摩根士丹利最新研报指出,谷歌TPU的产能即将迎来爆发式增长,且供应链的不确定性已基本解决,这为谷歌对外销售芯片扫清了障碍。报告大幅上调了预测,预计2027年TPU产量将达500万块,2028年更将攀升至700万块,较此前预测分别上调67%和120%。这意味着未来两年的计划产量,将远超过去四年的总和。
从战略层面看,谷歌意图明确,计划向第三方数据中心销售TPU,作为其谷歌云平台(GCP)业务的重要补充。尽管大部分TPU仍将用于谷歌自身的AI训练和云服务,但如此庞大的产能储备,无疑是为更广泛的商业化铺路。在全行业对先进AI算力需求高涨的背景下,谷歌显然不愿错过这轮红利。
这一系列动态表明,英伟达在AI芯片市场一家独大的格局,正迎来前所未有的挑战。

(动图来自博主赛博轩Albert)
近期,业内对谷歌TPU与英伟达GPU的技术较量关注度颇高。一篇题为《2025年AI推理成本:谷歌TPU为何比英伟达GPU性能高出4倍》的报道,系统分析了两者的技术差异与性能对比。
AI算力的分野:训练与推理
要理解市场正在发生的巨变,首先需要剖析人工智能计算的两大支柱:训练和推理。

训练:英伟达的传统优势领域
训练是向神经网络注入海量数据,以“教会”它们识别模式、做出预测的密集型过程。它需要极强的并行计算能力,涉及数千个GPU协同进行矩阵乘法等运算。英伟达正是凭借在此领域的深厚积累构建了其帝国。其CUDA软件生态和Hopper架构(如H100 GPU)专为处理此类高强度计算任务设计,催生了GPT-4等突破性模型。
但训练具有一次性特征,成本虽然高昂(例如GPT-4训练成本约1.5亿美元),却是前置且有限的。长期以来,英伟达GPU因其在图形、模拟和通用计算方面的多功能性,成为此阶段的首选。
推理:持续增长的成本中心
推理则是模型的部署与应用阶段,如每次ChatGPT查询、图像生成或推荐算法运行。与训练不同,推理是持续进行的,每处理一个token、每一次用户交互都会产生成本。
严峻的现实在于,推理需求随着使用量增长呈指数级上升。OpenAI 2024年的推理支出预计高达23亿美元,是其GPT-4训练成本的15倍。分析师估计,到2026年,推理需求可能比训练需求高出118倍;到2030年,推理计算将消耗75%的AI算力资源。在这个领域,每次查询的成本变得至关重要,而英伟达为高吞吐量并行训练优化的GPU,在处理持续查询时往往面临能效挑战。
谷歌TPU:为推理时代而生的专用架构
谷歌TPU并非偶然产物,它是为其庞大的搜索、YouTube推荐等业务量身定制的专用集成电路(ASIC),核心专长为处理人工智能的基础数学运算——张量运算。
架构优势:TPU如何在推理中确立优势
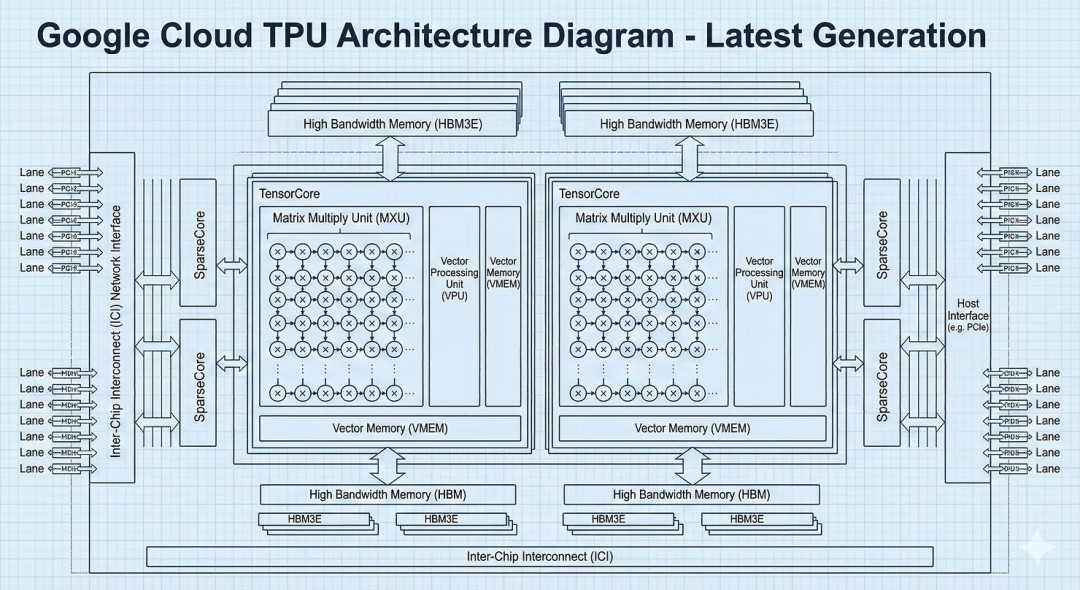
TPU的核心优势在于其脉动阵列设计,该硬件网格能高效流动数据,减少频繁的内存访问,从而显著降低延迟与能耗。相比之下,英伟达GPU如同功能强大的瑞士军刀,需要即时解码指令,带来了额外开销。
对于大规模语言模型等推理任务,这种架构差异直接转化为巨大的性价比优势。分析指出,TPU的性价比可达英伟达H100的四倍。谷歌最新的Ironwood(v7)TPU速度是v6的四倍,峰值算力是v5p的十倍,每一代都能带来2-3倍的性价比提升。
能效是另一关键优势。TPU采用垂直供电等设计,在执行搜索查询时可比GPU节能60-65%。在MLPerf基准测试中,TPU v5e在9个推理类别中的8个领先。
价格层面,按需使用的TPU v6e起价为每小时1.375美元,长期合约价可低至0.55美元/小时,且无需支付英伟达的授权费。用户反馈表明,在特定工作负载下,一个v5e扩展舱的性价比优于八个H100扩展舱。
ASIC与GPU的本质区别
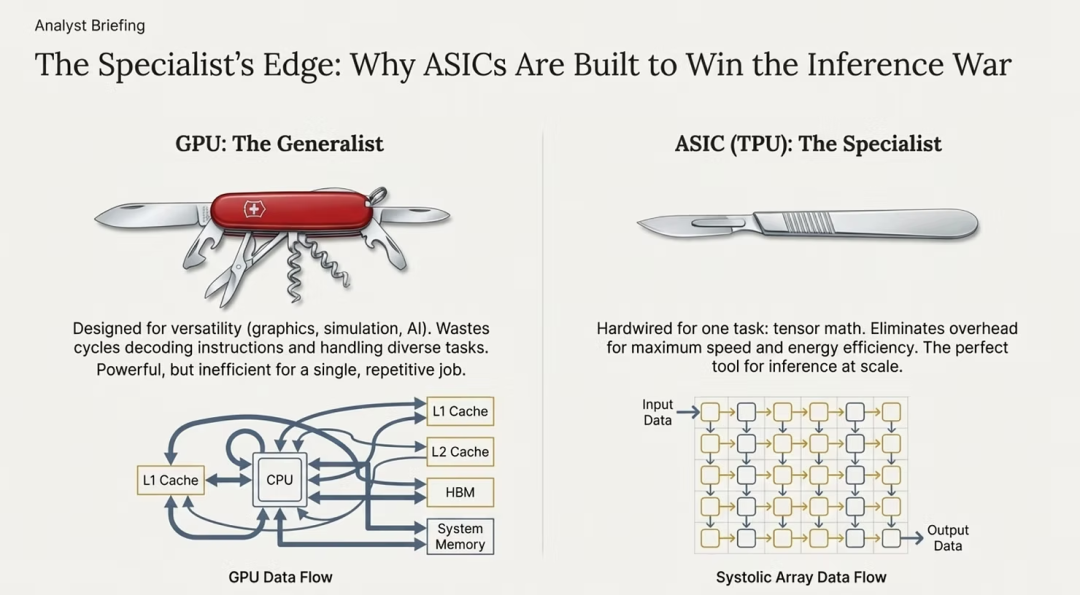
要理解TPU如何挑战英伟达,需掌握ASIC与GPU的根本架构差异。
- GPU(图形处理器):本质是通用处理器。最初为图形渲染设计,后被用于AI。其优势在于多功能性,可处理游戏、科学模拟、加密货币及神经网络等多种负载,是AI早期发展的“多面手”。
- ASIC(专用集成电路):是为单一目的设计的专业芯片。谷歌TPU专为矩阵乘法和张量运算硬编码,牺牲灵活性以换取极致效率。每个晶体管都针对单一目标优化,实现高速、低能耗的张量处理。
简单比喻:GPU像全能运动员,而ASIC像奥运短跑冠军。对于需要24/7不间断运行的推理任务,“短跑冠军”更具优势。
ASIC的核心优势包括:
- 能效:消除指令解码开销,相同负载下能耗降低60-65%。
- 低延迟:脉动阵列提供确定性数据流,避免GPU内存层次结构带来的延迟波动,对实时应用至关重要。
- 每操作成本:去除冗余电路,在Transformer模型上实现更高的每美元性能。
- 可扩展性:可通过定制互连(如TPU Pod)实现近乎线性的扩展,突破PCIe的限制。
当然,ASIC的专用性亦是其局限。训练新模型、尝试新架构或运行非AI任务仍需GPU的灵活性。因此,未来趋势是战略分工:GPU用于研究和训练,ASIC用于生产推理。这也意味着企业需要构建更复杂的异构计算策略,正如在云原生/IaaS实践中管理混合工作负载一样普遍。
现实案例:行业巨头转向TPU
迁移案例最能说明趋势。全球领先的AI运营商正转向TPU,以实现显著的成本节约和扩展。
- Midjourney:2024年从GPU转向TPU后,其月度推理成本从200万美元降至70万美元,降幅达65%。吞吐量提升了3倍。
- Anthropic:与谷歌达成价值数百亿美元协议,承诺使用多达100万个TPU。其CEO表示,“卓越的性价比和效率”是交易关键。
- Meta:作为英伟达最大客户之一,正就价值数十亿美元的TPU部署进行深入洽谈,计划从2026年起通过谷歌云租赁TPU,并考虑在2027年前部署本地TPU,用于Llama微调等任务。
决策指南:何时选择TPU或GPU
选择TPU还是英伟达GPU取决于具体的工作负载、规模与基础设施策略。
在以下情况选择TPU:
- 月度推理成本超过5万美元,TPU可节省40-65%的成本。
- 工作负载为大规模LLM服务、推荐系统、图像/视频生成等张量密集型操作。
- 已部署或计划采用Google Cloud及TensorFlow/JAX生态。
- 对能源效率和可持续发展目标有较高要求。
在以下情况选择英伟达GPU:
- 需要进行模型训练、自定义架构研究,或依赖特定的CUDA库和工具链。
- 执行多云战略,要求硬件在AWS、Azure及本地数据中心间可移植。
- 工作负载多样化,包含图形渲染、模拟或非AI计算。
- 预算有限(如月算力支出低于2万美元),迁移成本不划算。
混合战略已成为许多企业的务实选择,例如使用NVIDIA H100进行训练与实验,同时部署TPU v6e/v7集群用于生产推理,可在保持研发灵活性的同时,优化40-50%的总计算成本。
挑战与未来展望
TPU并非没有挑战。其生态与TensorFlow/JAX深度绑定,相比英伟达CUDA的通用性有所限制。大规模扩展TPU(如组建Pod)需要深度集成Google Cloud的架构。
竞争也在加剧。亚马逊的Trainium、微软的Maia等专用芯片正涌入市场,加剧了ASIC领域的碎片化。然而,谷歌TPU凭借其九代产品的迭代经验和支撑谷歌万亿级查询的实战规模,目前仍保持领先。
供应链方面,谷歌正与博通、台积电合作加速v7芯片生产,预计到2026年,TPU供应将能更好地满足市场需求。
结论
英伟达凭借在训练时代的辉煌建立了计算帝国,但推理主导的未来正在到来。在这一领域,专用架构展现出显著优势。谷歌TPU凭借数倍的性价比,正吸引着Midjourney、Anthropic、Meta等行业巨头的转向,预示着AI计算市场格局正在发生深刻变革。这一转变不仅关乎硬件竞争,更将推动整个人工智能产业向更高效、更可持续的方向演进。
 发表于 2025-12-11 06:46:44
|
查看: 306|
回复: 0
发表于 2025-12-11 06:46:44
|
查看: 306|
回复: 0
