本文将对Redis进行系统性的梳理与总结,涵盖其核心概念、应用场景以及在生产环境中常见问题的解决方案。
主要内容概览
- Redis简介与定位
- 为什么要使用Redis/缓存?
- 为什么选择Redis而非Map/Guava?
- Redis与Memcached的核心区别
- Redis常见数据结构及使用场景分析
- Redis的过期键删除策略
- Redis内存淘汰机制
- Redis持久化机制(如何保证故障后数据可恢复)
- Redis事务
- 缓存雪崩与缓存穿透问题及解决方案
- 如何解决Redis的并发竞争Key问题
- 如何保证缓存与数据库双写时的数据一致性
Redis简介
Redis本质上是一个基于内存的数据库,这使其读写速度远超传统的基于磁盘的数据库,因此被广泛应用于缓存场景。此外,Redis也常被用来实现分布式锁。它支持多种数据类型以适应不同的业务需求,同时提供了事务、持久化、Lua脚本、LRU驱动淘汰、以及多种集群方案等强大功能。
为什么要用Redis / 为什么要用缓存?
主要可以从“高性能”和“高并发”两个维度来理解。
高性能
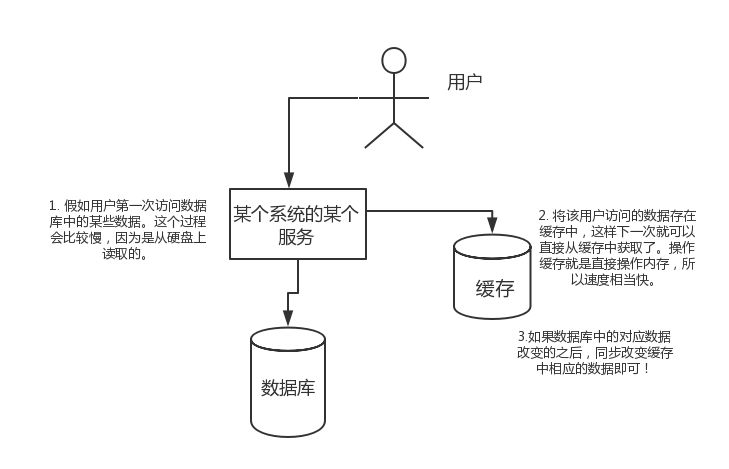
设想用户首次访问数据库中的某些数据。这个过程通常较慢,因为涉及到磁盘I/O。如果我们将该用户访问的数据存储在缓存中,那么下一次访问时就可以直接从内存中获取。操作缓存直接操作内存,速度极快。当数据库中的对应数据发生变更时,同步更新缓存中的相应数据即可。
高并发
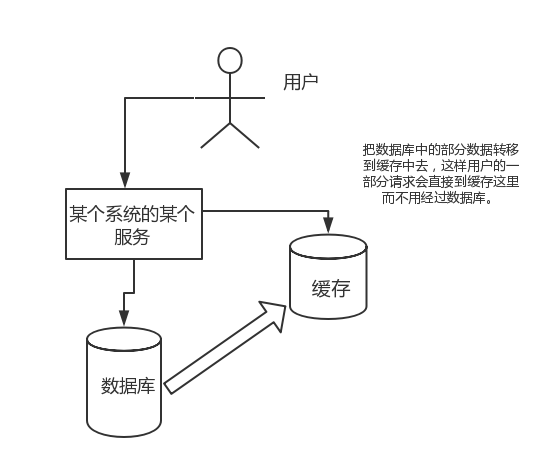
缓存能够承受的请求量远大于直接访问数据库。因此,我们可以考虑将数据库中的热点数据转移到缓存中,这样一部分用户请求会直接命中缓存,无需经过数据库,从而极大地提升系统的整体并发处理能力。
为什么要用Redis而不用Map/Guava做缓存?
此问题灵感来源于SegmentFault社区的一位网友提问。
缓存可分为本地缓存和分布式缓存。以Java为例,使用自带的Map或Guava库实现的是本地缓存,其主要特点是轻量与快速,但其生命周期随JVM的销毁而结束。在分布式多实例部署的场景下,每个服务实例都各自维护一份缓存副本,这导致了缓存数据不一致的问题。
而使用Redis或Memcached则属于分布式缓存。在多实例环境下,所有实例共享同一份缓存数据,保证了缓存的一致性。其缺点是需要维护Redis或Memcached服务的高可用性,这使得整体架构变得相对复杂。
Redis和Memcached的区别
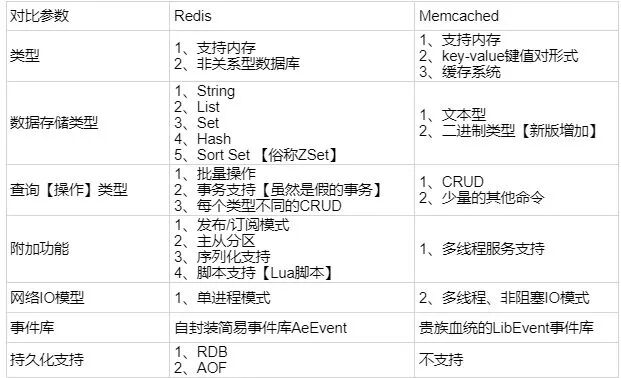
以下总结了Redis与Memcached的四个主要区别。目前业界普遍采用Redis作为缓存方案,且其功能生态日益强大。
- 数据类型丰富度:Redis支持更丰富的数据结构,包括String、List、Set、Hash、Sorted Set (ZSet),适用于更复杂的应用场景。而Memcached仅支持简单的key-value(字符串或二进制)类型。
- 数据持久化:Redis支持将内存中的数据持久化到磁盘,重启后可重新加载使用。Memcached则将数据完全存储在内存中,重启即丢失。
- 集群模式:Memcached本身不支持原生的集群模式,需要依赖客户端实现数据分片。而Redis原生支持Cluster集群模式。
- 线程模型:Memcached采用多线程、非阻塞IO复用的网络模型。Redis则使用单线程的多路IO复用模型(6.0版本后引入多线程处理网络IO,但核心命令处理仍是单线程)。
下图清晰地对比了两者的特性差异:
Redis常见数据结构以及使用场景分析
1. String(字符串)
常用命令: set, get, decr, incr, mget 等。
String是最基本的数据类型,是简单的key-value结构。value不仅可以是字符串,也可以是数字(Redis会自动识别)。
- 典型应用:常规的key-value缓存,如会话(Session)存储。
- 计数场景:利用
incr/decr命令实现微博数、粉丝数等计数器功能。
2. Hash(哈希)
常用命令: hget, hset, hgetall 等。
Hash是一个String类型的field(字段)和value(值)的映射表。它特别适合用于存储对象。后续你可以直接修改这个对象中的某个字段,而无需操作整个对象。
示例:存储用户信息。
key=JavaUser293847
value={
“id”:1,
“name”:“SnailClimb”,
“age”:22,
“location”:“Wuhan,Hubei”
}
3. List(列表)
常用命令: lpush, rpush, lpop, rpop, lrange 等。
List本质上是链表。Redis的List应用场景非常广泛,是实现如微博关注列表、粉丝列表、消息队列等功能的理想数据结构。
Redis的List实现为双向链表,支持反向查找和遍历,操作方便,但会带来额外的内存开销。
一个很棒的特性是可以通过lrange命令实现分页查询,例如微博中“下拉不断加载更多”的功能,基于此实现性能极高。
4. Set(集合)
常用命令: sadd, spop, smembers, sunion 等。
Set提供的功能类似于列表(List),但其特殊之处在于自动去重。当你需要存储一个列表数据,又不希望出现重复数据时,Set是绝佳选择。Set还提供了判断某个成员是否在集合内的接口。
Set可以轻松实现交集、并集、差集操作。
示例:在社交应用中,将用户的所有关注人存储在一个Set中,所有粉丝存储在另一个Set中。Redis可以方便地计算出“共同关注”、“共同粉丝”。
sinterstore key1 key2 key3 # 求 key2 和 key3 的交集,并存储到 key1
5. Sorted Set(有序集合)
常用命令: zadd, zrange, zrem, zcard 等。
与Set相比,Sorted Set增加了一个权重参数score,使得集合中的元素能够按照score进行有序排列。
应用场景:实时排行榜系统,如直播间在线用户排行榜、礼物热度榜、按时间排序的弹幕消息列表等。
Redis设置过期时间
Redis允许为存储在其中的键值对设置一个过期时间(TTL),这对于缓存数据库来说极为实用。例如,项目中的用户令牌(Token)、登录信息或短信验证码通常都有时效性。如果使用传统数据库自行判断过期,会严重影响性能。
在使用SET命令时,可以通过EX参数指定键的存活时间(秒)。
那么问题来了:假设你设置了一批key在1小时后过期,1小时后Redis是如何删除它们的呢?
答案是:定期删除 + 惰性删除。
- 定期删除:Redis默认每隔100ms随机抽取一部分设置了过期时间的key,检查其是否过期,过期则删除。随机抽取是为了避免遍历全部过期key给CPU带来过大压力。
- 惰性删除:定期删除可能导致某些过期key未能被及时清理。当客户端尝试访问一个key时,Redis会先检查该key是否已过期,如果过期则立即删除并返回空。这就是“惰性”的体现。
然而,仅靠这两种策略仍有隐患:如果大量过期key在内存中堆积,既未被定期删除抽查到,也长期无访问触发惰性删除,就会导致内存被无意义的数据占满。如何解决?这就引出了下一节的内容。
Redis内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
当Redis内存使用达到上限(通过maxmemory配置)时,便会触发内存淘汰机制。在配置文件redis.conf中有详细说明。Redis提供了6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集中,淘汰最近最少使用的数据。
- volatile-ttl:从已设置过期时间的数据集中,淘汰即将过期的数据。
- volatile-random:从已设置过期时间的数据集中,随机淘汰数据。
- allkeys-lru(最常用):当内存不足时,从所有键空间中淘汰最近最少使用的key。
- allkeys-random:从所有键空间中随机淘汰数据。
- no-enviction:禁止淘汰数据。当内存不足时,新写入操作会报错。生产环境一般不会使用。
Redis持久化机制(怎么保证Redis挂掉之后再重启数据可以进行恢复)
Redis支持两种持久化方式,将内存数据保存到硬盘,以便在重启或故障后恢复。
RDB(快照)持久化
RDB是Redis默认的持久化方式。它通过创建某个时间点的数据快照(Snapshot)来实现。你可以对快照进行备份、复制到从服务器,或用于重启恢复。
在redis.conf中,默认配置如下,定义了触发快照保存的条件:
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
AOF(追加文件)持久化
AOF持久化的实时性优于RDB,已成为主流方案。需在配置中开启:
appendonly yes
开启后,每执行一条会修改数据的命令,Redis都会将其追加到AOF文件末尾。AOF文件的位置可通过dir参数设置,默认名为appendonly.aof。
AOF提供了三种同步策略(appendfsync):
appendfsync always:每次写命令都同步写入磁盘,数据最安全,但性能影响最大。appendfsync everysec(推荐):每秒同步一次,是性能与安全性的良好折衷,最多丢失一秒数据。appendfsync no:由操作系统决定同步时机,性能最好,但数据丢失风险最高。
Redis 4.0+ 混合持久化
Redis 4.0开始支持RDB与AOF的混合持久化(通过aof-use-rdb-preamble配置开启)。开启后,在执行AOF重写时,会先将当前数据以RDB格式写入AOF文件开头,然后再追加后续的AOF命令。这样结合了RDB快速加载和AOF丢失数据少的优点,但文件可读性变差。
Redis事务
Redis通过MULTI(开启事务)、EXEC(执行事务)、WATCH(监视键)等命令支持事务。事务将多个命令打包,然后一次性、顺序地执行。在执行期间,服务器不会中断事务去处理其他命令。
在Redis中,事务总是保证原子性(所有命令要么全部执行,要么全部不执行)、一致性和隔离性。在特定持久化模式下,也能保证持久性。但需要注意,Redis事务不支持回滚(Rollback),这与传统关系型数据库不同。
缓存雪崩和缓存穿透问题解决方案
缓存雪崩
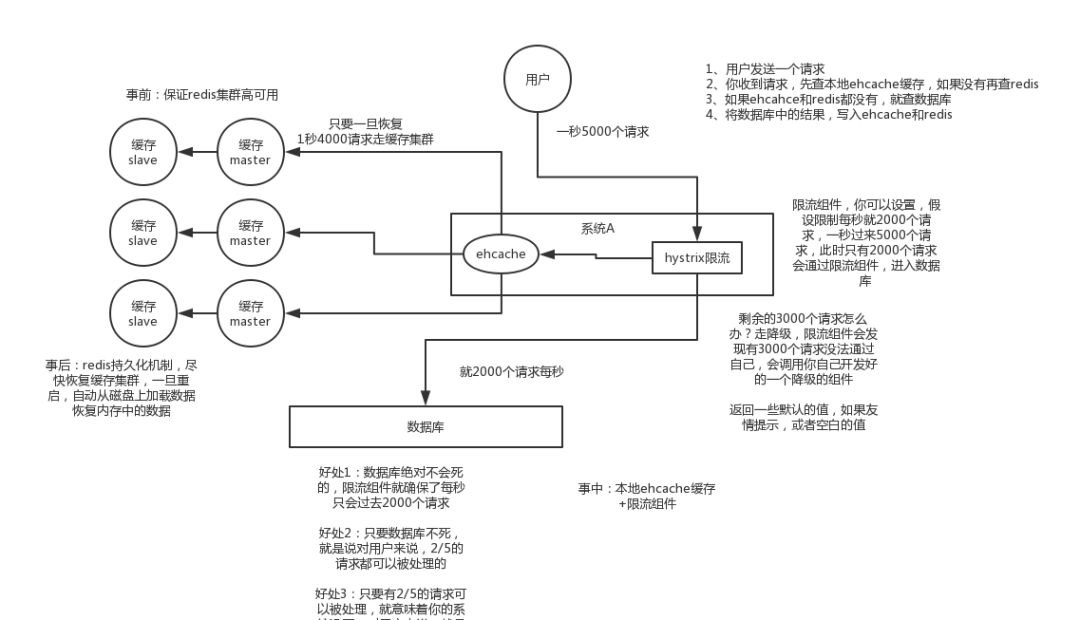
问题描述:大量缓存数据在同一时间点大规模失效,导致所有请求瞬间涌向数据库,造成数据库压力过大甚至崩溃。
解决方案(分层防御):
- 事前:保证Redis集群的高可用性,避免单点故障。合理设置不同key的过期时间,使其均匀分布,避免集中失效。
- 事中:采用本地缓存(如Ehcache)作为二级屏障,并结合限流降级组件(如Hystrix/Sentinel),当流量激增时,对请求进行限流或返回降级内容,保护数据库。
- 事后:利用Redis的持久化机制(RDB/AOF)快速恢复缓存数据。
缓存穿透
问题描述:查询一个数据库中必然不存在的数据(如ID为负数的用户),导致每次请求都无法命中缓存,直接穿透到数据库。这可能是恶意攻击所致。
解决方案:
- 布隆过滤器(Bloom Filter):将所有可能存在的数据哈希到一个足够大的位图(bitmap)中。一个一定不存在的数据会被这个过滤器拦截,从而避免对底层数据库的查询压力。这是最经典的解决方案。
- 缓存空对象:更为简单直接的方法。如果一个查询返回的数据为空(无论数据不存在还是系统故障),我们仍然将这个空结果(如
null)进行缓存,但为其设置一个较短的过期时间(例如5分钟)。这样可以有效应对短时间内的恶意攻击。
如何解决Redis的并发竞争Key问题
问题描述:多个系统或线程同时对一个key进行操作(如先读后写),由于执行顺序的不确定性,导致最终结果与预期不符。
推荐方案:使用分布式锁来保证对某个key操作的互斥性。ZooKeeper和Redis本身都可以实现分布式锁。
- 基于ZooKeeper:利用临时有序节点实现。每个客户端尝试加锁时,在指定目录下创建一个唯一的瞬时有序节点。判断是否获取锁只需检查序号最小的节点是否为当前节点。释放锁时删除该节点即可。此方案可靠性高,能避免死锁。
- 基于Redis:通常使用
SET key value NX PX milliseconds命令实现,要求value唯一(如UUID)以安全释放锁。
注意:如果业务场景本身不存在严重的并发竞争,不应滥用分布式锁,否则会影响系统性能。
如何保证缓存与数据库双写时的数据一致性?
这是一个经典难题。只要使用缓存,并涉及数据库与缓存的双写,就必然存在一致性问题。
思路:
- 容忍短暂不一致:对于一致性要求不严格的场景(如浏览量统计),可以接受缓存与数据库存在短暂不一致。通常采用先更新数据库,再删除缓存的策略(Cache-Aside Pattern),并给缓存设置合理的过期时间作为最终兜底。
- 强一致性方案:如果要求强一致,方案会非常复杂且成本高昂。一种思路是将读请求和写请求串行化到同一个内存队列中,保证同一资源的操作顺序性。但这会大幅降低系统吞吐量,通常需要更多的服务器资源来支撑。
希望这份关于Redis的总结能帮助你构建更清晰的知识体系。如果你想深入探讨更多系统设计与高并发相关的技术细节,欢迎在云栈社区与更多开发者交流。
 发表于 2026-4-4 06:26:13
|
查看: 153|
回复: 0
发表于 2026-4-4 06:26:13
|
查看: 153|
回复: 0
