近日,来自麻省理工学院 (MIT)、加州大学圣地亚哥分校 (UCSD)、EleutherAI 等多所顶尖机构的研究者发表了一篇观点论文,对当前 AI 科研领域的一个普遍做法提出了尖锐质疑:依赖 ChatGPT、Claude 这类“黑箱”模型进行严肃的科学研究,其结论的可靠性究竟如何?
论文标题直指核心:《语言模型需要开放到什么程度,才能支持可靠的科学推理?》。这篇论文并非介绍新技术,而是从科研方法论的层面进行系统性批判,论证了一个关键主张:对于旨在做出可推广科学推断的研究,开放权重模型应成为默认选择,而封闭的 API 模型则充满了难以规避的风险。
核心概念:封闭模型 vs. 开放权重模型
在深入探讨之前,有必要明确两个基础术语:
- 封闭模型 (Closed Model):指通过网页聊天界面或商业 API 访问的系统,例如 chatgpt.com 上的 ChatGPT。用户只能输入文本并接收文本输出,而模型权重、架构细节、数据处理流程、系统提示词等关键信息完全隐藏。它本质上是一个“黑箱”。
- 开放权重模型 (Open-Weight Model):指提供了完整模型权重、分词器、架构说明和足够运行代码的模型。例如,你可以从 Hugging Face 平台下载 Llama 3 的权重,在自己的机器上完整运行,并访问其内部的完整概率分布。Meta 开源的 Llama 系列、Mistral AI 的模型大多属于此类。
AI 研究正快速从早期的开放模型转向封闭模型。然而,当研究目标不仅仅是“用模型完成任务”,而是要对模型本身做出可推广的科学推断时,封闭模型的“黑箱”特性就暴露出了致命缺陷。论文主要聚焦于三大核心科研目标:模型评估、模型比较和模型可解释性。
三大威胁:封闭模型如何“摧毁”可靠科学推断
论文精炼地总结了封闭模型对可靠科学推理构成的三大根本性威胁。下面的表格来自论文附录,清晰地概括了这些问题:
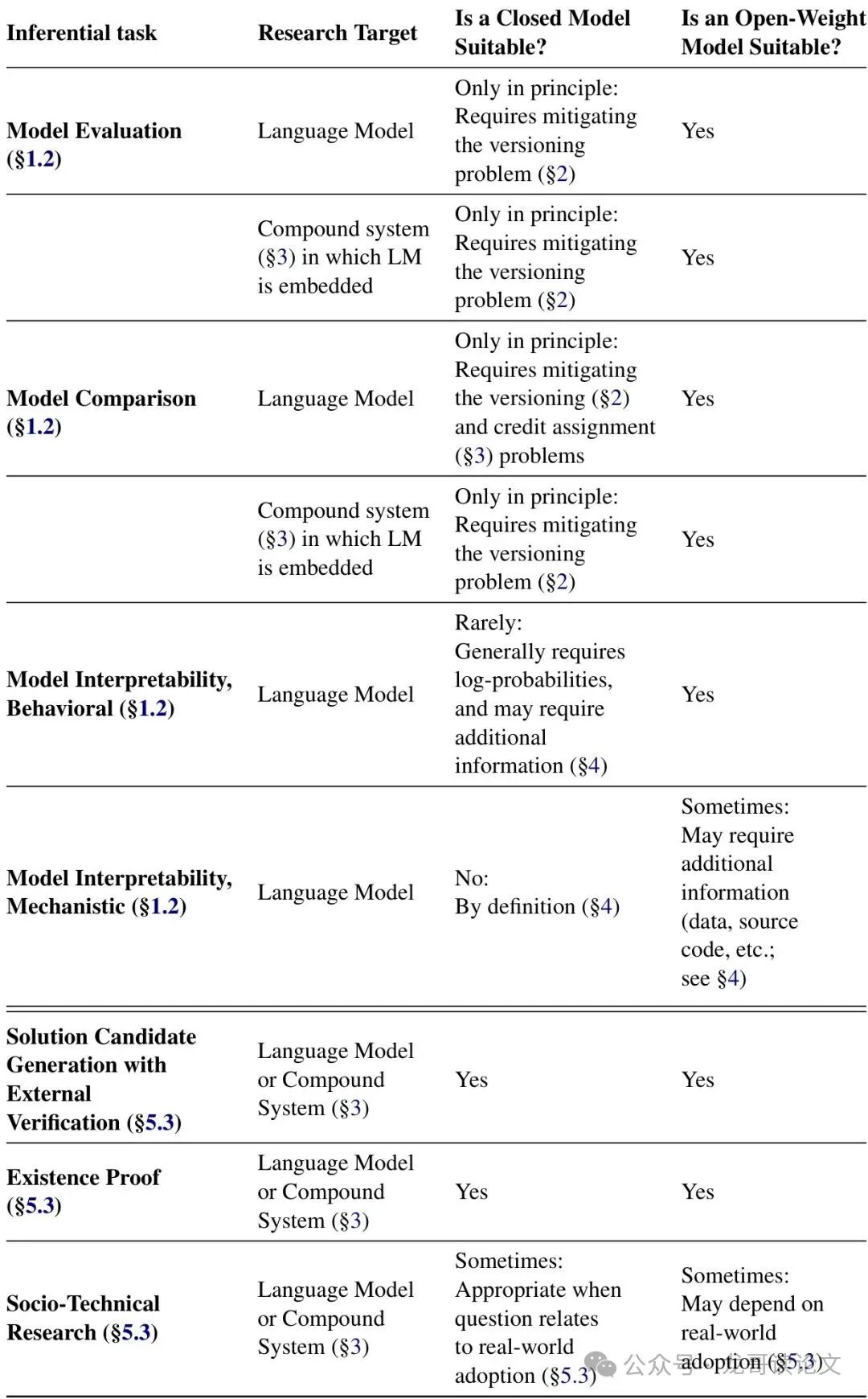
下面我们用更直白的语言解读这三大“罪状”。
威胁一:版本化问题 - “此 GPT 非彼 GPT”
你认为今天测试的“GPT-4”和三个月前另一篇论文中提到的“GPT-4”是同一个模型吗?答案很可能是否定的。
封闭模型作为商业产品,会进行静默更新。提供商可能添加了新数据、进行了安全微调,甚至修改了底层架构,但不会每次都高调宣布。这导致一个严重问题:基于旧版本模型得出的研究结论,可能完全无法复现,也无法推广到新版本。
论文引用了一项扎心的事实:GPT-3.5 和 GPT-4 在判断一个数是否为素数这项任务上的表现,在 2023 年 3 月和 6 月的不同版本间,正确率波动高达 60%!更关键的是,一旦旧版本 API 被下线(如最初的 GPT-3),所有基于它的研究都成了无法验证的“绝版”。
这意味着,任何声称“模型A在任务B上表现如何”的评估或比较,其有效性都严格限定在某个特定时间点的某个特定服务实例上,完全违背了科学研究所必需的稳定性和可复现性原则。

威胁二:归因问题 - “功劳算谁的?”
当你通过 ChatGPT 的 API 得到一个惊艳的回答时,你真的知道这个答案是怎么生成的吗?是核心语言模型本身的智慧,还是背后隐藏的系统提示词在引导?或者是接入了联网搜索或计算器 API?又或者是输出被安全过滤器修改过?
封闭模型通常是一个由多个组件构成的“复合系统”,但这些组件及其交互方式完全不透明:
- 系统提示词“作弊”:提供商可能在用户问题前预置一段指令(如“你是一个乐于助人且准确的AI”),这会极大影响表现,但研究者无从知晓。
- 解码策略“黑箱”:模型如何从概率分布中挑选下一个词(贪婪采样、温度采样等)?策略是固定的还是动态的?这些细节被隐藏,却严重影响输出。
- 后处理“滤镜”:生成的内容在返回前可能被过滤或重写,你看到的可能不是模型的“原始想法”,而是“安全版本”。
因此,当评价“GPT-4在任务X上表现很好”时,你实际上是在评价一个无法拆解的“黑箱复合系统”,根本无法确定有多少功劳归于核心语言模型本身。这使得公平的模型比较和可解释性研究无从谈起。
威胁三:信息不足问题 - “巧妇难为无米之炊”
封闭模型通常只返回生成的文本。对于更深度的科学评估,这点信息远远不够:
- 无法获取概率分布:在很多场景下,我们关心模型“认为”各个选项的可能性有多大(例如,诊断是“流感”的概率是90%还是51%)。封闭模型不提供概率。
- 无法进行精细探测:假设想测试模型对物理世界的理解,给出句子“她把一件旧毛衣塞满了__”。我们想比较模型对“树叶”和“水”这两个选项的倾向性。封闭模型只返回最可能的词,我们无从比较。
- 无法触及内部状态:现代的模型可解释性研究(如探查特定神经元、分析注意力机制)严重依赖对模型内部隐藏状态的访问,这对封闭模型是不可能的。
没有这些关键信息,许多深入的评估、比较和解释工作就成了“无米之炊”,结论的深度和可靠性大打折扣。

解决方案:为何开放权重模型是可靠研究的基石
面对上述三大威胁,解决方案清晰明确:对于旨在做出可推广科学推断的研究,开放权重模型应成为默认选择。
开放权重模型能完美或极大地缓解所有威胁:
- 解决版本化问题:一个固定的权重文件在任何时间、任何地点运行,结果都应是可复现、可比较的,从而重建了科学研究的基石——可重复性。
- 解决归因问题:你可以隔离出纯粹的核心语言模型来运行,没有隐藏提示和后处理,可以精确控制所有参数。任何表现都能明确归因于模型本身。
- 解决信息不足问题:你可以获取完整的概率分布,查看任何中间层的内部激活状态,为精细评估和深度可解释性研究铺平道路。
当然,运行大型开放权重模型需要计算资源和专业知识,这构成了门槛。但社区正在努力降低门槛,例如通过提供易于使用的推理接口和工具(如 NNsight)来访问内部状态。
实践指南:给研究者、读者与审稿人的建议
论文给出了具体的行动建议:
给研究者的建议:
- 默认使用开放模型:如果科学目标是评估、比较或解释语言模型本身,优先选择开放权重模型。
- 使用封闭模型需充分论证:如果必须使用封闭模型(如研究社会影响、作为性能上限参考),必须在论文中明确说明理由,并系统性讨论三大威胁对推论的可能影响。
- 详细记录版本信息:如果使用封闭模型,务必记录使用的大致版本和测试日期。
给读者和审稿人的建议:
- 批判性看待结论:对于基于封闭模型的比较性结论,要质疑其是否解决了版本和归因问题。
- 审稿时提高标准:对于使用封闭模型进行模型评估/比较的研究,应要求作者提供强理由并充分讨论局限性。

未来展望:走向更全面的开放科学
论文最后指出,开放权重是可靠科学推理的必要基础,但可能还不是充分条件。为了进行更深度的研究(如探究训练数据的影响),有时还需要更多:
- 训练数据:理解模型“吃了什么”。
- 训练检查点:研究能力涌现等现象。
- 完整的训练和评估代码:确保每一步都可复现。
未来的理想状态是朝着更全面、更彻底的开放科学迈进,而开放权重是实现这一目标的关键第一步。
关键问题澄清
1. 什么是开放权重模型?和开源模型一样吗?
开放权重模型特指提供了完整模型参数(权重)的模型。这是“开源”的重要组成部分,但狭义的开源可能还包含训练代码、数据等。本文强调“开放权重”是因为这是解决科学推理三大威胁的最低必要条件。
2. 三大威胁里,哪个最“坑”?
归因问题可能最为棘手。版本问题尚可“留痕”,信息不足有时能规避。但归因问题无解,你永远不知道测试的“GPT-4”能力里,有多少是模型真本事,多少是“系统提示词外挂”,这使得任何比较研究都像是在比较两个包装未知的盒子。
3. 所有用封闭模型做的研究都没价值吗?
并非如此。论文明确了封闭模型适用的场景:
- 作为“存在性证明”或性能上限参考。
- 研究其作为已部署产品的社会、伦理影响。
- 生成一次性的、可验证的解决方案(如辅助数学证明)。
在这些场景下,研究对象就是“黑箱产品”本身,结论不追求推广到模型内核,因此是合理的。
总结
这篇来自 MIT 等机构的论文为 AI 科研社区敲响了一记警钟。它系统地论证了,如果研究目标是理解模型本身而非仅仅使用它,那么依赖封闭的“黑箱”模型将严重损害科学结论的可靠性、可复现性和可解释性。开放权重模型,凭借其固定的版本、透明的运行方式和丰富的可访问信息,为可靠的、可积累的科学知识构建提供了必要的基础。这不仅是方法论上的建议,更是对整个领域研究规范性的一次重要呼吁。对于从事或关注 Transformer 架构及大语言模型研究的开发者和学者而言,理解和践行这一原则至关重要。更多关于开源模型最佳实践的讨论,也欢迎在云栈社区的技术板块进行交流。
 发表于 2026-4-5 07:37:51
|
查看: 139|
回复: 0
发表于 2026-4-5 07:37:51
|
查看: 139|
回复: 0
