面对海量Nginx日志,如何快速、准确地识别潜在攻击?TQSec LogAnalysisBot或许是一个值得关注的轻量级解决方案。这是一个基于深度学习的Nginx日志分析工具,能够自动识别和分类攻击行为,旨在帮助运维与安全团队以极低的资源消耗,实现高效的安全威胁发现与响应。
这个工具的核心是一个经过训练的小模型,其设计理念是“小而精”。模型文件大小不超过3MB,在最低1核1G的配置上即可运行,单次识别速度可控制在10毫秒以内。目前它主要针对PHP后端应用的日志进行优化训练,但您完全可以利用自己的日志数据集,训练出专属于您业务场景的定制化模型。
工具性能与配置
Q: 它的精准度和泛化能力如何?
根据测试,该模型在测试集上表现优异:
- 精准度 (Precision): 98.88%
- 召回率 (Recall): 99.51%
- F1分数: 99.24%
模型展现了良好的泛化能力,能够较为准确地识别未知的攻击模式。在测试中,对于同类型(PHP后端)的攻击行为,识别概率通常高于0.9;对于正常行为,识别概率则通常低于0.1。

Q: 运行它需要什么配置?
- 最低运行配置: 1核1G,无需GPU。
- 推荐运行配置: 2核2G,无需GPU。
- 训练/微调配置建议: 如果需要基于自有数据重新训练或微调模型,建议准备8核8G的配置(同样无需GPU)。
如何定制属于您的小模型?
如果您希望模型能更好地适应您的具体业务和环境,可以遵循以下六个步骤,使用自己的Nginx日志数据进行训练。
第一步:准备环境与数据
首先,您需要准备训练数据集,即两份Nginx日志文件:
attack.log.txt: 包含已知攻击行为的日志。safe.log.txt: 包含正常请求的日志。
然后,安装项目所需的Python依赖包。

第二步:格式化日志数据
运行脚本,将原始的日志文本文件转换为结构化的JSON Lines格式。脚本会自动为每条日志打上is_attack标签(攻击为1,正常为0)。
python Log2Jsonl.py

第三步:特征提取与向量化
此步骤将对日志中的URL、User-Agent等字段进行分词和特征提取,并将结果保存为后续训练所需的格式。
python Jsonl2npy.py

第四步:训练深度学习模型
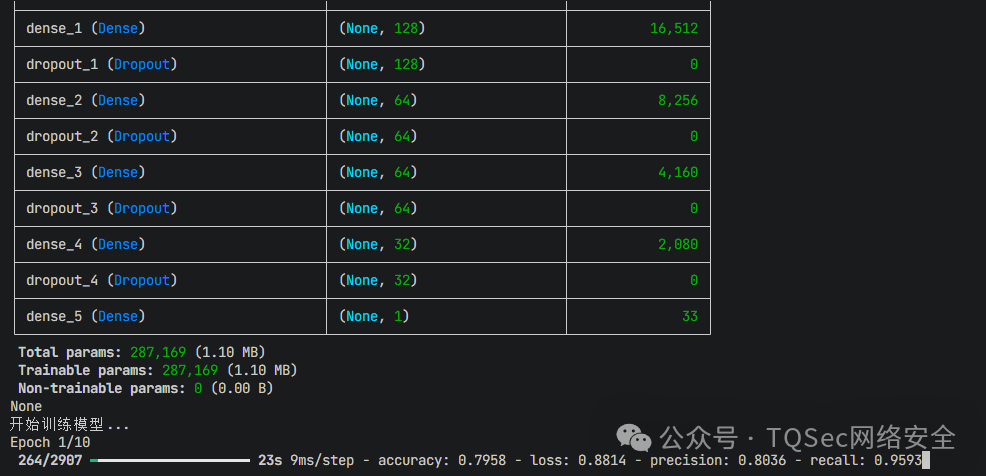
调用训练脚本,开始训练您的定制化攻击检测模型。
python model_train.py

训练完成后,将生成两个关键文件:
tqsecLogAI.h5: 保存训练好的Keras模型。scaler.npy: 保存用于特征数据标准化的参数。
第五步:使用模型进行预测
模型训练好后,您可以使用它对新的Nginx日志文件进行安全分析。
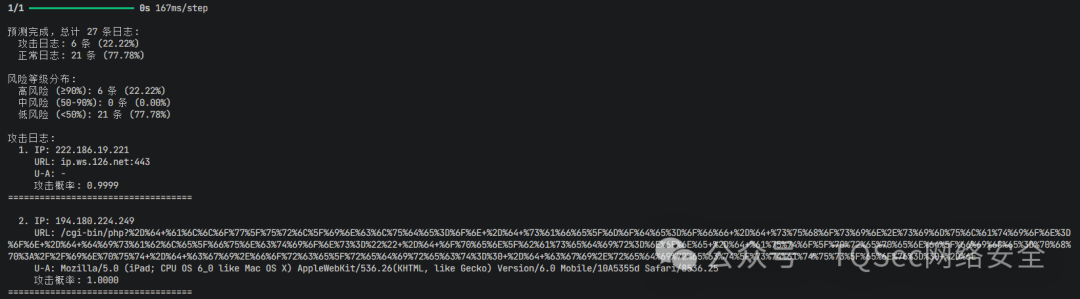
python predict_final.py test.log

脚本会输出分析报告,包括风险等级分布(高、中、低风险)以及每条日志的详细分析结果和攻击概率。
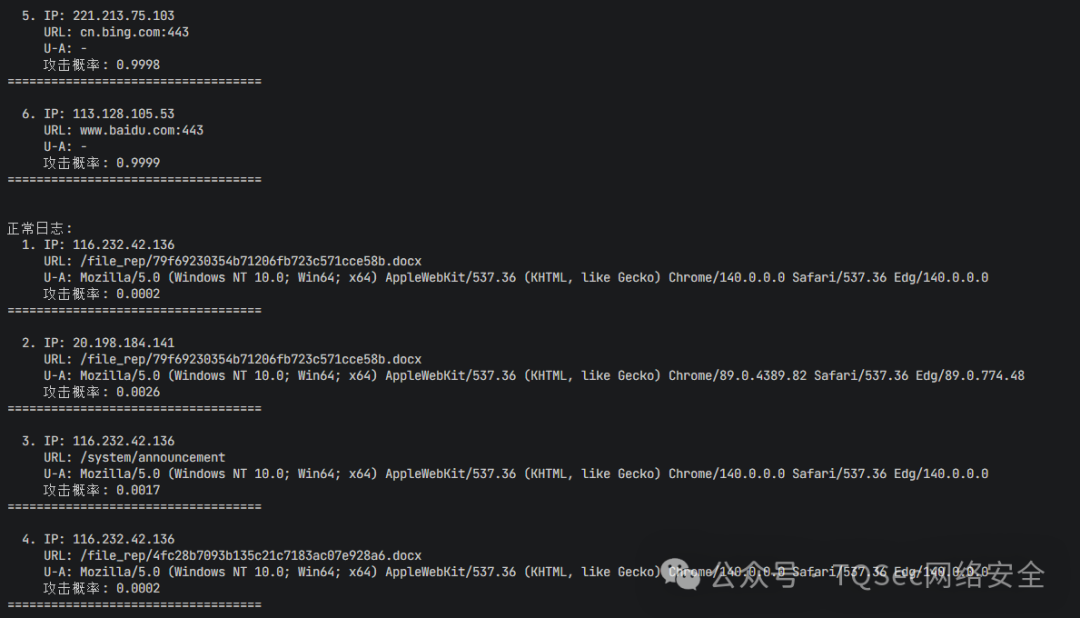
第六步:模型微调
如果后续有新的日志数据,您可以在原有模型基础上进行微调,而非从头训练。基本流程如下:
# 1. 将新的日志文件格式化为 jsonl
python Log2Jsonl.py
# 2. 提取特征
python Jsonl2npy.py
# 3. 微调模型
python trimming.py
请注意:微调的效果很大程度上取决于新数据的数量和质量。如果数据量很少(例如不足1万条),直接使用新数据重新训练可能比微调效果更好。进行微调前,请确保已准备好新的attack.log.txt和safe.log.txt文件。
常见问题处理
在Windows系统上运行训练脚本时,可能会遇到因缺少Visual C++运行时组件而导致的错误。

解决方案:安装项目目录下的VC_redist.x64.exe文件,或从微软官网下载并安装最新的Microsoft Visual C++ Redistributable。
获取项目
TQSec LogAnalysisBot 是一个开源项目。如果您对基于 Nginx 日志进行开源实战感兴趣,可以通过以下地址获取完整源代码和详细文档:
项目地址:https://gitee.com/dashengbaby/tqsec-log-analysis-bot |  发表于 2026-4-11 02:57:27
|
查看: 191|
回复: 0
发表于 2026-4-11 02:57:27
|
查看: 191|
回复: 0
