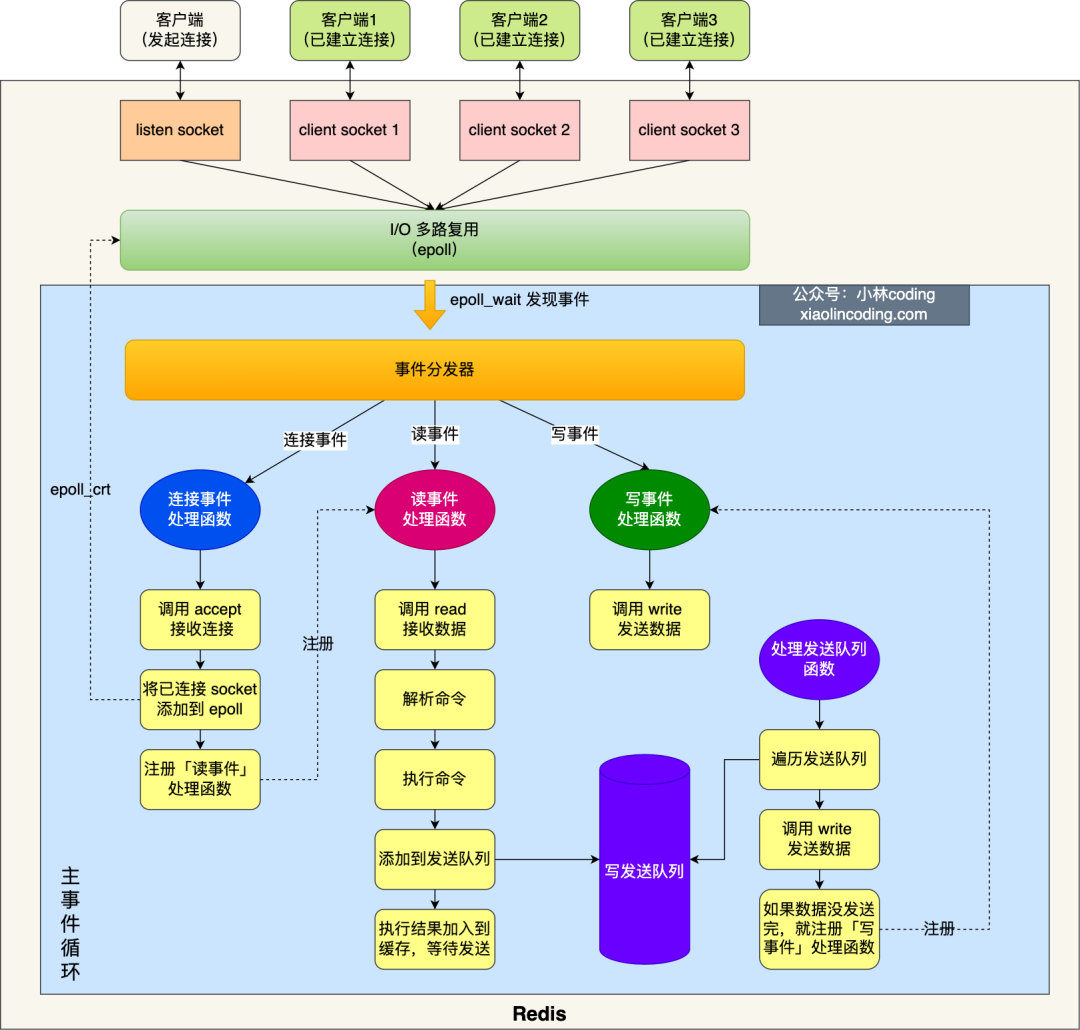
*主线程负责事件循环与命令执行;I/O 线程分担 socket 读写压力*
### Redis 单线程为何如此之快?
官方基准测试显示:单线程 Redis 吞吐可达 **10w+ QPS**:
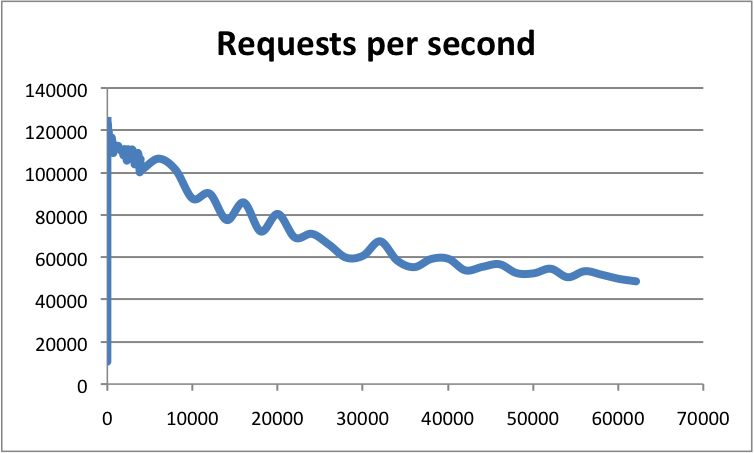
三大核心原因:
1. **纯内存操作**:99% 操作在内存完成,瓶颈通常是带宽或内存,而非 CPU;
2. **无锁设计**:单线程天然规避竞态条件、死锁、上下文切换开销;
3. **IO 多路复用(epoll/kqueue)**:一个线程监听成千上万连接,高效分发事件。
> 📌 补充说明:Redis 官方 FAQ 明确指出——“CPU 很少成为 Redis 瓶颈,更多受限于内存与网络”。因此,单线程是理性选择,而非妥协。
---
## Redis 持久化
### Redis 如何实现数据不丢失?
Redis 默认数据全在内存,重启即丢。为保障可靠性,提供三种持久化机制:
| 方式 | 原理 | 优点 | 缺点 |
|------|------|------|------|
| **AOF(Append Only File)** | 记录每条写命令(如 `*3\r\n$3\r\nset\r\n$4\r\nname\r\n$7\r\nxiaolin`) | 数据丢失少(`everysec` 模式最多丢 1s);可读性强 | 文件体积大;恢复慢(需重放全部命令) |
| **RDB(Redis Database)** | 定时生成内存快照(二进制 dump) | 恢复快;文件紧凑;适合备份 | 数据丢失多(最后一次快照后全丢);频繁 fork 影响性能 |
| **混合持久化(Redis 4.0+)** | AOF 重写时,前半部分为 RDB 格式,后半部分为 AOF 增量 | 兼顾恢复速度与数据安全性 | AOF 文件可读性差;兼容性仅限 Redis 4.0+ |
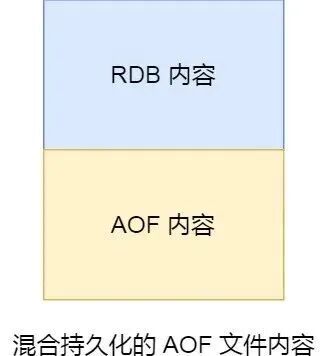
*RDB 内容 + AOF 内容 = 混合持久化 AOF 文件*
### AOF 日志是如何实现的?
流程如下(以 `SET name xiaolin` 为例):
1. 主线程执行命令 → 修改内存;
2. 将命令以 Redis 协议格式追加至 `server.aof_buf` 缓冲区;
3. `write()` 系统调用将 buf 写入内核 page cache(非落盘);
4. 由内核决定何时 `fsync()` 刷盘(取决于 `appendfsync` 策略)。
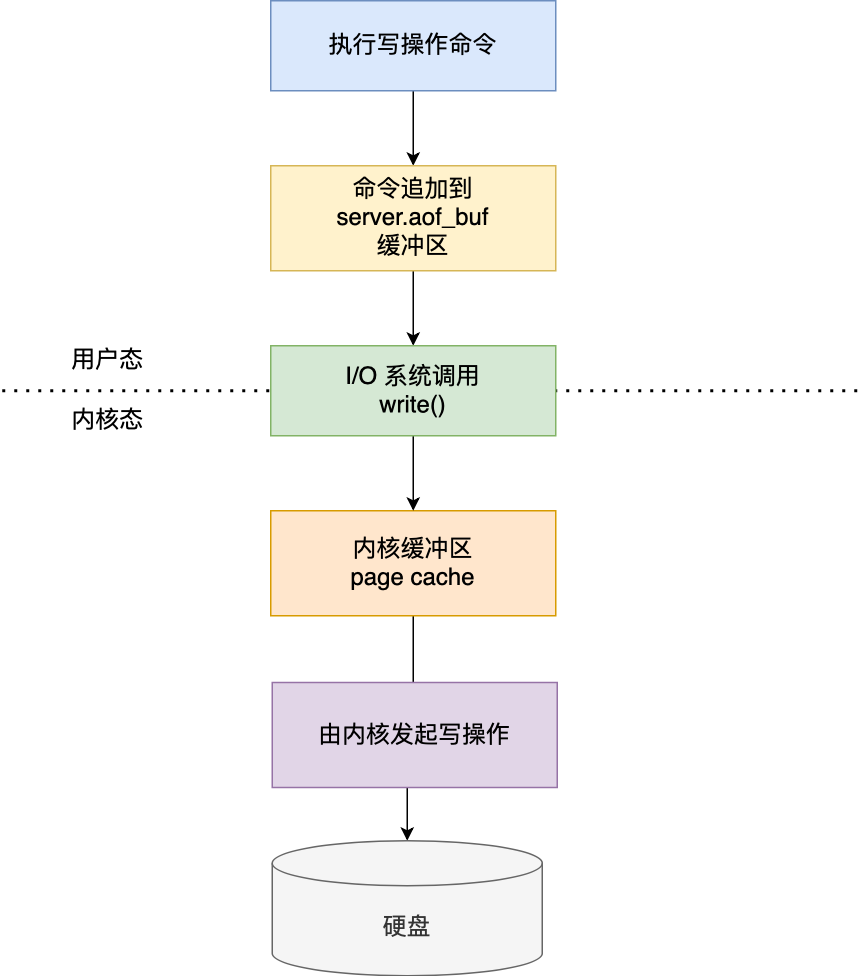
#### AOF 三种写回策略对比
| 策略 | 配置项 | 优点 | 缺点 |
|------|--------|------|------|
| `Always` | `appendfsync always` | 数据最安全(每次写都落盘) | 性能最差(磁盘 I/O 成瓶颈) |
| `Everysec` | `appendfsync everysec` | 性能与安全平衡(默认) | 宕机最多丢 1s 数据 |
| `No` | `appendfsync no` | 性能最优(交由 OS 控制) | 宕机可能丢失大量数据 |
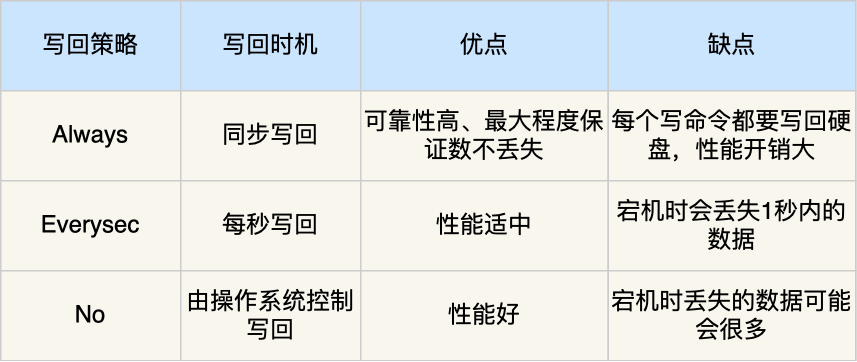
> ⚠️ 关键细节:Redis **先执行命令,再写 AOF 日志**(避免语法错误污染日志),但也带来宕机丢数据风险。
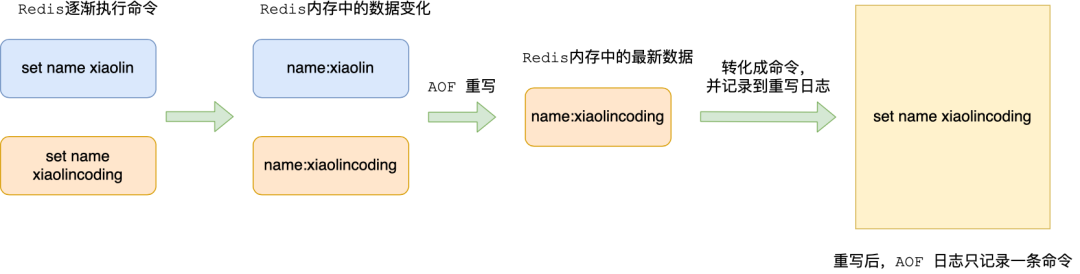
#### AOF 重写机制(Rewrite)
AOF 文件持续增长 → 启动重写压缩:
- 重写由子进程 `bgrewriteaof` 执行,不阻塞主线程;
- 子进程读取当前数据库状态,用最少命令重建(如多次 `SET` 合并为最终值);
- 重写期间,主进程将新写命令**同时写入 AOF 缓冲区与 AOF 重写缓冲区**,确保数据一致;
- 重写完成后,原子替换旧 AOF 文件。
### RDB 快照是如何实现的?
RDB 是某时刻内存数据的**全量二进制快照**,恢复时直接加载,无需执行命令。
#### 两种触发方式
- `SAVE`:主线程阻塞执行,慎用;
- `BGSAVE`:fork 子进程执行,推荐(默认配置自动触发)。
Redis 默认配置(满足任一即触发 `BGSAVE`):
```conf
save 900 1 # 900s 内至少 1 次修改
save 300 10 # 300s 内至少 10 次修改
save 60 10000 # 60s 内至少 10000 次修改
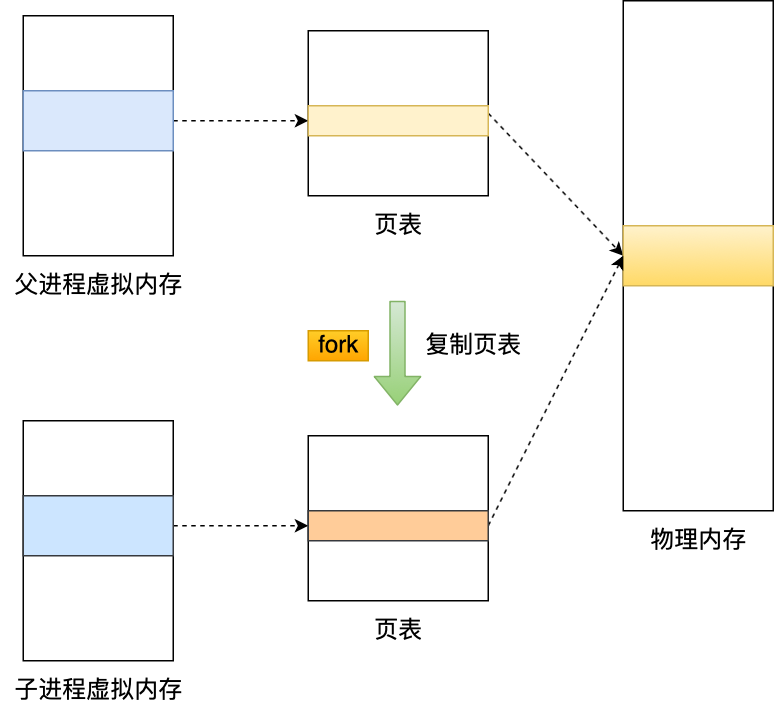
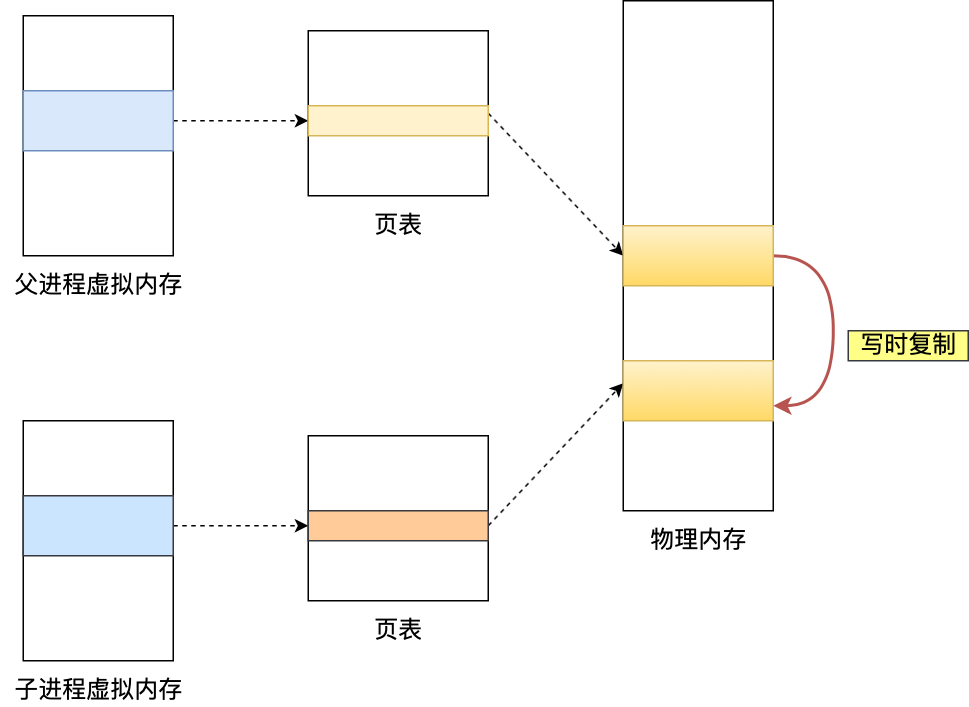
RDB 快照时数据能否修改?——写时复制(Copy-on-Write)
fork() 创建子进程时,父子进程共享物理内存页(只读);- 主进程写操作触发「写时复制」:被修改页自动拷贝副本,子进程继续读取原页;
- 子进程将副本数据写入 RDB 文件,主线程不受影响。
✅ 延伸阅读:面试求职 —— 获取高频 Redis 面试题 PDF、模拟面试反馈、简历优化指南。
Redis 集群
Redis 如何实现服务高可用?
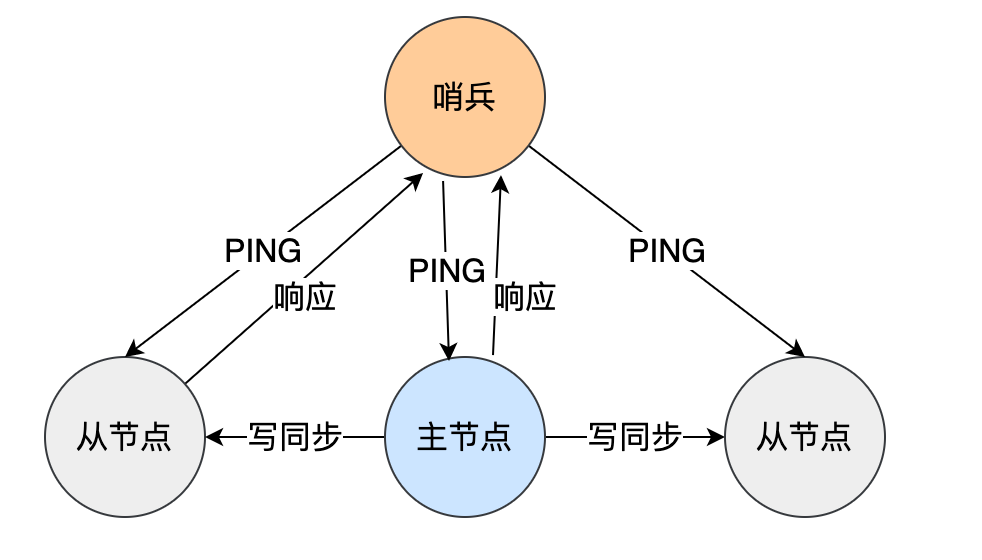
三大演进阶段:主从复制 → 哨兵(Sentinel)→ 集群(Cluster)
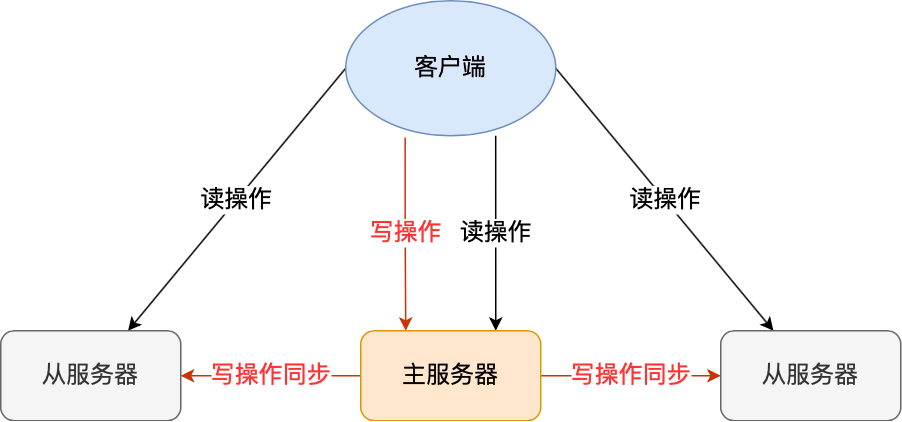
主从复制(基础)
- 一主多从,读写分离(主写、从读);
- 异步复制:主写完即返回客户端,从库延迟不可避免;
- 数据最终一致,无法保证强一致性。
哨兵模式(Sentinel)
- 监控主从健康状态;
- 自动故障转移:主宕机 → 选举新主 → 通知客户端;
- 本质是「高可用管理组件」,不改变数据分布。
Redis Cluster(分片集群)
- 采用 16384 个哈希槽(Hash Slot) 分片;
- Key → CRC16(key) → mod 16384 → Slot → Node;
- 支持节点扩缩容、自动迁移 Slot。
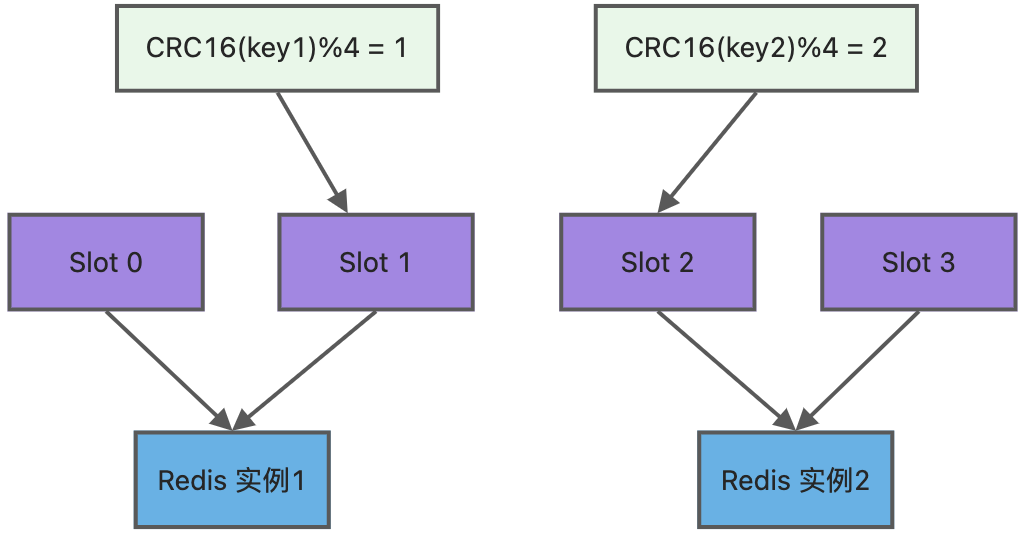
💡 示例命令(手动分配 Slot):
redis-cli -h 192.168.1.10 -p 6379 cluster addslots 0,1
redis-cli -h 192.168.1.11 -p 6379 cluster addslots 2,3
集群脑裂导致数据丢失怎么办?
什么是脑裂?
主节点网络分区 → 与从节点失联 → 哨兵误判主宕机 → 选举新主 → 出现双主 → 网络恢复后旧主降级清空数据 → 客户端写入丢失。
解决方案:写安全阈值控制
通过以下两个参数限制主节点写入,避免脑裂:
min-slaves-to-write 1 # 至少 1 个从节点在线才允许写
min-slaves-max-lag 12 # 从节点延迟 ≤12s 才允许写
- 若不满足,主节点拒绝写请求,返回错误;
- 新主上线后,客户端写入仅流向新主,旧主降级同步时不会清空有效数据。
✅ 此方案是生产环境 Redis 高可用的必备配置。
Redis 过期删除与内存淘汰
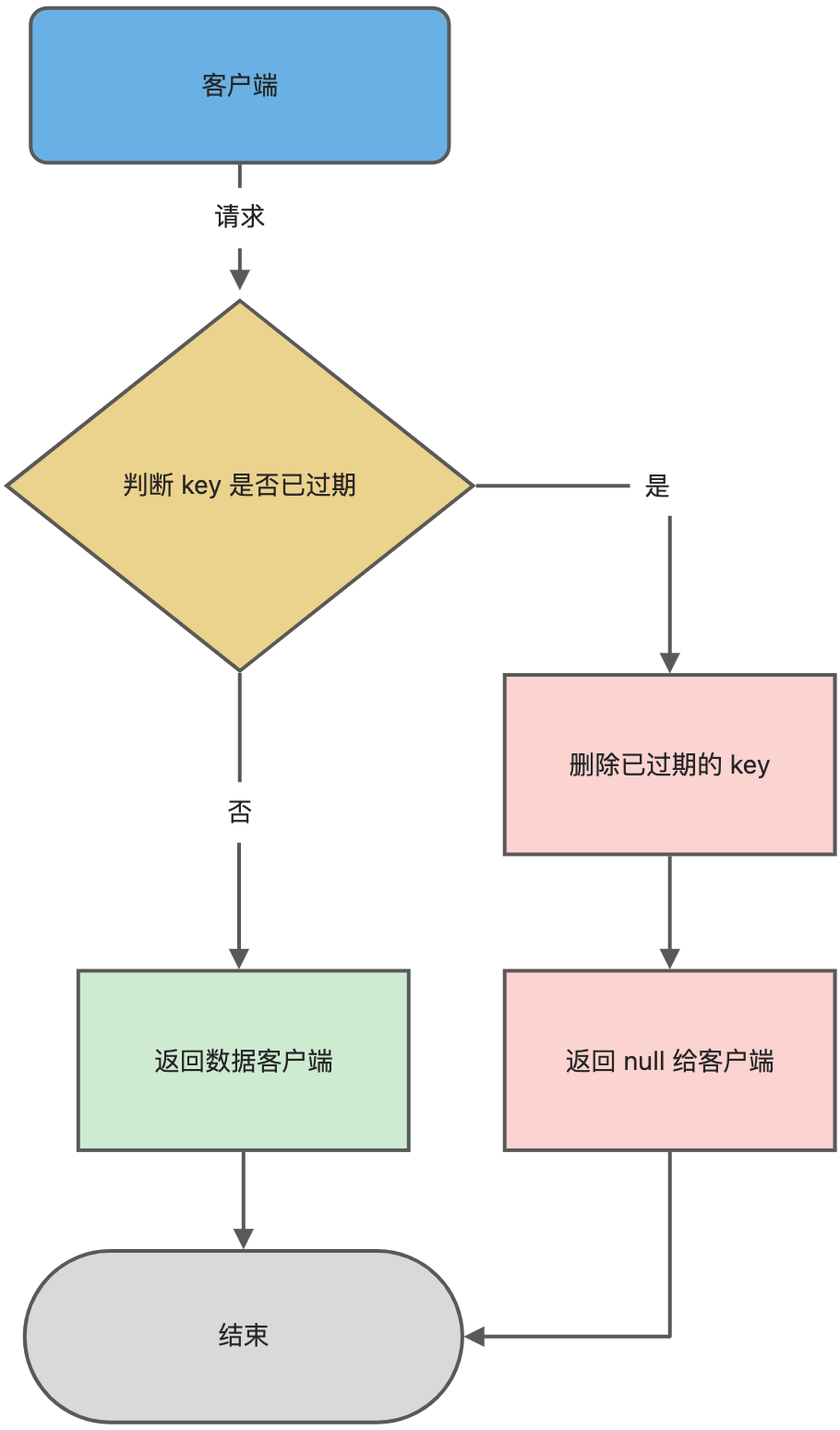
Redis 使用的过期删除策略是什么?
采用 惰性删除 + 定期删除 双策略组合:
- 惰性删除:每次访问 key 时检查是否过期,过期则删除;
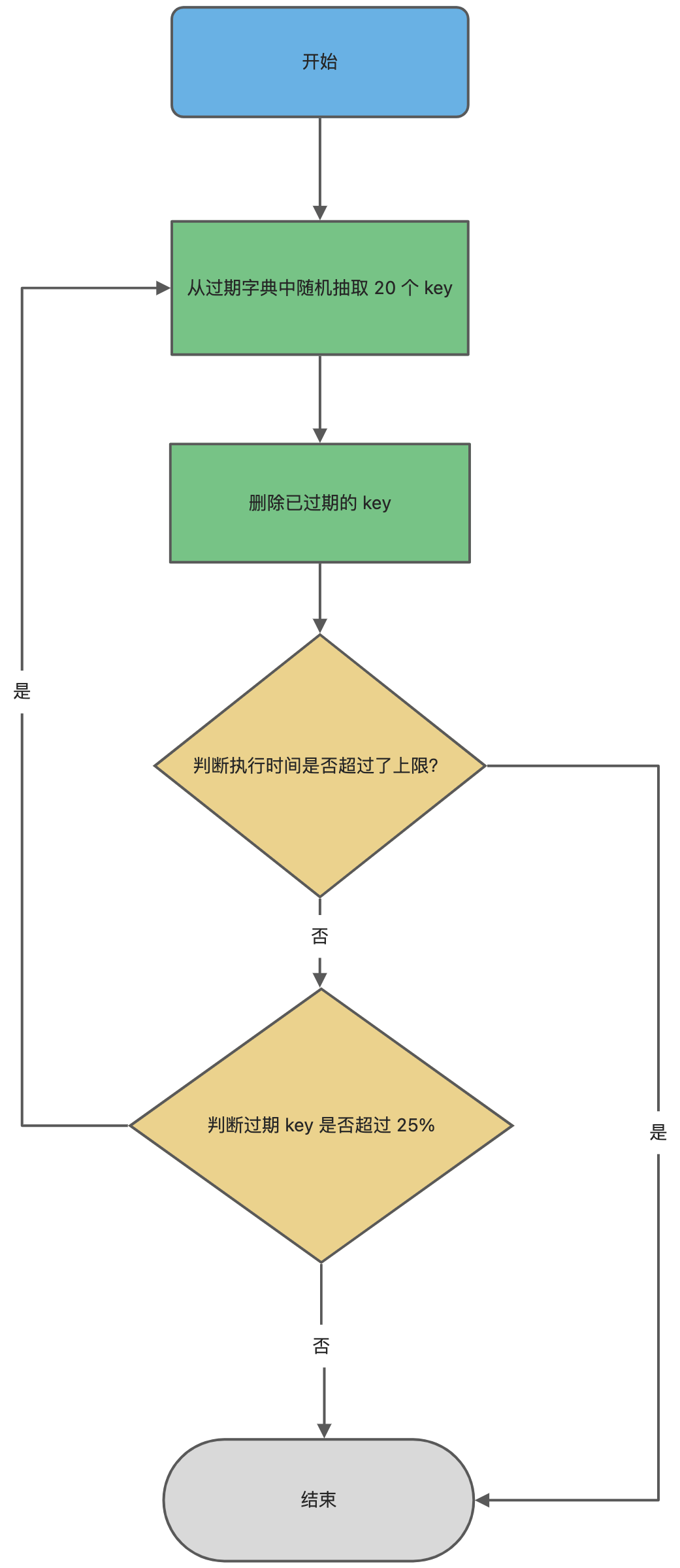
- 定期删除:每 100ms 随机抽样 20 个 key,删除过期者;若过期率 >25%,继续抽样(上限 25ms);
- ✅ 平衡内存与 CPU;
- ❌ 抽样无法覆盖全部 key。
Redis 内存满了,会发生什么?
触发 内存淘汰机制(maxmemory 配置项控制阈值)。
八种淘汰策略分类
| 类别 |
策略 |
说明 |
| 不淘汰 |
noeviction(默认) |
内存满后直接返回错误(OOM) |
| 仅淘汰过期 key |
volatile-random / volatile-ttl / volatile-lru / volatile-lfu |
仅作用于设置了 EXPIRE 的 key |
| 淘汰所有 key |
allkeys-random / allkeys-lru / allkeys-lfu |
无视过期时间,全局淘汰 |
💡 Redis 4.0+ 新增 LFU(Least Frequently Used),比 LRU 更抗缓存污染。
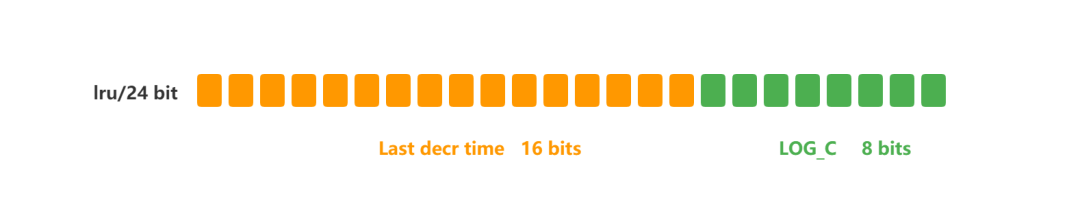
LRU vs LFU 原理对比
- LRU:记录最后访问时间戳(
lru 字段高 16bit),随机采样淘汰最久未用者;
- LFU:
lru 字段拆分为高 16bit(访问时间戳)+ 低 8bit(访问频次计数器);
- LFU 更合理:避免一次性批量读取导致的缓存污染。
Redis 缓存设计
如何避免缓存雪崩、击穿、穿透?
| 问题 |
原因 |
解决方案 |
| 缓存雪崩 |
大量 key 同一时间过期 → 请求穿透 DB |
✅ 过期时间随机化(如 expire + rand(1,600))
✅ 永不过期 + 后台异步更新 |
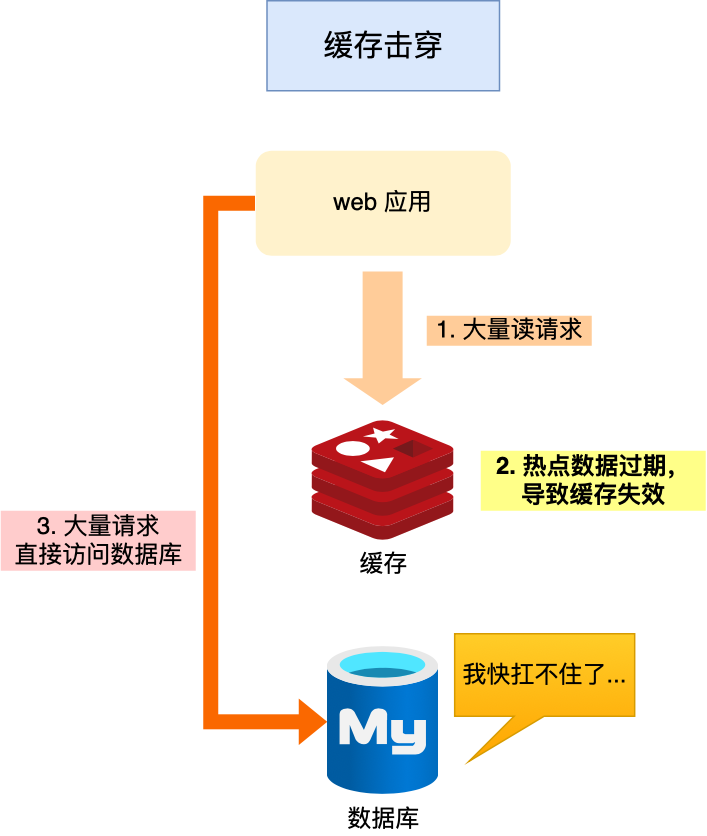
| 缓存击穿 |
热点 key 过期瞬间,海量请求直达 DB |
✅ 互斥锁(SETNX lock_key 1 EX 30 NX)
✅ 热点 key 永不过期 |
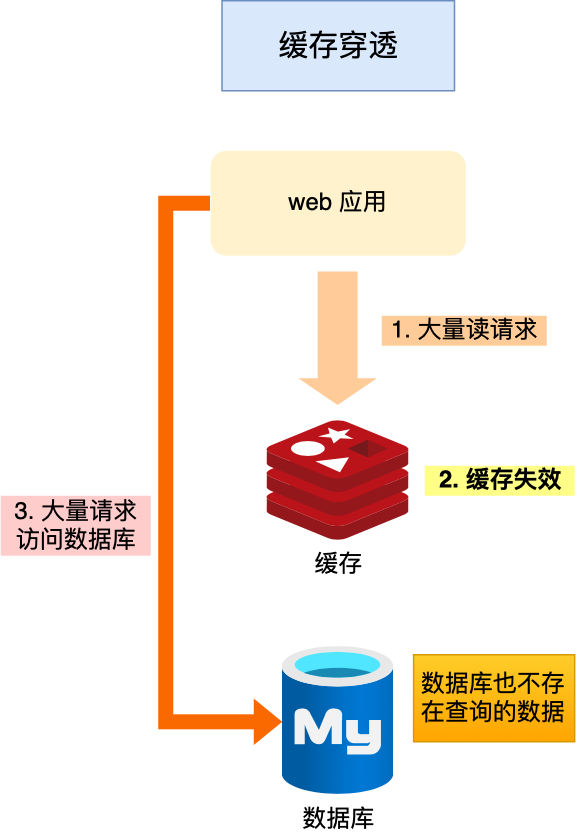
| 缓存穿透 |
查询不存在的 key(恶意 or 误删)→ 请求直达 DB |
✅ 参数校验(非法 ID 直接拦截)
✅ 空值缓存(SET key "" EX 60)
✅ 布隆过滤器(Bloom Filter)前置校验 |
常见缓存更新策略
| 策略 |
描述 |
适用场景 |
Redis 是否支持 |
| Cache Aside(旁路缓存) |
应用直连 DB 与 Cache,自行维护一致性 |
✅ 读多写少;主流方案 |
✔️(推荐) |
| Read/Write Through |
应用只连 Cache,Cache 代理 DB 读写 |
❌ Redis 无内置 DB 代理能力 |
✖️(需自研中间件) |
| Write Back(写回) |
更新只写 Cache,异步刷 DB |
❌ Redis 无异步刷 DB 功能 |
✖️(仅适用于 CPU Cache / Page Cache) |
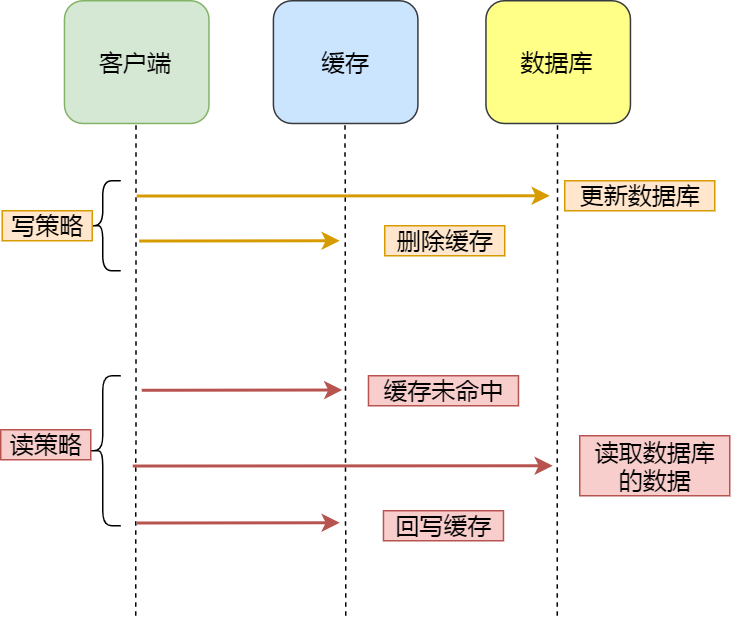
Cache Aside 写策略(重点!)
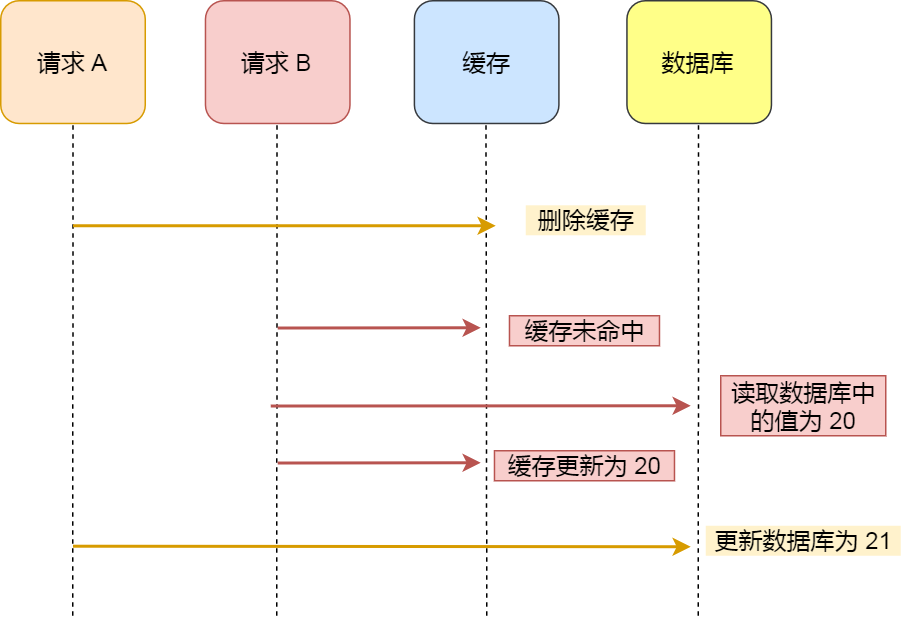
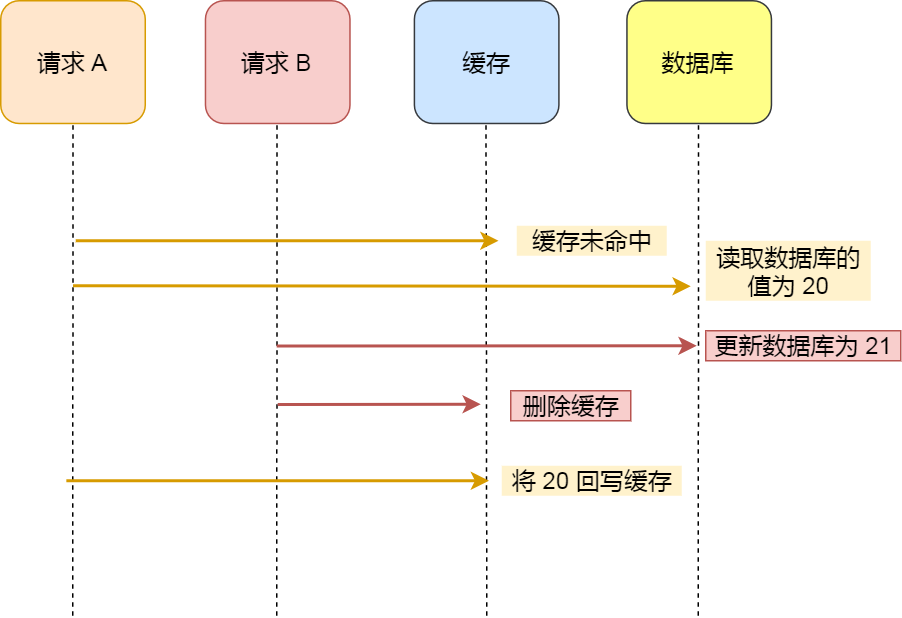
- ✅ 正确顺序:先更新 DB,再删除 Cache
(避免并发下「读旧缓存 → 写 DB → 写缓存」导致脏数据);
- ❌ 禁止「先删 Cache 再更新 DB」:极端并发下必然不一致;
- ⚠️ 仍存在极小概率不一致(DB 更新成功 → Cache 删除失败),可通过「消息队列重试」或「定时对账」兜底。
Redis 实战
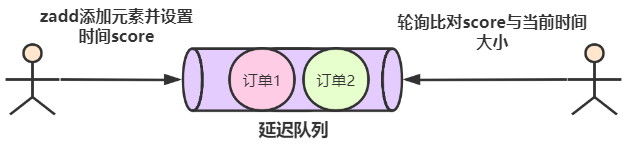
Redis 如何实现延迟队列?
利用 ZSet 的 score 排序能力:
ZADD queue_key <timestamp> <task_id>:按执行时间戳插入;ZRANGEBYSCORE queue_key -inf <now>:拉取所有到期任务;- 消费后
ZREM 删除。
Redis 的大 key 如何处理?
什么是大 key?
- String > 10 KB;
- Hash/List/Set/ZSet 元素 > 5000 个。
危害
- 阻塞主线程(
DEL、HGETALL 等);
- 网络传输卡顿(1MB key × 1000 QPS = 1GB/s 流量);
- 内存碎片化、集群倾斜。
查找方案
redis-cli --bigkeys(快速扫描,但精度有限);SCAN + TYPE + MEMORY USAGE(精准定位,推荐);rdbtools 解析 RDB 文件(离线分析)。
安全删除方案
- ✅ 分批删除(
HSCAN/HDEL、SSCAN/SREM、LTRIM);
- ✅ 异步删除(Redis 4.0+
UNLINK,或开启 lazyfree-* 配置)。
💡 lazyfree 相关配置(建议开启):
lazyfree-lazy-eviction yes
lazyfree-lazy-expire yes
lazyfree-lazy-server-del yes
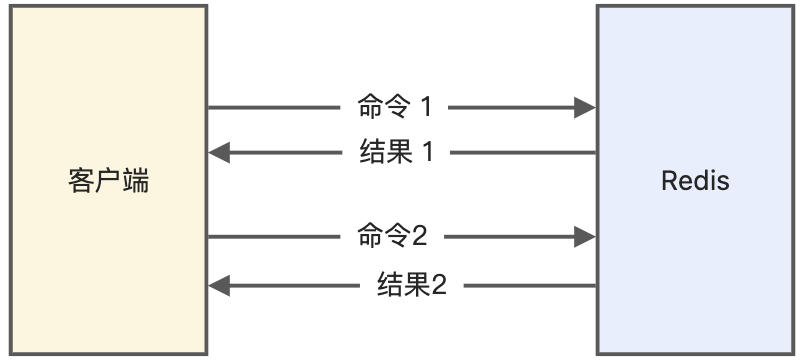
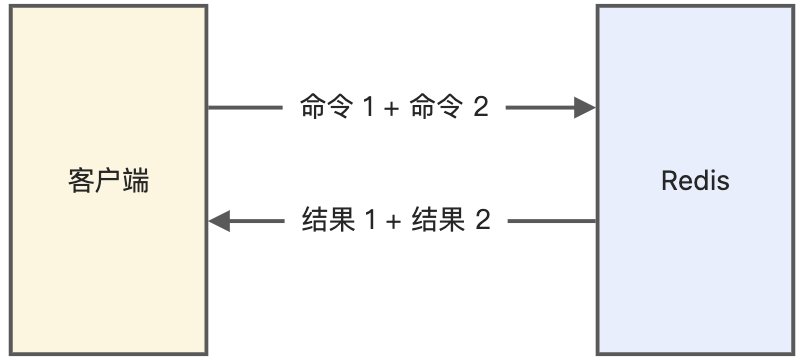
Redis 管道(Pipeline)有什么用?
- 本质:客户端批处理技术(非 Redis 服务端功能);
- 价值:减少 RTT(往返时延),将 N 次请求合并为 1 次 TCP 包;
- 注意:避免单次 pipeline 过大(>1MB),防止网络拥塞。
Redis 事务支持回滚吗?
不支持运行时错误回滚(如 EXPIRE key "abc" 语法错误)。
MULTI/EXEC 仅保证命令排队原子性,不保证执行原子性;DISCARD 仅清空队列,非传统回滚;- Redis 官方认为:运行时错误多为开发 bug,应在测试阶段暴露,无需复杂回滚机制。

如何用 Redis 实现分布式锁?
单节点加锁(SET + Lua)
SET lock_key unique_value NX PX 10000
NX:key 不存在才设置;PX:自动过期,防死锁;unique_value:客户端唯一标识(防误删)。
安全解锁(Lua 脚本保证原子性)
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
集群可靠性方案:Redlock(红锁)
- 向 ≥3 个独立 Redis 节点发起加锁请求;
- 成功 ≥N/2+1 个节点,且总耗时 < 锁过期时间 → 加锁成功;
- 官方推荐 5 节点部署(容忍 2 节点故障)。
✅ 延伸阅读:云栈社区 —— 获取最新 Redis 源码解读、性能调优实践与企业级集群部署手册。
 发表于 2026-4-4 06:13:51
|
查看: 130|
回复: 0
发表于 2026-4-4 06:13:51
|
查看: 130|
回复: 0
