用户对点赞的容忍度有多低?点击后超过500毫秒无反馈,90%的用户会直接划走;同一个内容点赞两次却计为两次数,70%的用户会觉得平台数据有问题。这一个小小的交互按钮,直接关系到社交平台的用户体验与数据可信度。今天,我们就来系统性地拆解,如何构建一个在高并发下仍能保证快速、准确、稳定且低成本的点赞系统。
需求拆解:从模糊到清晰的技术指标
面对一个系统设计问题,第一步永远是化模糊为清晰。点赞系统看似简单,但要设计好,必须先明确以下四个核心需求:
1. 快 — 秒级响应
用户点击后,系统必须瞬间响应。我们关注的是端到端延迟,从用户点击到界面视觉反馈,超过500ms用户就能感知到卡顿。在实际链路中,一次点赞需要经过前端请求、网络传输、服务处理、缓存操作、数据库同步等多个环节,每个环节都可能成为瓶颈。因此,我们必须将目标设定在200ms以内,为每个环节留出充足的余量。
2. 准 — 数据一致性
10万次点赞少算1个,用户可能发现不了;但如果同一用户点了两次赞却计了两次,就会引发投诉。这里的“准”并非强一致性,而是追求 “不丢不重” 与 “最终一致” 。即用户点赞后,即使数据尚未同步到数据库,至少在缓存层面状态和计数必须是正确的;取消点赞时,也不能因并发操作导致计数未减。

3. 稳 — 应对流量洪峰
假设一条热门内容在5分钟内获得100万点赞,平均每秒就是3333次请求,高峰期瞬时可能达到每秒1万次。系统在如此突发的、无规律的流量冲击下,必须保证不崩溃、不丢数据,甚至不能出现明显的延迟抖动。这对系统的弹性、高并发处理能力是极大的考验。
4. 省 — 合理的成本控制
成本控制并非偷工减料,而是对存储资源进行精细化分级利用:
- 热数据:如热门内容的实时点赞数和状态,必须存放在Redis中,保证毫秒级读写。
- 温数据:如近30天的普通内容点赞记录,读写频率中等,可存入MySQL,按需查询,平衡性能与成本。
- 冷数据:超过3个月的历史点赞记录,仅供后台统计与分析,可归档至对象存储等低成本服务。

技术选型:核心工具的权衡
明确了需求,下一步就是选择合适的技术栈。点赞系统的选型,本质是对 高频读写、数据一致性和成本控制 三大矛盾的权衡。
Redis:缓存的不二之选
为什么是Redis而不是Memcached或本地缓存?这要回归点赞场景的核心诉求:高频读写、原子操作、丰富的数据结构支持。
- 数据结构丰富:Hash、Set、Sorted Set等多种结构可以灵活应对不同查询需求。
- 原子操作与Lua脚本:完美解决并发下的状态判断与计数更新问题,是保证数据“准”的关键。
- 持久化机制:RDB+AOF虽然不是核心需求,但能在关键时刻避免缓存数据全部丢失,增加一道保险。
当然,Redis内存成本高于磁盘,因此必须配合精细化的缓存策略,不能无节制地存放数据。
消息队列:异步解耦的核心
异步化是应对高并发的经典手段。在点赞系统中,点赞数更新与数据持久化必须解耦。如果用户点击后需等待数据库写入完成才返回,延迟必然不可控。消息队列正是实现这种异步解耦的核心工具。
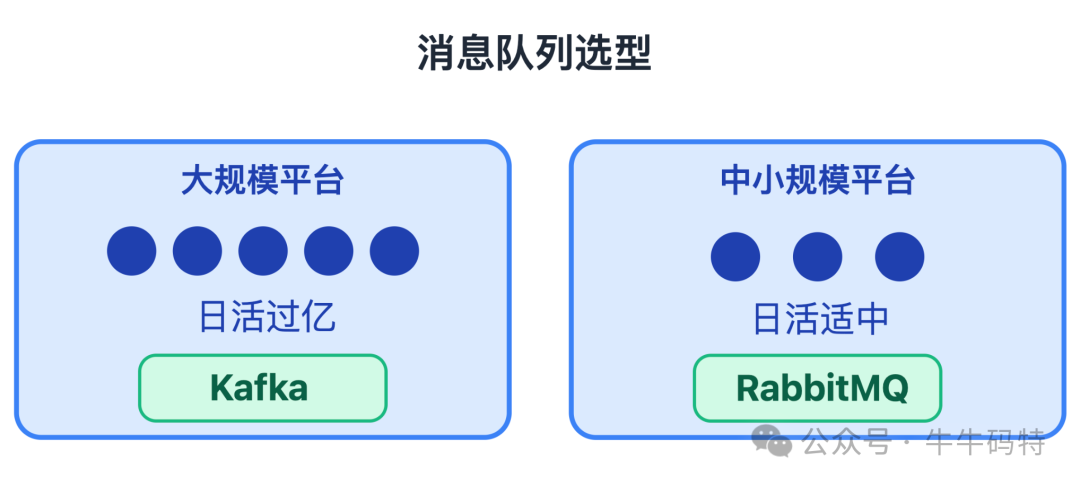
Kafka和RabbitMQ如何选择?
- 大规模平台(日活过亿):点赞消息吞吐量极高,可能达到每秒数万条,此时Kafka的超高吞吐量和强持久化能力更具优势。
- 中小规模平台:RabbitMQ的易用性、丰富的路由策略以及开箱即用的特性(如死信队列处理失败消息)更为友好。
需要注意的是,引入消息队列会带来最终一致性问题,因此必须开启消息确认机制,并建立定期对账流程来修复潜在的数据不一致。
MySQL:数据的最终归宿
既然Redis已经存储了点赞数,为何还需要MySQL?因为Redis本质是缓存,存在数据丢失的风险(如宕机)。用户的点赞记录是核心资产,必须有一份持久化、可靠的存储作为最终归宿。
MySQL的作用就是存储全量点赞记录:谁、在何时、给什么内容点了赞。这些数据不仅用于缓存恢复,更能支撑“我的点赞”列表、按点赞时间排序等后续业务需求。
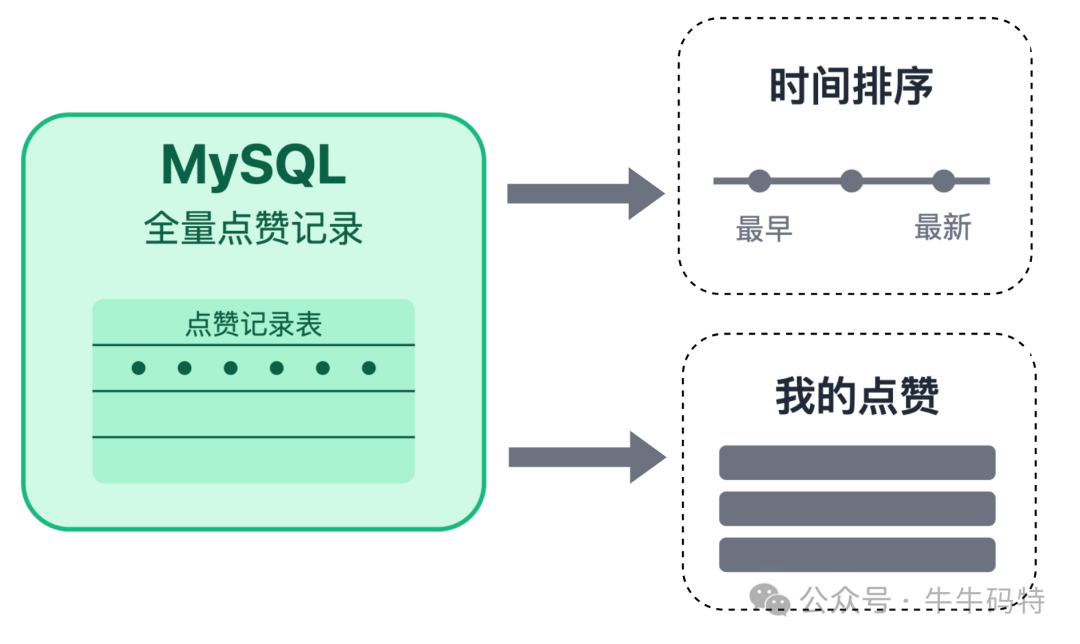
在设计表结构时,索引优化至关重要。例如,通过联合唯一索引防止用户对同一内容重复点赞。
CREATE TABLE `like_records` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',
`user_id` bigint(20) NOT NULL COMMENT '用户ID',
`content_id` bigint(20) NOT NULL COMMENT '内容ID(如动态ID、评论ID)',
`content_type` varchar(20) NOT NULL COMMENT '内容类型(区分动态、评论等)',
`created_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '点赞时间',
`updated_at` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间(取消点赞时更新)',
`is_canceled` tinyint(1) NOT NULL DEFAULT 0 COMMENT '是否取消点赞(0-正常,1-取消)',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_content` (`user_id`,`content_id`,`content_type`) COMMENT '防止重复点赞',
KEY `idx_content` (`content_id`,`content_type`) COMMENT '按内容查点赞记录'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='用户点赞记录表';
uk_user_content 唯一索引从数据库层面杜绝了重复点赞;idx_content 索引则优化了查询某内容所有点赞记录的效率。
架构拆解:四层逻辑处理流程
将上述组件组合起来,便形成了一个典型的高并发点赞系统架构。从用户点击到数据落地,主要经历四层处理逻辑。
前端层:用户体验优先
核心目标是创造“快”的感知,即使后端仍在处理,也要让用户感觉操作已立刻生效。
- 本地即时反馈:用户点击瞬间,按钮颜色改变(如灰变红),并播放“点赞+1”的动画效果。

- 异步发送请求:在动画播放的同时,异步向服务端发送点赞请求。这样即便网络或后端稍有延迟,用户也无感知。
- 失败补偿机制:若网络异常导致请求失败,前端应将操作缓存至本地(如localStorage),待网络恢复后自动重试,并给予用户友好提示。
服务层:业务逻辑中枢
这是点赞业务逻辑的核心,负责三件事:
- 参数校验:验证用户登录状态、内容ID合法性。
- 状态判断:查询Redis,判断用户对该内容是否已点赞。
- 操作执行:根据状态,调用Redis接口进行点赞/取消操作,并发送异步消息到消息队列。
此外,服务层必须保证幂等性,防止用户快速双击导致重复处理。可为每个请求生成唯一ID,并借助分布式锁(Redis实现)确保同一逻辑只被执行一次。
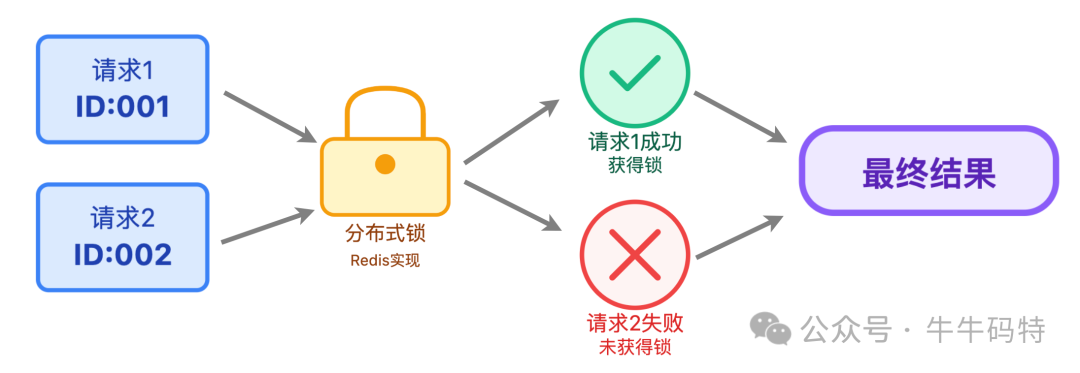
缓存层:Redis存储两类核心数据
Redis是系统的“心脏”,主要存储两类数据:
第一类:用户点赞状态(用户->内容)
使用Set还是Hash取决于业务需求。若仅需判断“是否点赞”,Set足够高效。
// 点赞:将用户ID加入集合
Redis.sAdd("like:status:123", "456");
// 判断是否已点赞
boolean isLiked = Redis.sIsMember("like:status:123", "456");
若需获取点赞用户列表及时间等更多信息,则Hash结构更合适。
// 点赞:记录用户ID和点赞时间戳
Redis.hSet("like:status:123", "456", "1629260800000");
// 获取该内容的所有点赞记录
Map<String, String> allLikes = Redis.hGetAll("like:status:123");
第二类:内容点赞数
使用String类型,Key格式如 like:count:{contentId},通过 INCR/DECR 命令进行原子增减。
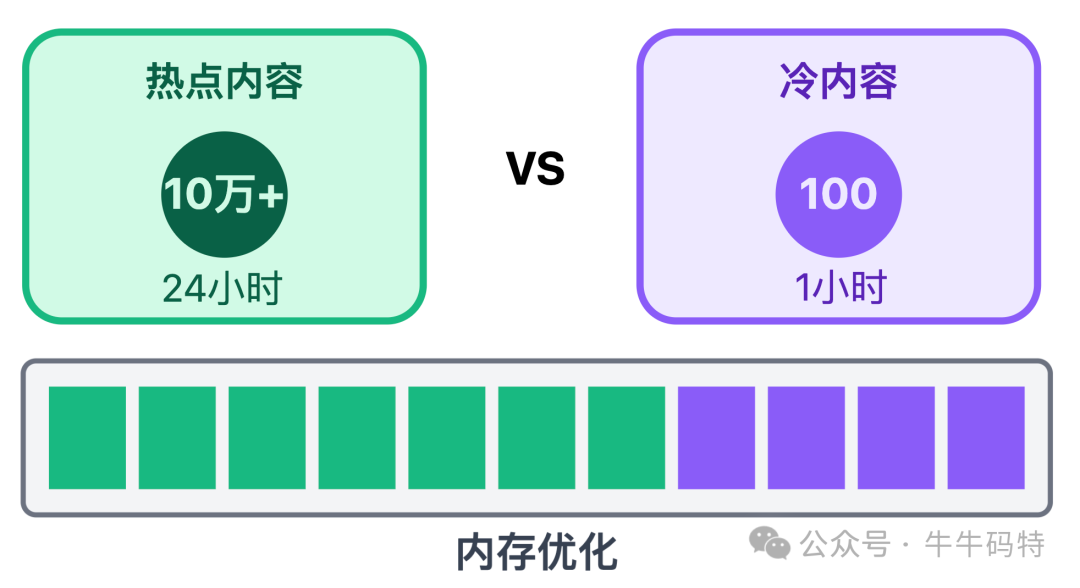
缓存需设置合理的过期策略:热门内容缓存24小时,冷内容缓存1小时,在保证体验的同时节约内存。
持久层:异步数据管道
持久化的核心是 “异步” 。服务层更新Redis后,随即发送一条消息(如“用户A点赞了内容B”)到Kafka,然后立即返回给前端,主流程无阻塞。
后台消费者服务从Kafka拉取消息,异步写入MySQL。这里建议采用逻辑删除而非物理删除:取消点赞时,将记录中的 is_canceled 字段更新为1。这样做的好处是:1) 用户反复点赞/取消时,更新效率更高;2) 保留完整数据,便于后续分析。

关键细节:规避经典陷阱
架构搭好,还需填充关键细节以规避常见陷阱。
Lua脚本:保障原子操作的利器
为什么必须用Lua脚本?看看这个并发场景:内容点赞数为1,用户A和B同时点击“取消点赞”。若服务端先“查状态”再“改计数”,可能发生:
- A查状态(已赞),准备取消。
- B查状态(同样是已赞),准备取消。
- A执行计数-1,状态变为未赞。
- B未察觉状态已变,仍执行计数-1,最终点赞数变为 -1。
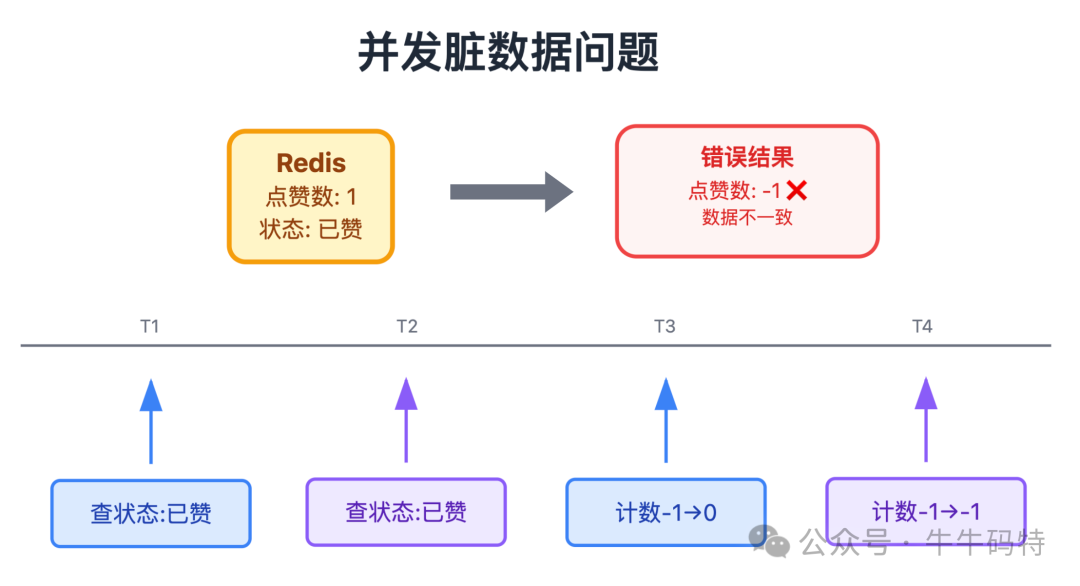
这正是因为“查”与“改”非原子操作,中间可能被其他请求穿插。Lua脚本可以将多个操作打包,由Redis原子性地一次性执行完毕,彻底解决此问题。
-- 判断并取消点赞的Lua脚本示例
local isLiked = redis.call('HEXISTS', 'like:status:123', '456')
if isLiked == 1 then
redis.call('HDEL', 'like:status:123', '456')
redis.call('DECR', 'like:count:123')
end
return 1
缓存过期与穿透防御
缓存不能永驻内存,需有合理的过期策略:
- 主动刷新:用户查看内容时,若缓存失效,则从DB加载并回设缓存。
- 定期同步:通过定时任务将Redis数据同步至MySQL,并刷新缓存过期时间。
- 缓存预热:新内容发布时,主动在Redis中初始化点赞数为0。
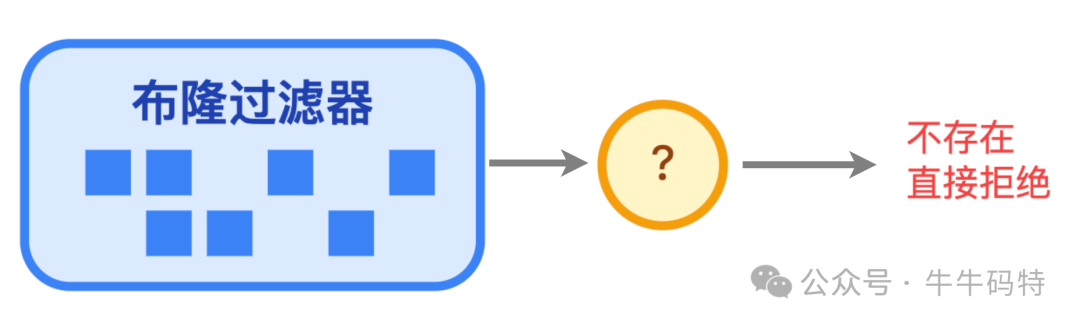
同时,需防范缓存穿透:恶意请求大量不存在的contentId,穿透缓存直接冲击数据库。解决方案:
- 布隆过滤器:在查询前先用布隆过滤器判断内容ID是否存在,不存在则直接拒绝。
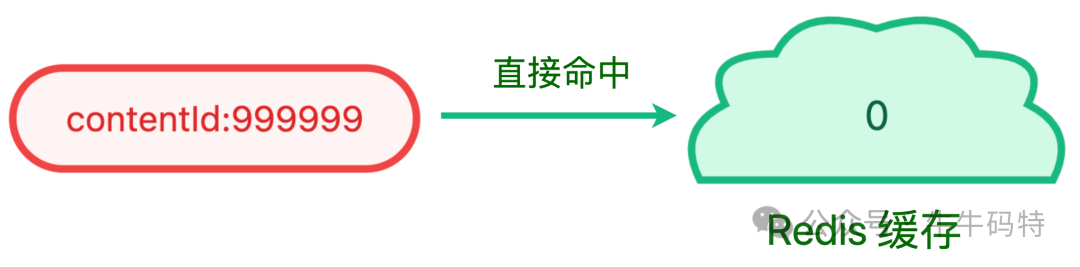
- 缓存空值:即使查询结果为空(内容不存在),也将该Key缓存起来(值为0),并设置一个较短的过期时间(如5分钟)。
优化进阶:从能用走向好用
基础系统跑起来后,还可以通过以下优化进一步提升性能和可靠性。
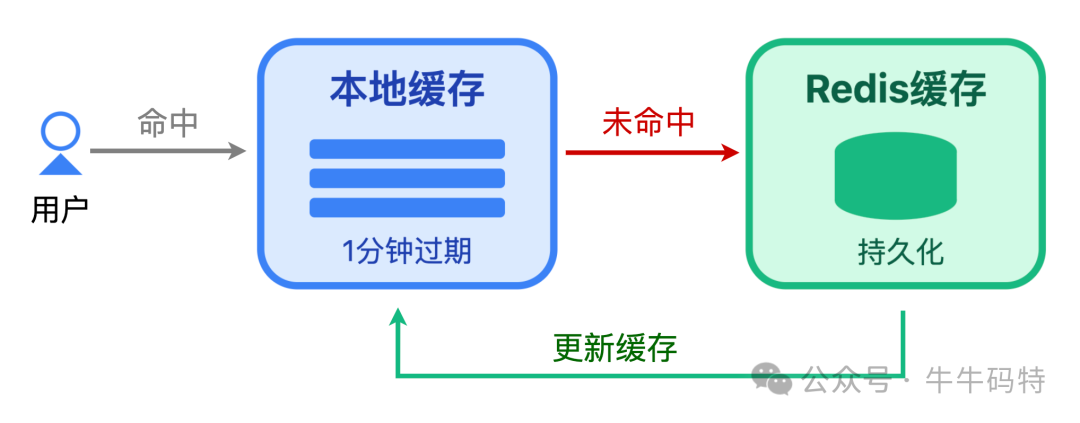
分级缓存:本地缓存 + Redis
对于日活过亿的超大规模应用,单靠Redis可能压力过大。可以引入应用级本地缓存(如Caffeine),形成二级缓存架构。
- 流程:请求先查询本地缓存,命中则直接返回;未命中再查询Redis,并将结果写回本地缓存(设置短过期时间,如1分钟)。
- 价值:能抵挡80%以上的读请求,极大减轻Redis压力。虽然本地缓存存在短暂的数据不一致(1分钟级),但在社交点赞场景下,用户对此延迟基本无感。
读写分离与分库分表
当点赞记录达到千万乃至亿级时,单库单表的MySQL查询压力巨大。解决方案:
- 读写分离:主库负责写入,多个从库负责查询(如“我的点赞列表”),分散读压力。
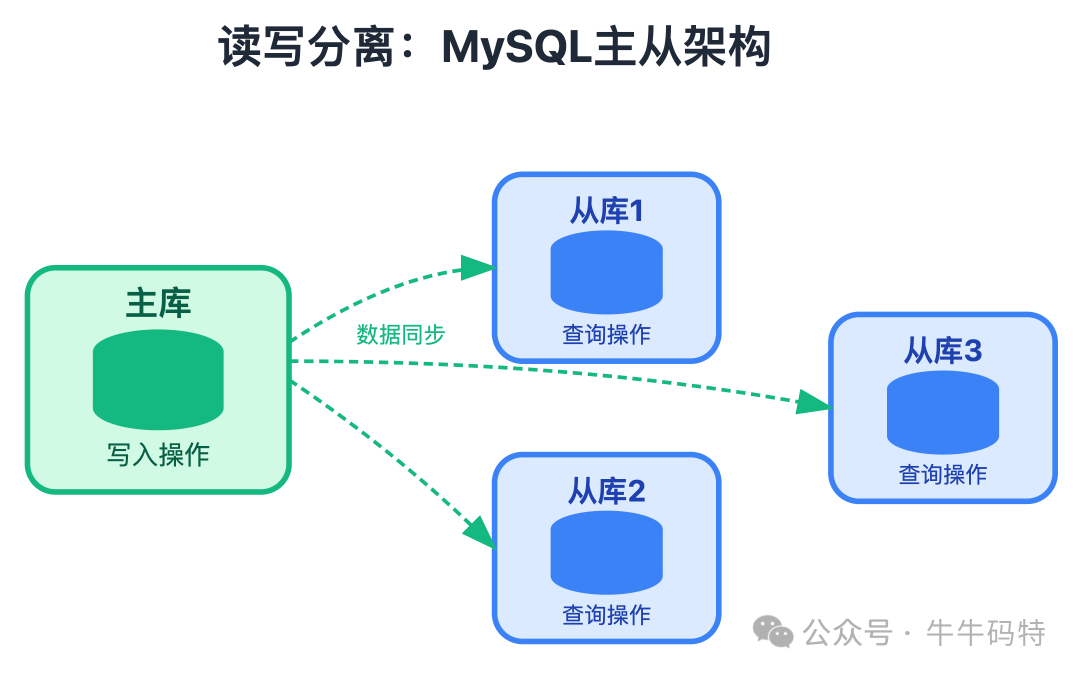
- 分库分表:按
user_id或content_id进行哈希分表,将数据分布到多个物理表中,大幅提升查询性能。
-- 假设按content_id分16张表,查询content_id=12345的记录
SELECT user_id, created_at FROM like_records_9
WHERE content_id = 12345 AND is_canceled = 0
ORDER BY created_at DESC LIMIT 20;
分库分表会引入跨表查询、分布式事务等复杂度,建议在单表数据量超过千万级后再考虑实施。
限流与熔断:系统的自我保护
面对顶流明星官宣等极端场景,瞬时流量可能压垮系统。此时需要最后一道防线:
- 限流:在服务入口或关键接口上限制每秒请求数(如1万QPS),超出部分快速失败或排队。可使用令牌桶等算法实现。
- 熔断:当检测到Redis或MySQL等下游服务连续失败时,自动熔断对该服务的调用,直接返回降级结果(如“点赞成功,稍后显示”),避免雪崩效应。
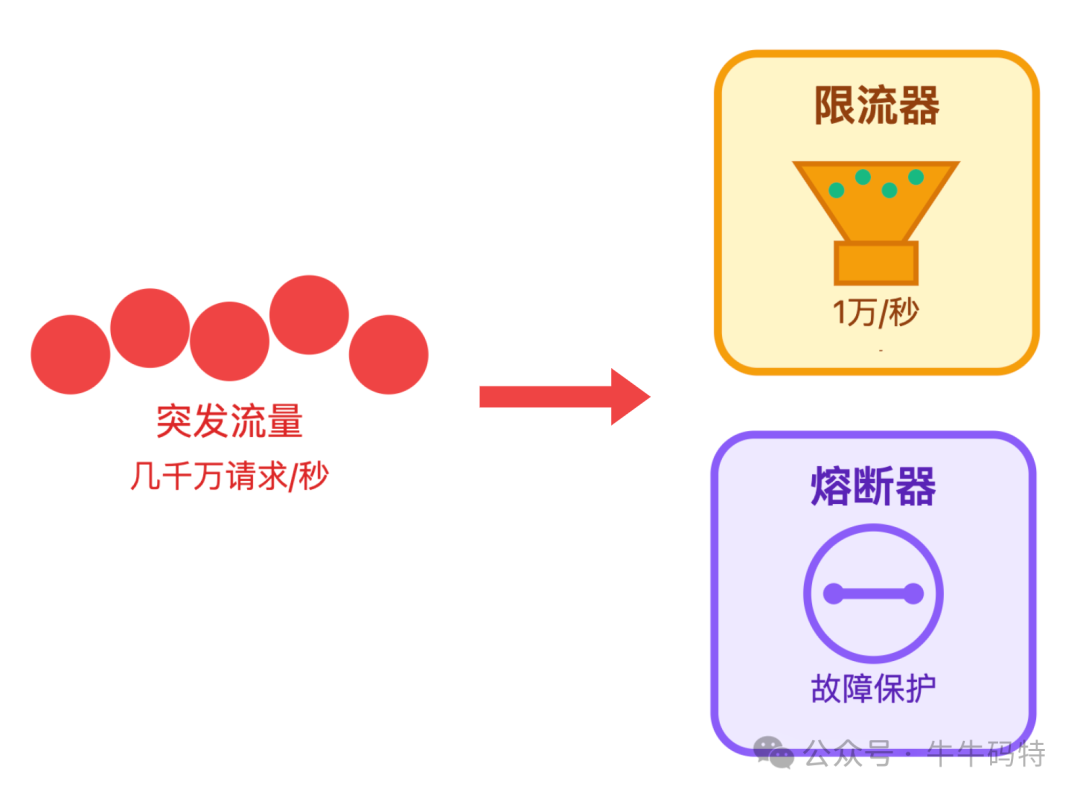
其核心思想是 “保系统优先于保体验” ,牺牲少数请求的即时性,确保整体服务不崩溃。
结语
设计一个高并发点赞系统,不应只盯着炫酷的技术栈,而应始终围绕核心需求展开:
- 为满足“快”,采用前端异步反馈 + 高性能缓存。
- 为达到“准”,依赖Redis原子操作与Lua脚本。
- 为保证“稳”,引入消息队列异步解耦与限流熔断。
- 为实现“省”,践行Redis与MySQL的分级存储策略。
这不仅是点赞系统的设计思路,也是构建大多数高并发系统的通用心法:不追求最前沿的技术,而选择最契合业务现状的方案;能用简单方式解决的问题,绝不无故复杂化,因为对线上系统而言,稳定性永远高于一切。希望这份从需求到细节的完整拆解,能为你下一次的系统设计面试或实战提供清晰的指引。如果你对这类高可用、高并发的架构话题感兴趣,欢迎在云栈社区与更多开发者交流探讨。
 发表于 2026-4-4 06:29:19
|
查看: 186|
回复: 0
发表于 2026-4-4 06:29:19
|
查看: 186|
回复: 0
