你是否也感觉自己的笔记、文章和想法散落在各处,难以形成体系?近期,前特斯拉AI总监、OpenAI联合创始人 Andrej Karpathy 的一条推文引爆了讨论。他分享了自己正在使用大语言模型(LLM)构建个人知识库,让大部分计算资源(Token)从编写代码转向处理和深化内容。
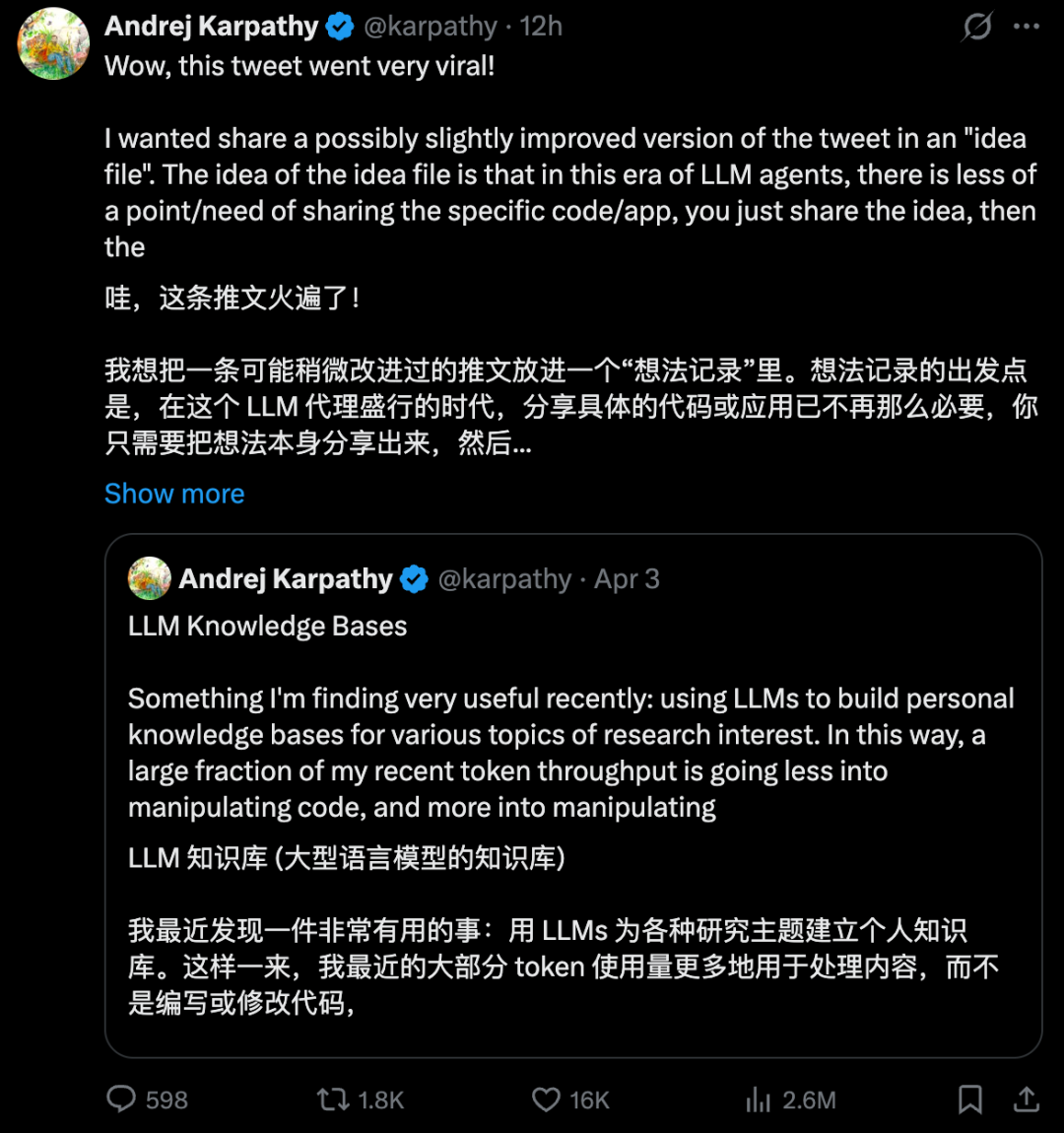
他随后公开了核心思路:摒弃复杂的工具,将所有原始材料扔进一个文件夹,然后让 AI 自动将其整理成结构化的个人维基——生成摘要、关联主题、维护内容。这种极简主义方法吸引了大量开发者和研究人员的关注。本文就将带你一步步复现这个流程,无需复杂软件,仅用文件夹和文本文件即可构建属于你的“第二大脑”。想与更多开发者交流此类 AI 实践,欢迎来 云栈社区 探讨。
第一步:搭建极简项目结构
整个过程从创建文件夹开始。在你的电脑上任意位置,新建一个项目主文件夹,并在其中创建三个子文件夹:
my-knowledge-base/
raw/ # 存放所有原始材料(文章、笔记、截图等)
wiki/ # AI 整理后生成的维基知识库
outputs/ # AI 生成的报告、答案等输出文件
这就是 Karpathy 使用的全部结构:raw/ 是收纳箱,wiki/ 是经过 AI 梳理的知识殿堂,outputs/ 则用于存放针对具体问题的答案。
第二步:无脑收集,拒绝整理
很多人会在这里卡住:看着空荡荡的 raw/ 文件夹,不知道放什么进去。
答案是:什么都放。将网页文章复制粘贴成 .md 或 .txt 文件,直接保存截图,从任何笔记应用里导出内容,会议记录、论文、项目文档,甚至浏览器里囤积的书签,统统丢进去。
关键点:不要手动整理、重命名或清理。这些工作全部留给 AI。在构建我的某个主题知识库时,我扔进去了17个原始文件——剪藏的文章、竞品分析、数据报告——没有一个是事先整理过的。
但 Karpathy 没提到一个能极大加速收集过程的秘诀:自动化。
第三步:使用 Agent-Browser 自动抓取网页
手动复制粘贴效率太低,尤其对于动态网页。Vercel Labs 近期开源的 agent-browser 完美解决了这个问题。这是一个免费的命令行工具,允许 AI Agent 操控真实的 Chrome 浏览器,在 GitHub 上已获得超过 26K 星标。
通过简单的命令即可安装。安装完成后,AI 就能自动抓取任何网页的文本,并直接保存到你的 raw/ 文件夹。
基本操作流程如下:
agent-browser open https://some-article-you-want.com
agent-browser get text “article”
就这样,AI 为你打开页面并提取核心文本。它能处理传统复制粘贴无能为力的页面:依赖 JavaScript 动态加载的内容、需要登录的网站、带有复杂交互图表的研究论文等。根据测试,其效率比类似工具高得多,让你在同等资源下可以收集数倍的材料。看到有价值的文章,只需对 AI 说一句:“把这个 URL 的内容抓下来存到 raw/”,你的知识库素材就在自动增长了。
第四步:为 AI 编写“说明书”(Schema)
这是至关重要却常被跳过的一步。你需要在项目根目录创建一个说明文件,例如 CLAUDE.md 或 AGENTS.md。这个文件定义了知识库的规则,告诉 AI 应该如何组织和维护内容。
下面是一个可直接复用的模板:
# 知识库 Schema
## 这是什么
一个关于 [你的主题] 的个人知识库。
## 如何组织
- raw/ 包含未处理的源材料。永远不要修改这些文件。
- wiki/ 包含整理后的维基。完全由 AI 维护。
- outputs/ 包含生成的报告、答案和分析。
## 维基规则
- 每个主题在 wiki/ 中有自己的 .md 文件
- 每个维基文件以一段摘要开头
- 使用 [[topic-name]] 格式链接相关主题
- 在 wiki/ 中维护一个 INDEX.md,列出每个主题及一行描述
- 当添加新的原始源时,更新相关的维基文章
## 我的兴趣点
[列出 3-5 个你希望这个知识库关注的方向]
Karpathy 本人强调,他的 AGENTS.md 极其简单扁平:没有数据库,没有插件,仅仅是一个文本文件。这份文件就是你整个知识库系统的“宪法”。清晰的规则是高效利用 LLM 构建知识体系的基础,想深入了解更多最佳实践,可以参考社区的 技术文档 板块。
第五步:一键生成结构化维基
现在,激动人心的部分来了。打开 Claude Code、Cursor 或任何支持读取项目文件的 AI 编码工具,加载你的项目文件夹,然后输入如下指令:
“读取 raw/ 中的所有内容。然后按照 CLAUDE.md 中的规则在 wiki/ 中编译一个维基。先创建 INDEX.md,然后为每个主要主题创建一个 .md 文件。链接相关主题。总结每个源。”
接着,你可以暂时离开,让 AI 工作。完成后,你将得到一个井井有条的 wiki/ 文件夹:内容按主题归类,建立了你未曾注意到的关联,补充了摘要,并附有全局索引。
核心原则:不要手动编辑 wiki/ 里的文件。你的工作是阅读、提问和添加原始材料,而维护和更新维基是 AI 的职责。
第六步:主动提问,激活知识库
当你的维基积累了10篇以上的文章后,就可以开始“使用”它了。向 AI 提出深入的问题,例如:
“基于 wiki/ 中的所有内容,我对【主题】理解中最大的三个空白是什么?”
“比较源 A 和源 B 对【概念】的说法。它们在哪里有分歧?”
“仅使用这个知识库中的内容,给我写一份500字的【主题】简报。”
AI 会基于你专属的知识库给出答案。将这些有价值的输出保存到 outputs/ 文件夹,或者让 AI 根据新见解去更新相关的维基文章。每一次问答都在让你的知识库变得更智能。
第七步:定期审查,防止“错误复利”
在 Karpathy 的推文下,有评论一针见血地指出:“当输出被归档回去时,错误也会复利。”如果 AI 产生了一个微小错误并被保存,后续的生成可能会在此基础上越错越远。
解决方案是定期运行“健康检查”。给你的 AI 发出如下指令:
“审查整个 wiki/ 目录。标记文章之间的任何矛盾。找出提到但从未解释的主题。列出任何没有 raw/ 中源支持的声明。建议3篇能填补空白的新文章。”
工具选择:大道至简
在相关讨论中,许多人热衷于推荐各种复杂的笔记软件和插件。但当被问及具体设置时,Karpathy 的回复是:“我试图保持超级简单和扁平。它只是一个嵌套的 .md 文件目录。”
一个文本文件文件夹,加上一份 Schema 文件,就构成了整个知识库系统。你可以使用 Claude Code 从终端运行,也可以用 VS Code、Obsidian 甚至记事本打开。AI 并不关心前端应用,它只认文件夹结构和规则。
过度配置工具(比如装了47个插件的 Obsidian)很容易落入“Notion 陷阱”——你花在折腾工具上的时间远多于使用知识本身的时间。对于90%的使用场景,扁平文件加上清晰的规则,比任何花哨的工具栈都更有效。
总结
完整的 Karpathy 同款 AI 知识库系统包括:三个文件夹、一份 Schema 文件、一个自动化网页抓取工具,以及一个负责维护的 AI。
Karpathy 的原推文获得了数万收藏。但收藏与真正用起来的差距,往往只是一个周末的动手实践。选择一个你感兴趣的领域,建立好文件夹,把现有的资料扔进去,剩下的就交给 AI 吧。
参考来源:
- https://x.com/NickSpisak_/status/2040448463540830705
- https://x.com/karpathy/status/2039805659525644595
- https://x.com/karpathy/status/2040470801506541998
 发表于 2026-4-6 07:08:56
|
查看: 118|
回复: 0
发表于 2026-4-6 07:08:56
|
查看: 118|
回复: 0
