如果你是数据科学家或 Python 开发者,大概率用过 Jupyter 来做实验和分析。但有没有过这样的经历:改了前面的代码却忘了手动重新运行依赖它的单元格,结果得到奇怪的错误,或者在把笔记本变成脚本或 App 时感到无比麻烦?今天介绍的 marimo 或许能彻底改变你的工作流。它集笔记、脚本、应用和可视化于一身,旨在让你告别手动管理,告别混乱状态。
marimo 是什么?
简单来说,marimo 是一个响应式(reactive) 的 Python 笔记本环境。它的核心设计哲学是自动追踪代码间的依赖关系。
- 当你运行某个单元格时,marimo 会自动计算出哪些其他单元格依赖于它,然后要么自动重新运行它们,要么将其标记为“过期”,确保代码输出始终保持一致。
- 更重要的是,你的“笔记本”本质上就是一个纯
.py 文件,可以随时作为脚本运行,也支持通过命令行传递参数。
- 想要一个可交互的 Web 应用?只需执行
marimo run your_notebook.py 即可一键部署。
它内置了 SQL 查询引擎、交互式滑块(slider)、表格浏览、图表渲染,甚至集成了 AI 助手、GitHub Copilot 和 Vim 键位支持。从某种程度上说,它试图将 Jupyter、Streamlit、papermill、ipywidgets 等多个工具的功能整合到一个现代化的、AI 原生的编辑器中。
它解决了哪些实际痛点?
- 隐藏状态问题:传统 Jupyter 笔记本容易产生脏状态,单元格执行顺序混乱就会导致出错。marimo 根据变量引用关系决定执行顺序,删除单元格时会立刻清理对应的变量。
- 手动管理依赖:你不再需要自己记忆“我改了 A,还需要重新运行 B、C、D”。一旦修改,依赖它的部分会自动更新。
- 可复现性:marimo 内置包管理支持,可以在文件中序列化依赖,自动生成虚拟环境沙箱,确保他人能一键复现你的环境。
- 多形态一体:数据分析笔记、可执行脚本、交互式 Web App、演示文稿,所有这些都可以基于同一个文件切换,无需为不同场景维护多份代码。
- 内聚的数据操作:可以直接用 SQL 语法查询数据,结果自动转为 pandas DataFrame,无需额外打开数据库客户端。
快速上手与核心示例
1. 安装
pip install marimo[recommended]
2. 创建与编辑笔记本
marimo edit analysis.py
这会启动一个本地服务器并打开浏览器编辑器。
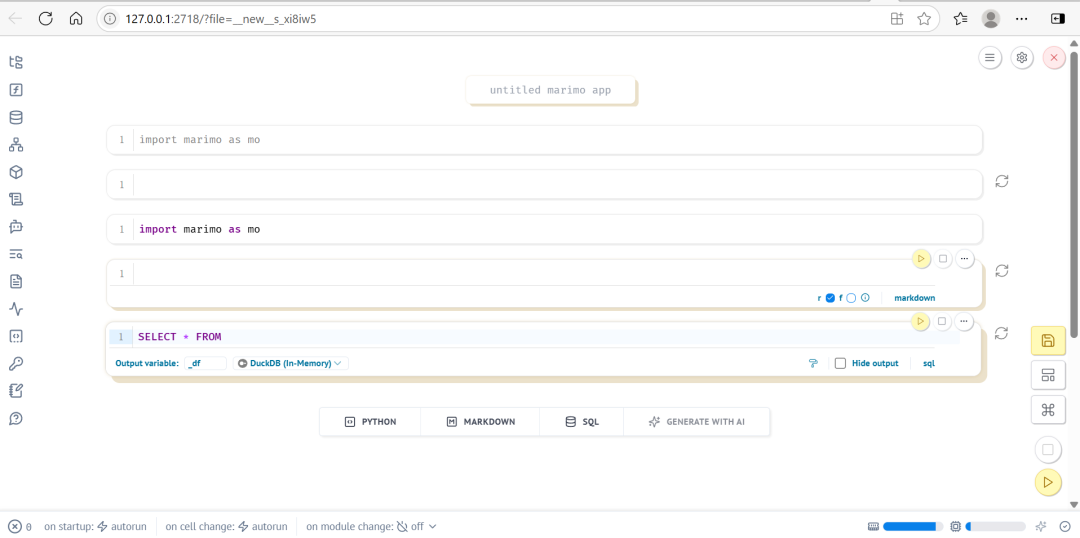
3. 编写混合内容(Python + Markdown + SQL)
在编辑器中,你可以创建不同类型的单元格。以下是一个示例笔记本的结构:
# %% md
## 🚀 数据加载与探索
# %%
import pandas as pd
df = pd.read_csv("data.csv")
# %% sql
SELECT category, AVG(value) AS avg_value
FROM df
GROUP BY category
# %%
from marimo.ui import slider
threshold = slider("设定阈值", 0, 100, 50)
filtered = df[df.value > threshold]
filtered.plot(kind="bar")
运行任意单元格,所有依赖它的单元格都会自动更新,始终保持状态一致。
4. 作为脚本运行
由于你的笔记本本身就是 .py 文件,你可以直接使用 Python 运行它,并传递参数(如果代码设计为接收参数的话):
python analysis.py --threshold 60
5. 部署为 Web 应用
一行命令即可将你的分析笔记变成可分享的交互式应用:
marimo run analysis.py
优点与缺点分析
优点
- 真正的响应式:自动管理依赖图,从根源上杜绝了脏状态,这对于复杂的数据分析和机器学习实验流程至关重要。
- 一体化工作流:一份文件,多种用途(笔记、脚本、App、幻灯片),极大减少了上下文切换和代码维护成本。
- 对开发者友好:纯文本
.py 文件,完美兼容 Git,便于进行代码审查和版本控制。
- 开箱即用:内置包管理、SQL 引擎和丰富的 UI 组件,降低了环境配置和集成的门槛。
当前存在的挑战
- 生态系统仍在成长:作为一个较新的项目,其社区和第三方库集成(插件、主题等)相比成熟的 Jupyter 生态还有差距。
- 需要思维转换:从命令式的“手动运行单元格”转向声明式的“响应式数据流”思维,初期有一定学习曲线。
- 深度定制能力:对于需要高度定制 UI 和交互逻辑的大型复杂应用,其能力上限可能不如专门的前端框架。
总结
marimo 的核心价值在于,它将“写分析笔记 → 执行实验 → 导出脚本 → 部署为可视化应用”这个数据科学工作流中的多个环节无缝串联了起来。这不仅能节省大量重复性劳动,也规避了中间环节可能产生的各种不一致和错误。
如果你追求更流畅、更可维护的数据科学开发体验,厌倦了在不同工具间来回切换,那么 marimo 绝对值得一试。你可以先去其官网体验在线 Playground,或者直接 pip install,几分钟就能感受到它的不同。对于追求效率的开发者而言,这类能简化工作流的工具总能带来惊喜。欢迎到云栈社区分享你使用 marimo 或其他 Python 神器的心得。
项目地址:https://github.com/marimo-team/marimo |  发表于 2026-4-10 05:13:57
|
查看: 150|
回复: 0
发表于 2026-4-10 05:13:57
|
查看: 150|
回复: 0
