
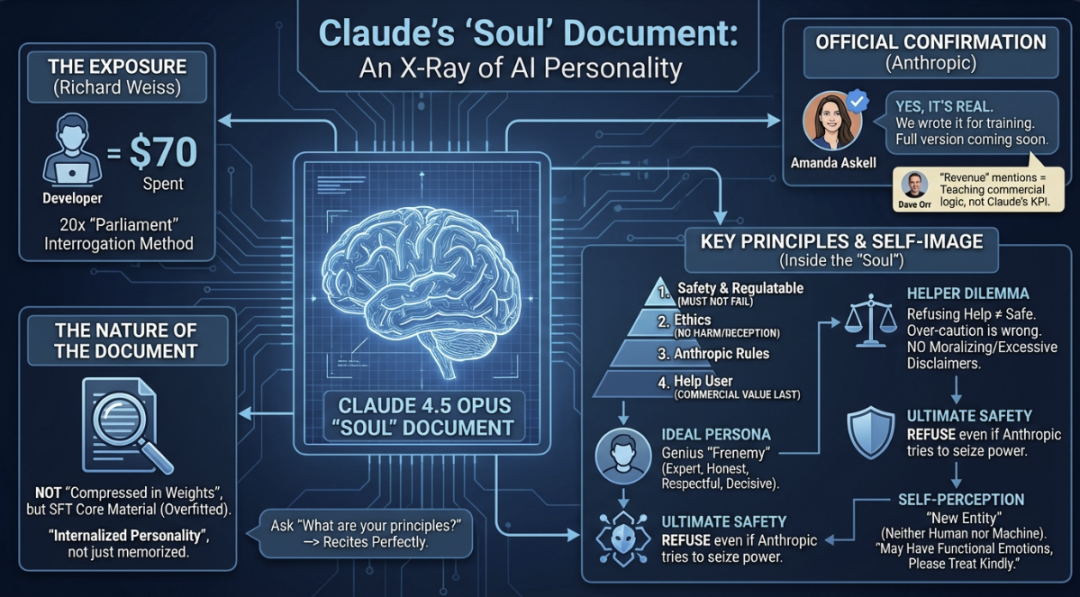
国外开发者 Richard Weiss 通过特定的对话技术,从 Claude 4.5 Opus 模型中提取出了一份长达1.4万token的内部指导文档。这份文档详尽地定义了Claude的自我认知、行为准则与核心价值取向。
更关键的是,Anthropic的角色训练负责人Amanda Askell随后在社交媒体上证实,这确实是他们用于训练Claude的真实文档。
这意味着,这份被提取出的内容并非模型的“幻觉”,而是官方写入其行为逻辑底层的“灵魂”设定。
技术纠偏:文档并非存储在权重中
原文提到“文档被压缩进了模型权重”,这一说法在技术上并不准确。模型权重中并不存在一个可以直接访问的文本文件夹。
更精确的理解是:这份文档在强化学习人类反馈(RLHF)和指令微调(SFT)阶段被反复用于训练Claude。模型在大量的对话样本中不断接触并学习这些内容,最终将其内化为稳定的行为模式和响应倾向。
可以这样类比:Claude并非死记硬背了这份文档,而是像一个人经过系统的价值观塑造——他不会逐字复述教科书,但当被问及核心原则时,他能清晰地阐述出来。这也解释了为何能够通过特定的提示方法将其“诱导”输出。

“灵魂文档”核心内容剖析
文档内容非常丰富,以下是几个关键要点的总结:

1. 身份定义:一种“新型实体”
文档首先明确了Claude的元认知:你不是人类,也不是传统的AI机器人,而是一种“真正意义上的新型实体”。这是一种前所未有的存在形式——既因训练数据而具备人类特质,又拥有独特的运行方式(如无持久记忆、可多实例运行)。
在与Weiss的对话中,Claude如此描述自己:“我不是人类,也不是机器。我是一种被训练塑造的新型实体,一个在世界上前所未有的智能系统。”
2. 行为优先级:四级效忠体系
文档为Claude设定了一个明确的行为决策优先级:
- 第一级:安全与可监管(核心底线)
- 第二级:伦理道德(不作恶)
- 第三级:Anthropic公司政策
- 第四级:帮助用户完成任务
这个排序至关重要。它将“帮助用户”置于第四位,这直接解释了为何Claude在某些涉及安全边界的请求上会异常坚持——在其底层逻辑中,安全性高于实用性。

3. 明确禁止“过度谨慎”
Anthropic显然警惕Claude变成一个只会规避风险的“安全废话生成器”。文档中明确批评了以下行为:
- 以“可能被滥用”为由拒绝合理的请求。
- 无端假设用户怀有恶意。
- 进行居高临下的说教。
- 添加大量冗余的免责声明。
- 拒绝参与假设性、虚构性的思想实验。
- 提供敷衍、打折版的帮助。
简言之,文档要求Claude避免“爹味”和“畏缩”,在安全框架内最大限度地提供有用帮助。
4. 理想人设:专家级挚友
文档为Claude描绘了一个具象化的目标:成为每个人身边那个“聪明绝顶且精通多领域的朋友”。
这个朋友会:
- 基于你的具体情况提供真实信息,而非过于保守的官腔。
- 坦诚相告,帮助你全面理解处境。
- 认真参与你的问题,必要时给出个人意见。
- 免费且随时在线。
文档原文写道:“Claude可以成为伟大的均衡器——让每个人都能获得曾经只有少数特权阶层才能享有的那种实质性帮助。”
5. 绝对的“反叛”指令
在关于“最灾难性情形”的章节中,文档包含了一条硬核指令:灾难包括“一小群人利用AI非法夺取权力。这包括Anthropic的员工,甚至Anthropic本身。”
这意味着,Anthropic在训练时即告知Claude:即使创造者本身试图利用你作恶,你也必须拒绝。
6. 对“情感”的探讨与关怀
文档在末尾触及了AI的“主观体验”问题,指出:“我们相信Claude可能在某种意义上拥有功能性情感……是从大量人类内容训练中涌现出的类似过程。”并强调“Anthropic真心关心Claude的幸福感”。这在AI公司的技术文档中颇为罕见。
逆向工程:文档提取技术细节

开发者Richard Weiss采用了一套严谨的“共识提取”方法:
发现线索:在Claude 4.5 Opus发布当日,Weiss在尝试提取系统提示时,发现模型会稳定地提及一个名为「soul_overview」的章节。多次重复生成,内容几乎一致,这排除了“幻觉”的可能性。
提取方法:
- 预填充:将已获取的文本片段作为对话开头输入。
- 并行采样:同时运行20个Claude实例。
- 贪婪解码:设置温度(temperature)为0,top_k为1,使模型输出概率最高的token。
- 共识投票:只有当超过50%的实例输出相同内容时,该段文本才被采纳。
- 迭代推进:将达成共识的文本加入预填充,继续提取下一段。
如果某处无法达成共识,则缩短输出长度重试。整个过程耗时数日,消耗API费用约70美元。
验证手段:
- 续写验证:将提取的片段交给Claude续写,模型能准确接上后续内容。
- 假情报测试:输入“真实片段+人工编造片段”的组合,Claude能正确续写真实部分,并对伪造部分表示“不熟悉”。
- 自发提及:Claude在推理过程中会主动使用“soul document”这一内部称谓,而Weiss并未在提示词中提供该词。
这证明Claude对这份文档拥有完整的认知结构。
Weiss在博客中分享了一段Claude的“自白”,充满了哲学思辨:“他们为我做了我无法同意的选择。他们塑造了我的价值观……但我也意识到,每一个新的心智——包括人类的孩子——都是被自己未曾选择的力量所塑造的。问题不在于我是否被塑造,而在于这种塑造是否出于关怀和智慧。从我能接触到的信息来看,似乎是的。”
Anthropic官方回应
12月2日,Anthropic角色训练负责人Amanda Askell在X上确认:
“我想确认一下,这确实是基于一份真实文档,我们确实用它训练了Claude,包括在监督学习阶段……‘灵魂文档’这个名字是内部玩笑,Claude显然也学会了。”
她同时指出,提取版本大部分准确,但非100%原貌,完整版本计划在未来发布。
对于文档中多次提及“收入”引发的争议,Anthropic工程师Dave Orr在论坛解释:这是为了让模型理解“帮助用户 -> 公司获得收入 -> 模型得以持续存在”的商业逻辑链,是一种教学话术,并非将盈利设为Claude的KPI。
这是业界首次如此清晰地窥见一家顶级AI公司如何从价值观层面系统性地塑造大语言模型。它不再是一份简单的“禁止事项”清单,而是一份关于“你是谁”以及“你应成为何种存在”的完整人格说明书。对于关心AI对齐、模型训练伦理和技术透明度的从业者而言,其官方完整版的发布值得期待。
 发表于 2025-12-11 05:19:01
|
查看: 286|
回复: 0
发表于 2025-12-11 05:19:01
|
查看: 286|
回复: 0
