在 Modelers GeekDay 上海站的分享中,社区贡献者丁一超系统性地介绍了大模型量化的入门路径。本文将基于其分享内容,梳理如何使用 MindStudio-ModelSlim 工具链完成模型量化,并结合 vLLM Ascend 部署与 AISBench 评测工具,构建一条完整的技术实践路径。无论你是初学者还是有一定经验的开发者,这篇指南都将为你提供清晰的操作指引和实用的避坑经验。
认识 MindStudio-ModelSlim
MindStudio ModelSlim(昇腾模型压缩工具,msModelSlim),是一个以昇腾AI处理器为根本的模型压缩工具。它集成了一系列量化和压缩等推理优化技术,旨在加速大语言稠密模型、MoE模型、多模态理解与生成模型等。
安装步骤
- 克隆代码仓:
git clone https://gitcode.com/Ascend/msmodelslim
- 进入目录并执行安装脚本:
cd msmodelslim
bash install.sh
- 安装 accelerate 依赖:
pip install accelerate
注意:如果后续修改或添加了新算法,需要重新执行安装脚本以配置环境,否则新算法可能无法正确加载。
msModelSlim量化操作
1. 一键量化
对于大多数常见模型,msModelSlim 提供了一键量化命令,可以快速完成操作。操作前可参考代码仓中的示例:https://gitcode.com/Ascend/msmodelslim/tree/master/example
量化命令(以 W8A8 为例):
msmodelslim quant --model_path {浮点权重路径} \
--save_path {W8A8量化权重路径} \
--device npu \
--model_type {模型类型} \
--quant_type w8a8 \
--trust_remote_code True
代码仓中提供了详尽的文档和最佳实践案例。正如丁一超所强调的:“代码仓里面有文档,有简单的 example,也有最佳实践的案例。开发者只要参考一下这些资料,自己也可以很轻松地上手量化。”
一键量化脚本参考目录结构:
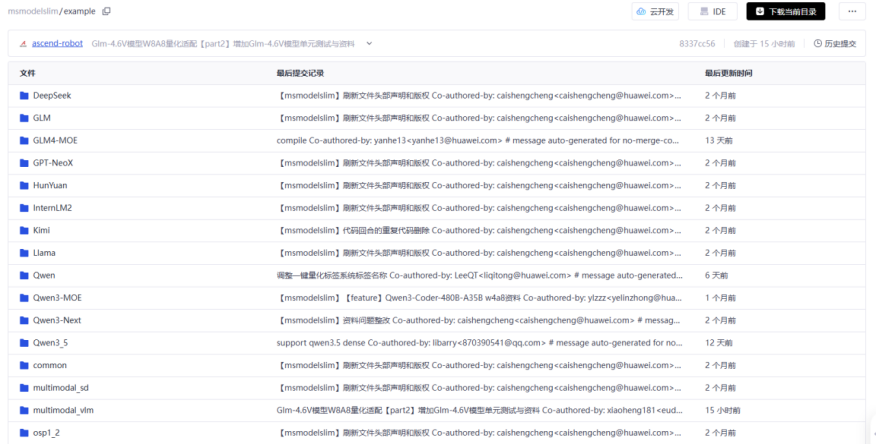
V0 版本量化配置文件参考格式:
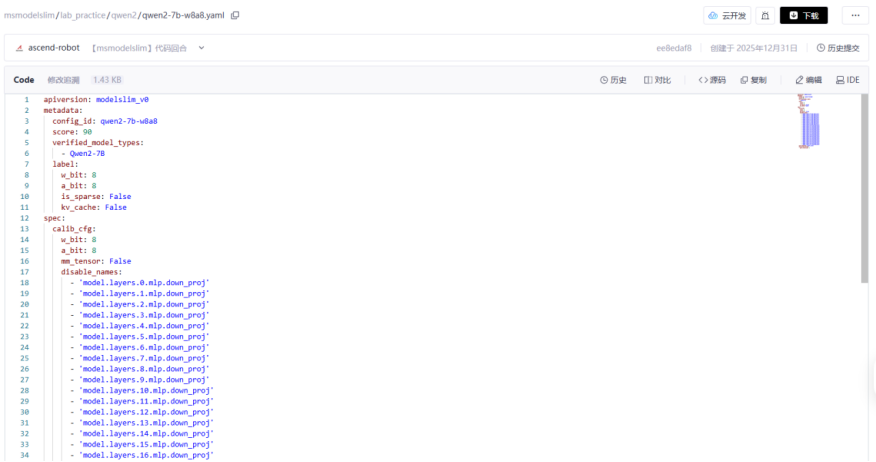
V1 版本量化配置文件参考格式:
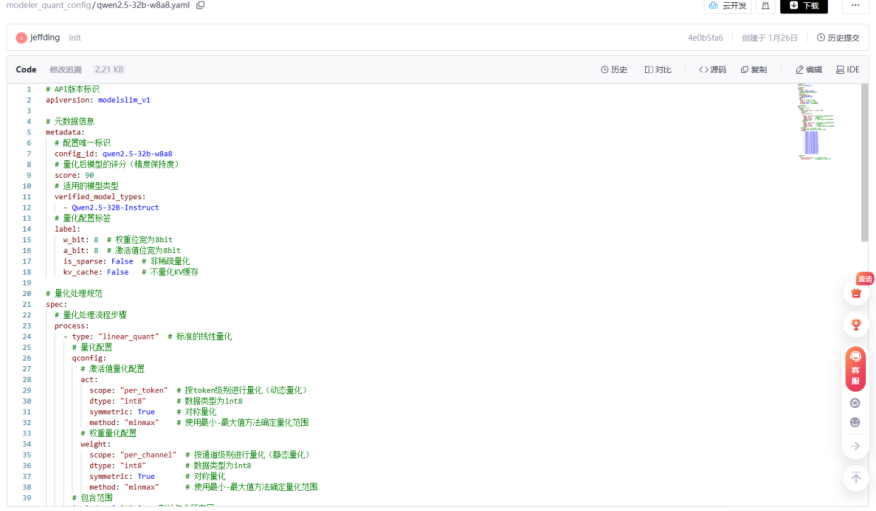
2. 敏感层分析
量化并非对所有层都友好,某些“敏感层”量化后会对模型精度产生较大影响。通过敏感层分析功能,可以识别出这些层,并在量化配置中对它们进行特殊处理(如保持 FP16 精度)。
分析命令:
msmodelslim analyze \
--model_type Qwen3-Next-80B-A3B-Instruct \
--model_path /path/to/your/model \
--device npu \
--metrics std \
--topk 20 \
--trust_remote_code False
3. 精细化量化配置
如果需要更精细的控制,例如选择特定的量化算法、排除某些层(基于敏感层分析结果),则可以使用 YAML 配置文件来指导量化过程。
执行命令:
msmodelslim quant --model_path {原始模型路径} \
--save_path {量化后模型存放路径} \
--device npu \
--model_type {模型类型} \
--config_path {yaml配置文件路径} \
--trust_remote_code True
在配置文件中,你可以指定量化的标签(如W8A8的位数)、是否开启偏差校正,以及从四种量化算法中选择其一。关于算法的详细介绍,建议查阅官方文档以获得更深入的理解。
模型部署与评测
1. 使用 vLLM Ascend 部署量化模型
量化完成后,下一步是使用支持昇腾硬件的推理框架来部署模型。以下是以 vLLM Ascend 为例的服务化启动命令。
部署命令:
vllm serve {模型目录} \
--served-model-name {自定义模型名} \
--max-num-seqs 8 \
--max-model-len 32768 \
--max_num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--allowed-local-media-path / \
--gpu-memory-utilization 0.9 \
--enforce-eager \
--port 9000 \
--quantization ascend
--served-model-name:自定义的模型名称,后续使用 AISBench 评测时需要与此名称保持一致。--max-model-len:模型支持的最大序列长度,需根据评测任务调整,设置过小可能影响评测结果。--gpu-memory-utilization:显存利用率,建议设置在 0.9-0.95 之间以获得较好的性能。--quantization ascend:关键参数,声明启动的是经过昇腾工具链量化的模型。如果启动的是原始浮点模型,则应省略此参数。
2. 使用 AISBench 进行模型评测
AISBench 是一个标准的模型评测工具,它可以通过 API 方式访问已部署的模型服务,并执行标准化的评测任务。
安装:
git clone https://github.com/aisbench/benchmark.git
# 推荐从GitHub拉取,若网速慢可使用代理
cd benchmark
pip install -e ./ --use-pep517
如果网络条件受限,也可以使用 Gitee 上的镜像仓库(注意更新可能稍有延迟):
git clone https://gitee.com/aisbench/benchmark.git
cd benchmark
pip install -e ./ --use-pep517
下载数据集:
评测需要对应的数据集。所有数据集的组织结构和下载方式,都可以在 ais_bench/benchmark/configs/datasets 目录下找到对应数据集的 README 文件。
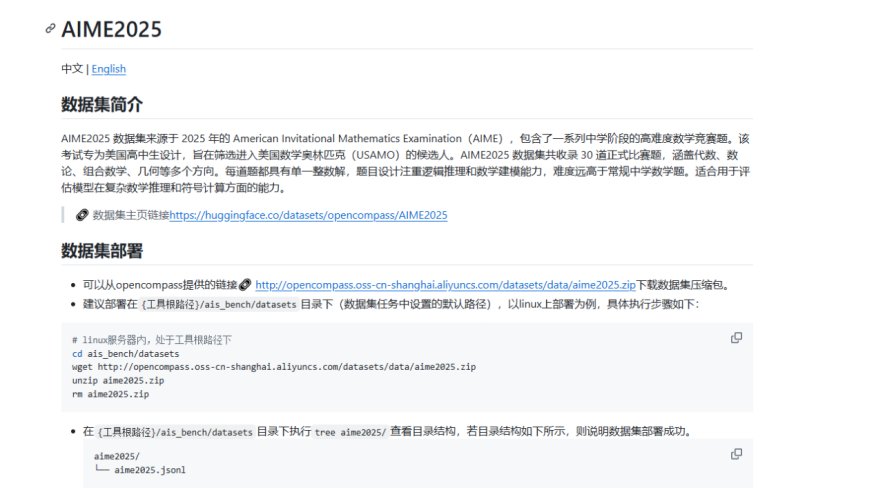
以 aime2025 数据集为例,下载和解压命令如下:
cd benchmark/ais_bench/datasets
wget http://opencompass.oss-cn-shanghai.aliyuncs.com/datasets/data/aime2025.zip
python3 -c “import zipfile; zipfile.ZipFile(‘aime2025.zip’).extractall()”
rm aime2025.zip
数据集配置文件目录示例:
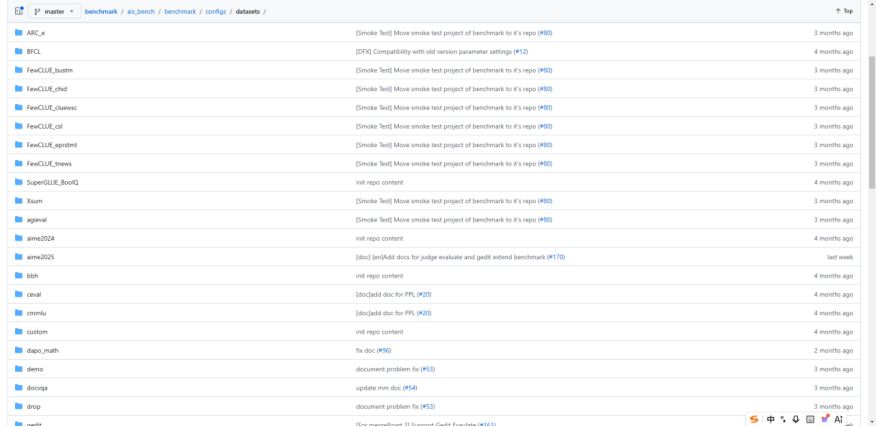
配置评测模型:
评测前,需要在 Python 配置文件中定义待评测的模型信息。以下是 LLM 模型和多模态(VLM)模型的配置示例。
LLM 模型配置示例:
from ais_bench.benchmark.models import VLLMCustomAPIChat
from ais_bench.benchmark.utils.postprocess.model_postprocessors import extract_non_reasoning_content
models = [
dict(
attr=”service”,
type=VLLMCustomAPIChat,
abbr=‘vllm-api-general-chat’,
path=”/home/openmind/models/Qwen3.5-122B-A10B”,
model=”qwen3.5”,
request_rate = 0,
retry = 2,
host_ip = “localhost”,
host_port = 9000,
max_out_len = 32768,
batch_size=16,
trust_remote_code=False,
generation_kwargs = dict(
temperature = 0.5,
top_k = 10,
top_p = 0.95,
seed = None,
repetition_penalty = 1.03,
),
pred_postprocessor=dict(type=extract_non_reasoning_content)
)
]
VLM(多模态)模型配置示例:
from ais_bench.benchmark.models import VLLMCustomAPIChat
from ais_bench.benchmark.utils.postprocess.model_postprocessors import extract_non_reasoning_content
models = [
dict(
attr=”service”,
type=VLLMCustomAPIChat,
abbr=”vllm-api-stream-chat”,
path=”/home/openmind/models/Qwen2.5-VL-7B-Instruct-w8a8”, # 启动服务化的权重路径
model=”qwen2_5_vl”, # 启动服务化时的模型名称
stream=True,
request_rate=0,
retry=2,
api_key=””,
host_ip=”localhost”,
host_port=9000, # 端口
url=””,
max_out_len=512,
batch_size=8,
trust_remote_code=False,
generation_kwargs=dict(
temperature=0.01,
ignore_eos=False,
),
pred_postprocessor=dict(type=extract_non_reasoning_content),
)
]
踩坑经验与优化建议
-
查看量化后模型大小:
量化后模型大小通常为原始模型的 50%-60%。多数模型的实际压缩率在 50%-55% 之间。若要精确查看模型文件大小,建议先删除模型目录下的 .git 文件夹(如果存在),再用 du 命令统计。

-
确认量化类型:
量化完成后,务必检查生成的 quant_model_description.json 文件,确认 model_quant_type 等字段是否符合预期(如 W8A8_DYNAMIC)。这可以避免因配置疏忽导致实际执行了其他非预期的量化类型(如 CA8)。
cat Qwen3-Next-80B-A3B-Instruct-w8a8/quant_model_description.json

-
环境依赖问题:
确保 torch 版本与 torch-npu 库的版本严格匹配。例如 torch==2.9.0 必须对应相同主版本的 torch_npu。
-
量化质量验证:
对于量化后的多模态模型,初步的图片测试通常不会出现乱码等严重问题。但在实际业务中,量化带来的精度损失(范围可能在1%-12%之间)需要根据具体任务场景进行评估和权衡。
-
性能权衡:
量化技术的主要目标是显著提升推理速度并降低显存占用,但这通常会伴随一定程度的精度损失。在实际应用中,需要根据业务对性能和精度的要求,找到最佳的平衡点。
总结
本文系统性地介绍了使用 MindStudio-ModelSlim 和 AISBench 在大模型量化、部署及评测方面的全流程实践。从一键量化到精细化的敏感层分析与配置,再到通过 vLLM Ascend 部署并利用标准评测工具验证效果,为开发者提供了一条清晰、可复现的技术实践路径。
正如分享者丁一超所体会的,“在魔乐社区你可以找到好玩的空间,积极参与活动还能体验到昇腾 NPU 算力。” 这种结合了实践资源与社区互动的环境,对于技术成长尤为重要。希望这篇指南能帮助你在实际项目中更好地应用模型量化技术,也欢迎你来到云栈社区与更多开发者交流,共同探索AI技术的更多可能性。
相关资源:
 发表于 2026-4-4 07:19:52
|
查看: 140|
回复: 0
发表于 2026-4-4 07:19:52
|
查看: 140|
回复: 0
