去年一次美团面试,面试官看着我的简历问:“你们项目里那个全局字典模块,比如省市代码、订单状态这些配置,是怎么做缓存的?”
我当时为了凸显系统架构的高大上,脱口而出:“为了保证高可用和扩展性,我们专门搭建了 Redis 集群,所有业务都直接查 Redis,完全能扛住大流量。”
话音刚落,面试官就忍不住笑了。看到他摇头,我才猛然意识到问题所在——我们那个字典表总共就几百条记录,而且几乎从不更新。
那次面试失败后我才真正明白:过度设计,说的就是我这种“为了技术而技术”的做法。明明引入一个 Caffeine 本地缓存就能完美解决的问题,非要为了所谓的“先进架构”走一遍 Redis 的网络 I/O。这不仅徒增了部署成本和系统复杂度,还无谓地拖慢了响应速度。
玩笑归玩笑,在实际业务开发中,厘清不同缓存方案的适用边界,尤其是本地缓存与分布式缓存的取舍,确实是系统设计的核心基本功。这往往也是考察候选人是否具备务实、落地的架构思维的高频考点。
当下竞争激烈,面试官越来越看重我们解决实际问题的能力,而非单纯堆砌技术栈。下面梳理了几道关于缓存选型和基础概念的面试题,希望能帮你理清思路:
- 为什么有些场景下,用 Redis 反而不如本地缓存?
- 单体架构下,JDK自带的 Map、Guava Cache 和 Caffeine 该如何选择?
- 引入分布式缓存(如 Redis)会给系统带来哪些额外成本和隐患?
- 面对极高并发的秒杀场景,如何设计本地缓存与 Redis 结合的多级缓存?
- 多级缓存架构下,如何低成本地保证数据一致性?
缓存的基本思想
很多同学知道缓存能提升性能、减少响应时间,但对其实质思想可能并不清晰。
缓存的核心思想其实非常朴素,就是我们熟知的 空间换时间 这一经典性能优化策略。简单说,就是用额外的存储空间来保存可能被重复使用或计算的数据,从而避免重复获取或计算带来的时间开销。
除了缓存,空间换时间的例子在生活中随处可见:
- 索引:数据库通过创建额外的数据结构(索引)来加快数据检索速度,虽然占用空间,但大幅降低了查询时的排序和遍历成本。
- 数据库表字段冗余:将经常需要联合查询的数据冗余存储在同一张表中,以减少多表关联查询,提升查询性能,减轻数据库压力。
- CDN(内容分发网络):将静态资源缓存到遍布全球的边缘节点,用户可就近访问,极大加快资源加载速度,同时缓解源站服务器的压力和带宽消耗。
学会归纳总结,将知识点串联起来,在面试时若能聊到这些,会给面试官留下深刻印象。
不要把缓存想得太神秘,虽然它对系统性能的提升性价比确实很高。你会发现,缓存思想在计算机系统的许多层面都有体现。
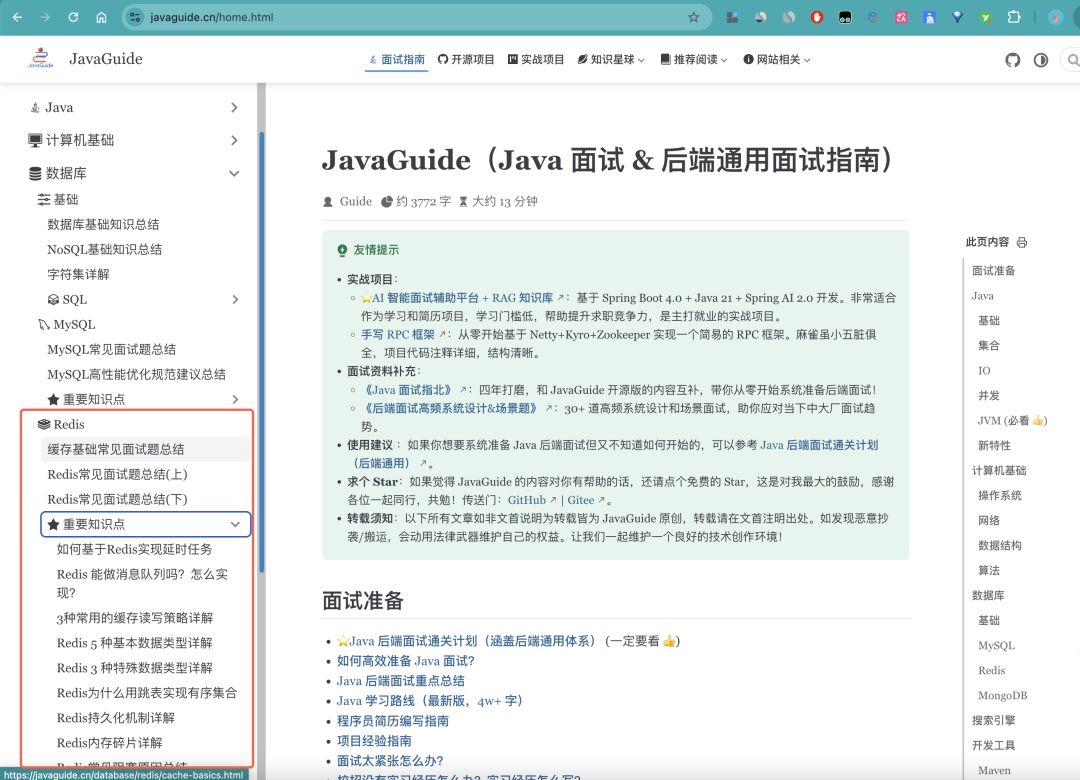
例如,CPU Cache 缓存的是内存数据,用以解决 CPU 处理速度远快于内存访问速度的矛盾;内存本身也可以看作是硬盘数据的缓存,用以解决硬盘 I/O 速度过慢的问题。
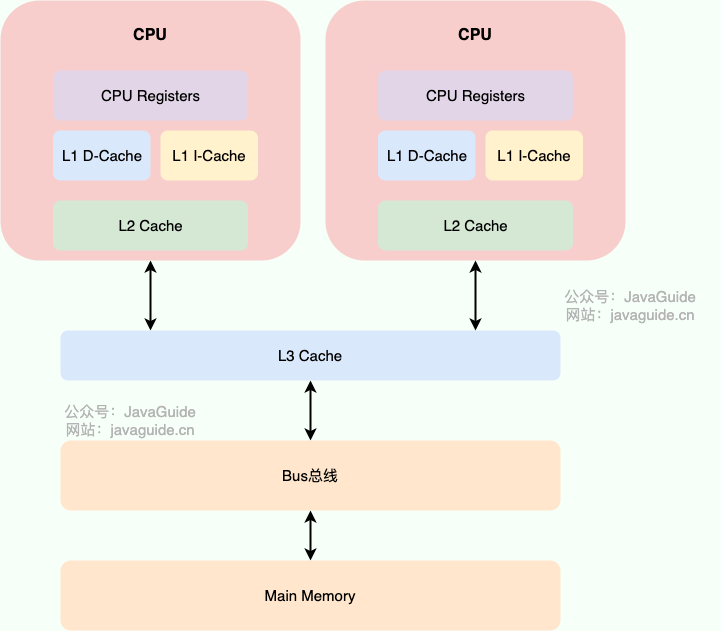
再比如,为了提高虚拟地址到物理地址的转换效率,操作系统在页表方案基础上引入了转址旁路缓存(TLB,快表)。
我们日常使用的浏览器,也会对访问过的图片、脚本等静态文件进行缓存,下次访问相同页面时加载速度会显著提升。
在开发中,缓存数据通常存储在 RAM(内存) 中,访问速度极快。为防止重启或宕机导致数据丢失,许多缓存中间件(如 Redis)提供了持久化到磁盘的机制。相比关系型数据库(如 MySQL),缓存的访问速度和并发支撑能力往往高出几个数量级。因此,在数据库前增加一层缓存,是保护底层存储、提升系统吞吐量的关键手段。
缓存的分类
接下来,我们看看日常开发中常见的缓存分类。
本地缓存
什么是本地缓存?
本地缓存在单体架构或数据量不大、无分布式需求的场景中使用较多。它位于应用程序内部,最大的优势是与应用进程共享同一内存空间,请求速度极快,没有额外的网络开销。
一个典型的单体架构可能如下图所示,使用 Nginx 做负载均衡,后端部署多个相同的应用实例,它们共享同一个数据库,并且各自使用自己的本地缓存。
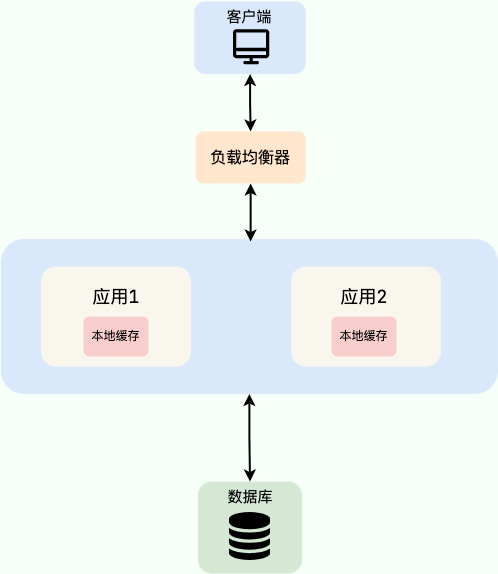
注意:在集群模式下使用本地缓存,必须考虑负载均衡策略。如果 Nginx 使用默认的轮询(Round-Robin),同一用户的请求会随机分发到不同机器,导致本地缓存命中率极低。解决方案通常有两种:
- 网关层:使用一致性哈希或粘性会话(Sticky Session),保证同一用户的请求始终路由到同一台服务器。但这会破坏微服务的无状态特性,且在节点扩缩容时缓存命中率波动大,容易引发单点热点问题,现代云原生架构中较少采用。
- 应用层:仅将本地缓存用于那些“全局几乎不变”的数据(如文章开头提到的配置字典),而非用户维度的动态数据。
本地缓存的方案有哪些?
1、JDK 自带的 HashMap 和 ConcurrentHashMap。
ConcurrentHashMap 是高并发环境下基础的线程安全键值对容器。虽然常被初学者当作简易缓存使用,但它本质上只是一个数据结构,并非功能完备的缓存框架。它缺乏缓存必备的核心机制:过期淘汰策略(TTL/TTI)、容量驱逐算法(如 LRU/W-TinyLFU) 以及命中率监控。
因此,在大部分场景下不会直接使用它们作为缓存。一个合格的缓存框架至少应提供:过期时间、淘汰机制、命中率统计 这三大基础功能。
2、Ehcache、Guava Cache、Spring Cache 是三种使用较广的本地缓存框架。
Ehcache 相对而言更为重量级。相比 Guava Cache 和 Spring Cache,它支持嵌入到 Hibernate 和 MyBatis 作为二级缓存,并能将缓存数据持久化到本地磁盘,同时也提供了集群方案(但较为鸡肋)。Guava Cache 和 Spring Cache 较为相似。Guava Cache 使用更广泛,它提供了友好的 API,支持设置缓存过期时间等功能。其内部实现简洁高效,许多设计思路与 ConcurrentHashMap 有异曲同工之妙。- 使用
Spring Cache 注解可以实现声明式缓存,代码非常优雅。但需警惕其默认实现的陷阱:Spring Cache 本身只是一层抽象,若底层直接使用默认的 ConcurrentMapCacheManager(基于无容量限制的 ConcurrentHashMap),在缓存大量动态 Key 时极易导致 OOM。因此,生产环境中必须将其底层实现替换为配置了最大容量的 Caffeine 或 Redis。
3、后起之秀 Caffeine。
相比 Guava Cache,Caffeine 在性能等各方面都更为优秀,通常建议用它来替代 Guava。并且,两者的使用方式非常相似。
以下是使用 Caffeine 创建本地缓存的代码示例:
// 使用 Caffeine 创建本地缓存示例
Cache<String, String> cache = Caffeine.newBuilder()
// 设置写入后 10 分钟过期
.expireAfterWrite(10, TimeUnit.MINUTES)
// 初始容量
.initialCapacity(100)
// 最大条数限制
.maximumSize(500)
// 开启统计功能
.recordStats()
.build();
本地缓存有什么痛点?
本地缓存的优点非常突出:低依赖、轻量、简单、成本低。
但其缺点也同样明显:
- 与应用耦合,对分布式架构支持不友好:当相同的服务部署在多台机器上时,各服务实例间的本地缓存无法共享。
- 容量受限于单机资源:缓存容量受服务部署机器本身内存的限制。如果应用本身已消耗大量内存,则可供缓存使用的空间就非常有限。
分布式缓存
什么是分布式缓存?
我们可以将分布式缓存看作是一个独立的内存数据库服务,其核心职能就是提供缓存数据。
分布式缓存独立于应用程序存在,多个应用可以共享同一个分布式缓存服务。
如下图所示,一个简单的使用分布式缓存的架构。Nginx 负责负载均衡,多个应用实例共享同一个数据库和同一个 Redis 缓存集群。
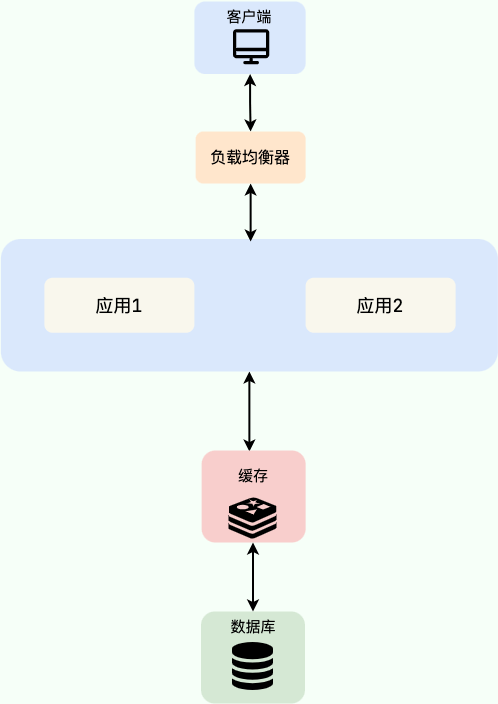
使用分布式缓存后,即使服务部署在多台机器上,它们访问的也是同一份缓存数据。独立的缓存服务在性能、容量和功能上都比本地缓存更加强大。
然而,软件系统设计中没有银弹,任何技术的引入都像一把双刃剑。 使用得当,能为系统带来巨大收益;使用不当,则可能徒增复杂度。
简单来说,引入分布式缓存后常会带来以下问题:
- 系统复杂性增加:需要维护缓存与数据库的数据一致性、处理热点缓存、保证缓存服务自身的高可用等。
- 运维与资源成本增加:意味着需要额外部署并维护一个高可用的缓存中间件集群,消耗额外的内存资源,并提高了系统的运维门槛。
分布式缓存的方案有哪些?
谈到分布式缓存,比较老牌且常用的当属 Memcached 和 Redis。不过,现在基本看不到新项目使用 Memcached 了,Redis 已成为绝对主流。
Memcached 是分布式缓存兴起早期常用的方案。随着 Redis 的快速发展,因其更强大的功能,大家逐渐转向了 Redis。
一些大厂也开源了类似 Redis 的分布式高性能 KV 存储,例如腾讯开源的 Tendis。Tendis 基于 RocksDB 存储引擎,100% 兼容 Redis 协议和数据模型。不过,从 Github 提交记录看,Tendis 开源版已基本停止维护,关注度和使用率都不高,因此不建议在生产中使用。
目前,业界比较认可的 Redis 替代品主要有下面两个(都以高性能和兼容 Redis 为卖点):
- Dragonfly:一种为现代应用负载构建的内存数据库,完全兼容 Redis 和 Memcached API,号称全球最快的内存数据库。
- KeyDB:Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
尽管如此,个人仍然建议将 Redis 作为分布式缓存的首选,毕竟它经过了多年大规模生产的考验,拥有极其优秀的生态和全面的资料。
多级缓存
什么是多级缓存?为什么要用?
这里我们只讨论最常见的 本地缓存 + 分布式缓存 的多级缓存方案。
这时你可能会问:既然已经用了分布式缓存,为什么还要加一层本地缓存?
原因在于,虽然都是缓存,但本地缓存的访问速度远高于分布式缓存,因为它没有网络开销。
不过,通常不建议轻易使用多级缓存,这会增加维护负担(例如需要保证 L1 和 L2 缓存的数据一致性)。而且,对于绝大多数业务场景,其带来的性能提升并不显著。
简单总结两种适合使用多级缓存的业务场景:
- 缓存的数据几乎不修改,非常稳定。
- 数据访问量极高,如秒杀场景。
在多级缓存方案中,第一级缓存(L1)使用本地内存(如 Caffeine),第二级缓存(L2)使用分布式缓存(如 Redis)。
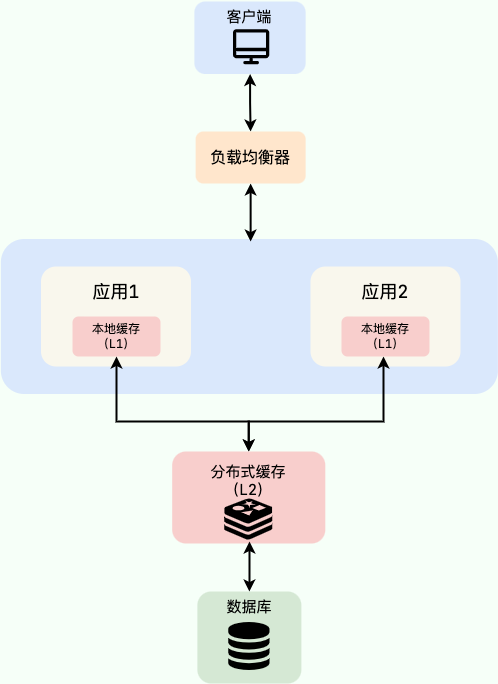
读取数据时,先从 L1 读取,未命中则去 L2 读取,如果 L2 也没有,最后才查询数据库。查询到数据后,同时回填到 L1 和 L2 中。这样可以有效减轻 L2 的压力,降低其读请求量。
多级缓存的开源实现推荐:
- J2Cache:基于本地内存和 Redis 的两级 Java 缓存框架。
- JetCache:阿里开源的缓存框架,支持多级缓存、分布式缓存自动刷新、TTL 等功能。
多级缓存一致性如何保证?
在多级缓存系统中,保证强一致性成本过高,因此业界的多级缓存框架基本都只保证最终一致性。常见方案是利用 Redis 的发布/订阅机制、Redis Stream 或消息队列,确保当一个应用实例的本地缓存更新后,其他实例能及时感知并更新自己的本地缓存。
例如政采云技术的方案采用了 Canal + 消息广播:
- DB 修改数据:首先在数据库中修改数据。
- Canal 监听触发更新:通过 Canal 监听数据库的变更(Binlog),当检测到数据变化时,触发缓存更新流程。
- 同步 Redis 缓存:由于 Redis 是共享的,直接更新或删除对应的 Redis 缓存键即可。
- 同步本地缓存:本地缓存分布在各个 JVM 实例中,需要借助消息队列(MQ)广播更新事件,通知所有业务实例清除或更新其本地缓存。
⚠️ 警惕消息乱序导致脏数据:在高并发修改场景下,Canal 可能监听到多次更新并推送到 MQ,由于网络延迟,消费端处理消息的顺序可能与数据库实际执行顺序不一致,导致旧数据覆盖新数据。生产环境中,更新缓存的操作建议改为 删除(使缓存失效) 而非直接更新,迫使下次请求时重新从数据库加载最新数据,再配合缓存本身的 TTL 兜底机制,可以最大程度避免脏数据残留。
在云栈社区的架构板块,你可以找到更多关于系统设计、缓存实践以及面试经验的深度讨论。缓存的选择没有固定答案,关键在于深入理解业务场景和技术组件的特性,做出最务实的设计。
 发表于 2026-4-4 06:16:30
|
查看: 122|
回复: 0
发表于 2026-4-4 06:16:30
|
查看: 122|
回复: 0
