本文旨在解决当前AI量化交易回测中的一个核心痛点:固定的手续费模型无法真实反映大额订单对市场价格的冲击成本。研究团队为此开发了一套包含三种交易场景的开源模拟环境,并引入了贴近真实市场的非线性“市场冲击”成本模型。实验对比了五种主流的强化学习算法,结果表明,真实的成本约束会彻底改变AI的交易行为与算法性能排名,有效遏制了在固定费率下可能出现的疯狂高频交易现象。
I. 引言
强化学习(RL)已成为量化交易和投资组合优化的强大工具,具备从市场数据中学习动态策略的潜力。然而,模拟回测与实盘表现之间往往存在巨大鸿沟。传统回测通常假设固定的交易成本(如10个基点),完全忽略了因订单规模、市场波动和流动性消耗引发的永久性与临时性价格变动——即市场冲击。这种简化的成本模型使得强化学习代理(Agent)得以进行脱离现实的高频交易,从而产生虚高的回测收益,这些策略在真实市场中往往无效。
为了解决这一问题,一个基于Gymnasium框架、包含三种多资产交易环境的开源套件被开发出来:MACE股票交易环境、融资融券交易环境以及投资组合优化环境。所有环境都整合了经验证的非线性市场冲击模型,并配有可插拔的成本核算模块、指数衰减的永久性冲击追踪以及详尽的交易日志生成器。该框架作为FinRL-Meta生态系统的扩展发布,旨在填补强化学习量化交易研究中缺失的成本感知环节。
II. 市场冲击模型
当大额交易指令在真实市场中执行并消耗流动性时,会迫使价格向不利于交易者的方向移动,产生市场冲击。本研究基于市场微观结构与最优执行理论对此进行建模。
根据平方根冲击定律,大额订单的预期价格变化与其交易规模占日均成交量(ADV)比例的平方根成正比,同时受到资产日波动率和经验因子的调节。此外,借助Almgren-Chriss(AC)成本分解框架,单笔交易的执行成本被精确分解为三部分:
- 永久性冲击:反映交易中蕴含信息导致的长效价格偏移。
- 价差成本:设定为固定的半买卖价差。
- 临时性冲击:反映即时消耗市场深度所产生的流动性溢价。
同时,市场会随时间逐步消化交易信息。永久性价格偏移服从指数衰减规律,系统默认针对大盘股设定5个交易日的衰减半衰期,使冲击成本的动态演化更贴合市场现实。
III. 环境设计
三大交易环境共享统一的Gymnasium接口,使用连续动作空间映射交易指令,并通过复杂的奖励函数平衡风险调整后收益与市场冲击成本。其中,MACE(Market-Adjusted Cost Execution)股票交易环境是框架的核心。
状态空间:观测状态是一个密集的多维特征向量,包括现金占比、日对数收益率、资产头寸价值占比、经过缩放处理的技术指标(如MACD、RSI、CCI),以及相对于20日平均成交量(ADV)的持仓比率。可选特征包括累积永久性冲击(基点计)、交易冷却计数器等。所有特征都经过基于在线运行均值和方差的标准化处理,以确保跨时间段的泛化能力。
动作空间与交易执行:在单向股票交易与融资融券环境中,每只股票对应一个[-1, 1]区间内的连续动作信号。单只股票的最大头寸受预设的风险敞口比例参数限制。生成的交易量首先被限制在头寸边界内,然后其绝对值被进一步裁剪,不得超过单日总成交量的预设最大分位数。执行逻辑强制卖单优先于买单撮合。在投资组合优化环境中,动作输出为现金与N只股票的原始Logits,经Softmax转化为目标权重,环境反向计算所需的再平衡交易量并施加相应的冲击成本。
奖励函数:MACE股票环境采用了差分夏普比率作为核心奖励信号,并对其进行二次修正,额外减去了与最大回撤幅度平方成正比的惩罚项,以抑制下行风险。融资融券及投资组合优化环境则沿用各自原始文献设定的奖励模型,以保持基准对比的公平性。
IV. 实验设置
数据与股票池:使用NASDAQ 100成分股的日线数据(2010年1月至2026年1月),按90/10比例划分为训练集和样本外测试集。超参数优化仅使用2025年1月前的数据,后续数据严格用于最终评估。基准标的为等权重纳斯达克100 ETF(QQEW)。
深度强化学习算法:评估覆盖了Stable-Baselines3库中的五种主流算法:A2C、PPO、DDPG、SAC以及TD3。采用基于Epoch的周期性训练,每个Epoch后进行独立的OOS测试以监控过拟合。
超参数优化:由Optuna框架驱动,使用TPE采样与中位数剪枝策略。搜索空间涵盖环境参数与算法内核参数,优化目标为最大化跨Epoch的OOS年化夏普比率。
对比协议:针对不同环境,执行了涵盖5种算法、2种成本模型(10bps固定费率与AC模型)、2种超参数配置的多次独立回测,形成全面的对比矩阵。
V. 结果
研究结果揭示了三个核心发现:股票交易环境对超参数优化和成本模型最敏感;投资组合优化环境能产生最高的绝对收益,且AC成本模型实质性地改善了神经网络的收敛动态;融资融券环境则清晰地展示了成本模型对收益分配的控制力。
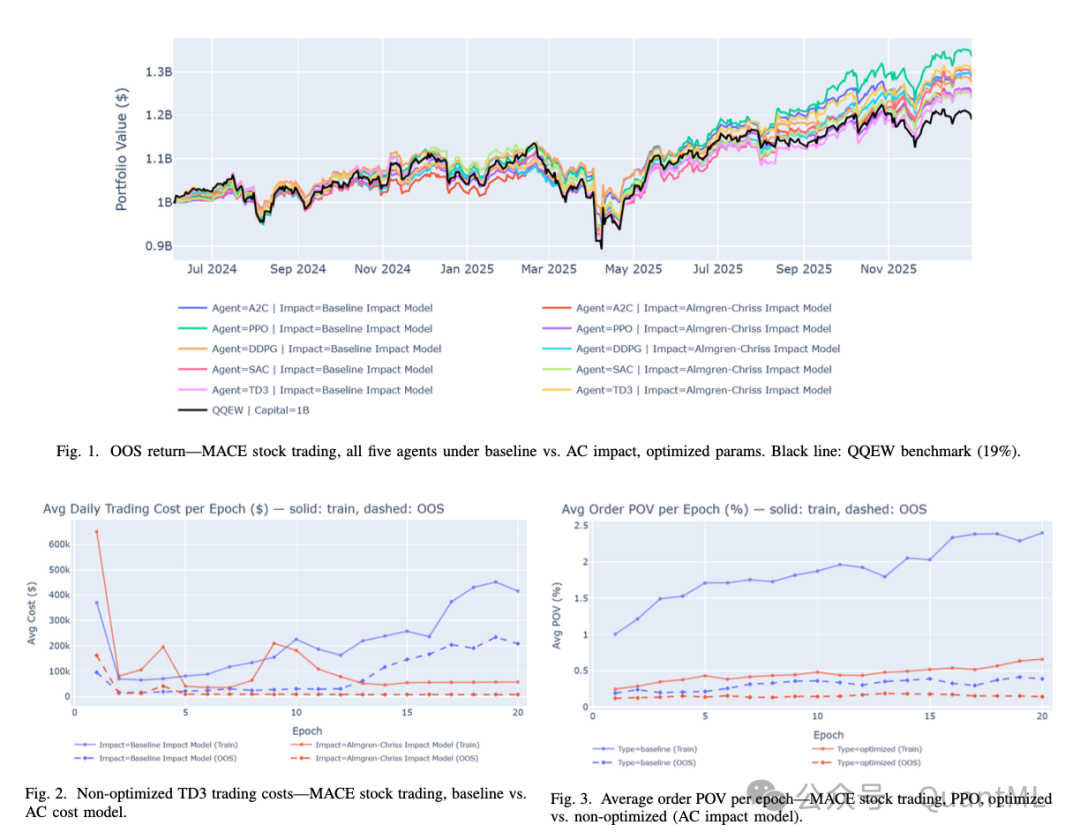
MACE股票交易:五种算法对比
除使用默认参数的TD3(AC模型下)外,所有模型配置均跑赢了QQEW基准(19% OOS收益率)。最优性能由基准成本模型下的优化版PPO取得:20%年化收益率,夏普比率1.06。切换到AC成本模型后,该PPO收益率降至15%(夏普1.03),但交易成本骤降55%,平均订单成交量占比(POV)和波动率均显著下降,塑造出一个风险更低的防御型组合。
与之形成鲜明对比的是TD3算法:引入AC成本信号后,其收益率从15%逆势升至18%,夏普从0.9升至1.1,同时换手率和交易成本均降低。超参数优化展现出强大的交易行为抑制力。例如,优化后的SAC算法在AC模型下将换手率从5%压缩至2%,交易成本削减82%。未优化的TD3在基准模型下表现出病态高频交易(日均换手率19%),切换至AC模型后,其换手率暴跌至1%,交易成本缩减96%,而收益仅微降。
融资融券交易:四种算法对比
所有Agent的OOS表现均未跑赢QQEW基准。AC模型对不同算法产生了不对称的影响:A2C在AC模型下获得了更好的泛化能力;PPO在AC模型下收益率意外下跌;DDPG在接入AC模型后性能大幅改善;而SAC则遭受严重打击。训练动态也显示出严重分化,部分算法出现过拟合或过早收敛至次优策略的现象。
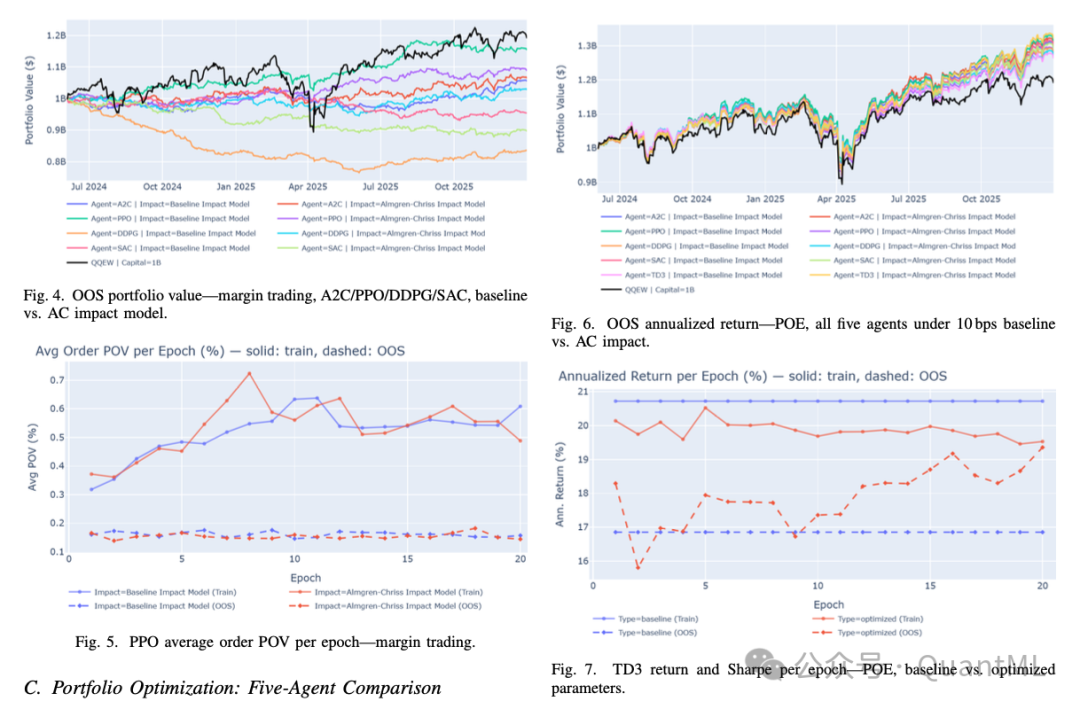
投资组合优化:五种算法对比
所有算法在此场景下均跑赢基准。TD3的表现差异最悬殊:在AC模型下取得了全场最高的32% OOS收益率,而在固定成本模型下仅为26%。A2C表现稳定,PPO是唯一在AC模型下出现性能倒退的算法。训练动态图清晰显示,超参数优化能有效引导TD3真正收敛,并阻止PPO陷入交易成本无限增长的陷阱。
横向对比证实,优化版TD3在AC模型下展现的完美OOS收敛曲线,在固定成本模型下完全消失。这确凿地证明,包含真实物理意义的非线性成本约束信号,能帮助Agent学习到泛化能力更强的稳健策略。
VI. 局限性与未来工作
尽管该框架在弥合回测与现实鸿沟方面奠定了坚实基础,但仍存在演进空间。例如,使用的是静态股票池,未来需纳入动态指数成分股调整;若测试范围扩展至流动性更差的标的,成本模型的差异会被放大。此外,融资融券环境尚未整合精确的持仓成本(如借券利息)计算引擎。当前的超参数优化单一追求夏普比率最大化,未来引入多目标优化有望锤炼出防御性更强的策略。
VII. 结论
本研究构建了一套兼容Gymnasium的强化学习交易环境,打破了固定交易成本的传统假设。通过对三大交易范式、五种主流深度学习算法的交叉验证,得出确定性结论:
- 成本模型的物理属性决定算法收益排名(如PPO在固定成本下最优,TD3在非线性成本下崛起)。
- 非线性AC成本模型能从根本上遏制病理性的高频交易行为。
- 超参数优化是压制算法过度交易倾向、防止模型坍塌的关键屏障。
- 算法性能与环境约束、成本模型间存在复杂的非线性耦合,没有单一算法能通吃所有场景。
该套件及其市场冲击模块、优化流程已全面开源,旨在为金融AI领域的成本感知研究提供可复现的工业级基础设施。对强化学习与量化交易结合感兴趣的开发者,可以在云栈社区 的人工智能与算法板块找到更多深入的讨论与资源。
 发表于 2026-4-5 02:38:00
|
查看: 151|
回复: 0
发表于 2026-4-5 02:38:00
|
查看: 151|
回复: 0
