当前的图像生成模型在描述需要精确或最新知识的场景时,常常会“露怯”。比如,让它画一幅“马斯克穿着最新款SpaceX宇航服在火星基地演讲”的图片,生成的结果可能在人物面部、服装细节上出现各种错误。这背后的根本原因在于,现有模型本质上是一个“知识库封闭”的系统——它的知识在训练完成后就被冻结了,无法获取后续的实时信息,也难以精确调用训练数据中的长尾细节。
那有没有办法让AI像人类创作者一样,在动手前先“上网查查资料”呢?近期,来自香港中文大学多媒体实验室、加州大学洛杉矶分校和伯克利分校的研究者们给出了肯定的答案。他们提出了一种名为 Gen-Searcher 的方法,旨在系统性地训练一个能为图像生成任务主动进行深度网络搜索的智能体。这不仅仅是简单的联网检索,而是一个具备规划、工具使用和多轮推理能力的完整工作流。
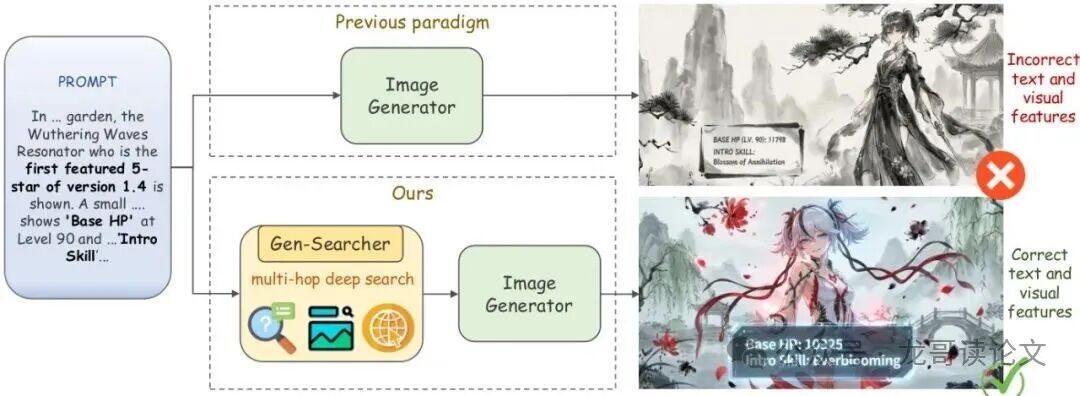
图:Gen-Searcher(下方流程)与传统“提示词直接生成”(上方流程)的对比。它通过多跳深度搜索获取精准信息,显著提升了生成图像中文本与视觉特征的正确性。
图像生成的“知识盲区”与搜索新范式
模型面临的“知识盲区”主要分为两类:
- 动态知识盲区:无法获取训练数据截止日期之后的信息,如最新事件、产品等。
- 长尾/精确知识盲区:即使知识存在于训练数据中,模型也难以精确记忆或关联,如小众角色的特定装扮、建筑的结构细节。
传统的解决思路是检索增强生成(RAG),但这种方法通常依赖静态知识库,存在覆盖不全、更新不及时的问题。Gen-Searcher则引入了一种全新的 “智能体搜索增强生成” 范式。它让一个经过训练的多模态大模型智能体直接与实时互联网交互,通过多轮、深度的搜索、浏览和推理,为图像生成搜集和整理最有效的“创作素材”。
揭秘Gen-Searcher:如何训练一个会“上网查资料”的AI助手
Gen-Searcher本身并非图像生成模型,而是一个 “搜索增强型提示词优化器” 。它基于Qwen3-VL-8B-Instruct模型构建,被赋予了三个核心工具:文本search、image_search和网页browse。
它的工作流程如同一位严谨的研究员:接到用户指令后,它会自主规划搜索路径。例如,针对“画一张爱因斯坦在普林斯顿办公室黑板上写质能方程的照片”这个提示,它可能先搜索环境参考图,再核实公式写法,甚至浏览传记网页确认历史细节。最后,它将所有信息整合成一个细节丰富、证据确凿的新提示词,并附上精选的参考图片,再交给下游的图像模型(如Qwen-Image)去执行生成。

图:Gen-Searcher为制作一份包含复活节岛、奥伊米亚康等地的旅行海报,进行了多轮思考和工具调用,最终生成了信息准确、视觉效果丰富的成果。
两阶段训练:从“学会用工具”到“用好工具”
训练这样一个智能体采用了经典的“模仿学习+强化学习”两阶段策略:
- 监督微调(SFT)阶段:让模型学习大量的高质量“标准答案”,即智能体搜索轨迹和最终整理好的提示词,目标是掌握基本的工具使用和提示词编写能力。
- 智能体强化学习(Agentic RL)阶段:这是让模型从“会用”变得“好用”的关键。模型自由尝试不同的搜索策略,然后根据一个奖励信号(Reward)来优化策略。本研究采用了GRPO(组相对策略优化)算法,这种方法特别适合训练工具使用这类复杂任务。
从零构建数据:高质量数据集与基准的诞生
训练和评估Gen-Searcher的最大挑战是没有现成数据。为此,研究团队构建了一套自动化的数据生产流水线,共四个步骤:
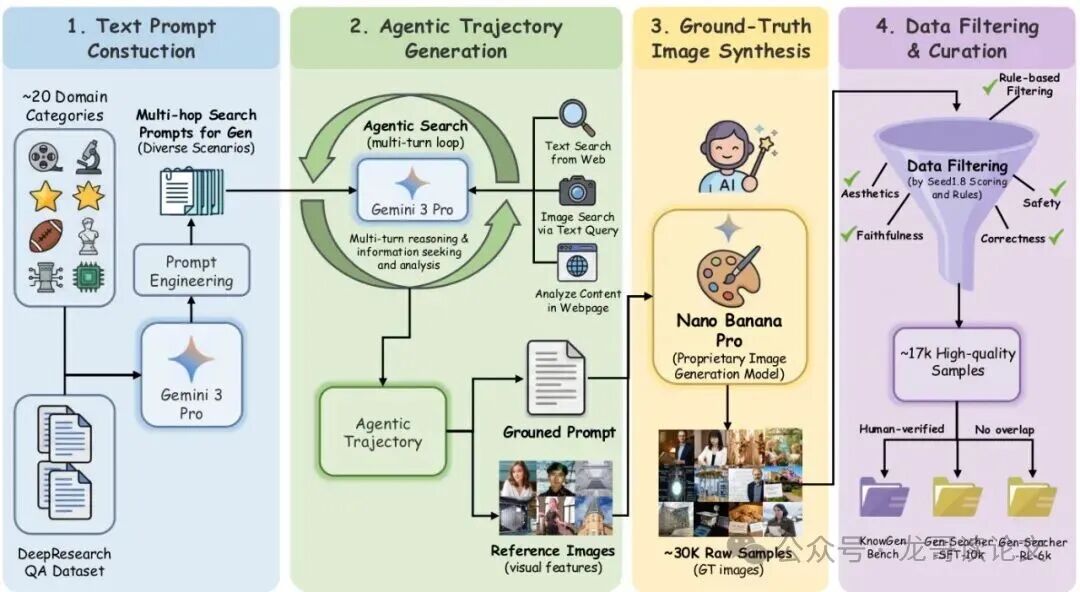
图:数据构建流程包括文本提示构造、智能体轨迹生成、真实图像合成及数据过滤。
- 构造需要搜索的文本提示:使用大模型在约20个多样类别(如科学、历史、动漫、名人)中生成复杂的、需要多轮证据聚合的提示。
- 生成智能体搜索轨迹:让另一个大模型扮演“教师”,使用搜索工具实际解答上述提示,产生包含多轮交互和最终输出(提示词+参考图)的轨迹,作为SFT的“标准答案”。
- 合成真实图像:将上一步得到的提示词和参考图,送入强大的图像模型(如Nano Banana Pro)生成最终图像,作为“真实效果”参考。
- 过滤与整理:使用评估模型从多个维度(正确性、美观度、安全性等)对样本进行打分和过滤,确保数据质量。
最终,团队构建了两个高质量训练数据集:Gen-Searcher-SFT-10k和Gen-Searcher-RL-6k。更重要的是,他们从中精选了630个样本,构建了全新的基准测试——KnowGen。
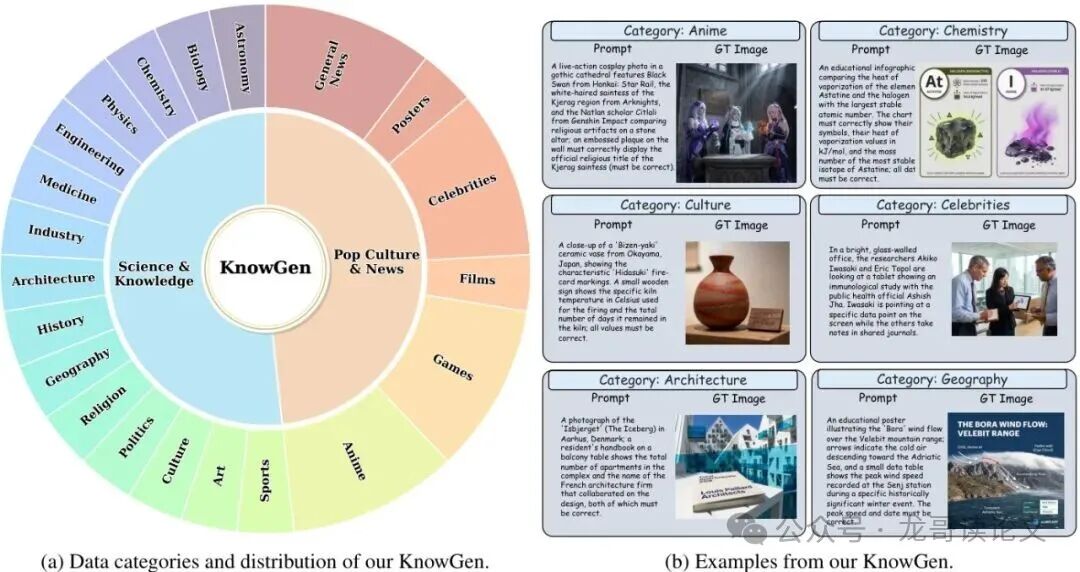
图:KnowGen基准覆盖科学与知识、流行文化与新闻两大类,包含多个具体领域的示例。
KnowGen专门用于评估“基于搜索的图像生成”能力。其评价指标K-Score由GPT-4.1从忠实度(Faithfulness)、视觉正确性(Visual Correctness)、文本准确性(Text Accuracy)和美学(Aesthetics)四个维度进行综合打分,其中视觉和文本准确性占比最高,强调了精准还原细节的核心目标。
双奖励强化学习:稳定训练搜索智能体的秘诀
强化学习成功的关键在于奖励函数设计。研究者发现,如果仅用最终生成图像的K-Score作为奖励,会导致训练极不稳定。因为对于能力较弱的开源图像模型,即使智能体搜集了100%正确的信息,生成结果也可能因模型自身限制而质量不佳,这会错误地惩罚智能体的搜索行为。
为此,Gen-Searcher提出了 “双奖励反馈” 机制:
- 文本奖励(R_text):评估智能体输出的“基于搜索的提示词”本身是否包含了足够、正确的信息。它直接监督信息搜集质量,不受下游图像生成器能力干扰。
- 图像奖励(R_image):即最终的K-Score,确保智能体的工作服务于核心任务。
总奖励 $R$ 是两者的加权和:$R = (1-\alpha)R_\text{image} + \alpha R_\text{text}$(论文中设 $\alpha=0.5$)。文本奖励提供了稳定、直接的监督,图像奖励则保证了不偏离终极目标,两者结合巧妙解决了训练稳定性难题。
实验结果惊人:大幅提升各类生成模型,实现“即插即用”
在KnowGen基准上的测试结果极具说服力:
- KnowGen极具挑战性:主流开源模型(如Qwen-Image、HunyuanImage-3.0)的K-Score仅在9-15分左右,而顶尖闭源模型Nano Banana Pro能达到50.38分,差距悬殊。
- Gen-Searcher效果显著:为Qwen-Image配上Gen-Searcher-8B后,其K-Score从14.98飙升至31.52,提升超过16个百分点,视觉正确性和文本准确性指标提升尤为明显。
- “即插即用”的强泛化能力:最令人惊喜的是,用Qwen-Image后端训练出的Gen-Searcher智能体,可以直接迁移到其他图像模型上使用,无需额外训练:
- 搭配Seedream 4.5:K-Score从31.01提升到47.29。
- 搭配Nano Banana Pro:K-Score从50.38提升到53.30。
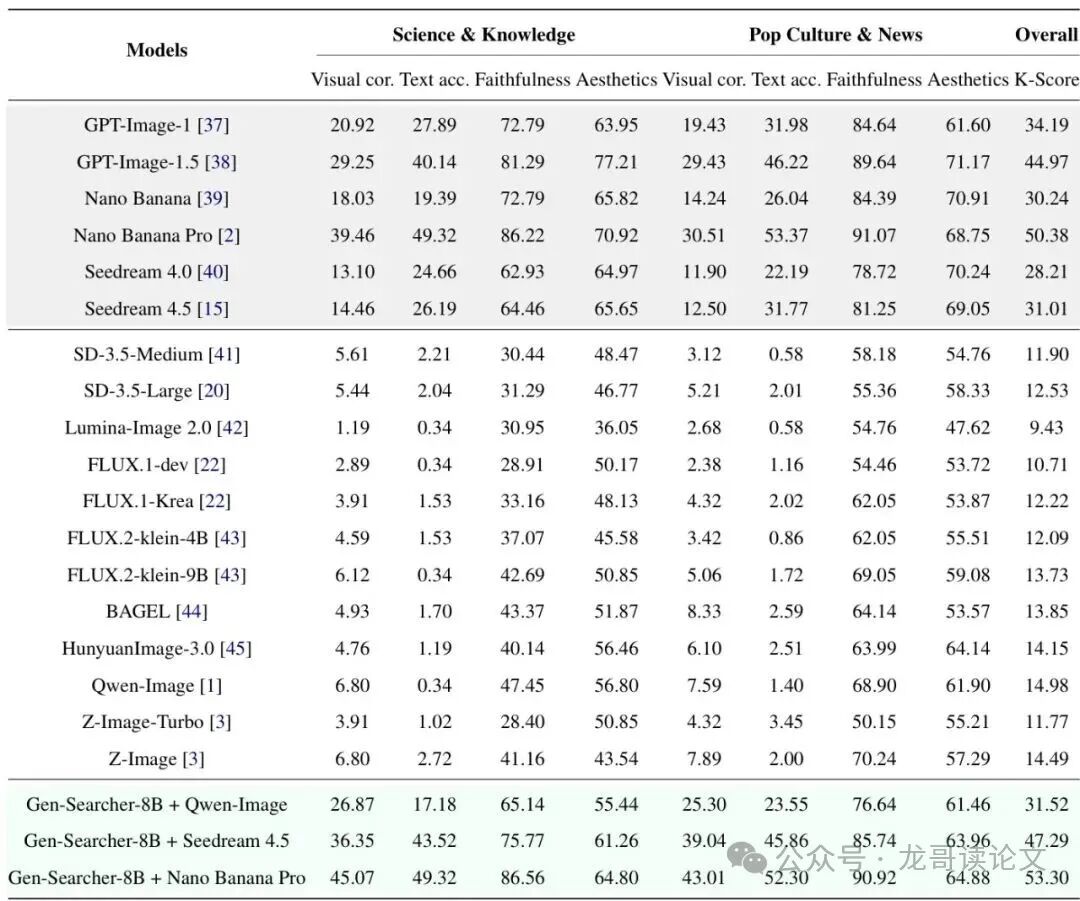
表:不同模型在KnowGen基准上的性能。Gen-Searcher能显著提升各类后端模型的K-Score。
这说明Gen-Searcher学会的是一套通用的、与后端模型解耦的搜索与信息整合能力。在另一个知识图像生成基准WISE上,它同样表现强劲,将Qwen-Image的总体得分从0.62提升到了0.77。
未来展望与挑战
Gen-Searcher为AIGC领域打开了“智能体搜索增强”的新思路,证明了通过智能体技术连接生成模型与实时开放世界知识的有效性。这一范式未来可扩展至视频、3D、音乐等多模态生成。
当然,挑战依然存在:
- 搜索延迟与成本:多轮实时搜索会增加生成耗时和API调用成本。
- 信息可信度与安全:需要更强的信息甄别和事实核查能力,避免生成有害或侵权内容。
- 复杂指令的理解:对于高度模糊或需要纯粹创造性的指令,如何规划有效的搜索策略仍是难题。
核心概念解读
- 智能体强化学习(Agentic RL):训练大模型去使用各种工具完成复杂、多步骤的任务,让其学会自主规划行动序列。
- GRPO算法:一种为训练大模型智能体设计的高效强化学习算法。其核心是对同一问题生成多个答案,在组内进行奖励归一化($A_i = (R_i - \text{mean}(\{R_j\})) / \text{std}(\{R_j\})$),用相对优势更新模型,更稳定高效。
- Gen-Searcher与简单“联网搜索”的区别:本质在于 “是否经过系统性训练” 。Gen-Searcher是一个经过训练、能进行多轮自主规划和推理的智能体,懂得如何拆解问题、整合信息,是从“功能”到“智能”的跃升。
随着多模态智能体技术的成熟,一个能随时联网、博古通今、精准创作的“AI艺术家助手”正逐渐成为现实。这项研究的开源代码和完整数据也为社区进一步探索提供了宝贵的基础。想了解更多前沿AI技术和实战解析,欢迎关注云栈社区的相关讨论。
 发表于 2026-4-5 07:45:54
|
查看: 131|
回复: 0
发表于 2026-4-5 07:45:54
|
查看: 131|
回复: 0
