为了实现极致的全面屏体验,屏下摄像头(UDC)技术应运而生。然而,光线穿过屏幕像素层时产生的复杂光学效应,导致拍摄的图像存在模糊、噪声、色偏和炫光等多种问题。更棘手的是,这种退化并非均匀分布,图像中心与边缘的受损程度和类型往往天差地别,为AI修复模型带来了巨大挑战。
针对这一“空间变化退化”难题,韩国汉阳大学与国防发展局的研究团队提出了一种新颖的解决方案——UCMNet(Uncertainty-aware Context-Memory Network,不确定性感知上下文记忆网络)。该网络的核心创新在于,它不再对所有图像区域“一视同仁”,而是学会了主动判断“哪里最难修复”,并据此从内置的“记忆库”中自适应地检索最佳的修复方案。
实验结果令人印象深刻:UCMNet在多个权威的UDC图像恢复基准测试中均取得了领先的性能,同时模型参数量比之前的先进方法减少了约30%。

图:现有UDC修复模型与UCMNet的视觉对比(上排为修复结果,下排为误差图)。UCMNet显示出更少的伪影和更准确的纹理重建(蓝色表示小误差,黄色表示大误差)。
屏下摄像头图像恢复的挑战:空间变异性与细节丢失
要理解UCMNet的价值,首先需厘清UDC图像退化的特殊性。这种退化是混合型且空间变化的:
- 混合型损伤:图像同时遭受模糊(类似失焦)、噪声(颗粒感)、低光照以及由屏幕结构引起的衍射炫光。
- 空间变化性:这是最核心的难点。由于光线穿过屏幕不同区域的光路长度和结构密度不同,导致图像中心和边缘的退化模式与强度存在显著差异。中心可能仅是轻微模糊,而边缘区域则可能因强烈衍射而完全丢失纹理细节,甚至出现彩色条纹。
传统方法在应对这种非均匀退化时显得力不从心:
- 物理建模派:尝试用点扩散函数(PSF)精确描述退化过程。但面对复杂多变的真实屏幕结构和光照条件,构建精确的通用模型非常困难。
- 频率分离派:将图像分解为低频(轮廓、色彩)和高频(边缘、纹理)分量分别处理。但这种方法在重组时,往往难以将高频细节精准地“贴合”回正确位置,导致纹理生硬或产生伪影。
问题的症结在于,现有方法缺乏对“修复难度”的动态感知能力。如果模型能识别出哪些区域因退化严重而“难以恢复”,并针对性地施以不同的修复策略,效果将有望大幅提升。UCMNet正是基于这一洞察而设计。
核心机制一:不确定性驱动——让网络学会评估“修复难度”
UCMNet的第一个关键创新是引入了“不确定性”(Uncertainty)估计。在图像恢复任务中,不确定性可以理解为模型对每个像素点预测值的置信度。对于被严重模糊或噪声覆盖的区域,模型“心里没底”,其不确定性就高;反之,对于退化较轻的区域,不确定性则低。
网络通过一种改进的不确定性驱动损失(Uncertainty-Driven Loss, UDL) 来学习生成这种“修复难度地图”。在训练时,网络不仅输出修复图像 $\hat{I}$,还输出一个不确定性值 $s$。损失函数会根据 $s$ 自动调整权重:对于高不确定性(难恢复)区域,损失的惩罚相对减轻;对于低不确定性区域,则正常惩罚。这使得模型不会被“不可能完成的任务”带偏,能够更均衡地学习。
传统的UDL损失函数形式如下:
$L_{UDL} = exp(-s) \lVert \hat{I} - I_{gt} \rVert _1 + 2s$
其中,$I_{gt}$ 是真实清晰图像。第一项是加权的L1损失,$exp(-s)$ 使得不确定性越高的区域权重越低;第二项是为了防止 $s$ 变得无穷大而加入的正则项。
最终,网络能够生成一张“不确定性图”,直观地标出图像中难以恢复的区域。
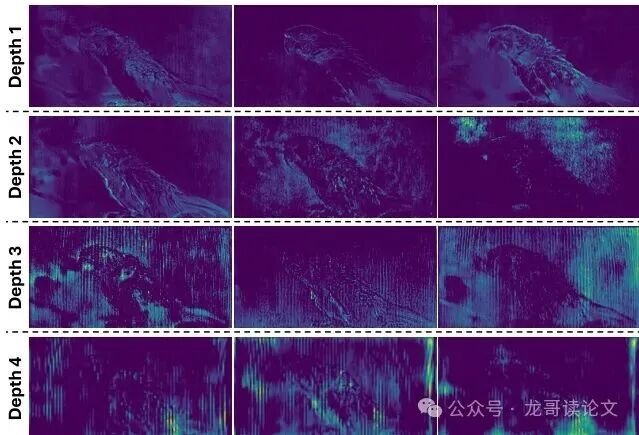
图:解码器各阶段不确定性图的可视化。早期阶段关注精细结构(如文字边缘),后期阶段则响应更粗糙的整体退化模式。
核心机制二:高频不确定性损失——精准锁定细节恢复目标
仅凭基于像素误差的不确定性感知还不够。UDC图像丢失的关键信息恰恰是人类视觉最敏感的高频细节(如边缘、纹理)。传统的UDL损失对恢复整体颜色和轮廓有效,但对“找回”这些高频细节不够敏感。
为此,UCMNet提出了第二个创新点:高频不确定性驱动损失(HF-UDL)。其巧妙之处在于,它并非直接比较修复图与原图的像素差异,而是先用拉普拉斯算子($\Delta$)提取两者的高频成分(即边缘信息),再比较这些高频成分的差异。
$L_{HF-UDL} = exp(-s) \lVert \Delta(\hat{I}) - \Delta(I_{gt}) \rVert _1 + 2s$
这样做的好处是直击要害。模型学习到的不确定性,会精准地反映“高频细节恢复的难度”。哪里的边缘模糊、纹理丢失严重,哪里的不确定性就高。这为后续的针对性修复提供了极其精准的“导航图”。

图:损失函数消融研究的可视化。(a)仅用PSNR损失,(b)用PSNR+传统UDL损失,(c)用PSNR+本文提出的HF-UDL损失。可见(c)的修复结果在细节上最接近真实图像(Ground Truth)。
知道了“哪里难修”,接下来就是“怎么修”。UCMNet最精彩的部分——不确定性先验Transformer(UPT) 模块登场,它充当了整个网络的“智能修复引擎”。
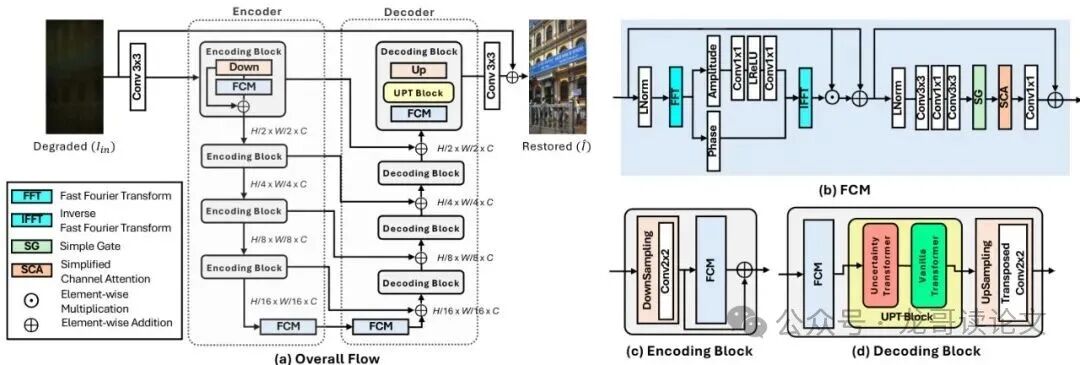
图:UCMNet方法架构。模型采用U形编码器-解码器设计。编码块的核心是频率卷积模块(FCM),解码块则引入了用于特征细化的不确定性先验Transformer(UPT)块。
记忆库与上下文库:“症状库”与“药材库”
UPT模块内部维护了两个可学习的记忆库:
- 记忆库(Memory Bank) $M$:相当于一个“症状库”,存储了 $N$ 种学习到的不确定性模式(例如,“中心轻微模糊”、“边缘严重衍射”等)。
$M = [m_1, m_2, ..., m_N]$
- 上下文库(Context Bank) $C$:相当于一个“药材库”,与 $M$ 一一对应,存储了针对上述各种“症状”的“修复配方”,即高频上下文特征。
$C = [c_1, c_2, ..., c_N]$
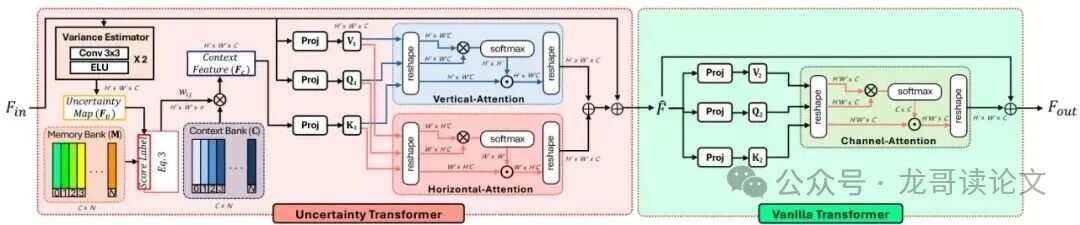
图:不确定性先验Transformer(UPT)块的架构。其通过预测不确定性图,并从记忆-上下文库中检索特征,通过垂直-水平交叉注意力产生细化后的特征。
智能检索与修复流程
当图像特征 $F_{in}$ 进入UPT模块时,会经历以下智能“诊断-抓药-用药”过程:
- 诊断:根据当前特征,预测其不确定性特征向量 $f^u$。
- 匹配与抓药:计算 $f^u$ 与记忆库 $M$ 中每个条目 $m_i$ 的余弦相似度 $s_{ij}$,并据此从上下文库 $C$ 中加权检索出定制化的高频上下文特征 $f^c$。
$s_{ij} = \frac{m_i (f_j^u)^T}{ \lVert m_i \rVert \cdot \lVert f_j^u \rVert }$
- 用药:通过垂直-水平交叉注意力机制,将检索到的上下文特征 $F_C$ 作为先验知识,与原始输入特征 $F_{in}$ 进行融合。该机制分别沿垂直和水平方向计算注意力,使网络能沿着空间结构方向更好地重建细节。
$\hat{F} = 0.5 \times (F_v + F_h) + F_{in}$
其中 $F_v$ 和 $F_h$ 分别是垂直和水平注意力的输出。最后,再经过一个标准的Transformer模块进行通道层面的特征整合,输出最终细化后的特征 $F_{out}$。
整个过程就像一个经验丰富的修图师,不仅能定位受损区域,还能从一个庞大的“细节素材库”中找到最匹配的补丁,并沿着纹理方向精准修复。
实验结果:效果与效率的双重突破
论文在三个主流UDC数据集上进行了全面评估:透光率低、色偏严重的POLED数据集;透光率高、模糊严重的TOLED数据集;以及使用PSF合成的SYNTH数据集。评估指标包括PSNR、SSIM(衡量像素相似度)以及LPIPS、DISTS(衡量感知质量)。
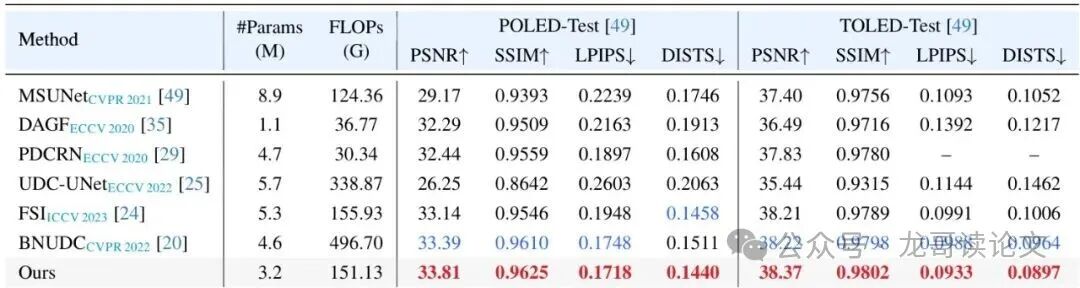
表:POLED和TOLED测试集上的定量结果对比。UCMNet(Ours)在绝大多数指标上领先,且参数量(#Params)和计算量(FLOPs)更低。
定量结果显示,UCMNet在几乎所有数据集和指标上都达到了最先进的性能,同时模型非常轻量(仅3.2M参数)。视觉对比更是清晰地展现了其优势:

图:POLED数据集上的定性比较。UCMNet清晰恢复了屋顶边缘和文字笔画,而其他方法存在模糊或条纹伪影。

图:TOLED数据集上的定性比较。UCMNet在墙壁图案和窗户结构分离上细节保存最好。
总结与展望
UCMNet通过引入不确定性感知和自适应记忆检索机制,为应对屏下摄像头图像的空间变异退化问题提供了一种新颖而有效的范式。它不仅显著提升了修复质量,还保持了模型的轻量化,有利于移动端部署。
当然,方法也存在局限,例如对于信息已完全丢失的极端过曝区域,恢复能力仍然有限。展望未来,UCMNet的“不确定性引导记忆检索”思路具有很强的启发性,可扩展至其他存在空间变化退化的计算机视觉任务,例如透过毛玻璃、雨雾或湍流介质的图像恢复。如何与扩散模型等新兴范式结合,以及如何构建更高效紧凑的记忆系统,都是值得探索的方向。
对于开发者社区而言,理解这类前沿的深度学习模型设计思想,有助于开拓解决实际工程问题的思路。我们可以在云栈社区关注和讨论更多类似的硬核技术解析与落地实践。
 发表于 2026-4-5 07:48:22
|
查看: 199|
回复: 0
发表于 2026-4-5 07:48:22
|
查看: 199|
回复: 0
