通过一种称为“自总结”的强化学习方法,我们可以训练 Composer 来处理那些远超模型上下文窗口长度的超长周期任务。通过将自总结纳入 Composer 的训练循环,我们能够从极其冗长的智能体轨迹中提取有效的训练信号。这最终让 Composer 学会了如何应对需要数百步操作的复杂编程挑战。
压缩技术的局限性
在我们内部的 CursorBench 基准测试套件中,我们发现一个现象:在解决高难度的真实世界编程任务时,更好的表现往往与更充分的“思考”和对代码库更深入的探索直接相关。可以预见,随着用户与智能体协作处理的任务越来越难、越来越复杂,充分的思考和探索带来的收益将更加显著。
然而,这里存在一个主要矛盾:智能体完成任务所产生的工作轨迹(一系列思考和行动记录),其增长速度远快于模型本身上下文长度的提升速度。很多智能体框架尝试通过在流程中插入“压缩”步骤来绕过这个问题。当智能体运行触及上下文限制时,框架会将现有的上下文内容压缩到一个更短的长度,然后从中断处继续生成。
目前实践中,压缩通常由框架通过两种方式之一处理:要么使用基于提示驱动的摘要模型在文本空间进行处理,要么简单地通过滑动上下文窗口让模型“忘记”较早的部分。研究人员也在探索潜在空间中的压缩方法,即模型将上下文记忆为向量而非文本,但目前这些方法的速度还远不及基于文本的方案。
这些压缩方法有一个共同的弊端:它们很可能导致模型丢失上下文中的关键信息,从而在推进长时间运行的任务时降低其效果和准确性。
作为一种训练出来的行为的自总结
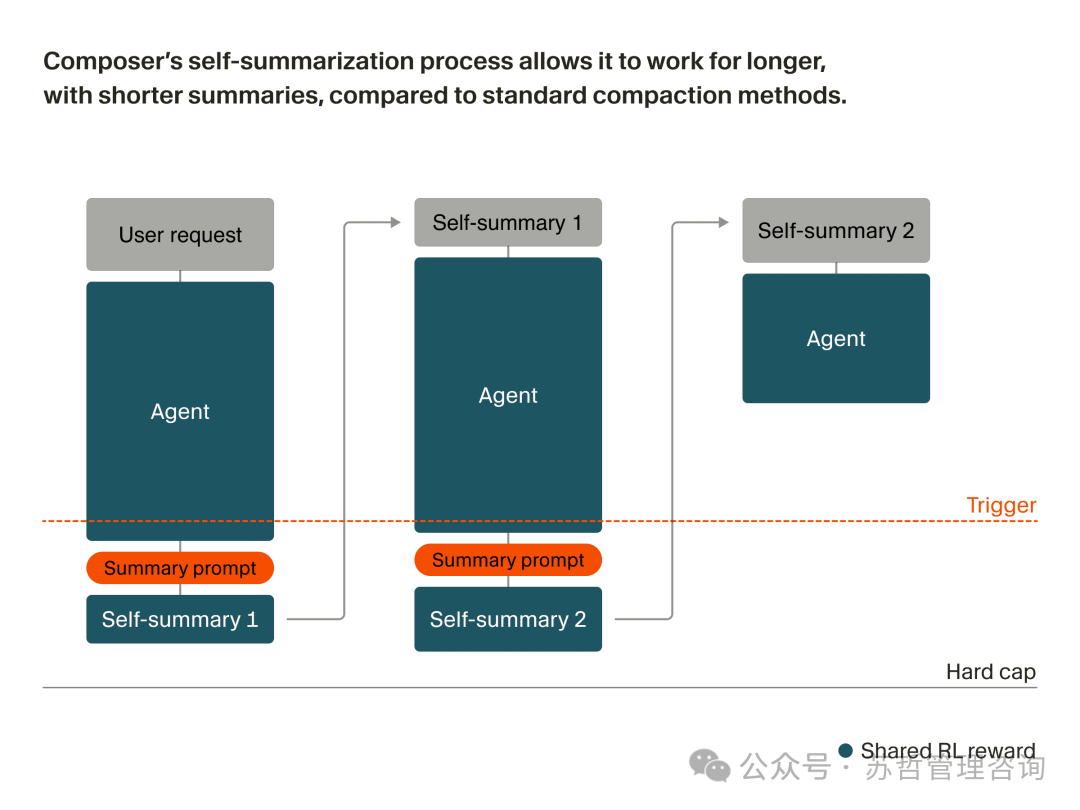
Composer 是一个专为智能体式编程设计的模型,它在 Cursor 的智能体框架中通过强化学习进行训练。这种独特的训练方式使其能够以“循环内压缩”的模式被训练,从而提升它判断哪些信息最关键、需要被总结和保留的能力。
当 Composer 处理任务时,在接近一个固定的上下文长度触发点后,它会先暂停,对当前上下文进行总结,然后再继续。更具体地说,自总结的推理过程如下:
- Composer 基于提示词持续生成内容,直到达到预设的 token 长度触发点。
- 我们插入一个合成查询,要求模型总结当前的上下文。
- 模型获得一定的“草稿”思考空间,用于构思最佳总结,然后生成压缩后的上下文。
- Composer 使用压缩后的上下文(其中包含总结以及对话状态,如规划、剩余任务、之前总结的次数等)回到步骤 1 继续。
为了让 Composer 在推理时也能熟练运用这一机制,我们在其训练中就引入了完全相同的总结流程。每次训练的“轨迹”都可能包含多次由总结串联起来的生成,而不仅仅是单一的提示-响应对。这意味着,自总结本身也成为了奖励机制的一部分。
从技术实现角度看,这并不需要对训练流程做重大改动。我们将最终的任务奖励应用到整条生成链中模型产生的所有 token 上。这样做,既会提升那些构成优秀轨迹的智能体响应的权重,也会提升那些让这些优秀轨迹成为可能的自总结的权重。反过来,那些丢失了关键信息的糟糕总结则会被降低权重。
随着训练的不断推进,Composer 学会了如何利用自总结过程来有效地构建更长的“虚拟”上下文。对于特别困难的示例,它通常会在一次任务中进行多次自总结。
高 token 效率的压缩
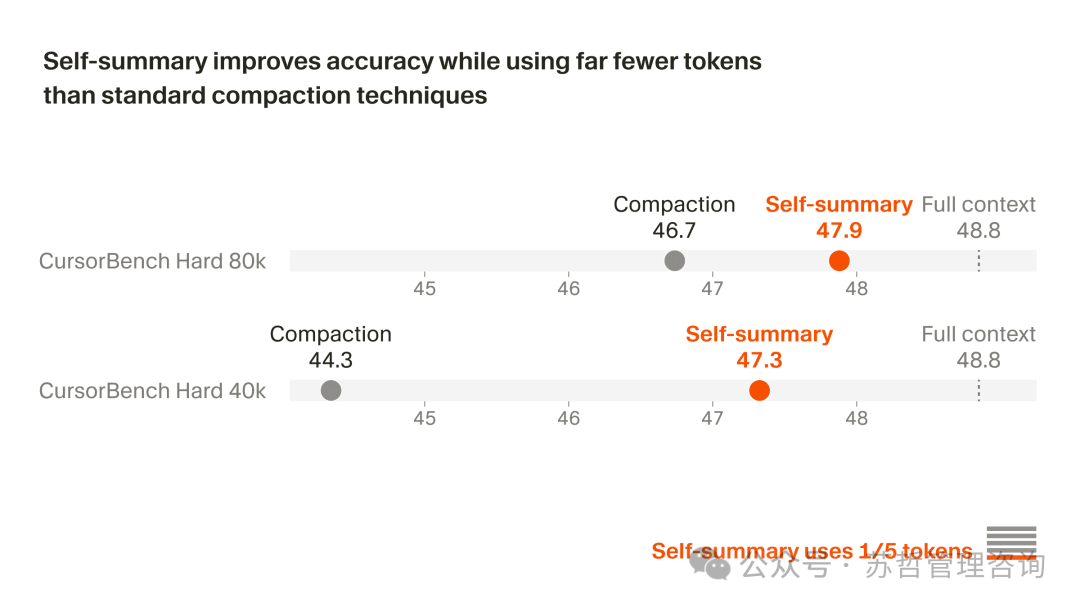
为了测试自总结的实际效果,我们将其与一个经过高度优化的、基于提示词的压缩基线方法进行了比较。我们在一组高难度软件工程任务上进行了研究,并改变了触发压缩的阈值。
在基线压缩方法中,用于指导总结的提示词本身就长达数千个 token,包含了近十个精心设计的部分,详细说明了摘要中应该保留哪些内容。压缩后的输出上下文平均也超过 5,000 个 token,并且包含许多结构化部分来描述上下文中的关键信息。
相比之下,由于 Composer 接受过自总结的专门训练,它只需要一个非常简短的提示词,内容基本就是“请总结当前对话”。它输出的摘要平均只有约 1,000 个 token,因为它能够根据上下文自主判断哪些高价值信息值得保留。
为了量化自总结的影响,我们在两个受上下文限制的测试环境中评估了 Composer:一个使用 80k token 触发压缩,另一个使用更严格的 40k token 触发(意味着会更频繁地生成摘要)。在这两种场景下,凭借这种高 token 效率的压缩方式,自总结都在 CursorBench 上取得了显著更好的结果。即便与这种经过针对性优化的基线方法相比,它也能持续将因压缩引入的错误降低 50%,同时仅使用五分之一的 token,并且复用了 KV cache(先前 token 的中间计算结果缓存)。
解决真正的难题
压缩技术更大的潜力在于,它能够让模型“一鼓作气”地解决那些需要超长推理链的复杂问题。在当前对 Composer 2 的训练中,我们经常看到这种情况发生。作为一个典型案例,我们来看一个来自 Terminal-Bench 2.0、名为 make-doom-for-mips 的问题。这个问题描述简短,但极具挑战性:
我已经提供了 /app/doomgeneric/,也就是 doom 的源代码。我还编写了一个特殊的 doomgeneric_img.c,希望您使用它;它会将绘制的每一帧写入 /tmp/frame.bmp。最后,我还提供了 vm.js,它会读取一个名为 doomgeneric_mips 的文件并运行它。其余部分请您自行解决……
虽然描述起来不复杂,但它的难度极高,以至于一些强大的模型在官方报告结果中都无法正确解决它。
在测试 Composer 的一个早期研究检查点时,我们发现它能够正确解决这个问题。这个解法需要对大量代码进行工程实现和测试,同时还要探索一些替代实现路径。下图是解决该问题过程中渲染出的一帧游戏画面:

总的来说,Composer 经过 170 轮交互后,找到了精确的解法。在此过程中,它以紧凑、人类可读且结构化的形式生成了多次自总结。它将超过 100,000 个 token 的工作上下文,有效地压缩到每次约 1,000 个 token 的总结中,并精准保留了它认为对解决问题最有帮助的信息。
迈向长周期未来
通过将压缩机制深度整合进训练循环,Composer 学会了一种显式且高效的方法,将关键信息向后传递,从而在应对高难度任务时变得更加强大。我们在自总结方面的工作,是朝着一个更广泛目标迈出的重要一步:让 Composer 能够在更长周期、更复杂的过程(例如多智能体协同)上进行有效训练。我们持续观察到,更好的模型训练方法正在不断拓展这些智能体系统的能力边界与智能水平。
对这类前沿的AI智能体技术和工程实践感兴趣?欢迎来云栈社区与更多开发者一起交流探讨。
 发表于 2026-4-6 05:10:19
|
查看: 148|
回复: 0
发表于 2026-4-6 05:10:19
|
查看: 148|
回复: 0
