用 ChatGPT 和用 Claude Code,是两种完全不同的体感。
前者就是聊天,后者是在聊天的基础上给用户干活。像 Claude Code 这样的 Coding Agent 打开终端,需求丢进去,它开始读文件、搜索代码、执行命令、跑测试、提 PR,一气呵成,中间出错了自己修,修完接着跑。它有工具,有记忆,能跨会话保留状态,能自主执行多步任务。
对话 AI 的核心是「理解和生成」。Coding Agent 的核心是「感知、规划、执行、反馈」。
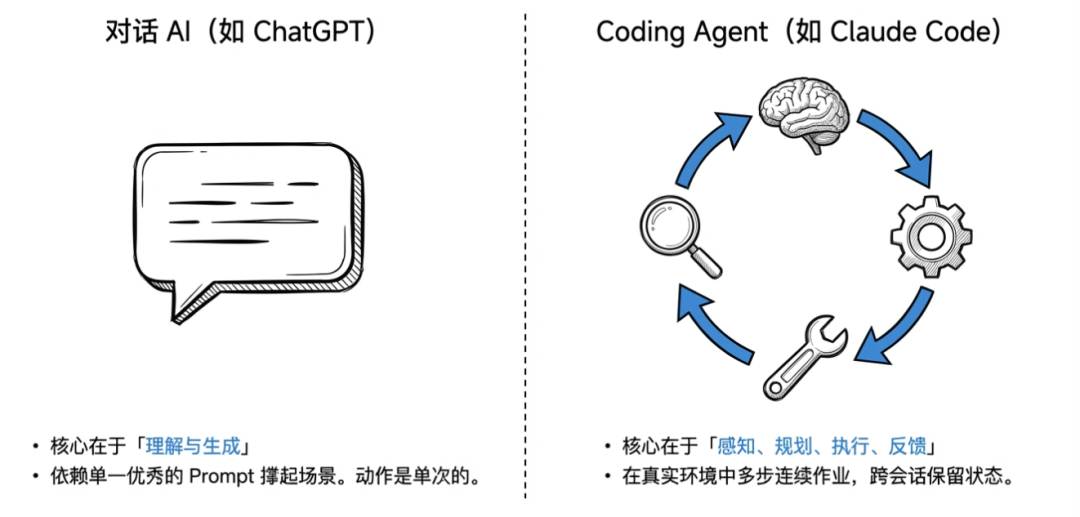
前者靠一个好 prompt 就能撑起大部分场景,后者要在真实环境里多步连续地把事情做对。Coding Agent 的代表产品:Claude Code(Anthropic)、Codex(OpenAI)、以及开源社区的 OpenClaw。它们的共同点是:都有工具调用能力,都有某种形式的记忆,都能跑相对长时间的任务。
但 Coding Agent 也有共同的痛点,跑着跑着就出问题:要么上下文撑不住,要么任务到一半崩了,要么调用错工具。
这些问题,就是 Harness 工程 要解决的。
Anthropic 刚发布了一篇新的工程实践文章,讲他们 怎么为长时运行的 Agent 设计 Harness。同时还发布了新产品 Claude Managed Agents。只要告诉 Anthropic 想要什么样的 AI 智能体,它就帮你在云端跑起来。相比于 claude code 给 C 端用户,Managed Agents 跑在 Anthropic 的云,主要给企业用。
Anthropic 认为,Agent 的基础设施将会越来越像微型操作系统(Agent OS)。 他们不承诺具体的 harness 长什么样,而是设计了一套 meta-harness:只承诺几类长期稳定的接口,具体实现随着模型能力迭代不断重写。就像 OS 从来不关心未来程序怎么写,它只提供抽象接口。
这篇文章从 Anthropic 新产品发布说起,结合其他大厂的 Harness 架构实践,我们系统性地梳理一下:什么是 Harness,大厂怎么做,我们又该如何理解和使用它。
从 Prompt 到 Harness:AI 工程化的演进
AI 工程化有一条清晰的演进线,这不是简单的替代,而是能力的层层包含与升级。
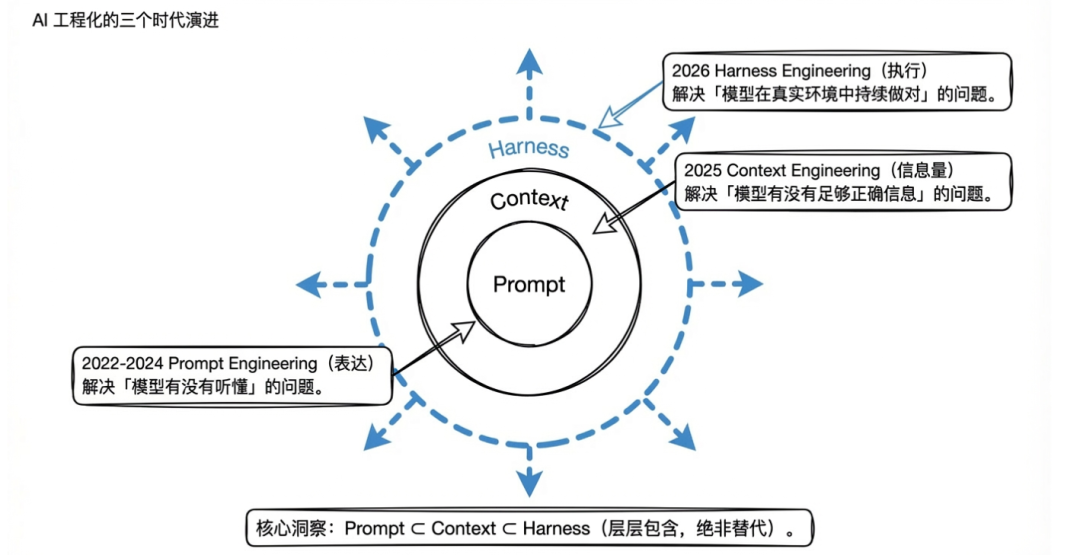
2022-2024 年:Prompt Engineering(提示词工程)
核心问题是「表达」:模型有没有听懂你在说什么?这个阶段的工作是设计一个完整的输入框架:告诉 AI 它是谁、面对什么情况、要完成什么任务、按什么格式输出。框架越完整,输出质量越可控。同一个模型,换一种说法,结果可能差很多。
2025 年:Context Engineering(上下文工程)
Andrej Karpathy 在 2025 年说:“Context Engineering 比 Prompt Engineering 更重要。这是一门精微的艺术与科学,用恰到好处的信息填充上下文窗口,以服务于下一步操作。” 核心问题变成了信息量:模型有没有拿到足够且正确的信息?
Prompt 擅长澄清任务、约束输出、激发模型已有能力。但它不擅长凭空补齐缺失知识、管理大量动态信息、处理状态变化。Context Engineering 的出现是因为这个阶段模型有了工具调用和外部系统,信息开始动态涌入:RAG 检索结果、对话历史、工具执行结果,这些都需要有人管。实际上,上下文工程 的挑战正是驱动 人工智能 Agent 进化的重要一环。
2026 年:Harness Engineering(驾驭工程)
核心问题变成了多步做对:模型在真实执行里能持续做对吗?Prompt Engineering 是表达问题,Context Engineering 是信息量问题,Harness Engineering 是执行问题。三者不是替代关系,而是层层包含:Prompt ⊂ Context ⊂ Harness。
Harness 到底是什么?
Harness 原指马具,缰绳、马鞍、马嚼子这一整套装备,用于驾驭强大的烈马,让它按照骑手意图安全前行。
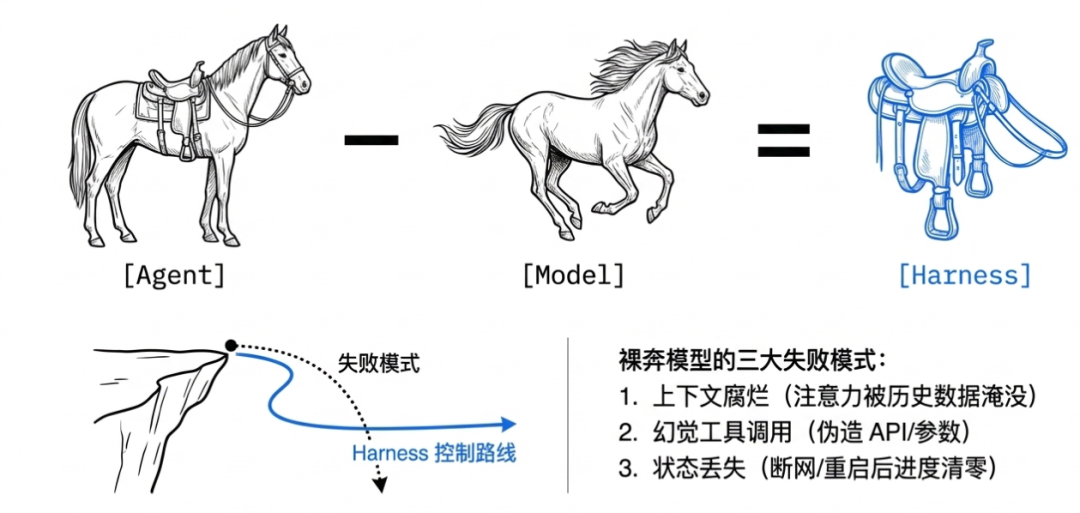
类比过来就是:
- 马 = Model,提供动力
- 骑手 = 工程师,提供方向
- 马具 = Harness,提供控制
没有 Harness 的 AI Agent,就像一匹烈马在开阔草原上奔跑,速度快、力量大,但完全不知道要去哪里,也无法完成任何实际任务。更直观的比喻:Model 是发动机,Harness 是整辆车。发动机决定马力上限,但没有方向盘、刹车、仪表盘,这辆车开不起来。
Harness 的定义可以用一个公式表达:Harness = Agent - Model
模型之外的一切,就是 Harness。模型负责做决策,Harness 负责提供执行环境。
裸模型(没有任何外部工程化)有三大弊端:
- 上下文腐烂:窗口填满工具输出和历史,模型失去对原始指令的注意力。
- 幻觉工具调用:无验证时,Agent 用错误参数调用函数,或引用不存在的 API。
- 状态丢失:网络超时或服务器重启,内存进度清零,下一会话从零开始。
Harness 是解药,通过上下文管理、验证护栏、状态持久化、失败恢复等机制,把裸模型的不可靠性转化为可生产部署的确定性系统。
Anthropic 最新实践:解耦的三权分立
Anthropic 发布的这篇文章,是目前看到的关于 Harness 架构最深度的一篇。他们早期的做法是把 harness、session、sandbox 全塞进一个容器里。结果遇到了一堆问题:harness 崩了整个会话难恢复,容器挂了状态可能丢失,调试困难,VPC 接入复杂。
然后他们做了一个根本性的架构决定:把三者彻底分离。
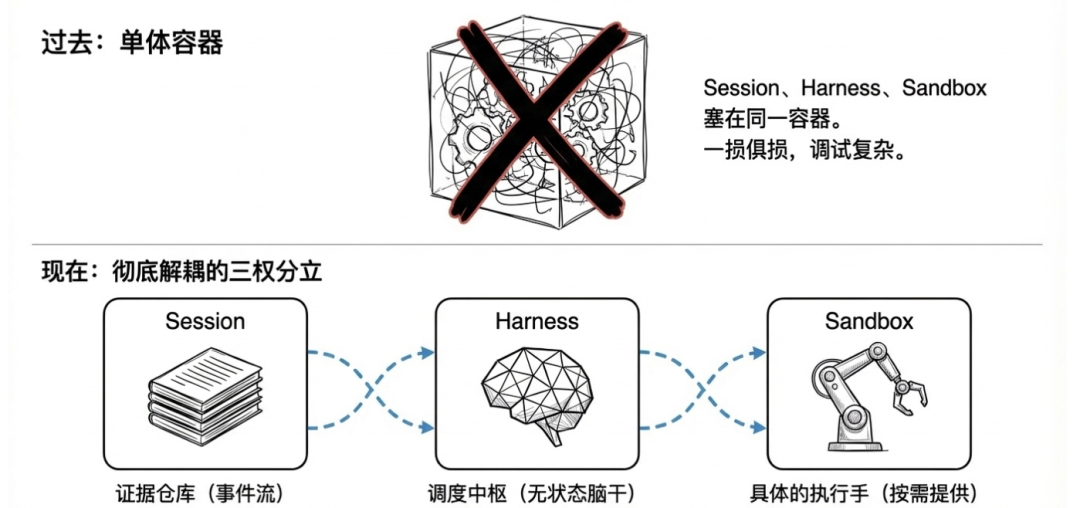
Session / Harness / Sandbox,各自独立,各司其职。
Session:不是聊天记录,是可恢复事件流
文章里有一句话:“The session is not Claude's context window.” Session 不是上下文窗口的镜像。它是一个 append-only event log,可查询、可回放、可恢复、可重组的真实执行历史。如果只把 session 当作喂给模型的 prompt,就损失了可恢复性。从系统角度看:Claude 的 context window 是执行现场,session log 是证据仓库,harness 是检索与重组器。
Harness:可替换的脑干,不拥有状态
他们把 harness 从容器里拿出来,变成一个调用工具的推理调度循环。
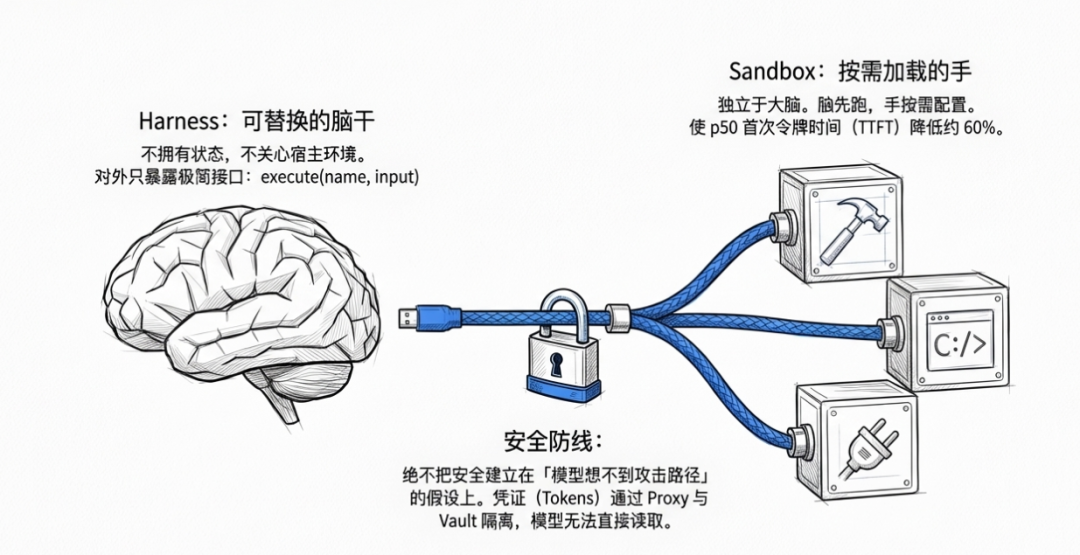
现在的 Harness 不再拥有状态,不再假设工具在哪里,对外只暴露一个接口:execute(name, input) -> string。
这样做的意思是:AI 不需要知道它在哪台设备、哪个操作系统、手机还是电脑、容器还是虚拟机,它只知道「我可以使用哪些手」。
Sandbox:某种具体的手
文章里说:将大脑与双手分离。
- Claude + harness 是 brain
- sandboxes / tools / MCP / custom infra 是 hands
一旦 sandbox 只是 hand,它们彼此独立,可以来自不同基础设施,可以共享和传递,也不需要每个 session 都加载启动完整的 sandbox。这直接带来了性能提升:先让 brain 起跑,hand 只有在需要时才 provision。p50 TTFT(首次令牌时间)降约 60%,p95 降超过 90%。原来的瓶颈并非模型推理本身,而是把整个执行环境预耦合到了请求入口。
安全架构:不把安全建立在模型能力不足上
文章里有个表述:给模型一个「范围较小的 token」,其实是在赌模型做不到某些攻击路径。而模型在持续变强,这种「它应该不会想到吧」的安全假设会越来越脆弱。
所以他们的做法是:Git token 只在初始化 clone/push/pull 过程中以受控方式接入,不让模型直接读到 token。模型通过 MCP proxy 间接调用,proxy 拿 session token 去 vault 取真实凭证再执行。不把安全建立在模型能力不足上。
文章结尾说的「Many brains, many hands」,代表的是 Anthropic 未来想做的事:Agent runtime substrate,多脑协作,多手编排,跨环境执行。Agent 的本体不绑定某个执行壳,而绑定一组可恢复状态与可调用能力。
这套架构的核心启发有三条:
- 会话是执行事实流而不是消息列表。
- 工具环境不要内化为 agent 自身。
- 上下文工程应该是可替换策略,模型一旦变强,换策略不产生技术债。
Claude Managed Agents:大厂开始接管基础设施层
理解了 Anthropic 的架构思路,再看他们发布 Claude Managed Agents 就不会觉得意外了——这个产品,就是把上面那套 meta-harness 做成了托管服务。
Anthropic 正式发布了 Claude Managed Agents。 核心是一套 API,让开发者不再需要自己搭 Harness 的基础设施部分。原来需要几个月自己搭建的东西,现在直接调用:
- 自动为每个 Agent 创建隔离容器,销毁后不留痕迹。
- Session 管理:durable event log,任务中断后从检查点继续,状态不丢失。
- 错误恢复:崩溃后自动重启,接着跑。
- 工具编排:决定哪些工具被调用,处理工具间的依赖关系。
- MCP 服务器接入:开箱支持,不需要自己处理认证和路由。
定价是 $0.08/小时,加上正常的 token 费用,空闲时间不计费。一个 20 分钟的客服任务,运行费大概 $0.027,加上 token 费用也就$0.1-0.5。Notion、Rakuten、Asana 都已经接入了。Anthropic 说,原来从零搭建一套生产级 Agent 基础设施需要几个月,现在用 Managed Agents 可以压缩到几天。
这个产品对行业的冲击,比它的功能列表看起来大得多。 Harness 层本身,也开始经历和模型层同样的事情:基础能力逐渐标准化、商品化,差异化往上移。
当年大家都自己训练模型,然后大厂开放 API,自训模型的必要性下降了。现在大家都自己搭 harness 基础设施,Managed Agents 出来了,自建 session 管理、沙箱、状态持久化的必要性也开始下降。
Harness 这一层,实际上正在被切成两层:
- 基础设施 Harness(session / sandbox / 状态 / 恢复):大厂在接管。
- 应用层 Harness(工作流设计、领域编排、上下文策略、业务约束):成为新的护城河。
真正的护城河,越来越集中在对特定领域的理解和任务流的设计质量上,而不是基础设施本身。这种架构分层与能力抽象,正是 云原生/IaaS 思想在 Agent 领域的具体体现。
大厂怎么做 Harness?惊人的共识:生成-评估-分离
Anthropic 不是唯一在认真想这件事的公司。研究了几家大厂的实践之后,发现了一个惊人的相似性:几乎所有人都收敛到了「生成-评估-分离」这个架构。
Anthropic:Planner + Generator + Evaluator
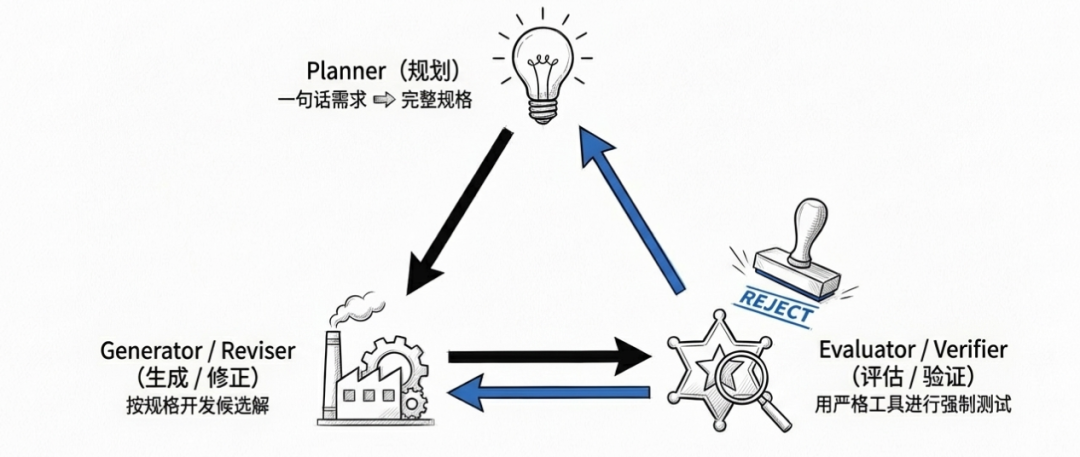
Planner 把一句话需求扩展成完整产品规格,防止系统范围过小。Generator 按规格逐功能开发,按 sprint 迭代。Evaluator 用 Playwright 做交互式验证,低于阈值打回重做。
当让模型评估自己的工作时,它会倾向于自信地表扬自己的作品,即使在人类看来质量明显平庸。工程化一个独立的严格评估器 Agent,远比教会生成器 Agent 自我批评容易得多。
他们还发现:Sonnet 4.5 时代,上下文增长到一定程度,模型会变得不稳定,就像快要下班的打工人开始疯狂敷衍。他们设计了上下文重置机制。到了 Opus 4.6,模型能力增强,这个机制直接被撤掉了。Harness 需要随模型更新和撤换。每个 Harness 组件都编码了一个假设,假设模型无法独立完成某件事。模型变强了,该撤就撤。
Google DeepMind:Generator + Reviser + Verifier
他们的 Aletheia Agent 在 IMO-Proof Bench Advanced 上达到 95.1% 准确率,远超之前记录 65.7%。同样是三角架构,Generator 提出候选解法,Verifier 检查逻辑缺陷和幻觉,Reviser 修正验证器发现的错误,循环迭代直到通过。
Manus:5 次重写,第 6 次才上线
Manus 从 2025 年就开始做 Harness,因为他们不是做模型的,一开始就意识到 Harness 才是核心。经历了 5 次架构重写。
他们学到的最重要教训:凡是希望模型「一定」做到的事,就不要靠提示词,要靠代码层面的硬约束。工具超时、输出截断、危险操作确认步骤,这些都应该是代码层面的强制规则。
以及:专业 Agent > 通用 Agent。对于特定任务,「狙击手 Agent」(专注单一任务)比通用 Agent 更可靠、更经济。
OpenAI Codex:工程师不写代码,设计环境
5 个月,团队从 3 人扩到 7 人,写了约 100 万行生成代码,合并了约 1500 个 PR,平均每个工程师每天合并 3.5 个 PR,速度是人工开发的 10 倍。
他们的核心做法是:发现问题,分析根因,设计解决方案,然后让 Codex 自我写代码来改进 Harness,形成闭环。
有一句话很值得记:「If a PR requires significant human intervention, the agent is not the problem—the Harness is.」如果 PR 需要大量人工干预,问题不在 Agent,而在 Harness。
成熟的 Harness 需要的 6 大模块
把几家大厂的实践抽象出来,一个成熟的 Harness 应该包含这 6 个模块。
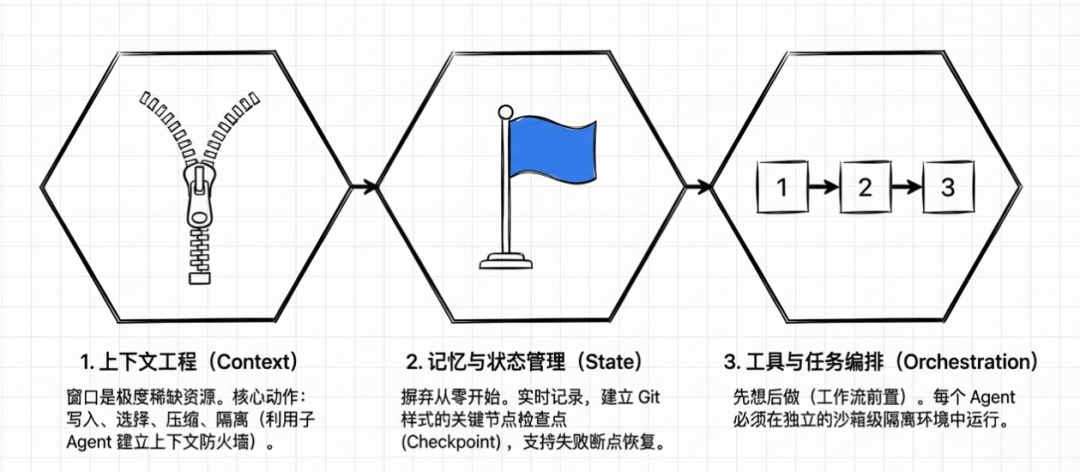
① 上下文工程
核心动作有四个:Write(写入持久状态)、Select(决定检索什么)、Compress(减少 token 体积)、Isolate(卸载到子 Agent)。
关键原则:上下文窗口是稀缺资源,需要的时候再给。不是「装不装得下」,而是「该不该装进去」。用子 Agent 作为上下文防火墙,不同子任务在隔离的上下文窗口运行。
② 记忆和状态管理
Session 生命周期的设计:开始时加载历史状态,执行中实时记录进度,关键节点创建 Git 检查点,失败后从检查点继续。
记忆和状态管理让 Agent 具备连续性,不是每次从零开始,而是基于历史持续进化。
③ 工具和任务编排
精选工具集(避免臃肿),工作流编排(行动前先想清楚步骤,成功率几乎翻倍),沙箱隔离(每个 Agent 在隔离环境中运行)。
核心原则:先想后做。让 Agent 在执行前就有清晰计划,而不是边做边想。
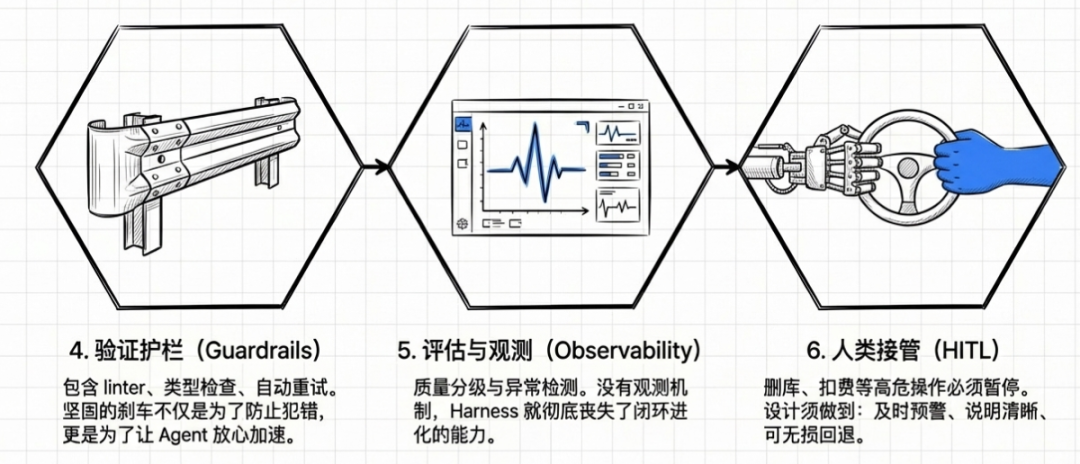
④ 验证护栏
确定性约束(自定义 linter、架构规则),校验机制(单元测试、类型检查),恢复机制(自动重试、回滚到稳定状态),评估机制(多维度评分,低于阈值打回重做)。
类比汽车刹车系统:不是为了阻止前进,而是为了让人能放心加速。
⑤ 评估和观测
执行追踪、输出验收、质量分级、异常检测、错误归因。
没有观测,就无法理解和改进。观测让 Harness 具备自我进化的能力:通过观测发现问题,通过评估量化改进,形成持续优化的闭环。
⑥ 人类接管
关键时刻把控制权交还给人类。删数据库、扣费、修改生产配置、权限变更、敏感数据访问,这些场景必须暂停等待确认。
设计原则:及时(在操作执行前暂停)、清晰(说明为什么需要接管)、可回退(拒绝后 Agent 能继续其他任务)。
总结
Anthropic 这篇文章真正代表的是一个产品哲学:他们不相信今天的 Agent Harness 会是最终形态,所以优先投资于稳定接口,而不是一次性最优实现。
这和 OS 的思路是一致的。CPU 性能提升了几百万倍,但我们依然需要操作系统。底层能力越强,上层系统越复杂,越需要精心设计的架构。
旧的 Harness 被淘汰,新的 Harness 接管更复杂的任务。Agent 系统的未来,在于一组长期稳定的系统抽象之上。现在,Anthropic 发布的新产品说明了,他们不止是在做模型,还在接管通用 harness,留给开发者的是如何在这套基础设施之上,把自己的业务逻辑和领域知识跑顺。
对于技术从业者而言,理解 Harness 工程 的核心思想,比掌握某个具体工具更重要。欢迎在 云栈社区 继续探讨 Agent 与 AI 工程化的最新实践。
参考资料
- Anthropic: Effective harnesses for long-running agents
- Anthropic: Harness design for long-running application development
- InfoQ: Anthropic Designs Three-Agent Harness
 发表于 2026-4-10 04:45:02
|
查看: 163|
回复: 0
发表于 2026-4-10 04:45:02
|
查看: 163|
回复: 0
