在深入探讨技术方案之前,我们必须明确一个核心理念:高可用的评论系统不存在“完美架构”。我们进行技术拆解的目标,并非寻找一个放之四海而皆准的终极方案,而是为特定的业务场景找到最适配的解决方案。
1. 理解评论系统的核心特质
要构建一个高可用的评论系统,首先必须回答它的“灵魂三问”:用户发评论是为了什么?产品通过评论要解决什么问题?技术层面需要应对哪些核心压力?
评论系统对于不同的角色而言,其意义和价值截然不同——这种差异直接决定了技术方案中各个模块的“优先级排序”。

- 对用户而言:评论是“情绪出口”和决策工具。看到剧情高潮想吐槽,购买商品前想查看评价,“能顺畅发表、能痛快浏览”是用户体验的底线。
- 对产品而言:评论是“用户真心话收集器”和内容护城河。其中蕴含的用户反馈比问卷调查真实得多,千万级别的UGC内容积累起来,就形成了用户难以离开的“内容堡垒”。
- 对技术而言:评论是流量放大器。它就像演唱会散场时的地铁站,平时门可罗雀,但在特定时刻会瞬间涌入海量人群,形成脉冲式的流量压力。
面对“百万级实时互动”这样的目标,很多人会感到无从下手。其实,只要将流量压力拆解成几个核心特征,技术目标就会清晰得多。
第一拆:流量比例——读多写少是铁律
如果有10万用户正在发表评论,那么可能同时有200万用户在浏览评论。典型的读写比约为20:1,因此读性能是决定用户体验的关键。

第二拆:流量形态——脉冲式爆发而非平均分布
当热点事件发生时,短短1小时的流量可能就等同于平时10天的总和。因此,系统设计必须按照“峰值流量”来配置资源容量,而在流量低谷时高效利用资源。
第三拆:用户忍耐力——对“慢”宽容,对“崩”零容忍
点赞数从1000变成1001,即使延迟3秒,也少有用户在意。但如果评论区加载时多次出现转圈圈,超过80%的用户会直接离开页面。所以,技术方案必须思路清晰:优先保证功能可用,再优化实时性。

2. 存储与数据层设计
理解了评论系统的特性后,接下来需要明确:海量的评论数据该如何存储?存储是评论系统的基石,如果选型不当,后续的任何性能优化都可能事倍功半。
存储方案对比
首先,我们可以通过一个表格对比三种主流的存储方案:
| 方案 |
适用场景 |
优点 |
缺点 |
| 纯 MySQL(关系型) |
需要保证事务、评论嵌套层级≤3级 |
支持ACID、数据可靠;索引成熟、运维熟悉 |
单表超千万后分页慢;分库分表逻辑复杂 |
| 纯 MongoDB(文档型) |
非结构化内容多、评论嵌套深 |
原生存JSON嵌套、不用拆表;写入比MySQL快30% |
深嵌套查询慢;事务支持弱 |
| MySQL + Redis(混合) |
多数评论业务场景 |
MySQL存全量保可靠;Redis存热点扛读压 |
双写易不一致;系统复杂度高 |
为什么在大部分业务场景下,更推荐第三种 MySQL + Redis 的混合存储方案?并非MongoDB不够优秀,而是它难以同时满足“数据强一致”和“极速查询”这两个最常见且刚性的需求。反观混合方案,恰恰解决了这些痛点:
- 用 MySQL 存储全量数据。无论是需要事务保证的“评论不丢”需求,还是简单的嵌套查询,MySQL 都能很好地胜任,相当于为数据找到了一个“安全保险柜”。
- 用 Redis 缓存热点数据。通常使用
ZSet 存储有序的评论列表,用 Hash 存储评论详情。读请求可以直接从 Redis 中获取,速度比查询 MySQL 快数十倍,完美解决了“刷评论卡顿”的体验问题。
这里自然会引出一个关键问题:双写一致性如何保证?
核心方案是先写 MySQL,确认写入成功后再删除 Redis 中对应的缓存。当后续用户查询时,如果发现 Redis 中没有数据,系统会自动从 MySQL 加载最新数据并回写到 Redis 中。
缓存策略
解决了“存得稳”的问题,接下来就要追求“查得快”。缓存就像冰箱,不是塞得越满越好,而是要根据数据的“热度”按需分层存放。
在高并发场景下,通常需要依赖 「本地缓存 Caffeine + Redis 集群」的组合拳来层层减压:
- 本地缓存 Caffeine:抵御“超热点”的第一道防线
适合缓存5分钟内被查询超过1000次的评论数据,例如爆款文章的前100条评论。其响应速度可达微秒级,比访问 Redis 还要快上百倍。通常配置最大缓存10万条数据,过期时间为1小时。

- Redis 集群:承载“次热点”的主力军
除了那些极致火爆的评论,其余高频访问的数据由 Redis 集群负责。通常根据内容ID进行哈希分片,例如分为16个分片,以避免热点Key集中导致的单点压力。

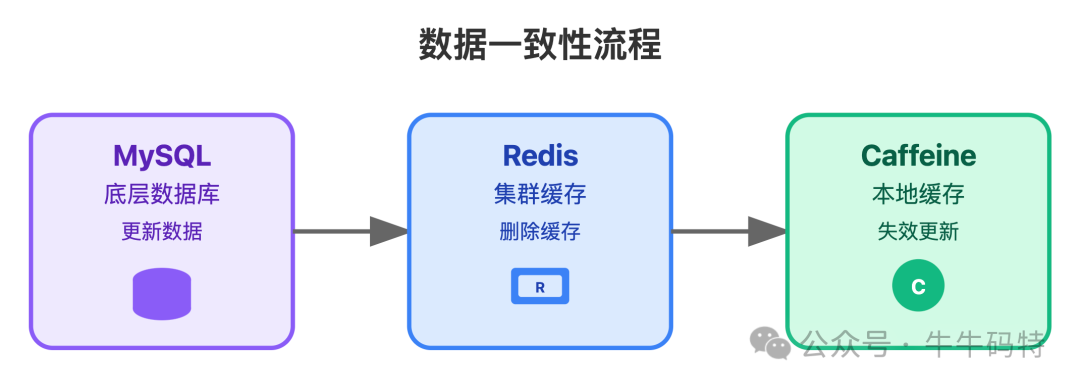
你可能会问,本地缓存、Redis 和 MySQL 之间,数据不一致怎么办?
核心思路是抓大放小:优先保证最终一致性,不必强求实时同步。例如,在更新评论内容或点赞数时:
- 先更新 MySQL 底库,成功后删除 Redis 缓存。
- 对于本地缓存,采用 「定时校验 + 主动失效」 的双重保险——每10分钟从 Redis 拉取最新数据对比,不一致则更新;同时,如果评论被修改,也会主动删除对应的本地缓存。
这样一来,即便出现极短时间的数据延迟,用户刷新一下页面即可看到最新内容,既不影响核心体验,也避免了复杂的实时同步逻辑给系统带来额外的复杂性。
分库分表策略
当 MySQL 单表数据超过千万级别时,查询性能会急剧下降。此时就必须引入分库分表。通常有三种主流的分表策略:
1. 按内容 ID 哈希分片
适用于热点比较分散的场景,例如普通资讯内容的评论。
路由公式为:tableIndex = contentId % 32,即将数据分散到32张表中。
但此策略有一个致命缺陷:爆款内容的所有评论会集中在一张表上。例如,某个热点新闻的评论可能占到全站的80%,全部挤在一张表里,查询时性能瓶颈会非常突出。
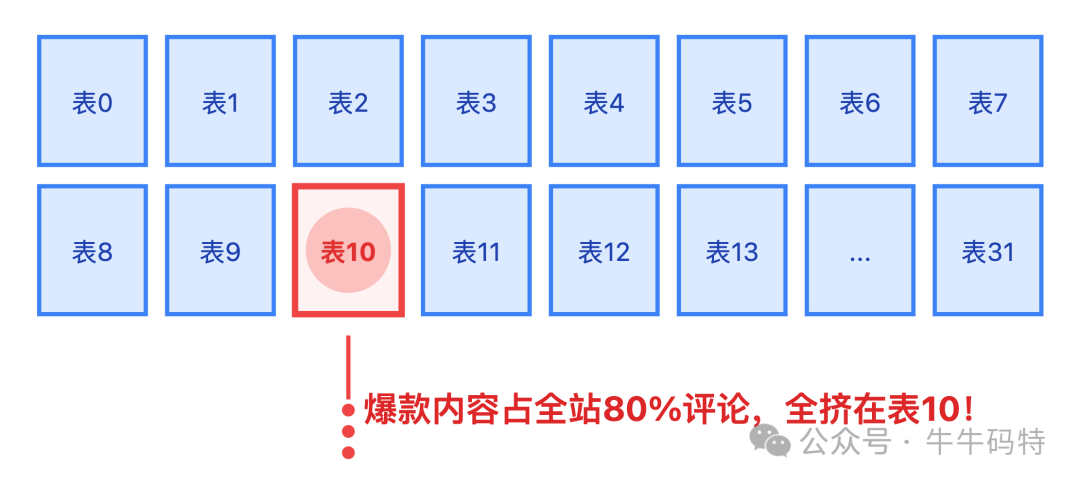
2. 按时间 + ID 复合分片
适用于访问量随时间明显衰减的内容,如新闻、短视频评论。
路由公式为:tableIndex = (contentId % 8) + (month % 4),同样产生32张表。
例如,3月的数据落在表0-7,4月的数据落在表8-15。查询历史数据时,只需扫描对应月份的分表,避免了全量扫描。但跨月数据的查询需要进行多表聚合,业务层处理逻辑会变得复杂。

3. 热点表单独拆分
针对可能出现的极端热点(如明星账号、重大社会事件),可以预设若干张热点表,并通过监控触发数据迁移。
实现逻辑分为三步:
- 监控:监控所有表的写入QPS,当某个
contentId 在5分钟内新增评论超过1万条时,将其标记为“热点”。

- 迁移:将该
contentId 下的评论从普通表迁移到预设的热点表中。在热点表内部,可以再按 user_id 哈希分到多张子表,避免单表压力过大。
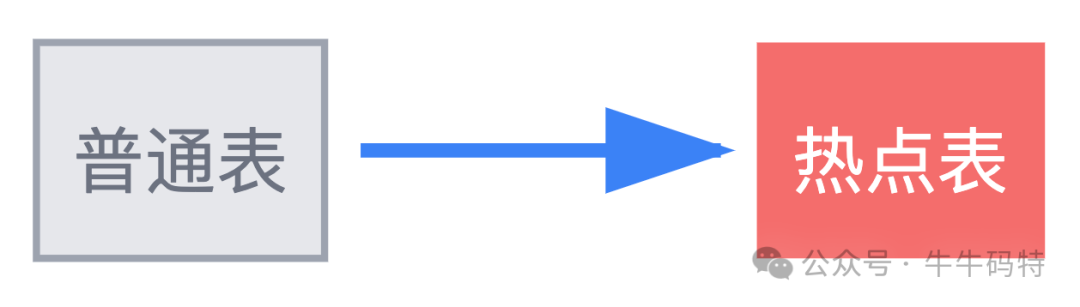
- 访问:查询时,优先访问热点表,如果未命中,再回查普通表。
分库分表的核心难题往往不是选择策略,而是如何实现用户无感知的平滑迁移。正确的姿势是采用 “双写 + 校验” 的四个阶段:
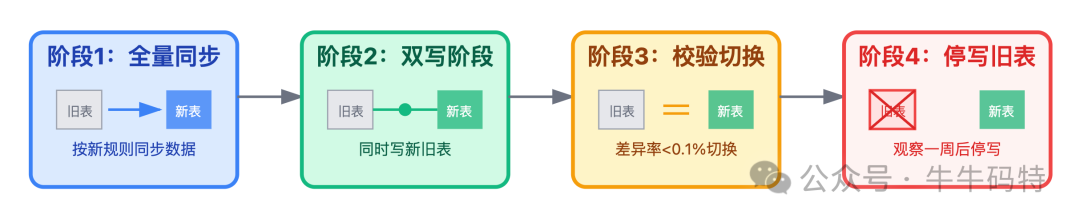
阶段1:全量同步。将旧表数据按新分表规则同步到新表。
阶段2:双写阶段。应用层代码修改,同时向旧表和新表写入数据。
阶段3:校验切换。编写脚本对比新旧表数据,当差异率低于0.1%时,说明双写逻辑可靠,此时将读流量切换至新分表。
阶段4:停写旧表。观察新分表运行稳定一周后,停止写入旧表,完成最终迁移。
通过这四个阶段,可以实现全程零停机,用户完全无感知。
3. 架构演进路径
搞定了存储、缓存和分库分表这些基础组件,接下来就是如何将它们组合成一个健壮的系统。系统架构并非一蹴而就,而应随着业务发展逐步演进,通常可以分为三个阶段:
1.0 青铜时代:单体架构
由 「单应用服务 + 单 MySQL + 本地缓存 Caffeine」 组成。这种架构特别适合业务初期,例如产品刚上线、日活跃用户在10万以内,评论功能仅需支持基础的发布、查询和点赞。
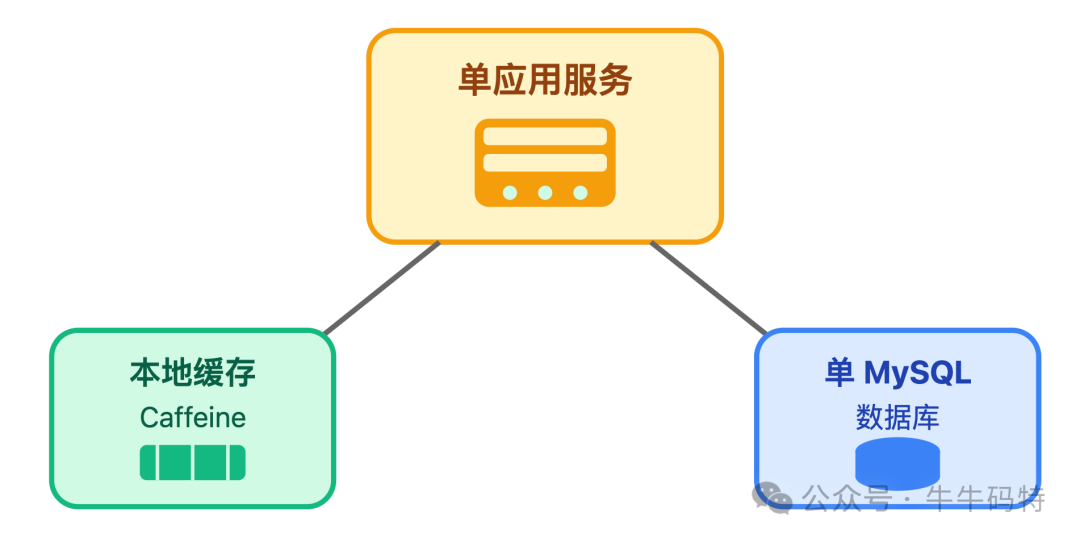
它的优点明确:开发速度快、运维简单、成本低廉。然而,一旦用户量开始增长,问题便会接踵而至:
- 数据库最先扛不住:单台 MySQL 在流量早高峰时CPU经常跑满。
- 单表性能崩溃:当评论表数据超过200万行,执行
LIMIT 2000,10 这样的分页查询可能需要扫描半张表,用户体验极差。
- 故障影响面太大:一旦应用服务器发生内存溢出等问题,整个评论功能会“一锅端”地宕机。

2.0 白银时代:垂直拆分
当单体应用难以支撑时,第一步通常是“分家”。核心思路是将 「评论发布/查询」 和 「点赞互动」 拆分为两个独立的服务,避免互相拖累。
- 评论发布/查询服务:负责发评论、删评论、查列表,核心目标是 「数据可靠」。
- 互动服务:负责点赞、回复、@用户,核心目标是 「高并发、低延迟」。
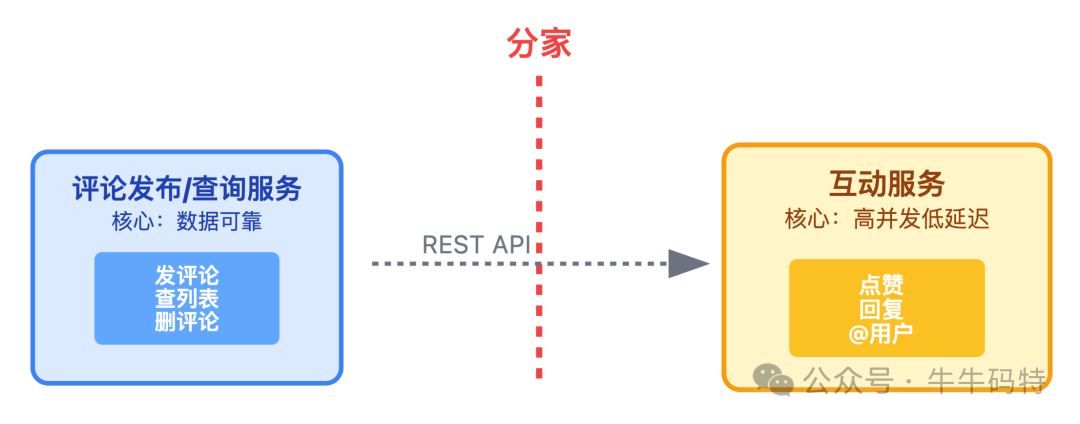
服务间通过 REST API 进行协作。数据层也随之优化:
- 实施 MySQL 读写分离:评论服务写主库,互动服务读从库。
- 增加缓存:在互动服务中引入 Redis 缓存点赞数,Key 格式如
comment:like:{id},设置合理的过期时间,减轻数据库压力。
这个架构解决了查询性能瓶颈和故障影响面过大的问题,能够支撑10万到80万的日活场景。但随着业务规模进一步扩大,跨服务调用延迟、数据一致性、代码冗余 等新的分布式系统典型问题开始浮现。
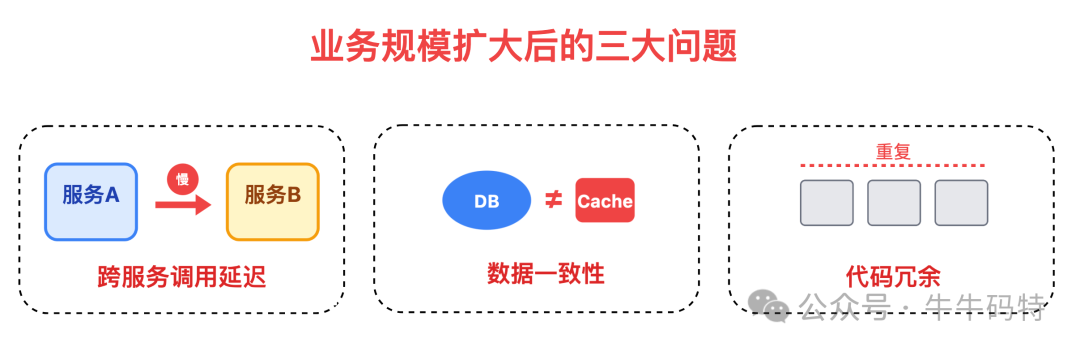
尤其是当单库写入QPS超过5000后,就必须考虑拆分单库,迈向更彻底的分布式架构。
3.0 黄金时代:分布式架构
分布式架构是支撑 “百万级用户实时互动” 的最终形态。其核心思想是将系统拆分为多个职责分明、又能协同工作的层次,形成 「分层防御」 的体系。
接入层:用户请求的第一道关卡
接入层的核心作用是 过滤无效流量、精准分发请求。
- LVS + Nginx 负载均衡集群:2台 LVS 物理机负责四层TCP流量分发,将请求均匀转发至后端的4台 Nginx 服务器。
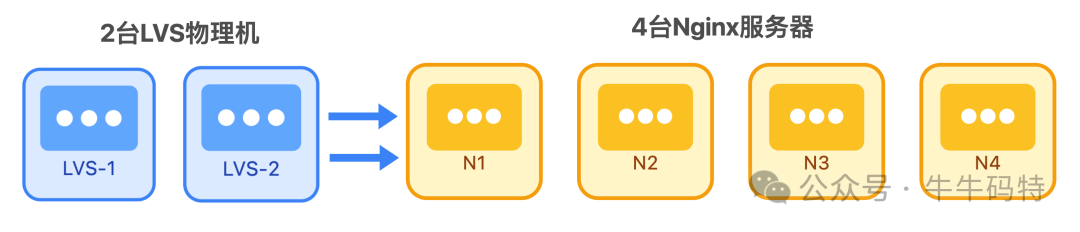
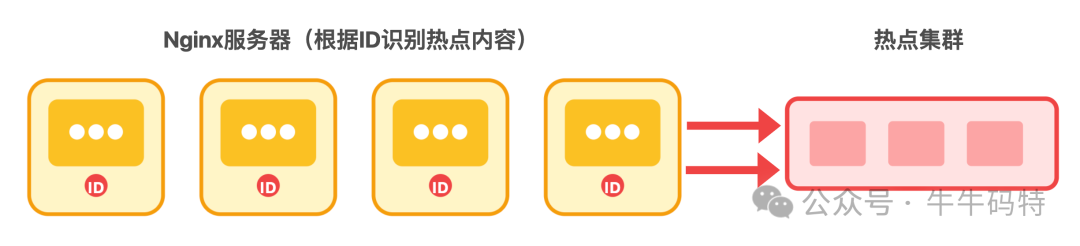
- Nginx 基于七层HTTP协议进行更精细的路由,例如根据内容ID识别热点内容,并将这类请求直接导向专用的“热点集群”,防止常规集群被突发流量击垮。
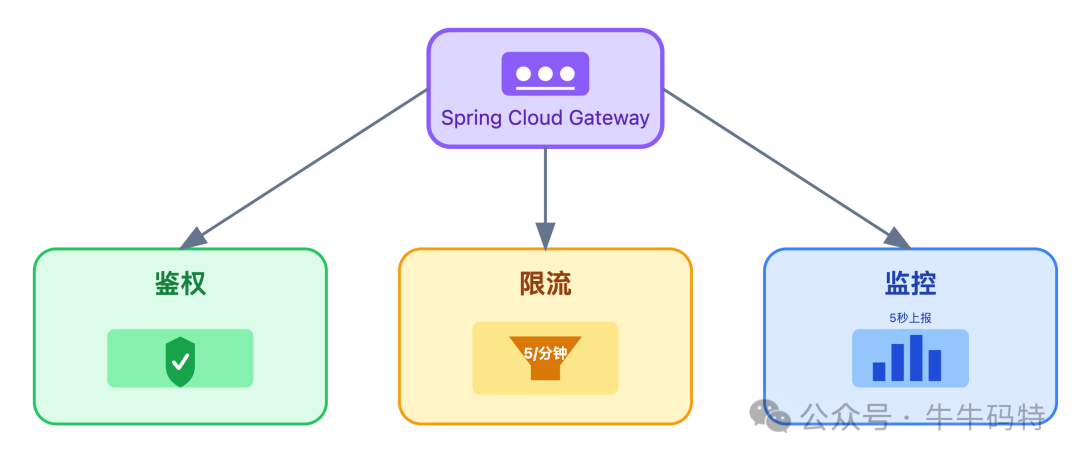
- 自研 API 网关:基于 Spring Cloud Gateway 开发,集成三大核心能力:
- 鉴权:校验用户Token与设备特征,拦截绝大部分恶意请求。
- 限流:例如,限制单用户每分钟最多发布5条评论。
- 监控:每5秒上报一次QPS、延迟等关键指标,为流量预警提供数据支撑。
应用层:微服务各司其职
这一层是业务逻辑的核心,按照“单一职责”原则拆分为多个微服务。
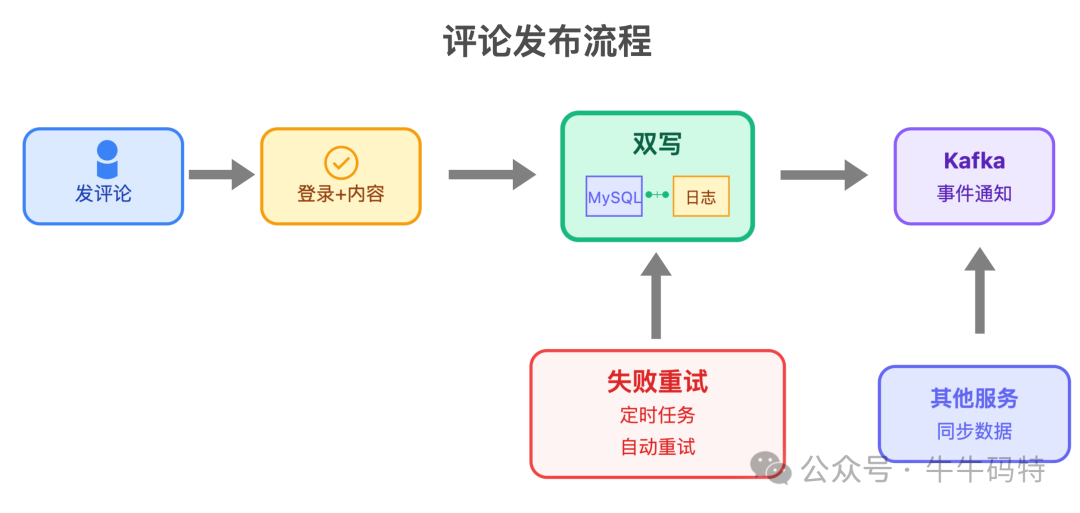
- 评论发布服务:专注于评论的发布与删除,设计上最重视 「数据不丢」。采用“双写 + 操作日志”的机制:先写入 MySQL 并记录日志,失败则通过定时任务自动重试;同时将“评论发布事件”发送到 Kafka 消息队列,供其他服务消费。
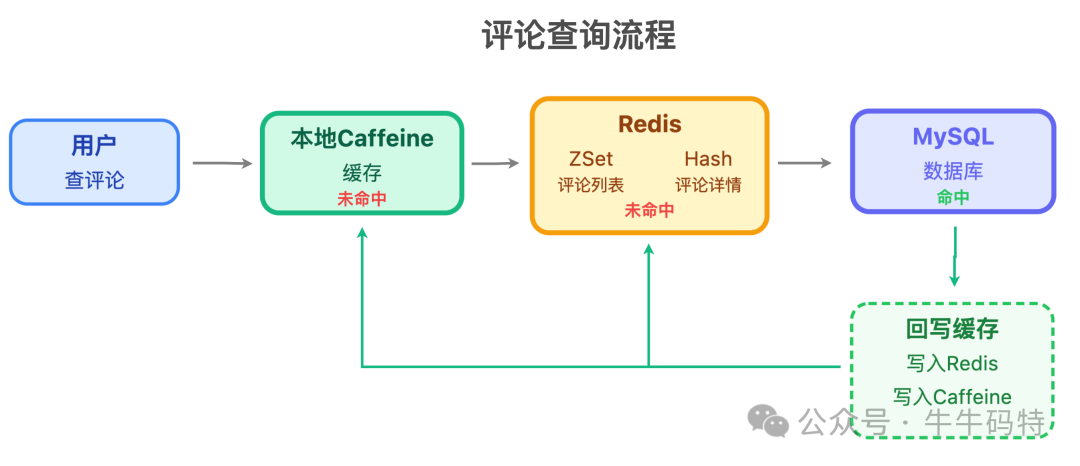
- 评论查询服务:负责加载评论列表和详情,核心目标是 「查询极速」。设计了多级缓存策略:用户查询时,依次检查本地 Caffeine -> Redis -> MySQL,并在命中后回写缓存。同时具备缓存预热和自动降级能力(如 Redis 故障时直连 MySQL)。
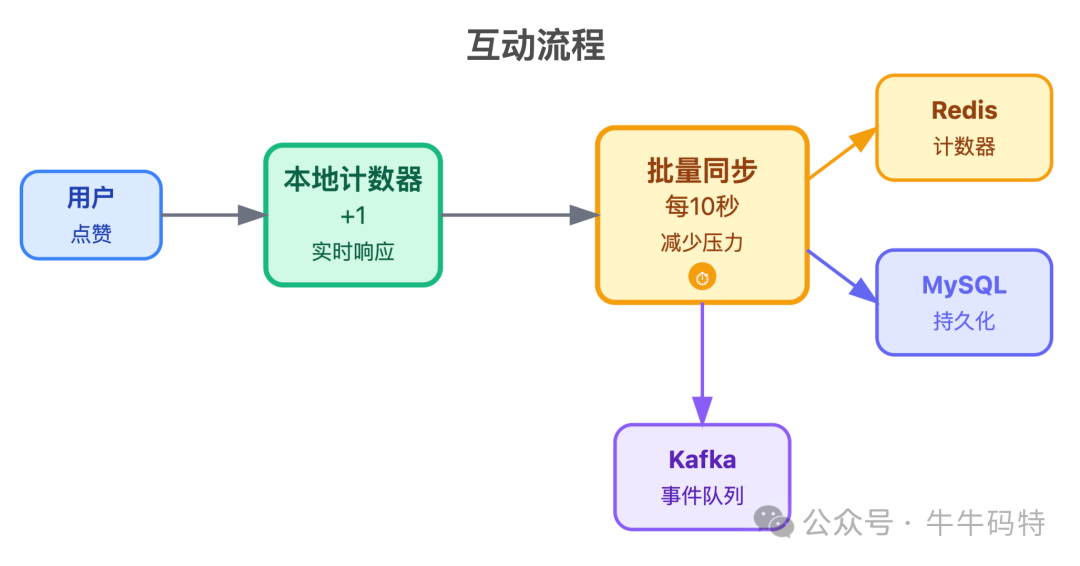
- 互动服务:处理点赞、回复等操作,核心需求是 「高并发」。点赞数更新采用“本地内存计数器 + 批量同步”策略:用户操作后先在本地累加,每10秒批量同步至 Redis,同时通过 Kafka 异步持久化到 MySQL,兼顾了实时性与数据库压力。
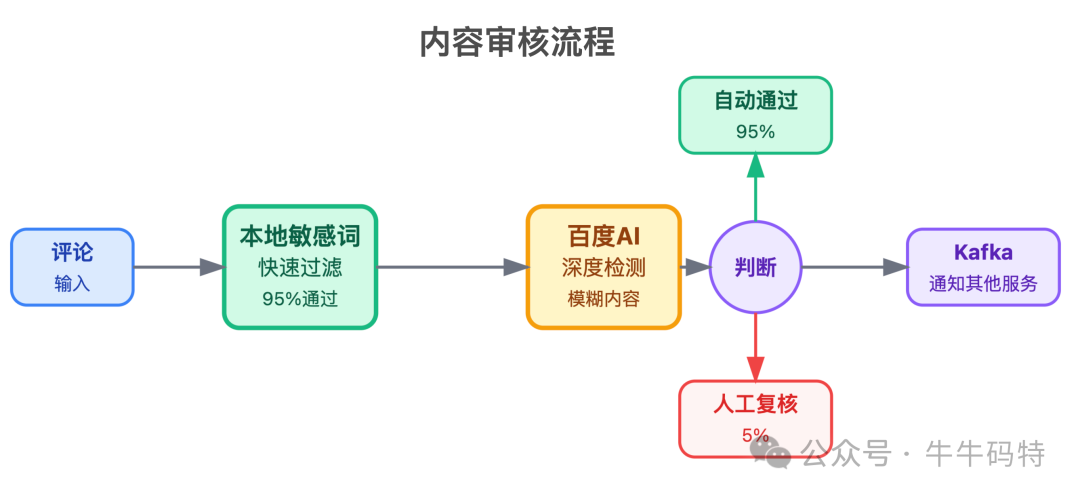
- 内容审核服务:过滤敏感内容,采用 「预审核 + 人工复核」 机制。先经过本地敏感词库快速过滤(通过率约95%),未命中的模糊内容再调用第三方AI接口检测,可疑内容转入人工队列。审核结果通过 Kafka 通知下游服务。
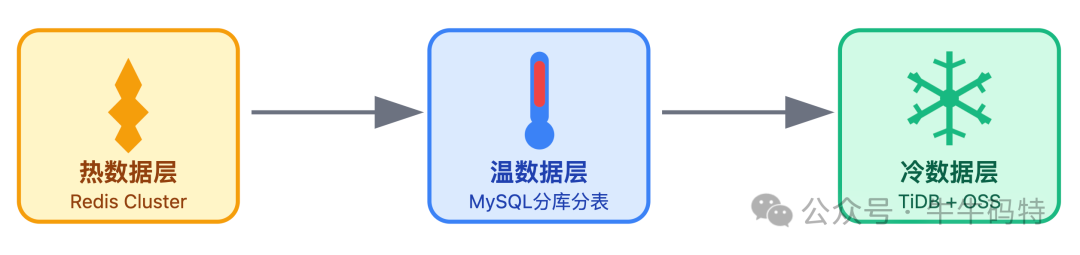
数据层:数据分层存储
根据数据的访问频率和特性,匹配不同的存储方案,实现热数据快取、全量数据可靠、冷数据低成本。
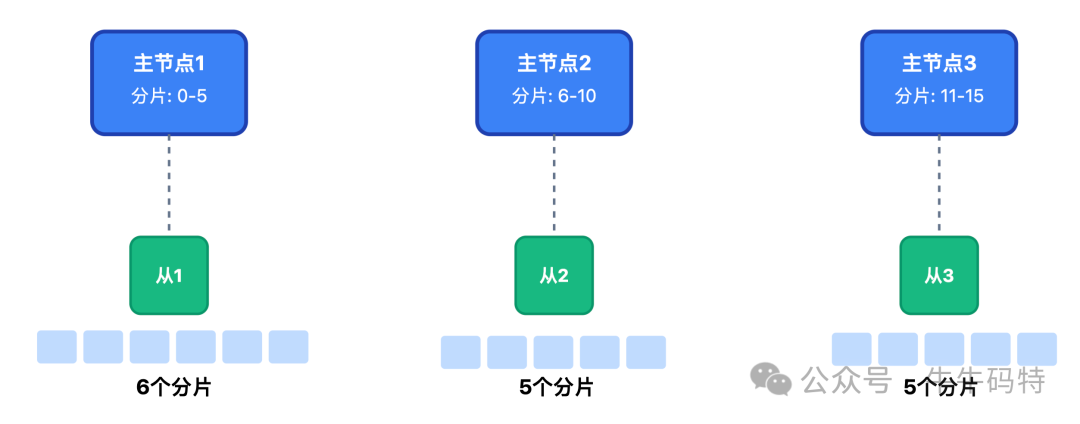
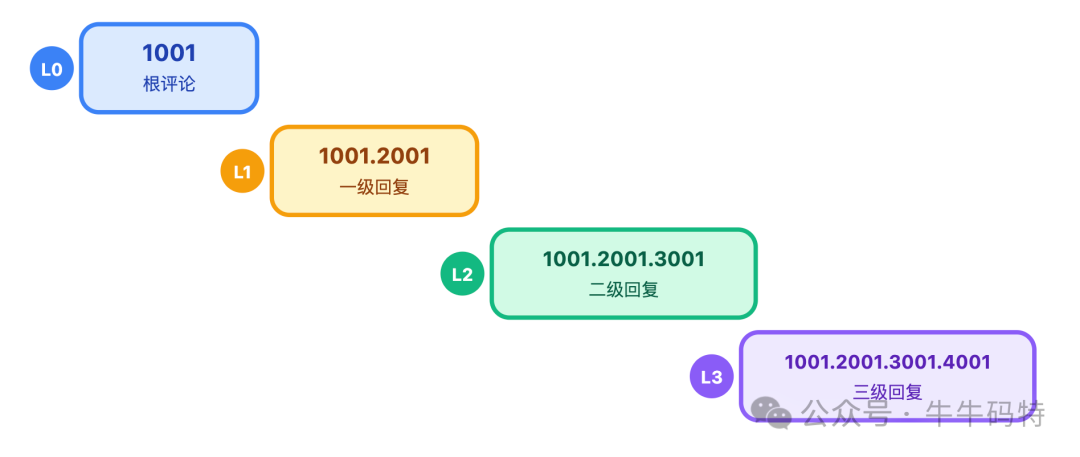
- 热数据层 (Redis Cluster):存储评论列表(ZSet)、详情(Hash)、点赞数(String)等高频访问数据。采用16个分片,3主3从架构。对于嵌套回复,使用“父ID+层级路径”(如
1001.2003.3005)的扁平化设计,前端负责组装层级,降低后端复杂度。
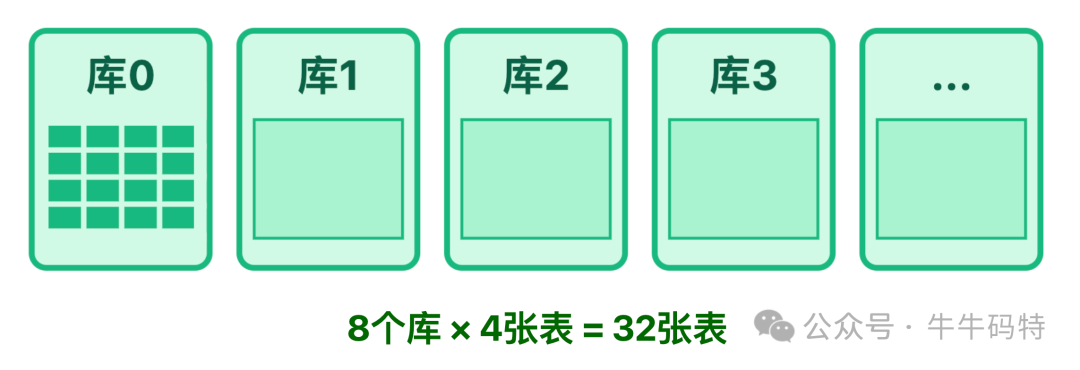
- 温数据层 (MySQL 分库分表):采用 「基础哈希分片 + 热点隔离」 策略。按
content_id % 8 分8个库,每个库 user_id % 4 分4张表,共32张表。同时预设热点表,通过监控 Binlog 将爆款内容的评论动态迁移至独立的热点表。
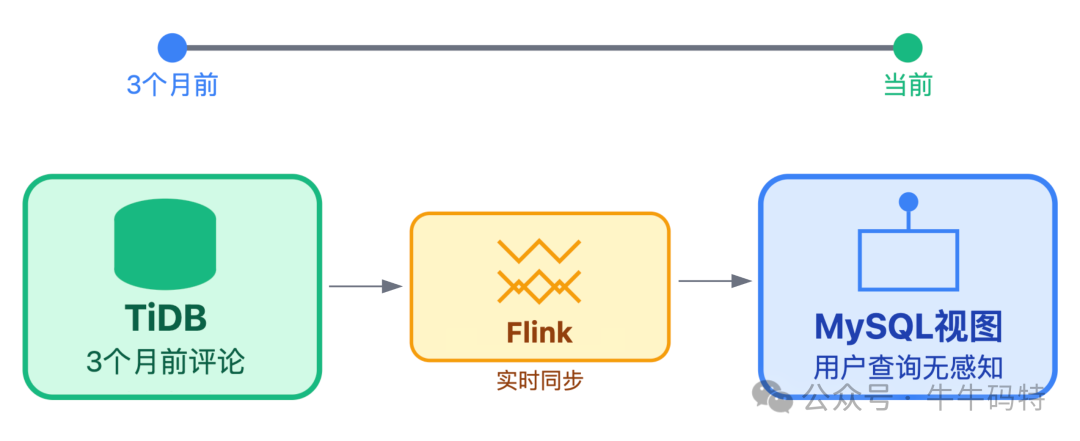
- 冷数据层 (TiDB + OSS):将3个月前的历史评论迁移至 TiDB,并通过 Flink 实时同步到 MySQL 的只读视图,保证用户查询无感知。评论中的图片、视频等大资源存储在对象存储 OSS 中,MySQL 仅保存URL。
中间件层:解耦与削峰
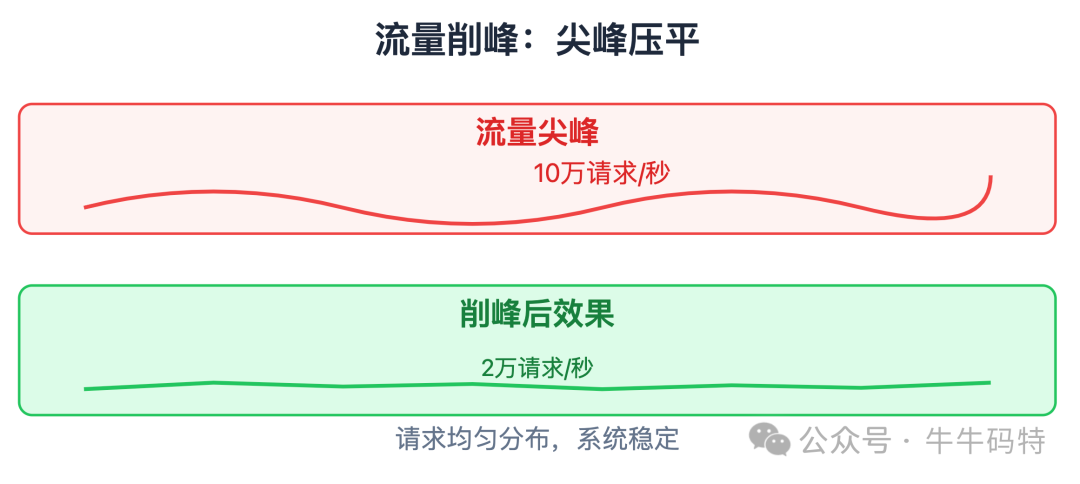
- Kafka:核心作用是 流量削峰。将瞬时的10万QPS写入缓冲为匀速的2万/秒,保护下游数据库。承载评论发布、点赞、审核等异步事件。
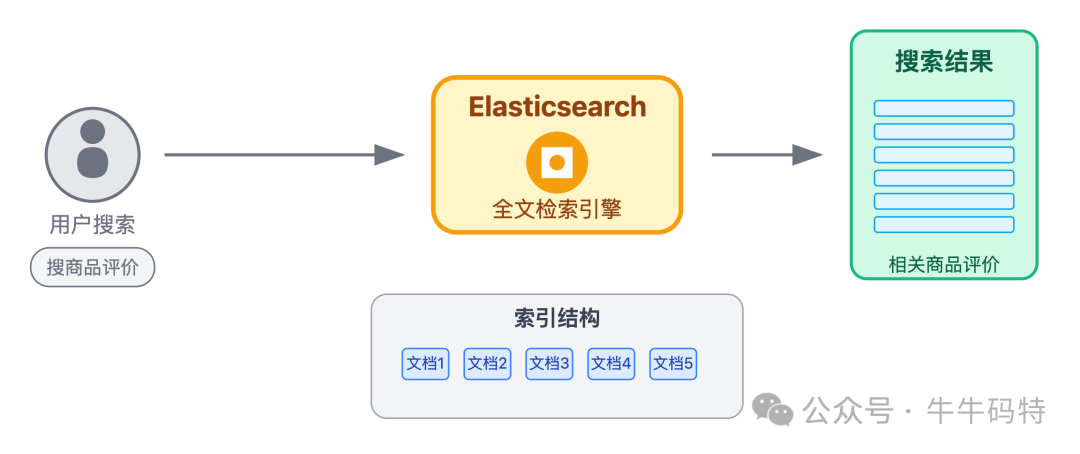
- Elasticsearch:提供全文检索能力,支撑“搜索商品评价”等复杂查询场景。
综合以上各层,一条用户发表评论的完整数据流可以概括如下:
- 用户发起请求:请求经 LVS -> Nginx -> 网关,路由至评论发布服务。
- 内容审核:调用审核服务,通过本地词库和AI接口过滤。
- 写入数据库:按分表规则写入 MySQL,同时发送事件至 Kafka。
- 缓存同步:评论查询服务消费 Kafka 事件,更新 Redis 和本地缓存。
- 用户查询:查询请求依次穿透 Caffeine -> Redis -> MySQL,返回结果。
- 异常降级:任何环节故障(如主库宕机、Redis失效)都有对应的降级预案(切从库、直连DB等),保障核心功能可用。
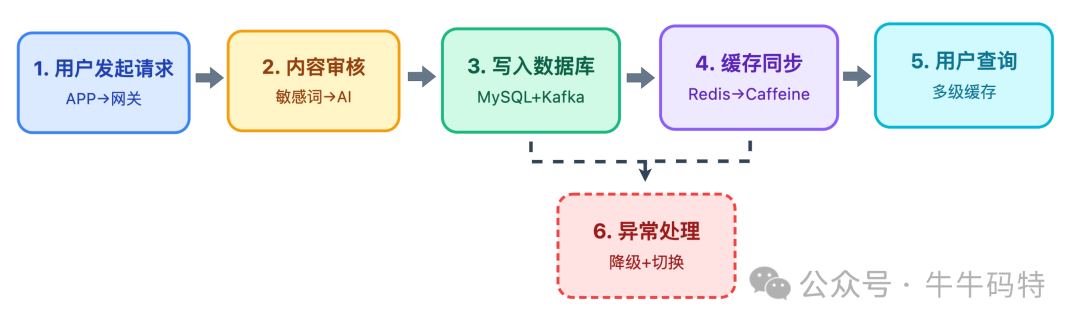
整个链路端到端延迟可控制在500ms以内,足以支撑百万级用户的实时互动。
4. 故障防御与恢复机制
一个健壮的系统,其高可用性不仅体现在正常运行时,更体现在故障发生时的快速恢复能力。高可用的目标不是追求零故障,而是确保故障发生时用户基本无感知。

1. 缓存雪崩防御
缓存系统最怕大量Key在同一时间点集体失效,导致所有请求瞬间压垮数据库。
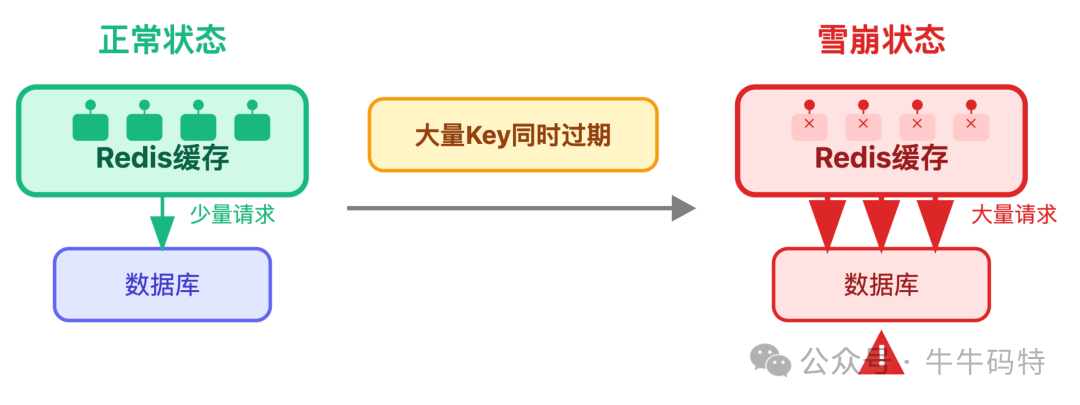
防御措施包括:
- 本地缓存作为缓冲:即使 Redis 集群完全故障,本地 Caffeine 也能暂时支撑部分热点请求。
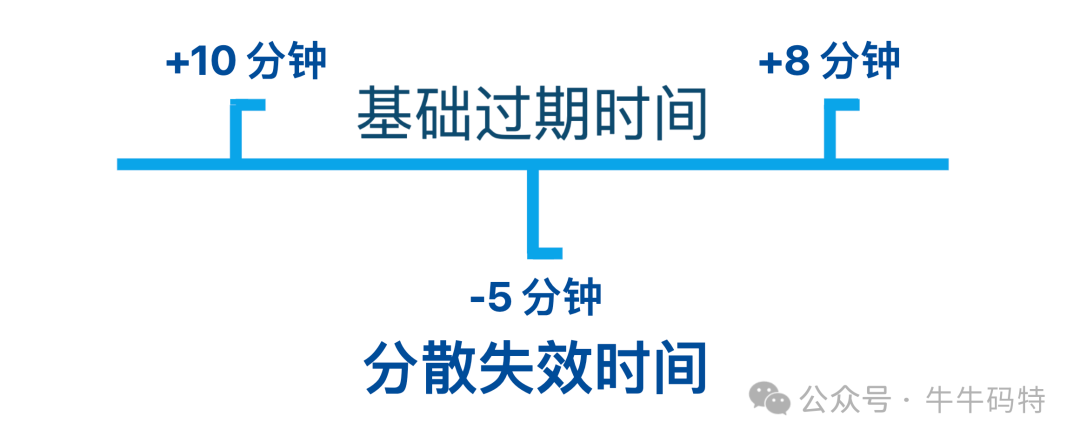
- 过期时间随机化:为 Redis 中的 Key 设置基础过期时间时,增加一个随机偏移值(如±10%),避免同时失效。
2. 数据故障快速切换
对于 MySQL 和 Redis 这类核心数据存储,必须建立多副本和快速故障切换机制。
- MySQL:采用基于 MGR 的 1主2从集群,主库故障可在30秒内完成自动切换。
- Redis:搭建3主3从的 Cluster 集群,配合哨兵监控,单主节点故障可在5秒内切换。
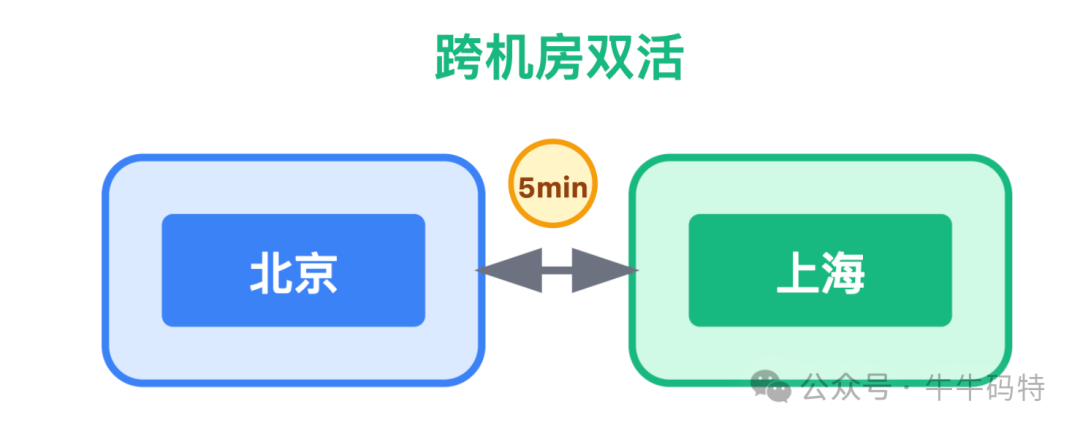
- 跨机房容灾:核心数据异步同步至异地机房,实现双活。当一个机房发生故障,另一个机房可在5分钟内接管核心服务。
3. 一键降级策略
当系统面临持续高压且短时间无法完全修复时,需要主动“舍小保大”,通过降级非核心功能来保全核心服务。可以预设多级降级策略:
- 一级降级(压力70%):限制新用户的评论发布频率(如每分钟1条)。
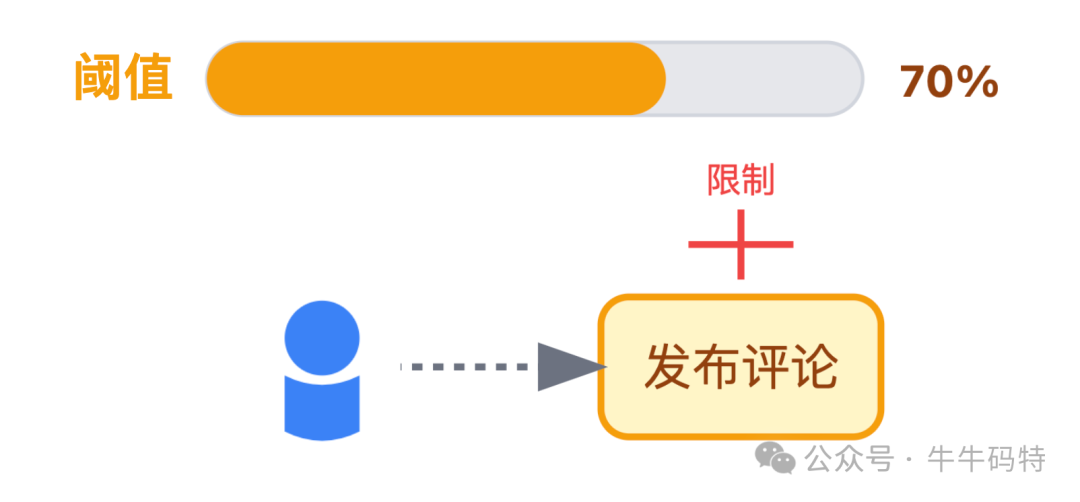
- 二级降级(压力90%):暂时关闭评论图片上传功能,节省带宽和处理资源。

- 三级降级(超负荷):评论列表仅返回前100条,并提示用户“高峰期请稍后尝试”。

这套预案如同手机的低电量模式,通过暂时关闭次要功能,确保核心体验不中断,为故障修复争取宝贵时间。
5. 总结与核心思路
回顾整个高可用评论系统的设计,技术细节虽多,但核心思路可以归结为以下三点:
- 先理解业务,再选择技术。首先要明确业务类型:是追求数据强一致的电商评价,还是容忍少量丢失但要求超高并发的直播弹幕?前者技术选型侧重“数据不丢”,后者则侧重“并发能扛”。
- 接受合理但不完美的权衡。点赞数延迟3秒更新,用户通常无感;但评论列表加载失败3次,用户就会离开。不必死磕“全量数据实时同步”,对于非核心的冷数据,性能稍弱是可以接受的。
- 平时多做预案,峰值才能从容。热点隔离的独立集群、多副本的高可用架构、清晰的降级策略,这些在平时看似占用资源的投入,在流量洪峰到来时就是系统的“救命稻草”。多思考“如果100万人同时点赞怎么办”、“如果 MySQL 主库宕机如何应对”,把预案做足,系统才能真正“抗揍”。
技术始终是服务于业务的工具。在构建高可用系统的道路上,理解业务本质,做出合理的权衡,并为之做好充分准备,远比追求一个理论上“完美”的架构更为重要。希望这份从存储选型到架构演进,再到故障恢复的完整解析,能为你设计自己的系统提供有价值的参考。更多关于后端架构和分布式系统的深度讨论,欢迎在技术社区进行交流。
 发表于 2026-4-4 06:33:07
|
查看: 118|
回复: 0
发表于 2026-4-4 06:33:07
|
查看: 118|
回复: 0
