给大模型做微调,你的第一反应是不是想到LoRA?加一些低秩适配器,小心翼翼地调整权重矩阵,生怕把预训练好的知识给“污染”了。
但最近有篇论文提出了一个堪称“反直觉”的思路:不碰权重一丁点,只改一个“初始值”,就能让模型在新任务上表现飙升,而且推理时完全没有额外计算成本!
这个方法叫做 S₀ Tuning。它专门针对一种越来越流行的模型架构:混合循环-注意力模型(Hybrid Recurrent-Attention Models)。比如阿里的Qwen3.5、TII的FalconH1,它们都在标准的Transformer注意力层之外,加入了像GatedDeltaNet或Mamba-2这样的循环层。
这些循环层有个特点:在处理文本时,它们内部维护着一个不断更新的“隐藏状态”(Hidden State),你可以把它想象成模型的“短期记忆”。通常,这个状态在开始处理一句话时,是被初始化为零的。
S₀ Tuning的想法简单到离谱:我们能不能不修改任何模型权重,只把这个“短期记忆”的初始值(记作S₀),从一个固定的零,变成一个可以学习的参数?
这就好比给一个复杂的机器(模型)换了一个全新的“启动开关”。开机瞬间注入一点特定的“能量”(学习到的S₀),整个机器的运行轨迹就被微妙地改变了。
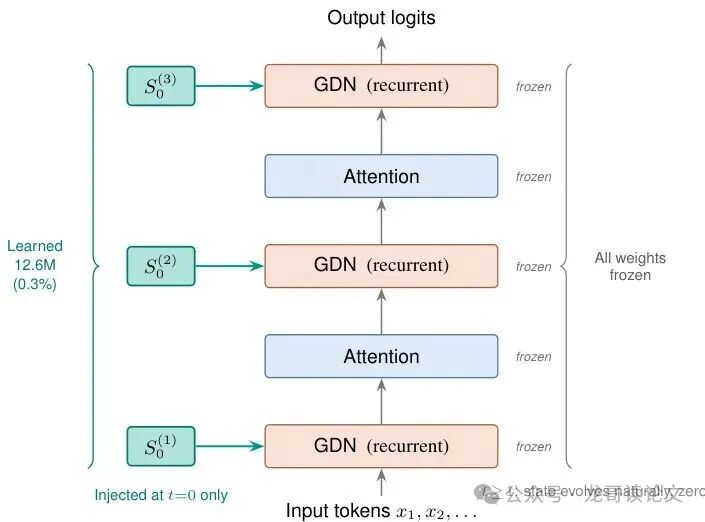
图1: S₀ Tuning的计算图。学习到的初始状态 S₀(青色)仅在处理第一个词元(token)前被注入到每个循环层。之后,它就被吸收到运行状态中,不产生任何额外的计算开销。所有模型权重保持冻结。
更妙的是,因为S₀只在处理第一个词元前被“注入”一次,之后就被整合进模型的自然循环中。所以在推理时,完全没有LoRA那种需要合并权重或增加额外计算分支的开销,是真正的“零开销”微调。
这个想法听起来美好,实际效果如何呢?让我们看看数据。
小数据大提升:48个样本如何带来23.6%的性能飞跃?
论文的实验设置非常“接地气”,甚至可以说有点“寒酸”:他们只用大约48个经过执行验证(execution-verified)的正确代码样本,来微调一个40亿参数的Qwen3.5模型,目标任务是代码生成(HumanEval基准)。
结果令人震惊:在保留的测试集上,仅优化初始状态S₀,就让模型的贪婪解码通过率(pass@1)从基线(未微调)的48.8% 提升到了 72.2%,绝对增益达到+23.6个百分点!
作为对比,使用相同数据对同一模型进行传统的LoRA微调(选择表现最好的配置),只能提升到61.5%。这意味着S₀ Tuning以10.8个百分点的显著优势击败了LoRA(p值小于0.001,统计学上高度显著)。

表1: HumanEval主要结果(在保留问题80-163上)。Qwen结果使用10次随机种子;Falcon结果使用3次随机种子。
有人可能会说:S₀ Tuning有1260万个可学习参数(占模型的0.3%),而实验中对比的LoRA只有470万参数,这不公平!论文作者早就想到了这一点。
他们做了严格的参数量匹配实验:将LoRA的秩(rank)提高到64,使其参数量同样达到1260万。结果出人意料:性能不升反降,平均比基线还差了15.5个百分点!10次随机种子实验中,有8次结果是负增益。
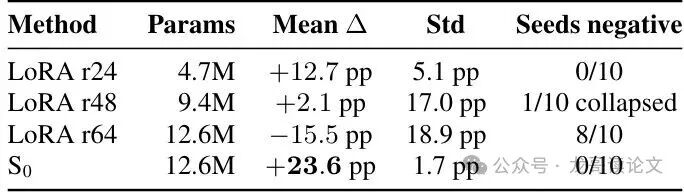
表2: Qwen3.5-4B HumanEval上的参数量匹配LoRA对比(各10次种子)。
这说明在小数据场景下,单纯增加LoRA的容量更容易导致过拟合,而将“学习能力”引导到初始状态这个维度上,则是一种更高效、更稳健的适配方式。
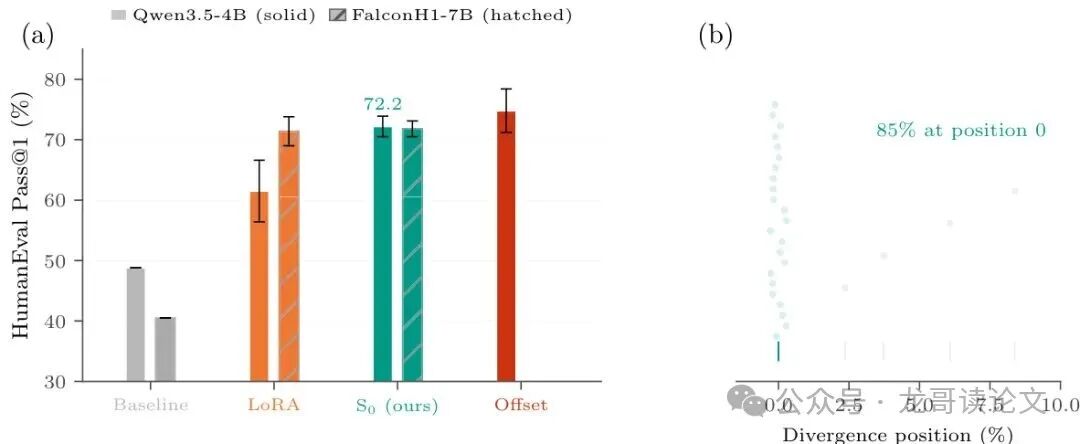
图2: S₀ Tuning概述。 (a) HumanEval上的跨架构对比。
原理揭秘:初始状态扰动如何“steering”生成轨迹?
只改一个初始值,效果为什么会这么强?论文提出了一个核心概念:轨迹引导(Trajectory Steering)。
想象一下,你轻轻推了一下钟摆的初始位置,虽然推力很小,但经过一系列摆动的放大,最终落点可能会完全不同。S₀ Tuning 对循环层初始状态的扰动,就类似于这个“初始推力”。
为了验证这一点,作者做了细致的机制分析。他们发现,虽然S₀的直接影响会随着模型处理提示词(prompt)而指数级衰减——到提示词末尾时,它对输出分布的影响已经微乎其微(KL散度比率降至0.03%)。
但是,这种微小的“偏向”被模型的自回归(autoregressive)生成过程放大了。论文统计了那些被S₀ Tuning “纠正”的样本(从失败变为通过),发现85%(23/27)的样本,在生成答案的第一个字符时,其输出就与基线模型不同了!
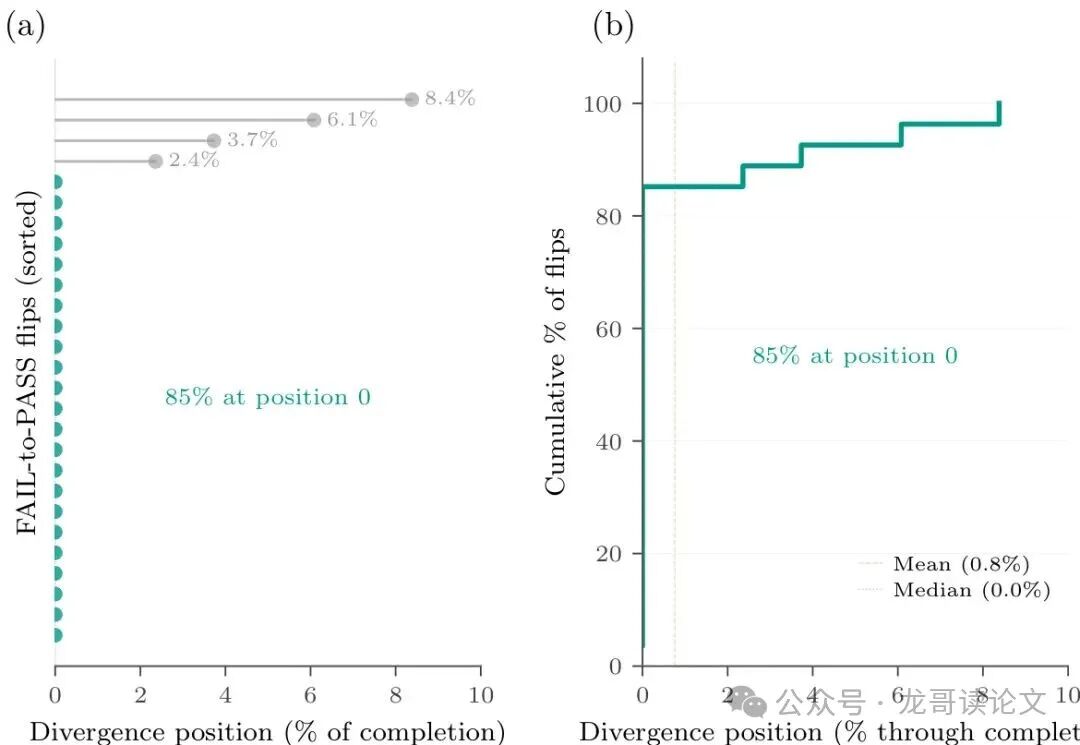
图3: FAIL-to-PASS翻转中的首字符分歧。S₀在第一个机会处就改变了输出分布;自回归解码将此放大为性质完全不同的解决方案。
这意味着,学习到的S₀并没有直接告诉模型“答案是什么”,而是在模型内部隐藏表示中植入了一个微小的、任务相关的方向性偏差。当模型开始生成时,这个偏差足以让它“选择”一个不同的词开头,而一旦开头选错(或选对),后续的生成就像走上了另一条岔路,结果天差地别。
这个过程与LoRA有本质区别。LoRA是均匀地修改权重矩阵,影响模型在所有输入上的行为。而S₀ Tuning是通过引导模型的“初始记忆”来间接地、动态地影响生成轨迹。
为了证明“循环状态”这个表面是关键,作者还做了一个精彩的反面实验(负对照):对一个纯Transformer架构的模型(Qwen2.5-3B)应用前缀微调(Prefix-Tuning),并将可学习参数量匹配到与S₀相当。结果是:在所有9种配置下,性能都下降了13.9个百分点。这强有力地说明,S₀ Tuning的成功离不开混合模型中的循环组件。
不只是Qwen:在FalconH1上的表现与LoRA旗鼓相当
一个好的方法不能只在一个模型上work。为了测试S₀ Tuning的通用性,论文在另一个著名的混合架构——FalconH1-7B 上进行了实验。FalconH1使用的是Mamba-2循环层,并且与注意力的结合方式(并行)也和Qwen3.5(交错)不同。
实验表明,在经过架构特定的超参数(状态缩放因子α)调优后,S₀ Tuning在FalconH1上达到了71.8%的通过率,而LoRA为71.4%。两者在3次随机种子的实验中表现统计上 indistinguishable(无法区分)。考虑到S₀ Tuning零开销的优势,这仍然是一个强有力的结果。
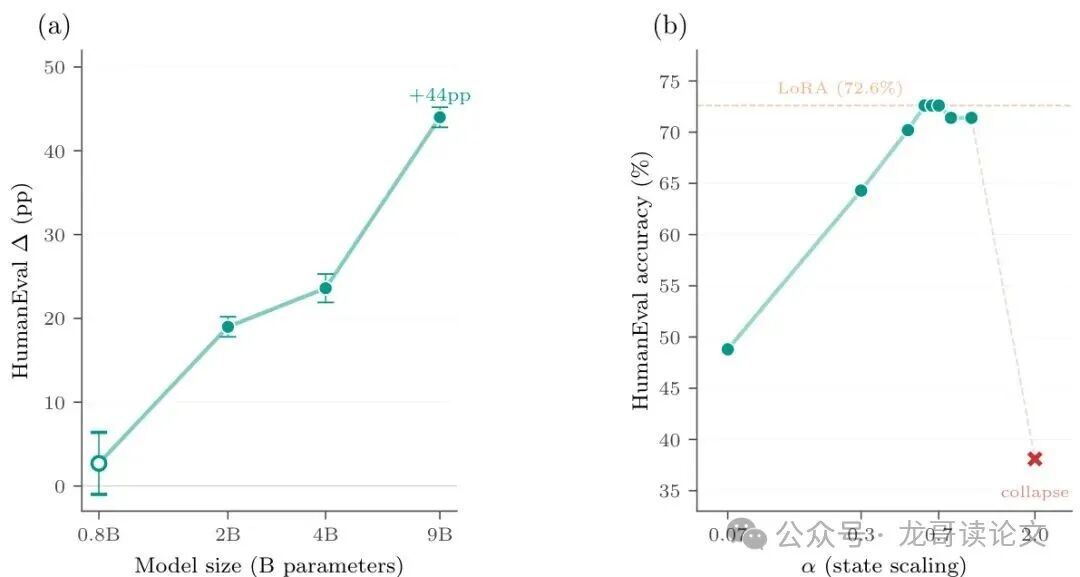
图4: 缩放与架构特定调优。(b) FalconH1的alpha扫描:默认α=0.07仅带来+8.3pp提升,但针对架构调优至α=0.6-0.7时达到71.8%,与LoRA的71.4%匹配。
论文还探索了S₀ Tuning的跨领域迁移能力。在数学推理基准MATH-500和GSM8K上,使用代码数据训练的S₀状态也能带来显著但较小的提升(分别+4.8pp和+2.8pp),这说明学习到的状态偏差具有一定的通用性。
此外,模型越大,S₀ Tuning的收益越明显。在Qwen3.5系列中,从0.8B到9B,增益从+2.6pp一路飙升到+44.0pp(将9B模型的性能从32.1%恢复到76.1%)。这表明大模型中蕴含着更多可以通过状态初始化来解锁的潜在能力。
局限与边界:何时有效?何时失灵?
当然,S₀ Tuning并非万能。论文也诚实地探讨了其局限性:
对架构有要求: 目前的成功案例都基于矩阵值状态(Matrix-valued State)的循环层(如GatedDeltaNet, Mamba-2)。对于使用对角状态(Diagonal State)的早期SSM模型(如Mamba-1),已有研究表明初始状态调优效果不如LoRA。论文认为,状态本身的表达能力(Expressiveness) 存在一个阈值,低于该阈值则无法与权重调优竞争。
对任务类型敏感: 该方法在代码和数学推理任务上表现优异,但在需要高度结构化输出的任务(如文本转SQL的Spider基准)上,几乎没有表现出任何迁移能力(+0.0pp)。作者推测,这可能是因为SQL查询的起始部分(如SELECT)多样性较低,初始状态的微小扰动难以引导出完全不同的、正确的生成轨迹。
对训练数据有要求: 论文中S₀ Tuning的成功依赖于少量经过执行验证的正确样本。这在小数据、高价值场景(如修复特定代码bug)下是可行的,但在无法轻易验证输出正确性的领域(例如创意写作),获取高质量训练数据可能成为瓶颈。LoRA在这方面约束更少。
未来展望:循环状态作为通用适配表面的潜力
S₀ Tuning的价值远不止于一个高效的微调工具。它更像一个“灯塔”,照亮了混合模型架构中一个长期被忽视的“新大陆”——循环状态空间。
随着Qwen、Falcon等主流开源模型纷纷采用混合架构,我们手中拥有越来越多具备强大循环组件的模型。S₀ Tuning证明了,仅仅利用这些组件自带的、动态更新的状态,就能实现高效的任务适配。
我们可以想象更多可能性:
- 快速任务切换:一个模型,多个S₀文件。需要执行代码任务?加载代码专用的S₀。需要解答数学题?瞬间切换到数学专用的S₀。无需重新加载模型或合并权重,切换成本极低。
- 个性化与安全:为用户或应用场景定制专属的启动状态,在不过度改变模型通用能力的前提下,优化特定领域的表现。
- 更丰富的状态操作:除了优化初始状态,是否可以优化每个时间步的状态偏移(论文中的State-offset变体,性能更好但有开销)?或者像“状态汤(State Soup)”研究那样,对不同任务的状态进行插值?
S₀ Tuning打开了一扇门,让我们意识到在追求参数高效微调的道路上,除了在权重矩阵上“精打细算”,还可以在模型的动态运行机制上做文章。这无疑为未来的模型适配研究提供了一个充满想象力的新方向。
核心问答与总结
S₀ Tuning和LoRA、Prefix-Tuning到底有什么区别?
核心区别在于“修改的对象”。LoRA修改模型权重(线性层的参数矩阵),Prefix-Tuning在输入前添加可学习的虚拟词元(影响注意力机制)。而S₀ Tuning不修改任何固定参数,只修改循环层内部动态变量的初始值。这使得它推理零开销,且特别适合混合了循环组件的模型。
“轨迹引导(Trajectory Steering)”具体是什么意思?
你可以把模型生成文本的过程想象成一辆车在行驶。LoRA像是换了车的发动机和零件(权重),改变了车的基本性能。而S₀ Tuning像是仅仅在车子启动时,给它一个特定的初始推力和方向盘角度(初始状态)。这个微小的初始条件,通过车辆自身复杂的动力学(模型的循环和自回归过程),被放大成了完全不同的行驶路线(生成的文本)。这就是“引导轨迹”。
我该在什么情况下考虑使用S₀ Tuning?
首先,你的模型必须是混合了矩阵值循环层(如GatedDeltaNet, Mamba-2)的架构,例如Qwen3.5, FalconH1等。其次,你的任务场景最好是小数据、高价值,且能获得少量已验证的正确样本(如代码补全、数学解题)。最后,你对推理延迟和部署简洁性有极高要求,希望实现真正的零开销适配和快速任务切换。如果满足这些条件,S₀ Tuning会是一个极具吸引力的选项。
S₀ Tuning是参数高效微调领域一个令人耳目一新的突破。它揭示了混合架构中“状态”这一维度的巨大潜力,为模型适配提供了全新的视角。虽然目前存在对架构和任务类型的限制,但其零开销、高效适配的核心思想极具启发性和实用价值。随着相关研究的深入,我们有望在更多模型和场景中利用这一高效的微调范式。想了解更多前沿技术解析与实践,欢迎关注云栈社区的人工智能与开源实战板块,获取更多深度内容。
原论文信息:
 发表于 2026-4-5 07:43:27
|
查看: 192|
回复: 0
发表于 2026-4-5 07:43:27
|
查看: 192|
回复: 0
