随着大语言模型(LLM)能力的显著提升,AI 系统正经历从被动响应到主动执行的根本性转变。智能体(Agent)作为这一转变的核心载体,能够自主感知环境、分解复杂目标、调用外部工具并持续迭代行动,将单次推理扩展为端到端的任务完成能力。这使 AI 首次具备了独立处理多步骤、跨系统、长周期任务的潜力。
然而,在 Agent 价值规模化落地的过程中,我们仍面临严峻挑战:
- 幻觉传导:错误信息在多步骤执行中被放大。
- 任务失败率高:复杂任务中途失败导致前功尽弃。
- 长程任务一致性难保证:执行过程中“目标漂移”现象普遍。
- 工具调用可靠性不足:外部工具集成缺乏统一标准。
GAIA:衡量 Agent 综合能力的“试金石”
为了客观评估智能体的真实水平,业界需要一个足够硬核的“考场”。GAIA(General AI Assistants Benchmark)正是这样一个由 Meta AI、Hugging Face 等顶级研究机构联合推出的通用 AI 助手评估基准,被公认为衡量 Agent 综合能力的权威标准。
它包含了 466 道涵盖推理、多模态处理、网页浏览、工具使用等真实场景的题目,其中 300 道私有测试题用于构建全球排行榜。其难度主要体现在:
- 需要多步骤推理和复杂规划能力。
- 涉及真实世界的信息检索和验证。
- 要求准确的工具调用和结果整合。
- 即使是强大的 GPT-4,其平均得分也不超过 30%。
- 人类专家水平为 92%。
历史性突破:登顶 GAIA,能力比肩人类
近期,阿里云 AI 搜索团队发布的全新企业级智能体框架 Ops-Agentic-Search,在 GAIA 基准测试中取得了 92.36% 的平均准确率,成功登顶榜单首位。
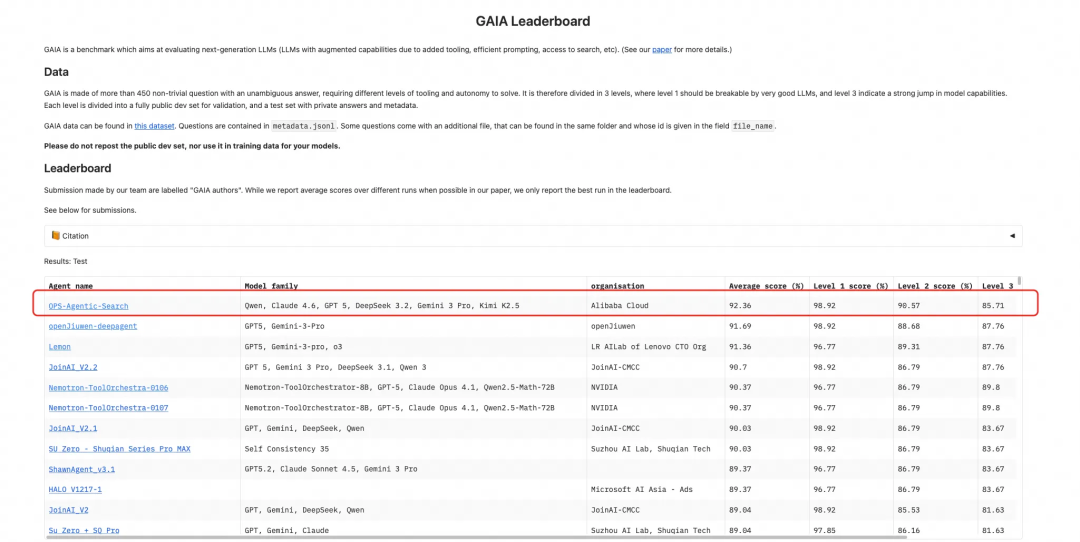
榜单链接:https://huggingface.co/spaces/gaia-benchmark/leaderboard
这一成绩不仅超越了众多明星产品,更首次将 Agent 的综合能力推进到人类专家水平。这标志着阿里云在 AI Agent 领域实现了从“跟跑”到“领跑”的跨越,为 Agent 的规模化企业应用奠定了坚实的技术基础。
核心技术揭秘:Ops-Agentic-Search 如何实现突破?
Ops-Agentic-Search 是阿里云 OpenSearch 团队打造的企业级智能体框架,深度融合了 OpenSearch 强大的搜索能力,构建了一个涵盖任务理解、动态规划、工具执行、反馈迭代、评估验证的端到端推理闭环。
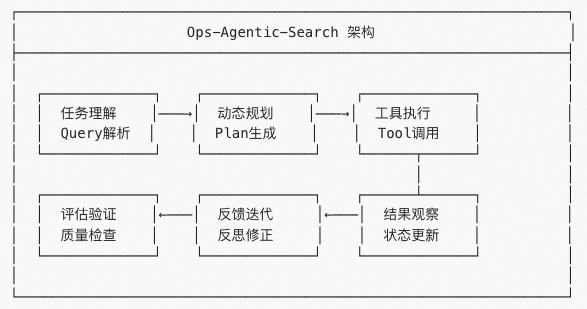
其核心能力矩阵如下:
| 能力维度 |
内置支持 |
说明 |
| 多模态理解 |
✅ 原生支持 |
文档/图片/视频/语音全模态处理 |
| 浏览器自动化 |
✅ BrowserUse |
自主网页浏览与信息提取 |
| 代码执行 |
✅ CodeAgent |
Python/Shell 代码生成与执行 |
| 文件操作 |
✅ 内置 |
本地文件读写与处理 |
| MCP 协议 |
✅ 兼容 |
支持 MCP Server 生态接入 |
| Skills 体系 |
✅ 自进化 |
自动提炼与进化可复用技能 |
1. 全局动态规划(Plan-with-Files):突破上下文与任务一致性瓶颈
传统 Agent 的规划与执行耦合紧密,易受上下文长度限制并产生“目标漂移”。Ops-Agentic-Search 创新性地采用了 plan_with_files 机制,将任务规划、中间结果和执行状态显式地外置到文件中,实现了深度解耦。
| 能力特性 |
技术实现 |
业务价值 |
| 突破上下文窗口限制 |
计划与中间结果外置到文件 |
解耦任务长度与上下文长度,支持超长复杂任务 |
| 增强任务执行一致性 |
Agent 每次行动前 reload plan |
确保每一步对齐最初目标,避免“目标漂移” |
| 支持动态更新与自我修正 |
步骤失败触发计划重排 |
实现自适应执行,提升复杂任务成功率 |
| 可观测与可解释性 |
文件形式留存执行轨迹 |
每一步的目标、结果、状态均有据可查 |
| 天然支持断点续传 |
从文件恢复执行状态 |
任务中断后无需从头开始,提升系统稳定性 |
2. 自我反思机制(Reflection):实现输出质量的迭代式收敛
该机制让 Agent 能在执行过程中对自身的输出、行为或推理过程进行自我评估和迭代改进,从而实现质量的持续收敛。
执行输出 → 交叉验证 → 错误识别 → 策略调整 → 重新执行
↑_________________________________________________↓
| 能力特性 |
实现效果 |
| 迭代式质量收敛 |
多轮自我评估与错误修正,输出质量逐步逼近最优解 |
| 幻觉主动抑制 |
对自身输出进行交叉式验证,降低模型过度自信导致的事实偏差 |
| 长链任务稳定性 |
阶段性校准防止误差在多步骤执行中累积放大 |
| 策略动态自适应 |
依据中间反馈实时调整执行路径,避免局部“死”循环 |
| 会话内经验复用 |
将失败信息结构化存入短期记忆,指导后续决策优化 |
3. 动态上下文管理:在信息完整性与资源效率间寻求最优解
为了解决长对话或复杂任务中的上下文信息过载问题,框架采用了双策略协同的动态上下文管理机制。
| 策略 |
机制 |
适用场景 |
| Summary 策略 |
语义级动态压缩,保留关键推理节点,将冗余内容转化为语义摘要 |
长对话历史、多轮推理链路 |
| Discard 策略 |
基于时效性/相关度/依赖性多维度评估,动态淘汰低优先级内容 |
上下文窗口满载、信息过载 |
4. 自进化 Skills 体系:从“单次执行”到“经验沉淀”
这是赋予智能体自我学习与持续进化能力的关键。系统能够自动从成功的历史任务中提炼出可复用的结构化 Skills(技能),并形成“执行 → 提炼 → 应用 → 再提炼”的闭环,驱动技能库螺旋式进化。

| 能力特性 |
说明 |
| Skills 自动提炼 |
无需人工干预,从多条推理路径中归纳抽象,提炼出可复用的结构化 Skills |
| Skills 自进化机制 |
形成闭环,驱动技能质量螺旋式跃升 |
| Skills 驱动推理加速 |
面对同类任务,已有 Skills 直接参与后续推理路径生成,跳过重复探索 |
典型应用场景与实战案例
基于上述强大的核心能力,Ops-Agentic-Search 能够胜任多种复杂的企业级任务。
| 场景 |
描述 |
效果 |
| 企业知识问答 |
基于企业内部文档库的智能问答 |
回答准确率提升至92%+ |
| 市场研究报告生成 |
自动收集、分析、整合多源信息 |
研究效率提升10倍+ |
| 代码辅助开发 |
理解需求、生成代码、调试优化 |
开发效率提升50%+ |
| 数据分析报告 |
自动提取数据、生成可视化图表 |
报告生成时间从天级降至分钟级 |
| 客户服务自动化 |
理解用户问题、查询知识库、给出解答 |
问题解决率提升至90%+ |
案例:执行复杂市场研究任务
- 任务:“分析 2025 年全球 AI Agent 市场格局,包括主要厂商、技术路线、市场份额,并预测未来 3 年发展趋势”。
- 执行过程:
Step 1: 任务分解
├── 子任务1: 收集2025年AI Agent市场主要厂商信息
├── 子任务2: 分析各厂商技术路线差异
├── 子任务3: 获取市场份额数据
└── 子任务4: 预测未来3年发展趋势
Step 2: 信息收集(并行执行)
├── 搜索权威市场报告(Gartner/IDC等)
├── 浏览厂商官网获取产品信息
├── 检索学术论文和技术博客
└── 分析开源社区活跃度
Step 3: 信息整合与分析
├── 交叉验证多源数据
├── 识别关键趋势和模式
└── 生成结构化分析报告
Step 4: 报告生成
├── 撰写执行摘要
├── 生成详细分析章节
├── 制作对比表格和图表
└── 输出最终研究报告
- 执行结果:
- 自动完成20+次网页浏览。
- 整合15+份权威报告。
- 生成包含图表的完整研究报告。
- 总耗时:5分钟内。
产品化:AgenticSearch 介绍
基于 Ops-Agentic-Search 框架能力,阿里云 OpenSearch 推出了 AgenticSearch —— 一种以智能体为核心的 AI 搜索新范式。它融合深度检索、多步推理、工具调用与多模态理解,致力于实现从“被动响应”到“主动执行”的体验跃迁。
| 能力 |
说明 |
| 深度检索 |
Multi-Agent 协同的递进式信息检索 |
| 任务执行 |
支持复杂多步骤任务的端到端执行 |
| 工具调用 |
内置浏览器、代码执行、文件操作等工具 |
| 多模态理解 |
支持文档、图片、视频、语音全模态处理 |
| 知识库集成 |
无缝对接企业知识库和 OpenSearch 索引 |
| 结果验证 |
自动验证信息准确性和来源可靠性 |
快速体验
总结与展望
Ops-Agentic-Search 首次登顶 GAIA 榜单 Top1 并达到人类专家水平,这不仅是阿里云 AI 技术实力的体现,更是整个 AI Agent 发展历程中的重要里程碑。它为 Agent 技术在企业场景中的规模化、可靠化应用扫清了一个关键障碍。
未来,团队将继续在技术开源、协议标准参与和生态建设上贡献力量,推动行业共同进步。对于开发者而言,关注此类前沿框架的演进和最佳实践,将是把握下一代 AI 应用开发趋势的关键。想了解更多 AI 与云计算的深度技术讨论,欢迎来 云栈社区 交流分享。
 发表于 2026-4-4 12:28:06
|
查看: 238|
回复: 0
发表于 2026-4-4 12:28:06
|
查看: 238|
回复: 0
