想象一下这个场景:一个酷似终结者T-800骨架的人形机器人,在户外阳光下,仅凭自己“头”上的眼睛,与人类连续对打乒乓球,甚至还能完成一记暴力扣杀。

图1:SMASH系统实现了首个户外人形乒乓球手和首个在双足人形机器人上的全身扣杀。通过可扩展的运动生成和全身运动匹配,机器人在广阔的击球工作空间内实现了富有表现力且敏捷的球类交互。
这可不是科幻电影,而是香港大学和Kinetix AI团队在论文《SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision》中展示的真实成果。
以前让机器人打乒乓球,大多离不开一套昂贵的“上帝视角”系统:需要在场地周围架设多个高速外部摄像头,实时追踪小球和机器人的位置。这就像是给机器人开了“全图挂”,虽然能打,但离真正的自主和“像人一样”还差得远。一旦走出实验室,没了这些外部设备,机器人就立刻“失明”了。
SMASH系统(直译就是“扣杀”)的核心突破,就是让人形机器人扔掉“拐杖”,仅依靠自己的视觉(Egocentric Vision)和身体感知来打乒乓球。这背后是一套精密的系统工程,其中最亮眼的是两大核心技术。
核心难题:如何让机器人学会“千变万化”的击球动作?
要理解SMASH的创新,我们先得看看传统方法是怎么做的。
一种常见思路是“模仿学习”:先请人类高手打几板,用动作捕捉(Motion Capture,简称MoCap)设备把动作录下来,然后让机器人照着学。但问题来了:就算你录上几百个击球动作,它们覆盖的击球点(球拍触球的位置)在桌面上也是星星点点,非常稀疏。如果来球飞到一个没被录过的位置,机器人就蒙了,因为它没学过那个姿势。
另一种思路是让机器人自己“瞎练”,用强化学习(Reinforcement Learning)在仿真环境里摸索。但乒乓球是个精细活,光靠“瞎练”很容易练出一些奇奇怪怪、不协调的“僵尸”动作,比如只动手臂,腿脚不动,或者身体扭曲,毫无美感,也不符合物理规律。
因此,核心矛盾在于:我们既需要一个覆盖整个可能击球区域的、丰富的动作库作为参考(保证动作自然、协调),又需要机器人能灵活选择和调整这些动作去精准击中飞来的球(保证任务成功)。
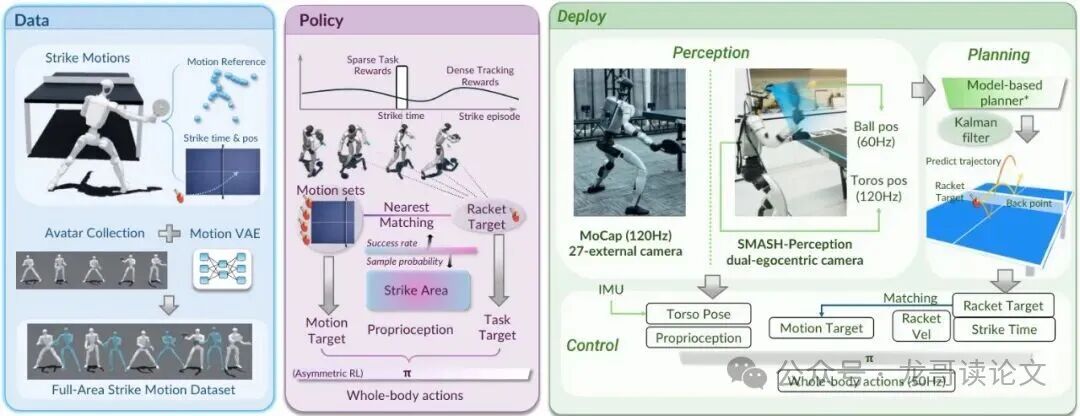
图2:SMASH系统概览。本系统将可扩展运动生成、任务对齐的策略学习和以自我为中心的机载感知连接成一个统一的人形乒乓球流水线。
SMASH给出的答案就在这张总览图里,它分为三个核心阶段:
数据阶段:用AI模型“脑补”出大量新击球动作,扩充动作库。
策略学习阶段:训练一个控制全身的“大脑”(策略),让它学会根据来球目标,从动作库里匹配最合适的姿势,并微调手腕去精准击球。
部署阶段:机器人的“眼睛”(机载摄像头)实时观测球和自身位置,预测球路并规划击球目标,驱动“大脑”执行动作。
妙招一:用AI“脑补”缺失的动作,覆盖整个击球空间
团队首先捕捉了400段人类击球动作。但正如前面所说,这些动作的击球点分布不均。SMASH祭出了第一个法宝:Motion-VAE(运动变分自编码器)。
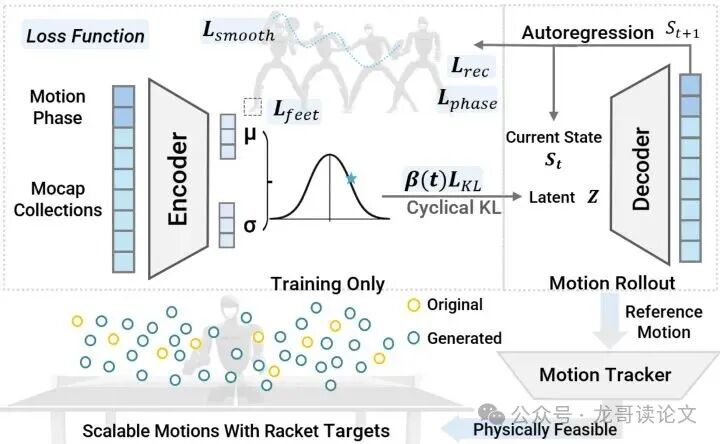
图3:用于可扩展击球运动生成的Motion-VAE。
简单理解,VAE就像一个会“脑补”的画家。你给它看几张真人照片(真实击球动作),它先学习这些人物的骨骼、姿态规律(编码到一个“潜变量”空间),然后你告诉它:“画一个击打左上角球的动作。”它就能根据学到的规律,生成一个全新的、但看起来依然自然协调的击球动作。
为了让生成的“画作”更逼真,论文还给VAE的训练加了几个“紧箍咒”:
相位重建损失:确保生成的挥拍动作有完整的“准备-击球-收拍”节奏感。
平滑损失:让动作衔接流畅,不抽搐。
足部穿透惩罚:防止生成“脚插进地里”这种违反物理的动作。
这样,Motion-VAE就能在原始400个动作的基础上,“脑补”出成千上万个新动作,它们的击球点能均匀覆盖整个桌面区域。
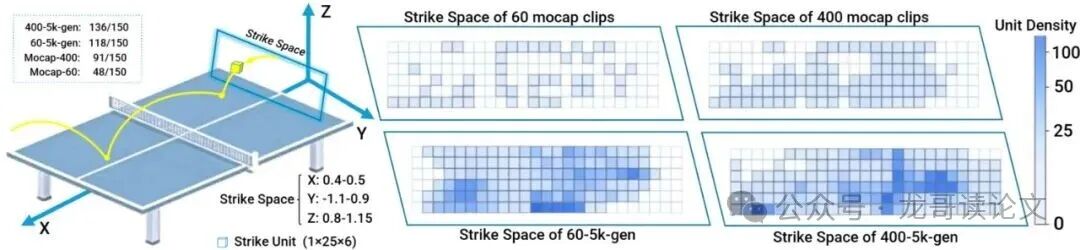
图4:Motion-VAE扩展了击球空间的覆盖范围。与原始动捕数据集相比,Motion-VAE生成的动作在可到达的击球工作空间上产生了更广泛的击球目标分布。
但还没完!AI“脑补”的动作可能在数学上很漂亮,但机器人硬件不一定能做得出来。比如,一个动作可能需要膝关节瞬间扭转180度,这在实际物理中是不可能的。
因此,SMASH加了一个精妙的“追踪器过滤”步骤:把生成的动作,喂给一个在仿真中训练好的、专门模仿动作的“追踪器”策略去执行。如果这个动作被顺利地做了出来,就保留;如果机器人摔倒了或者动作完全走样,就淘汰。
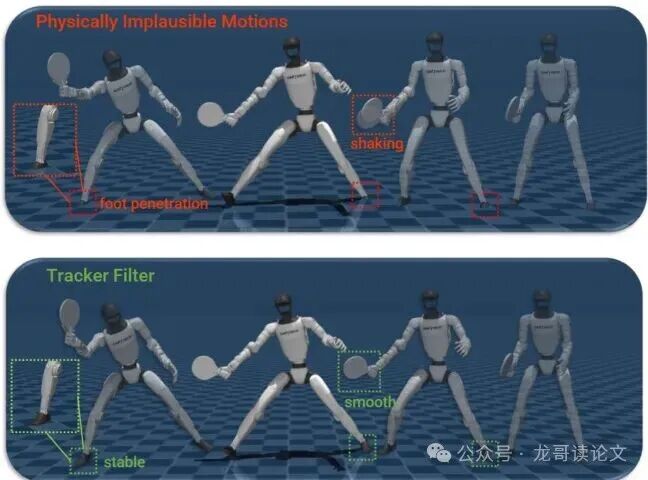
图5:物理上不可行的击球动作(上)与经过追踪器过滤校正的动作(下)对比。
过滤后(下图)的机器人姿势明显更稳定、更合理。经过这轮“物理考试”的筛选,最终形成了一个既丰富多样又物理可行的击球动作库。实验证明,使用这个扩充后的库,机器人策略学得更快、效果更好。
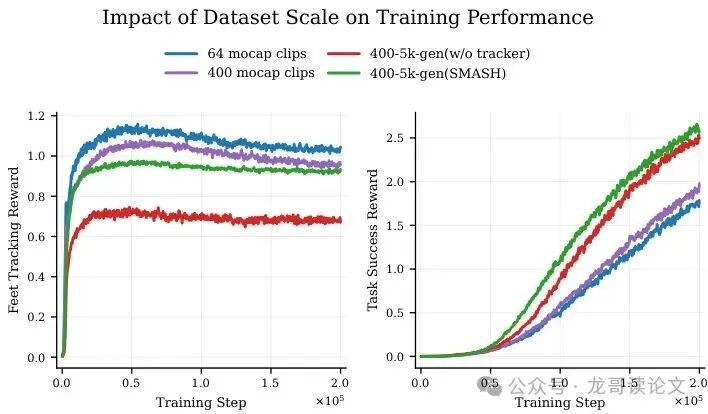
图6:数据集规模对训练性能的影响。
妙招二:像人类一样,根据来球实时匹配最佳击球姿势
有了丰富的动作库,接下来就要训练机器人的“大脑”(控制策略)了。这个大脑的目标是:根据实时预测的来球落点(任务目标),瞬间从动作库里找到一个最接近的姿势作为参考,然后控制全身(尤其是灵活的手腕)微调,精准地把球打回去。
这个过程叫任务导向的运动匹配。匹配的原则很简单:计算当前需要的击球位置,在动作库里找一个击球位置最接近的动作。由于库里的动作已经覆盖很广,所以总能找到一个不错的“基础模板”。
接下来是关键:策略的大脑通过强化学习来训练,它的“观察”和“奖励”设计得非常巧妙。
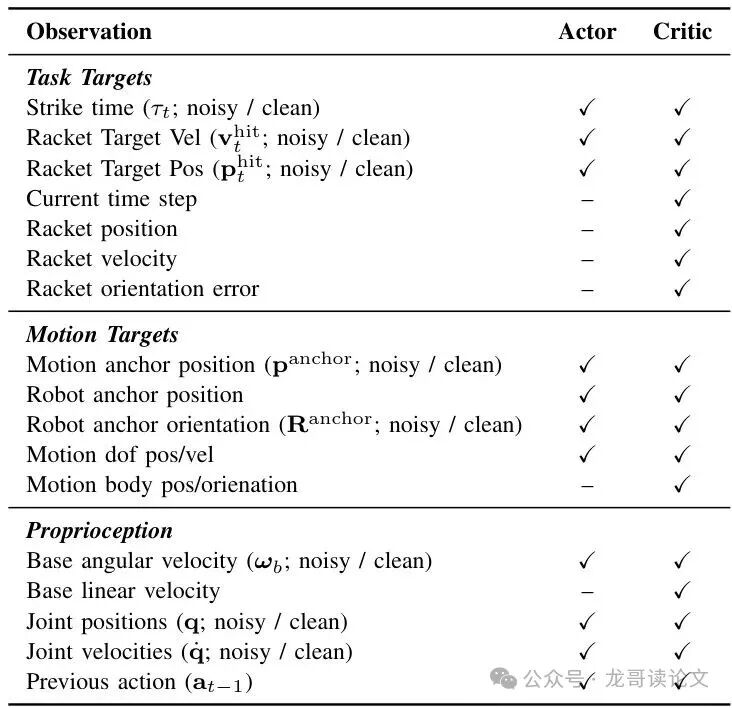
表1:面向演员和评论家的非对称观察设计。
它采用“演员-评论家”框架。简单说,“演员”负责做动作,“评论家”负责打分。为了让策略更鲁棒(对噪声不敏感),“演员”看到的是带噪声的观察(比如略有误差的击球时间、自身关节角度),而“评论家”在训练时能看到更干净、更准确的信息来辅助打分。
给策略的“奖励”是混合的:
任务奖励:打中了球,并且球拍在击球瞬间的位置、速度、角度都符合要求,就给高分。这是主要目标。
运动跟踪奖励:身体其他部位(排除手腕)要尽量贴近匹配到的那个“基础模板”动作,保证姿势协调自然。
正则化奖励:动作不能太猛、太耗能,要平滑。
这里有个神来之笔:手腕被排除在运动跟踪奖励之外。这意味着,策略的大脑被赋予了一项特权:在保持全身大框架协调(像人类一样挥拍)的前提下,可以自由地、精细地控制手腕去“够”那个球,调整拍面角度去控制回球方向。这完美模拟了人类打球时“身体带动,手腕微调”的智慧。
实战检验:户外对打、暴力扣杀,样样精通!
学成了,该上“考场”了。SMASH的感知系统同样硬核。它采用双摄像头方案:一个装在头上,负责远距离追踪小球;一个略微朝下,结合AprilTag标记来定位机器人自身和球桌的位置。所有计算都在机载电脑上实时完成,频率超过50Hz。
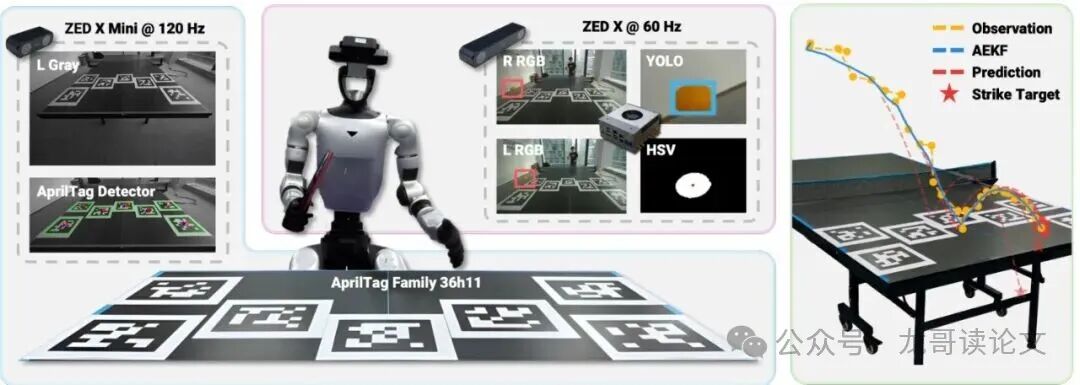
图7:以自我为中心的机载感知系统。感知流水线结合了基于YOLO的球体检测、基于AprilTag的机器人定位和自适应卡尔曼滤波用于状态估计。
实验结果表明,这套系统强大而稳定。

图8:硬件实验快照。展示了多样化的全身技能,例如扣杀、低身击球、横向移动。
在室内,基于高精度动捕系统作为感知基准,机器人表现出极高的成功率(超过90%的单次击球成功率),并能完成连续对打。
更重要的是,在户外,完全依靠自己的摄像头,机器人成功实现了连续击球对打,这是首次演示。它不仅能进行常规的推挡,还能做出大幅度的横向移动击球、低身救球,以及充满力量的全身协调扣杀!动作非常拟人、协调。
论文还详细分析了感知系统的误差。如下图所示,随着球越来越接近击球时刻(时间趋近于0),对球的位置、速度和击球时间的估计误差都显著减小。这说明系统在关键时刻的感知是最准的,符合直觉。
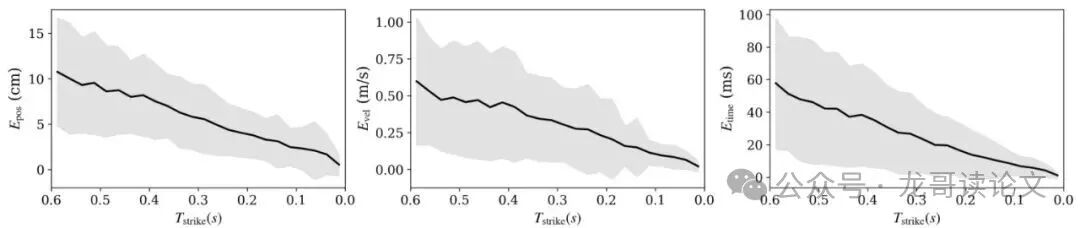
图9:自我中心感知噪声。图表显示了位置、速度和击球时间估计的误差分布与剩余击球时间的关系。
最终的击球点分布和成功率如下图所示,可以看到机器人能在桌面相当大的范围内成功回球,覆盖了正手和反手区域。
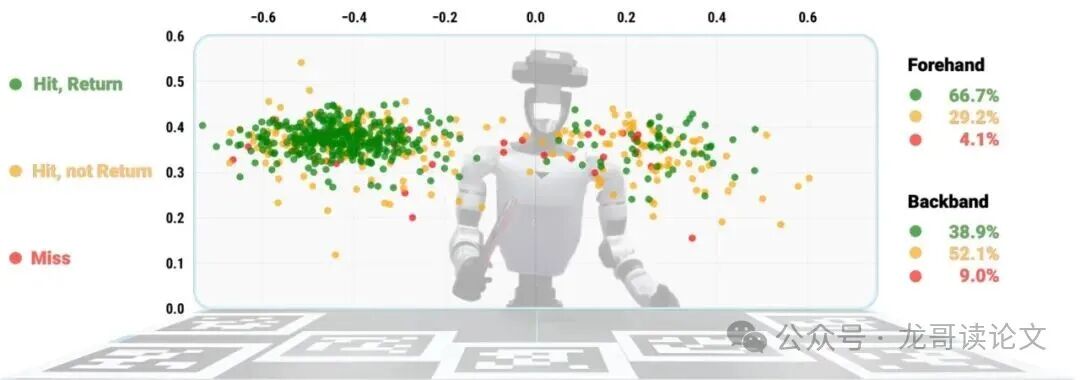
图10:击球点分布和回球表现。正手和反手击球点与可到达击球工作空间内相应的击球和回球统计数据一起可视化。
局限与展望:视野和旋转,仍是待攻克的堡垒
当然,SMASH并非完美无缺。论文也坦诚地指出了当前系统的局限性,这恰好指明了未来的方向:
视野限制:目前机器人的摄像头视野有限,当球飞到非常贴近身体或者极端侧面时,可能会短暂丢失跟踪。未来的改进方向可能是使用广角镜头、鱼眼相机,或者引入预测模型来“猜测”短暂丢失的球路。
球的旋转:当前系统主要处理不转或轻微旋转的球。对于强烈的上旋、下旋或侧旋球,球的飞行轨迹会发生显著变化,目前的物理模型无法精确预测。这是乒乓球机器人领域一个公认的难题,需要更先进的感知技术(如高速相机分析球面纹理)和空气动力学模型来解决。
尽管有这些挑战,SMASH系统已经为“具身智能”和“人形机器人动态交互”树立了一个非常出色的标杆。它证明,通过巧妙的算法设计(可扩展运动生成+任务导向运动匹配),结合鲁棒的机载感知,人形机器人完全有能力在复杂的动态任务中实现不依赖外部基础设施的自主行为。这项研究融合了运动生成、强化学习与实时感知,其系统构建思路对于开源实战和机器人应用开发具有重要的参考价值。
核心问题解答
下面是对于大家可能的一些问题的解答:
这篇论文最核心的贡献是什么?
最核心的贡献是构建了一个不依赖任何外部感知设备(如固定摄像头、动捕系统)的、能完成动态全身协调任务(乒乓球连续对打)的人形机器人系统。它将可扩展的运动生成、任务对齐的策略学习和鲁棒的机载视觉感知无缝集成,实现了从“实验室特供”到“户外可用”的关键跨越。
Motion-VAE和“追踪器过滤”分别解决了什么问题?
Motion-VAE解决了高质量动作数据稀缺和分布不均的问题,它通过生成新动作来“填满”整个击球空间。“追踪器过滤”则解决了生成动作的物理可行性问题,确保动作库里的每个姿势都是机器人身体在实际物理约束下能够稳定做出的,将“数学上合理”变成了“物理上可行”。
为什么策略训练时要让“演员”和“评论家”看到不同的信息(非对称观察)?
这是一种提高策略鲁棒性和仿真到现实迁移能力的常用技巧。“演员”(执行者)看到带噪声的、与现实部署更接近的观察,迫使它学会在不确定信息下做出稳健决策。“评论家”(打分者)在训练时看到更干净、更特权(Privileged)的信息,能做出更准确的价值评估,从而更好地指导“演员”学习。两者各司其职,最终得到一个在嘈杂现实中也能work的策略。
论文简评
创新性:★★★★☆
将可扩展运动生成(Motion-VAE+追踪器过滤)与任务导向的运动匹配相结合,用于解决人形机器人动态全身任务的数据覆盖和动作自然性问题,思路清晰且有新意。真正实现纯机载视觉下的户外连续乒乓球对打,具有标志性意义。
实验合理度:★★★★☆
实验设计全面,涵盖了仿真验证、室内高精度基准测试和终极的户外真实场景测试。对感知误差、动作库影响、各模块贡献等进行了详尽的消融分析和可视化,支撑有力。
研究价值:★★★★★
价值很高。为人形机器人在动态、非结构化环境中的自主交互提供了一个强有力的技术范本和系统级解决方案。其“生成扩充数据+物理过滤保证可行性+任务条件匹配”的框架,可迁移至其他需要丰富技能库和精准任务执行的人形机器人应用。
稳定性与泛化:★★★☆☆
在预设测试场景下表现出色,但对极端情况(如高速旋转球、视野外丢球)的鲁棒性有待验证。适应不同落点、速度的平击球,但对球的旋转这一关键变量基本没有泛化能力。
复现与产品化:★★☆☆☆
难度较高,涉及完整的软硬件栈集成,论文未提及代码开源。目前完全处于前沿研究演示阶段,受限于硬件成本、环境敏感性等因素,距离产品化还有很长的路。
此类前沿的机器人系统研究,其背后的技术思路和工程实现细节,往往值得在专业的开发者社区进行深入探讨和交流。
参考文献
[1] Ren, J., Li, Y., Zhang, K., Fu, P., et al. (2026). SMASH: Mastering Scalable Whole-Body Skills for Humanoid Ping-Pong with Egocentric Vision. arXiv preprint arXiv:2604.01158.
[2] 项目主页与演示视频:https://mmlab.hk/Smash/
 发表于 2026-4-5 07:40:43
|
查看: 151|
回复: 0
发表于 2026-4-5 07:40:43
|
查看: 151|
回复: 0
