当大模型进入推理时代,如何在提升能力的同时,控制好成本和延迟?ATTS (Asynchronous Test-Time Scaling) 提供了一条值得探索的新路径。
过去一年,大模型的发展重点出现了明显的变化。早期,业界更关注模型的参数量、训练数据规模和训练时长。而现在,一个日益关键的问题是:模型在回答复杂问题时,能否进行更深入、更复杂的“思考”。
尤其在数学推理、竞赛编程或复杂逻辑判断等高难度任务中,模型的能力瓶颈往往不在于“不知道”,而在于缺乏足够的计算资源去探索、筛选和修正推理路径。因此,测试时扩展 (Test-Time Scaling) 已成为增强大模型能力的一个重要方向。
然而,这条路并不平坦。虽然测试时扩展能有效提升模型表现,但它通常伴随着显著的副作用:更长的推理延迟、更大的显存压力以及复杂的系统同步开销。模型“想得更多”,但系统“跑得更重”。如何在效果与效率之间找到平衡,成了当前大模型人工智能部署必须面对的核心挑战。
近期提出的 ATTS 工作,正是为了解决这一矛盾。它试图回答一个非常实际的问题:能否让大模型在测试时高效地扩展推理能力,同时显著降低系统开销?
答案是肯定的,并且方式颇具新意。
为什么测试时扩展效果显著,但代价高昂?
在复杂推理任务中,模型的最终表现不仅取决于它“第一反应”的质量,更在于它是否有机会生成并筛选多条潜在的推理路径。
这正是测试时扩展的基本逻辑:在推理阶段投入更多计算资源,让模型“多尝试几次,多走几条路”。
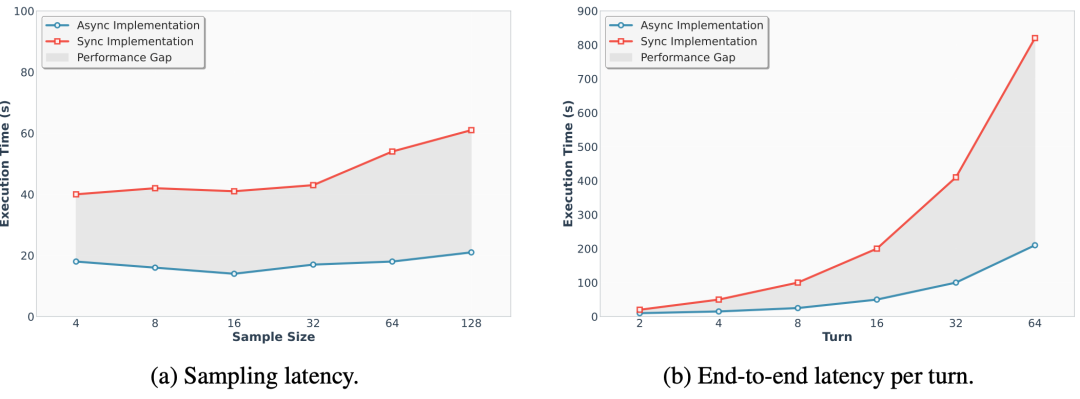
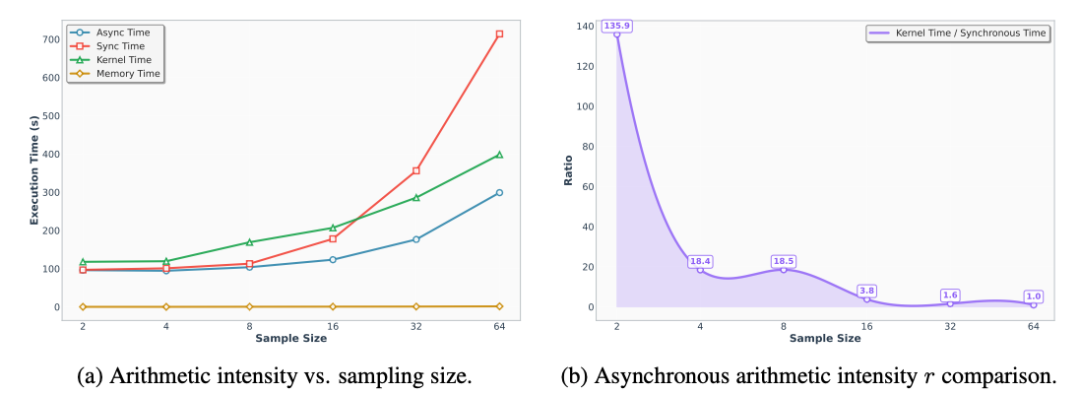
但当这一理念落地到实际系统中时,问题便接踵而至。生成更多候选路径意味着需要更多的采样、验证和排序操作。更重要的是,这些操作通常被强同步的流程所束缚——即前一步骤必须等待所有并行路径完成后,才能进入下一步。只要其中某些路径计算较慢,整个流程就会被拖住。随着扩展规模增大,这种同步等待的成本会急剧上升,成为实际部署中的主要瓶颈。
因此,核心挑战不仅是让模型“多想”,更是让它更高效地多想。
从投机解码到异步推理,瓶颈何在?
在众多大模型推理加速技术中,投机解码 (Speculative Decoding) 已成为一个关键方向。其核心思路直观:先用一个轻量、快速的草稿模型 (Draft Model) 生成一段候选 tokens,再由更强的目标模型 (Target Model) 进行验证。如果候选通过验证,就可以批量接受,从而减少目标模型逐 token 解码的开销。
形式化地看,草稿模型先提出候选序列:
$\tilde{y}_{1:m}$
目标模型再对其进行校验,决定接受哪些部分。最终系统真正保留的前缀可表示为:
$\tilde{y}_{1:\tau}, \quad \tau \leq m$
其中,$\tau$ 代表通过验证的最长前缀长度。
虽然投机解码比传统逐 token 解码高效得多,但它仍有一个显著局限:大多数实现本质上仍是同步的。草稿模型生成候选后,系统必须等待目标模型完成统一的验证,才能决定后续操作。这种“先生成,后集中校验”的模式,在单一路径生成时问题不大。但在测试时扩展场景下,候选路径数量激增,系统将面临严重的同步等待、缓存管理和显存占用压力。
简而言之,投机解码解决了“每一步都慢”的问题,但未能彻底解决“多条路径相互等待”的问题。而 ATTS 的关键创新,正是将投机解码从传统的同步范式,推进到了更适合测试时扩展的异步范式。
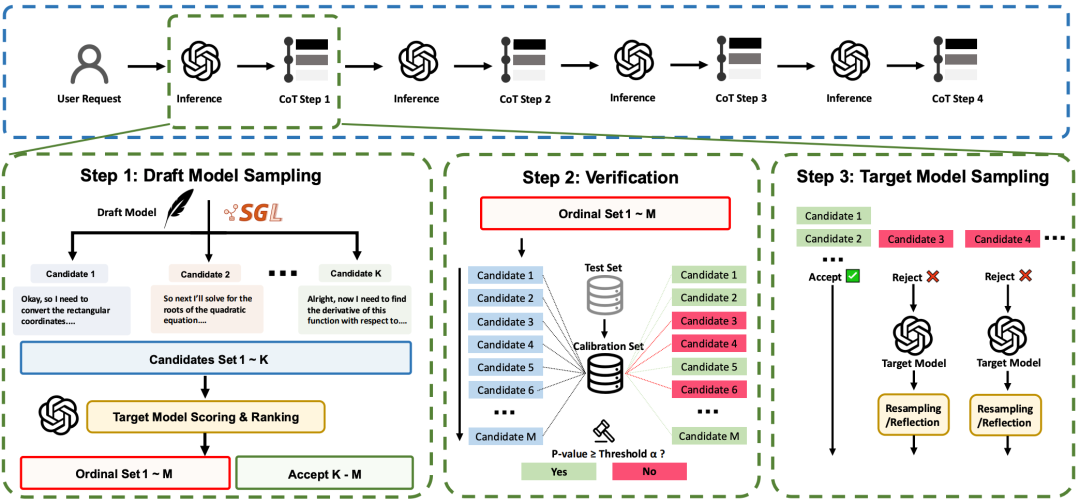
ATTS 的核心思路:引入统计筛选的异步框架
ATTS,即异步测试时扩展,其核心在于“异步”。这项工作的关键思路是将传统偏同步的扩展流程,改造为一个更灵活、高效的异步框架,允许系统对不同推理路径进行动态的、差异化的处理和资源分配。
具体而言,ATTS 并非简单地将投机解码应用于测试时扩展,而是进一步引入了共形预测 (Conformal Prediction) 这一统计工具,用于进行校准和判断:哪些候选值得继续投入计算,哪些可以提前终止。
从方法论上看,共形预测首先定义一个衡量候选“不靠谱”程度的非一致性分数:
$s(x, y)$
其中,$x$ 是输入问题,$y$ 是某条候选推理路径,$s(x, y)$ 分数越高,表示该候选越不可靠。
接着,在一个校准集上计算这些分数,并取其经验分位数作为决策阈值:
$\hat{q}_{1-\alpha} = \text{Quantile}_{1-\alpha} \{ s_i \}_{i=1}^{n}$
这里,$\alpha$ 是允许的风险水平,$\hat{q}_{1-\alpha}$ 就是系统用于筛选候选的关键门槛。
于是,基于共形预测的接受规则可以写成:
$C(x) = \{ y : s(x, y) \leq \hat{q}_{1-\alpha} \}$
这意味着,只有那些风险分数不超过阈值的候选路径,才会被保留并进入后续更昂贵的推理阶段。
这组公式背后的思想很直观:ATTS 并非盲目地为所有候选追加算力,而是先进行一次有统计理论保证的筛选,再将宝贵的计算资源集中到更有潜力的路径上。它试图解决一个根本性问题:在有限的推理预算下,如何智能地分配计算资源?
机制详解:快速生成与选择性深入
从整体流程看,ATTS 可分为三个阶段:
- 草稿模型采样:由轻量级的 Draft Model 快速生成多个候选推理链。
- 验证与筛选:由更强的 Target Model 对候选进行验证,并基于共形预测规则进行拒绝采样。
- 选择性深入:系统仅对通过筛选的候选投入进一步的推理预算。
如果说传统投机解码是“先猜一段,再统一验收”,那么 ATTS 则将其扩展到了“多候选、多路径、异步筛选”的测试时扩展场景。它不仅加速单条生成链,更让整个推理搜索过程能更灵活、高效地运行。
从形式上看,这是一个基于阈值的预算分配过程。对于每个候选 $y_k$,系统根据以下规则决定是否继续:
$\text{Accept}(y_k) = \mathbb{1}\{ s(x, y_k) \leq \hat{q}_{1-\alpha} \}$
其中 $\mathbb{1}\{\cdot\}$ 是指示函数,条件满足时取值为1(接受),否则为0(拒绝)。分数低于阈值的候选会被接受并扩展,反之则被提前截断。
从预算分配的视角可以更清楚地理解:
$B(x) = \sum_{k=1}^{K} \mathbb{1}\{ s(x, y_k) \leq \hat{q}_{1-\alpha} \}$
这里,$B(x)$ 表示对输入 $x$ 最终分配到的有效推理预算,$K$ 是初始候选总数。该式表明,最终能获得后续算力的,仅是那些通过共形筛选的候选子集。
这种机制的优势显而易见:它既保留了测试时扩展通过多路径搜索提升效果的能力,又避免了将昂贵资源浪费在低质量的候选上;既增强了复杂任务中的探索深度,又显著降低了系统架构层面的无效开销和等待时间。ATTS 的本质不是“让模型少想”,而是让模型把‘思考’的预算花在刀刃上。
超越速度:有原则的加速与统计保证
ATTS 的深层价值在于,它重新定义了测试时扩展的优化目标。以往我们默认扩展能力等于增加采样数、推理轮次或并行路径。但 ATTS 提示我们,关键在于“扩展得更合理”,而非“扩展得更多”。
共形预测为这种“合理扩展”提供了坚实的统计框架。在理想条件下,它关注如下覆盖性质:
$\Pr(y^* \in C(x)) \geq 1 - \alpha$
其中,$y^*$ 代表真实有效的目标候选,$C(x)$ 是筛选后保留的候选集合。该式表明,系统能以至少 $1-\alpha$ 的概率,将真正有价值的候选包含在内。
在 ATTS 的语境下,这一点至关重要。这意味着系统并非随意丢弃候选,而是在统计可控的前提下,主动减少无效计算。因此,ATTS 的意义不限于工程上的加速,更是将测试时扩展推向了 “有原则地加速” 的新阶段。
实验验证:高效且有效的性能表现
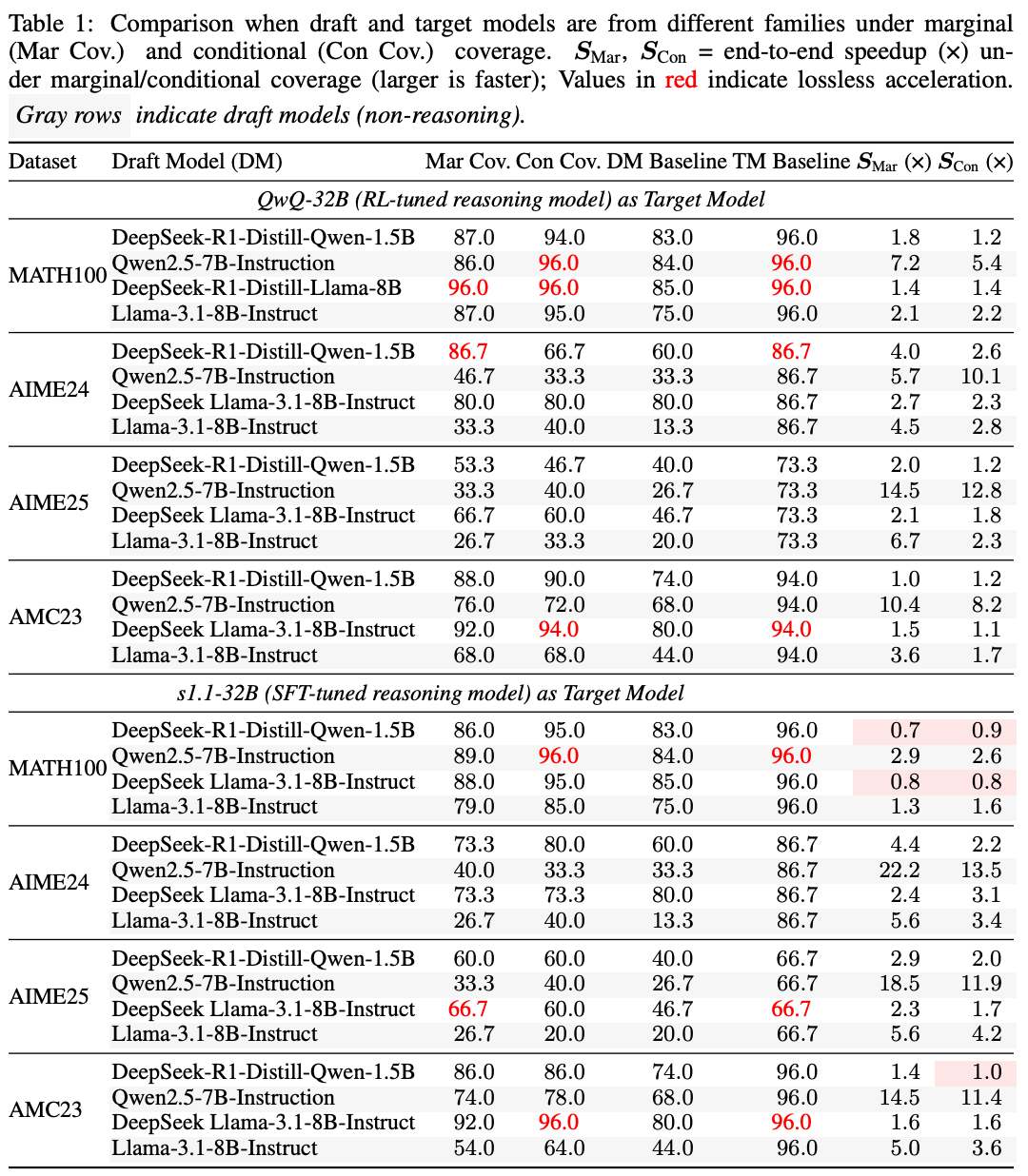
根据论文实验结果,ATTS 在多个高难度数学推理数据集(如 MATH, AMC23, AIME24/25)上均展现出显著的效率优势和稳定的效果。
该方法最高可实现:
- 56.7倍的测试时扩展加速
- 4.14倍的吞吐量提升
尤为关键的是,这种加速并未以牺牲模型性能为代价。ATTS 在维持甚至提升模型效果的同时,将测试时扩展从“有效但昂贵”推进到了“有效且高效可用”的层面。
此外,在大规模扩展设置下,ATTS 展现了强大的系统潜力。例如,使用 1.5B 的草稿模型与 70B 的目标模型组合,在 AIME 数据集上能够取得接近先进推理模型 o3-mini (high) 的表现水平。这表明,通过合理的异步协同机制,轻量草稿模型与强大目标模型的组合,可能成为未来高效推理系统中一条极具实用价值的路线。
总结:迈向更智能的推理时代
大模型的发展正进入一个新阶段。模型能力的提升,将越来越依赖于推理阶段的资源组织与调度智慧,而不仅限于训练阶段的规模扩张。
ATTS 的价值在于,它将测试时扩展从一个高成本的增强手段,转化为一个更具工程落地性、有统计理论保证、且充满算法想象力的技术框架。它向我们展示,未来大模型的推理不仅可以“多想几步”,更能做到:
多想,但不盲想;扩展,但不低效;更强,也更快。
这或许是当前大模型推理时代最值得关注的技术方向之一。对这类前沿技术方案的深入讨论和实践分享,也欢迎大家在云栈社区进一步交流。
 发表于 2026-4-10 07:23:11
|
查看: 191|
回复: 0
发表于 2026-4-10 07:23:11
|
查看: 191|
回复: 0
