来源:机器之心
本文约3000字,建议阅读5分钟
核心观点:与其让模型吐一个离散分数了事,不如把它内部的完整概率分布也用上。
你是否遇到过这样的困惑:让 GPT-4 给两篇AI生成的文章打分,A 得了 4 分、B 得了 3 分,按理说 A 应该更好。但当你把它们放在一起,要求同一个模型直接比较时,它却可能给出“B 更好”的结论。更离谱的情况是出现“A > B > C > A”这种像“石头剪刀布”一样的循环判断,连最基本的传递性都无法保证。
这并非个例,而是当前“LLM-as-a-Judge”(大模型即裁判)评估范式中一个普遍存在的问题。为了解决这一难题,北京大学、清华大学等八所高校的研究团队在 ICLR 2026 上提出了 TrustJudge,一个基于概率的评估框架。其核心思想并不复杂:与其只取模型输出的那个离散分数或偏好,不如把它背后完整的概率分布信息也充分利用起来。令人欣喜的是,这种方法无需额外训练,就能显著降低评估的不一致性,并同步提升判断的准确性。

- 论文标题:TrustJudge: Inconsistencies of LLM-as-a-Judge and How to Alleviate Them
- 作者:Yidong Wang, Yunze Song, Tingyuan Zhu, Xuanwang Zhang, Zhuohao Yu, Hao Chen, Chiyu Song, Qiufeng Wang, Zhen Wu, Xinyu Dai, Yue Zhang, Cunxiang Wang†, Wei Ye†, Shikun Zhang†
- 单位:北京大学、清华大学、新加坡国立大学、南京大学、卡内基梅隆大学、西湖大学、东南大学、东京科学大学
- 论文链接:https://arxiv.org/abs/2509.21117
- 开源代码:https://github.com/TrustJudge/TrustJudge
问题有多严重?
用大模型给其他模型或生成内容当裁判,已成为评估领域的标配——MT-Bench 使用单项评分,AlpacaEval 使用成对比较,RLHF/GRPO 则依赖其进行偏好标注。然而,这位“裁判”用不同“考法”得出的结论,却常常相互矛盾。
TrustJudge 的作者对此进行了系统性的量化测量,将问题归结为两类:
评分-比较不一致
模型在单独评分时给 A 的分数比 B 高,但在成对比较时却认为 B 更好。测试显示,使用 Llama-3.1-70B 作为裁判时,这种不一致率高达 23.32%——几乎每四次评估就会出现一次矛盾。
成对传递性不一致
在成对比较中出现循环偏好(A > B > C > A)或等价性矛盾(A = B 且 B = C,但 A ≠ C)。在 Llama-3.1-70B 上,这种不一致率为 15.22%。
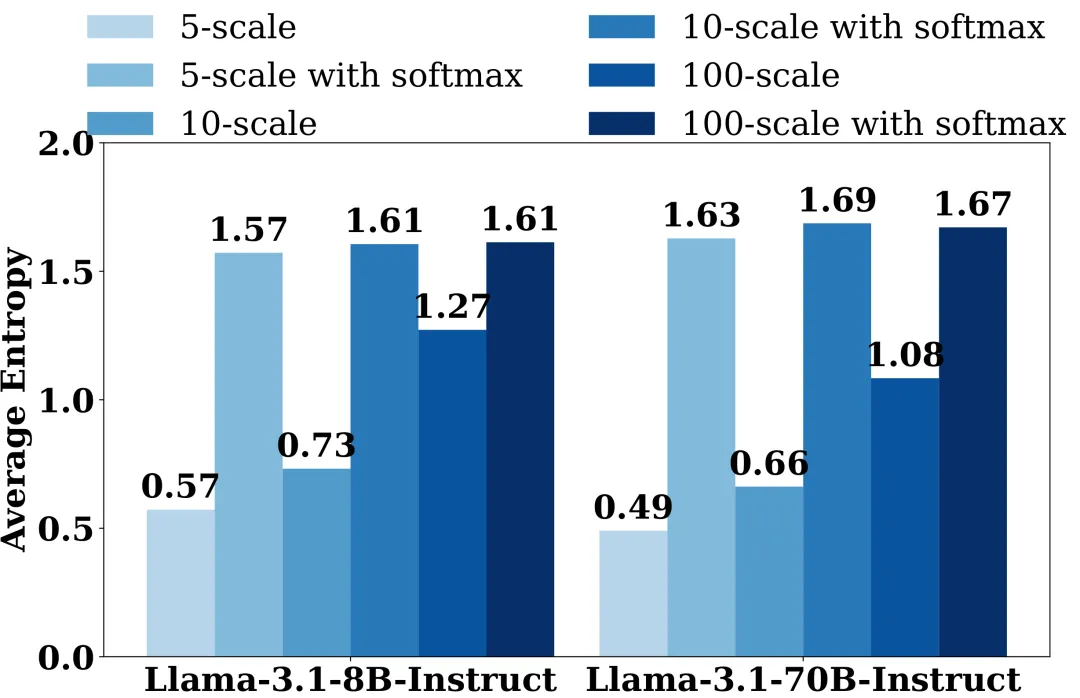

图 1:上图展示了Llama-3系列模型在1200条指令上的评分熵分布,熵值越高表示模型判断越不确定;下图则展示了成对比较中两种传递性错误的占比,不等式传递性不一致是主要问题。
问题根源是什么?
数据揭示了现象,那么根源何在?作者从信息论的角度给出了归因。
离散评分丢失信息
采用5分制打分,本质上是将模型内心的连续判断强行离散化到几个整数格子里。例如,两条回复的实际质量可能是3.8和4.2,但在5分制下都会被归为4分,从分数上看不出差别。然而当成对比较时,模型却能感知到这0.4的细微差距——矛盾便由此产生。作者从理论上证明了:存在两个不同的概率分布,它们在离散评分下输出完全相同,但所包含的信息(熵)却不同。这表明,离散化在结构上就必然会导致信息丢失。
模糊平局破坏传递性
在进行成对比较时,模型对于质量相近的回复经常给出“平局”判断。但“平局”与“平局”不同——有些是模型真觉得二者半斤八两,有些则是模型自己也无法确定。这些“模糊的平局”在不同组合中不一致地出现,就导致了 A = B、B = C,但 A ≠ C 的情况。
TrustJudge 的解决方案
思路其实很直接:不要只取模型输出的那个离散答案,把它背后完整的概率分布信息也用起来。 框架主要包含两部分:
分布敏感评分
传统做法是让模型输出一个分数(如“4”)后直接采纳。TrustJudge 则不然:
- 先将评分尺度从粗糙的5分制扩展到细致的100分制,提供足够的粒度。
- 对模型输出层所有候选分数对应的 logits 值进行 softmax 操作,得到一个覆盖所有可能分数的完整概率分布。
- 计算该概率分布的加权期望值作为最终分数:
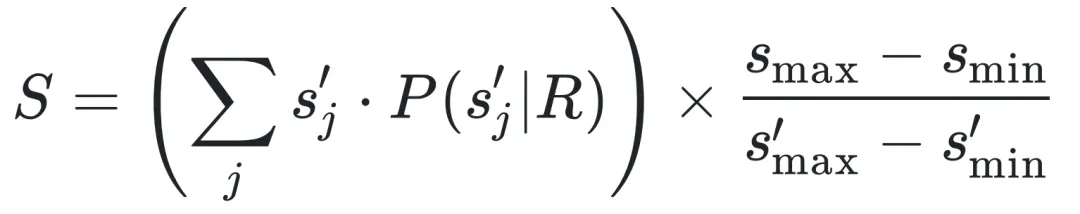
这样一来,原本在5分制下同得4分的两条回复,现在可能分别得到3.82和4.17的分数,细微差异得以保留。这与 G-Eval 等方法的区别在于,TrustJudge 通过 softmax 进行严格的归一化,确保所有可能分数的概率之和为1,避免了被非评分相关 token 干扰的问题。
似然感知聚合
对于成对比较,TrustJudge 提供了两种策略来处理模糊的平局,以提升判断的一致性:
策略一:基于困惑度
当模型输出“平局”时,分别计算将回复 A 放在前面和将回复 B 放在前面两种排列下,模型生成“A更好”或“B更好”这类判断文本的困惑度。选择困惑度更低的那种排列方向作为最终判断——模型读起来更通顺、更自然的排列,其判断往往也更可靠。
C(R_x, R_y) = { C_order1, if PPL(M, R_x, R_y) < PPL(M, R_y, R_x)
C_order2, otherwise
策略二:双向概率聚合
将两个比较方向(A vs B 和 B vs A)上模型输出“A更好”的概率进行聚合,选择置信度最高的偏好方向。这种方法能有效抵消因回复顺序不同带来的位置偏差。
m[k] = p_order1[k] + p_order2[-k], k* = arg max m[k]
理论支撑
上述方法在直觉上说得通,但有没有更严格的理论保证?作者给出了形式化的证明:

用一句话概括就是:分布敏感评分保留了更多信息,而似然感知聚合则有效降低了判断的不确定性。
实验结果
实验数据来自 MT-Bench 和 ArenaHard 数据集,裁判模型涵盖了 Llama-3 系列和 GPT-4o。
主实验效果
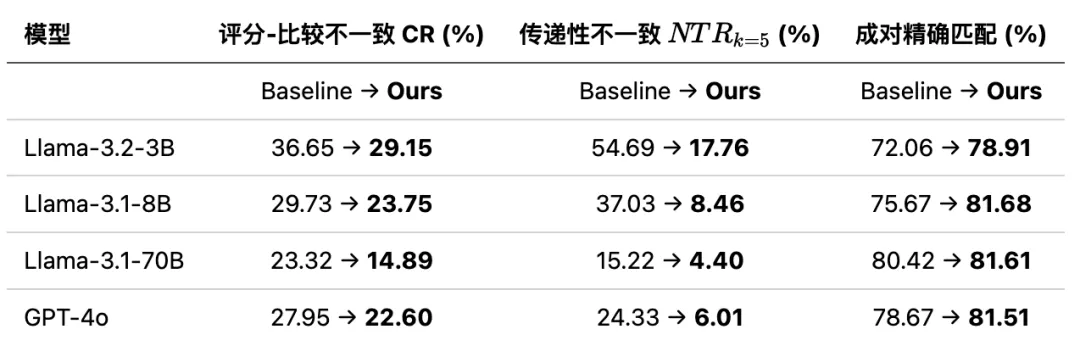
表 1:在所有测试模型上,TrustJudge 都显著降低了两类不一致性,同时提高了成对比较的精确匹配率。其中 Llama-3.2-3B 的传递性不一致率从 54.69% 大幅降至 17.76%。
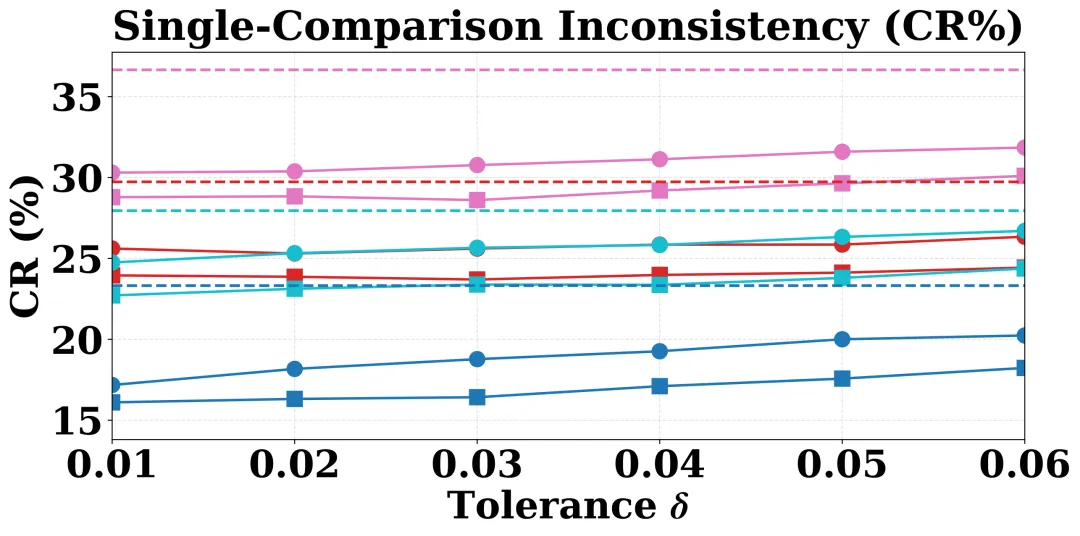
图 2:在不同容忍度阈值 δ 下,TrustJudge 方法(实心标记)的单一比较不一致率始终低于传统基线方法(虚线)。
消融实验
为了厘清每个组件的贡献,作者进行了细致的消融研究:
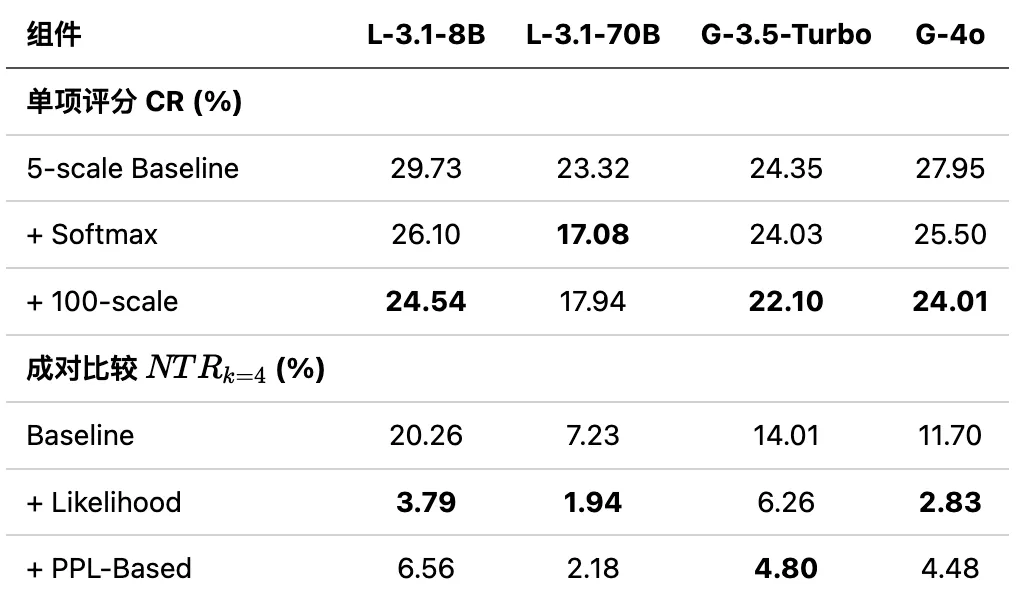
表 2:Softmax 归一化和100分制对改善评分不一致各有贡献;似然聚合和基于困惑度的方法对降低传递性不一致效果显著,其中似然聚合整体略优。
泛化性:对其他模型有效吗?
主实验主要基于 Llama 和 GPT 系列。一个很自然的问题是:TrustJudge 的方法是否适用于其他架构的模型?
答案是肯定的。作者将实验扩展到了 Qwen-2.5、Gemma-2、Llama-3 和 GPT 四个模型家族的共12个不同规模的变体上。
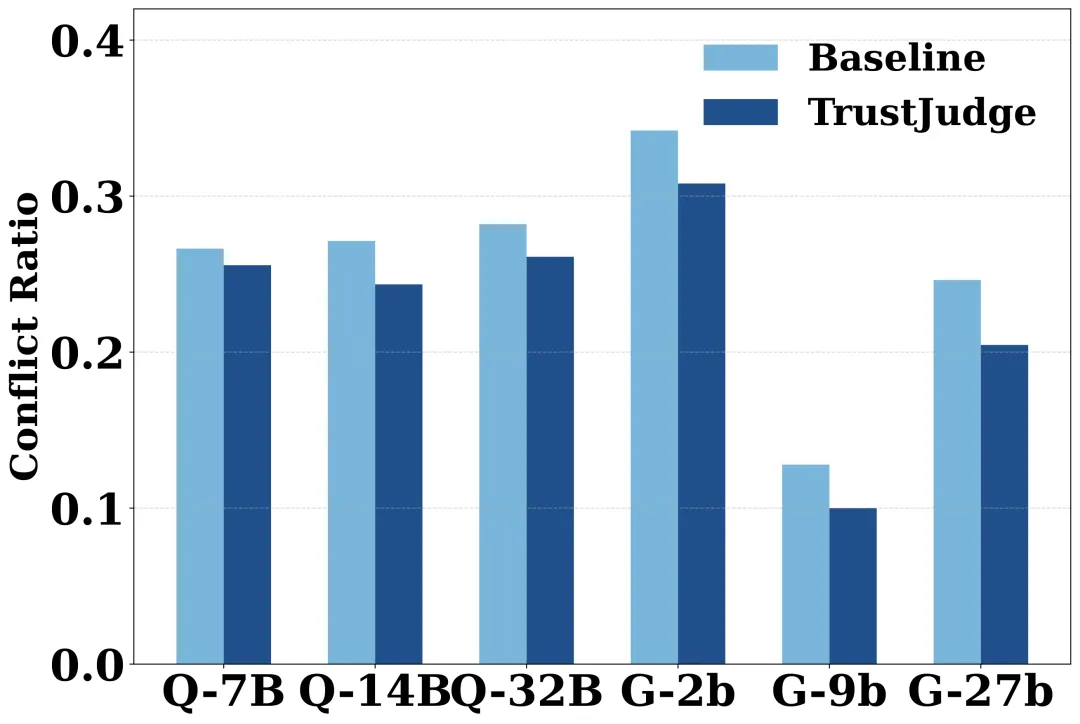
图 3:在四个主流模型家族上的不一致性对比。左图为评分-比较不一致,右图为传递性不一致。TrustJudge 在所有模型架构和规模上均表现出一致的改善效果。
一些有趣的发现:
- 分布敏感评分的改善效果与模型架构无关,具有普适性。
- 在加上似然感知聚合后,一个8B参数的模型其传递性不一致率,甚至可能低于未使用 TrustJudge 的70B大模型。
- 并非模型越大评估就越一致,例如9B的 Gemma 比27B的 Gemma 不一致性更低。
意外发现:推理模型反而更不一致?
一个令人意外的发现是:专门针对推理能力进行过强化训练的模型,在担任评估裁判时反而可能表现出更高的不一致性。
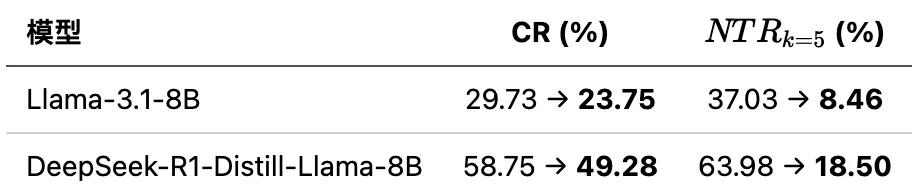
例如,DeepSeek-R1 的蒸馏版模型,其评分-比较不一致率高达 58.75%,几乎是同参数量 Llama 模型的两倍。这似乎表明,在数学推理数据上进行强化训练,可能会以损害模型的评估一致性为代价。不过,TrustJudge 即使在如此高的不一致基线水平上依然有效,将传递性不一致率从 63.98% 大幅压缩到了 18.50%。
实际应用:作为强化学习的奖励信号
除了用于评估,TrustJudge 还有一个重要的实际用途:为强化学习提供更高质量的奖励信号。
作者将其集成到 GRPO 框架中,用于训练 Qwen2.5-7B-Instruct 模型,训练数据覆盖摘要、数学推理、指令遵循等多种任务。

表 3:使用传统基线奖励训练的模型,在两种评估协议下的平均奖励均未超过原始模型;而使用 TrustJudge 奖励训练的模型,则在两种协议下均获得了提升。
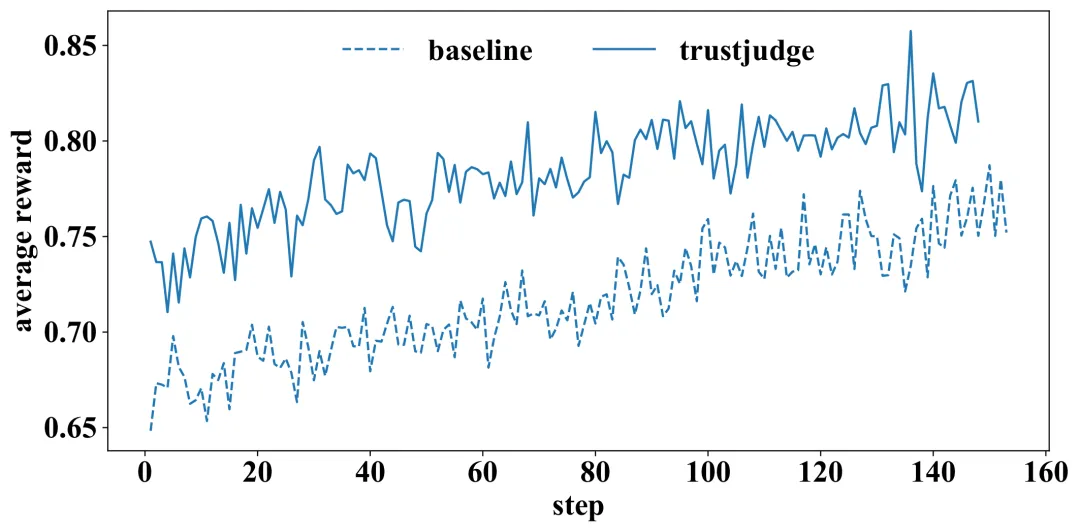
图 4:训练过程中,基于 TrustJudge 的奖励信号全程高于基线奖励。
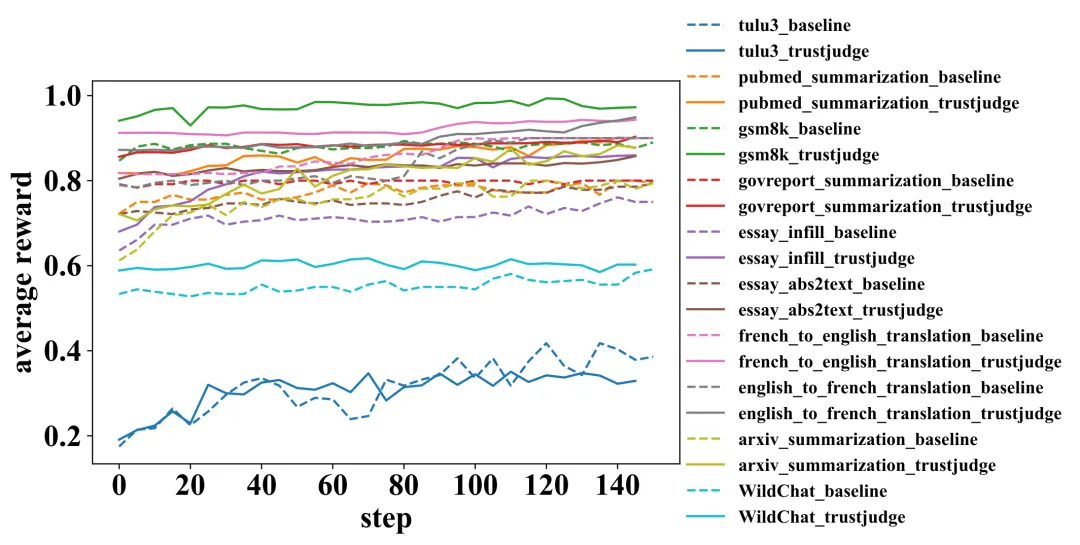
图 5:在多个验证任务上的奖励曲线,TrustJudge 带来的改善是全面且一致的。
这背后的道理很直观:评估越一致,提供的奖励信号噪声就越小,模型从中学习也就越准确、高效。这为如何利用大模型进行更可靠的强化学习对齐提供了新思路。
仅仅提高评分粒度就够了吗?
看到这里,你可能会问:TrustJudge 既提高了评分粒度(5分→100分),又加入了概率归一化。如果我只做前者,不做后者,效果如何?
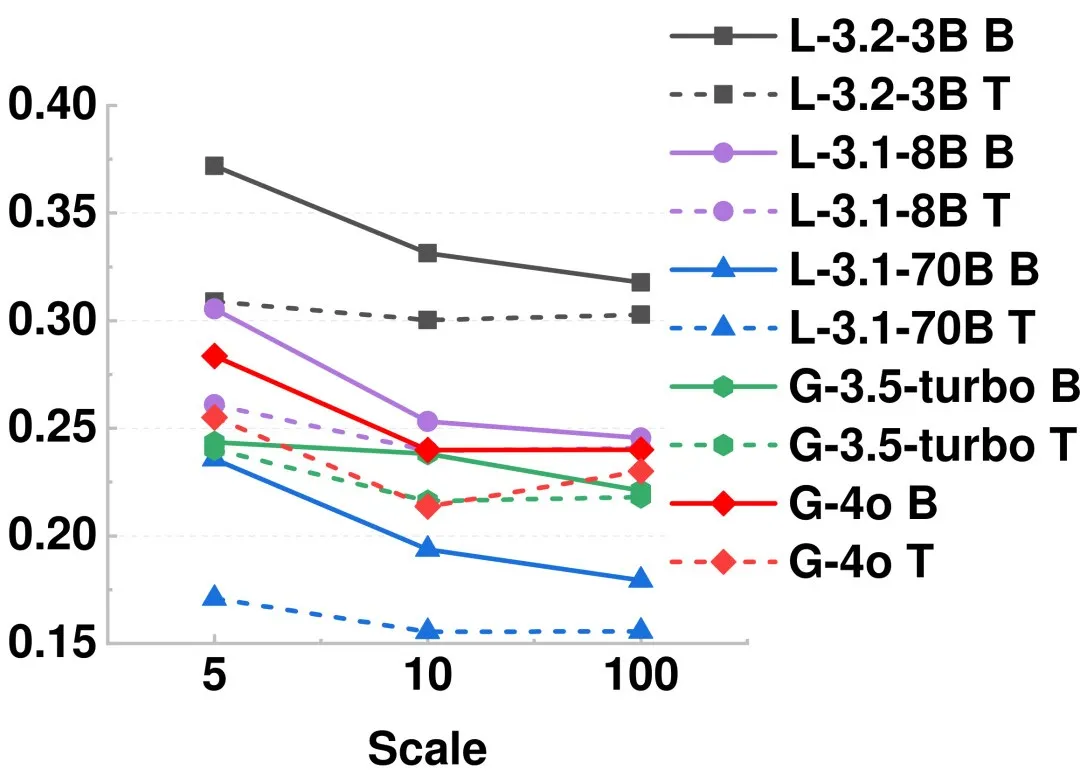
图 6:在5分、10分、100分三种不同粒度下,TrustJudge 方法的不一致性始终低于基线方法。提高粒度有帮助,但光靠粒度不够。
结论很明确:提高评分粒度确实有助于降低不一致性,但仅靠粒度提升是不够的。 TrustJudge 的优势在于将 粒度提升 与 概率分布归一化 二者结合了起来。如果你对这类提升大模型评估可靠性的开源实战方法感兴趣,不妨去其GitHub仓库查看具体实现。
总结
TrustJudge 的工作可以用两句话清晰概括:
- 针对“离散评分丢信息” → 改用分布敏感评分,保住模型内部的完整概率分布信息。
- 针对“模糊平局坏传递性” → 改用似然感知聚合,让原本模糊的判断变得清晰、一致。
在实际效果上,它无需额外训练,开箱即用;在 Llama、GPT、Qwen、Gemma 四大主流架构上均验证有效;不仅可用于评估,还能作为强化学习的优质奖励信号;并且有扎实的理论证明作为支撑。这项研究提醒我们,在让大模型担当裁判,去评估其他模型或内容之前,首先要确保这位“裁判”自身的判断是前后一致、值得信赖的。对于希望深入理解大模型评估底层逻辑的开发者,可以参考相关的技术文档进行进一步研究。
 发表于 2026-4-5 02:01:45
|
查看: 106|
回复: 0
发表于 2026-4-5 02:01:45
|
查看: 106|
回复: 0
