在互联网应用开发中,Redis 缓存的使用,大部分都是为了保护数据库。让应用在非必要的情况下,尽可能减少对数据库的调用。比如一份固定的数据可以放到 Redis 缓存中提供查询,或者需要数据库唯一索引防重拦截 insert 操作前先进行 Redis 布隆过滤器校验,也或者是分布式场景下的加锁处理。这样可以减少对数据库资源的占用,同时也提升了接口的响应性能。
除此之外,还有一些专门针对 Redis 做的技术方案,来提高系统的响应吞吐量和性能。例如:基于 Redis 内存存储实现的规则引擎、基于 Redis 队列实现的低延迟任务调度、基于 Redis 发布和订阅实现的流程解耦操作等等,都是互联网需求场景中非常常用的技术方案。本节会模拟一个订单下单场景,来综合运用 Redis 的缓存、加锁、发布/订阅等功能,展示 Redis 在实际项目中的实践。
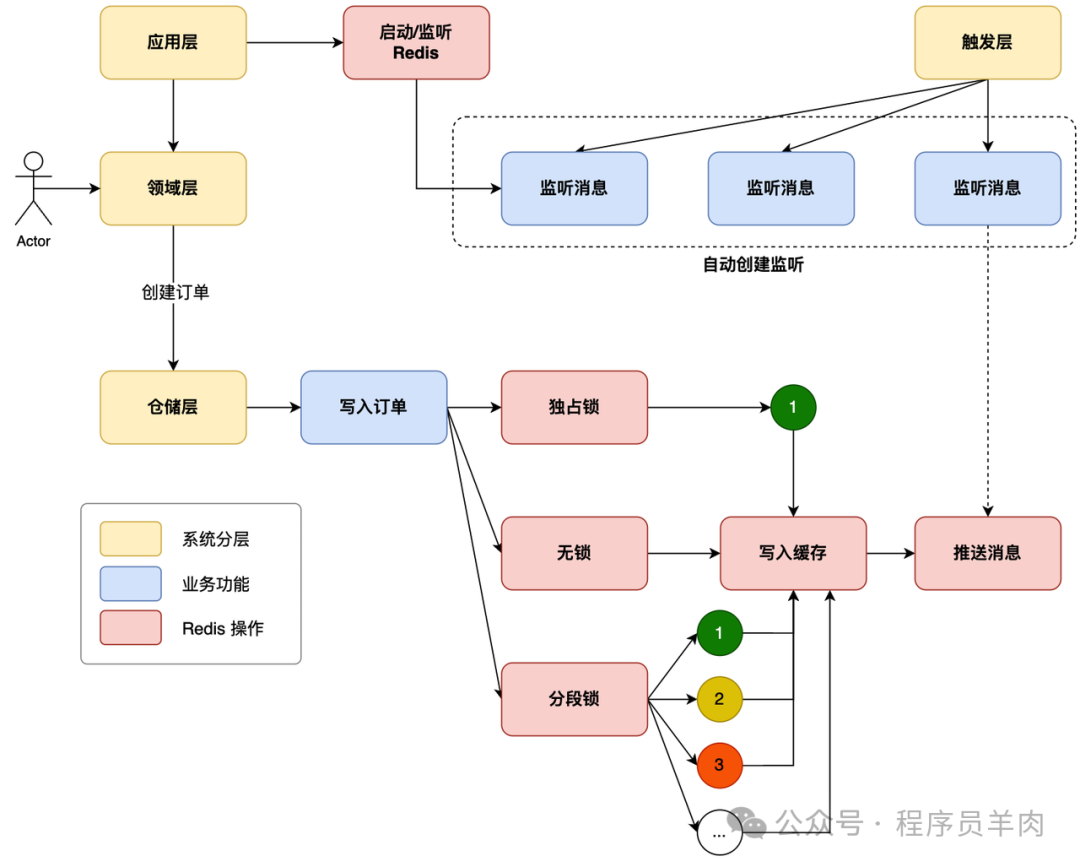
整个案例在 DDD 分层架构下,通过领域层调用仓储,完成订单的写库操作。在写库时,添加了不同类型锁的处理,以验证性能差异。之后写入缓存和发布 Redis 消息,让监听端可以收到发布的信息。通过这样一个常见的订单创建和查询场景,来学习 Redis 的使用。在实现中,我们用到了 Redisson 框架来处理 Redis 的调用。
一、工程结构
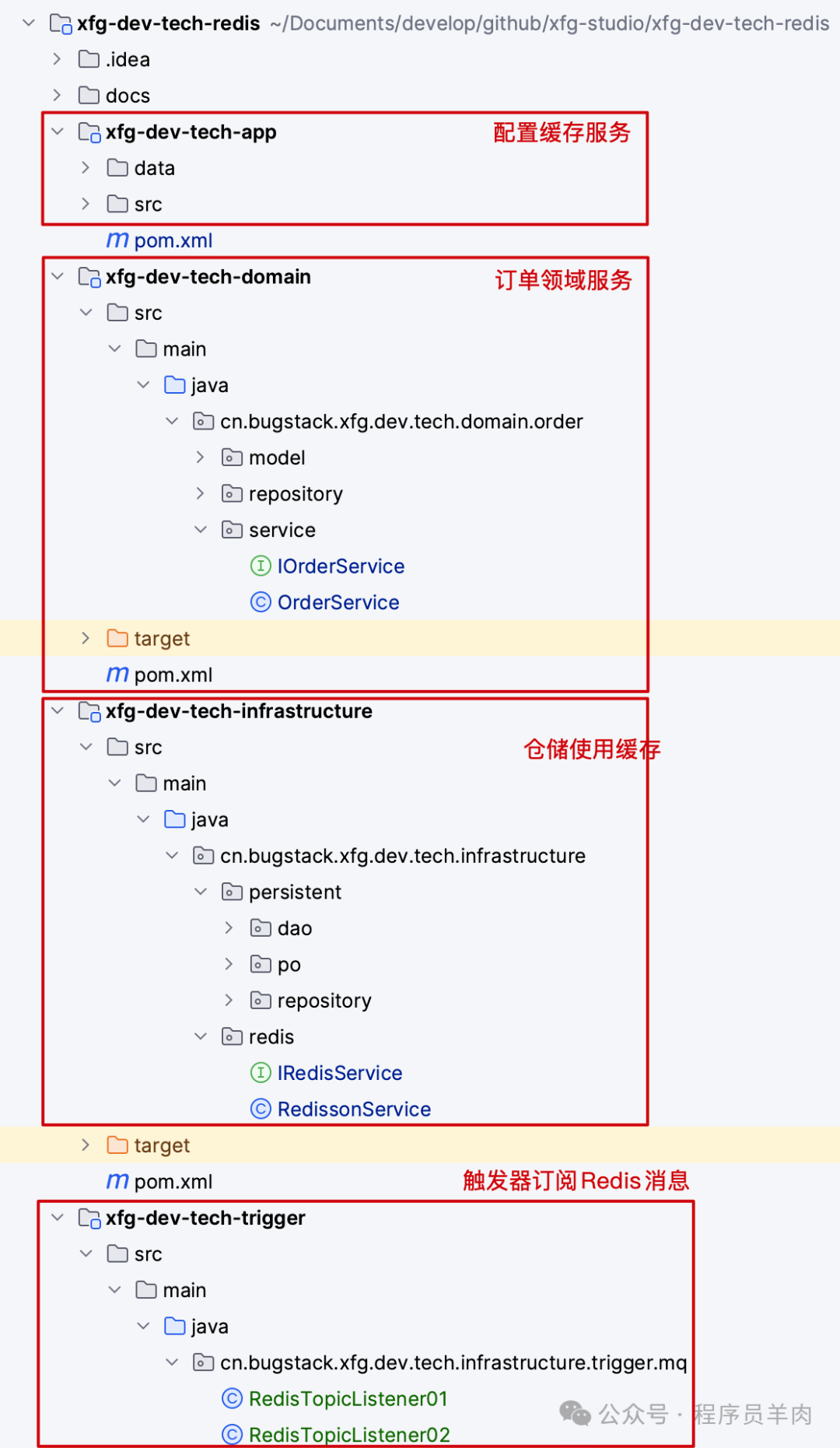
这是一套 DDD 工程模型,将各个模块嵌入到 DDD 分层架构中,展示它们如何协同工作。
工程分为:app、domain、infrastructure、trigger 四层,此外还有一个 types 通用层。
- app:用于配置 Redis 的相关启动操作。鉴于 Spring Boot 以及 Redis 版本差异,这里自己创建客户端,以更好地兼容不同版本并方便功能扩展。
- domain:领域服务层,order 可视为一个订单域,包括订单的创建、支付、查询等业务逻辑。
- infrastructure:基础层,是对 domain 依赖倒置的具体实现。具体的库操作、缓存操作都在这一层实现,因此操作 Redis 的加锁、缓存也在此处理。
- trigger:触发器层,也有叫接口层。通常 http、rpc、job、mq、listener 都在这一层。因此订阅 Redis 消息的处理也放在此层。
- types:工程中还有一个通用类型层,定义非专属 domain 领域内的公共资源。例如本文中定义了一个自定义注解,来处理类的动态加载和组件开发,这非常值得学习。
二、配置缓存
在 app 模块下的 config 中,创建 RedisClientConfigProperties 配置类和 RedisClientConfig 客户端启动类,用于通过 Redisson 创建 Redis 连接客户端。
RedisClientConfigProperties.class
@Data
@ConfigurationProperties(prefix = "redis.sdk.config", ignoreInvalidFields = true)
public class RedisClientConfigProperties {
/** host:ip */
private String host;
/** 端口 */
private int port;
/** 账密 */
private String password;
/** 设置连接池的大小,默认为64 */
private int poolSize = 64;
/** 设置连接池的最小空闲连接数,默认为10 */
private int minIdleSize = 10;
/** 设置连接的最大空闲时间(单位:毫秒),超过该时间的空闲连接将被关闭,默认为10000 */
private int idleTimeout = 10000;
/** 设置连接超时时间(单位:毫秒),默认为10000 */
private int connectTimeout = 10000;
/** 设置连接重试次数,默认为3 */
private int retryAttempts = 3;
/** 设置连接重试的间隔时间(单位:毫秒),默认为1000 */
private int retryInterval = 1000;
/** 设置定期检查连接是否可用的时间间隔(单位:毫秒),默认为0,表示不进行定期检查 */
private int pingInterval = 0;
/** 设置是否保持长连接,默认为true */
private boolean keepAlive = true;
}
RedisClientConfig.class
@Configuration
@EnableConfigurationProperties(RedisClientConfigProperties.class)
public class RedisClientConfig {
@Bean("redissonClient")
public RedissonClient redissonClient(ConfigurableApplicationContext applicationContext, RedisClientConfigProperties properties){
Config config = new Config();
// 根据需要可以设定编解码器;https://github.com/redisson/redisson/wiki/4.-%E6%95%B0%E6%8D%AE%E5%BA%8F%E5%88%97%E5%8C%96
// config.setCodec(new RedisCodec());
config.useSingleServer()
.setAddress("redis://" + properties.getHost() + ":" + properties.getPort())
.setPassword(properties.getPassword())
.setConnectionPoolSize(properties.getPoolSize())
.setConnectionMinimumIdleSize(properties.getMinIdleSize())
.setIdleConnectionTimeout(properties.getIdleTimeout())
.setConnectTimeout(properties.getConnectTimeout())
.setRetryAttempts(properties.getRetryAttempts())
.setRetryInterval(properties.getRetryInterval())
.setPingConnectionInterval(properties.getPingInterval())
.setKeepAlive(properties.isKeepAlive())
;
RedissonClient redissonClient = Redisson.create(config);
String[] beanNamesForType = applicationContext.getBeanNamesForType(MessageListener.class);
for (String beanName : beanNamesForType) {
MessageListener bean = applicationContext.getBean(beanName, MessageListener.class);
Class<? extends MessageListener> beanClass = bean.getClass();
if (beanClass.isAnnotationPresent(RedisTopic.class)) {
RedisTopic redisTopic = beanClass.getAnnotation(RedisTopic.class);
RTopic topic = redissonClient.getTopic(redisTopic.topic());
topic.addListener(String.class, bean);
ConfigurableListableBeanFactory beanFactory = applicationContext.getBeanFactory();
beanFactory.registerSingleton(redisTopic.topic(), topic);
}
}
return redissonClient;
}
/**
* 手动配置
*/
@Bean("testRedisTopic")
public RTopic testRedisTopicListener(RedissonClient redissonClient, RedisTopicListener01 redisTopicListener){
RTopic topic = redissonClient.getTopic("xfg-dev-tech-topic");
topic.addListener(String.class, redisTopicListener);
return topic;
}
}
application-dev.yaml
redis:
sdk:
config:
host: localhost
port: 6379
password: 123456
pool-size: 10
min-idle-size: 5
idle-timeout: 30000
connect-timeout: 5000
retry-attempts: 3
retry-interval: 1000
ping-interval: 60000
keep-alive: true
Spring 本身也提供了 Redis 配置,但考虑到兼容性问题和后续功能拓展,建议采用自定义配置。
三、数据缓存
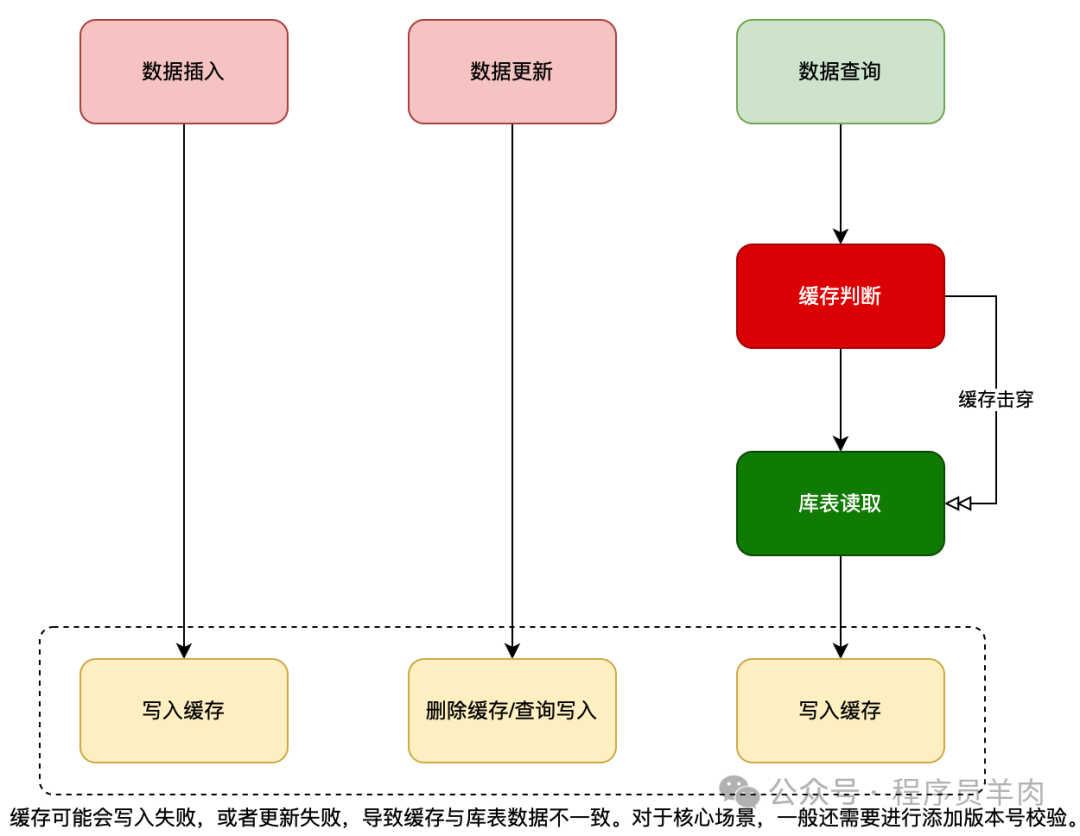
Redis 的大部分操作都是缓存数据,以提高系统的 QPS。在插入、更新、删除(逻辑删)、查询时,依赖 Redis 进行提速。
@Override
public OrderEntity queryOrder(String orderId) {
OrderEntity orderEntity = redissonService.getValue(orderId);
if (null == orderEntity) {
UserOrderPO userOrderPO = userOrderDao.selectByOrderId(orderId);
orderEntity = new OrderEntity();
orderEntity.setUserName(userOrderPO.getUserName());
orderEntity.setUserId(userOrderPO.getUserId());
orderEntity.setUserMobile(userOrderPO.getUserMobile());
orderEntity.setSku(userOrderPO.getSku());
orderEntity.setSkuName(userOrderPO.getSkuName());
orderEntity.setOrderId(userOrderPO.getOrderId());
orderEntity.setQuantity(userOrderPO.getQuantity());
orderEntity.setUnitPrice(userOrderPO.getUnitPrice());
orderEntity.setDiscountAmount(userOrderPO.getDiscountAmount());
orderEntity.setTax(userOrderPO.getTax());
orderEntity.setTotalAmount(userOrderPO.getTotalAmount());
orderEntity.setOrderDate(userOrderPO.getOrderDate());
orderEntity.setOrderStatus(userOrderPO.getOrderStatus());
orderEntity.setUuid(userOrderPO.getUuid());
orderEntity.setDeviceVO(JSON.parseObject(userOrderPO.getExtData(), DeviceVO.class));
// 设置到缓存
redissonService.setValue(orderId, orderEntity);
}
return orderEntity;
}
- 插入数据时,可以一并写入缓存。
- 更新操作时,可以考虑删除缓存,再由下次查询写入。因为更新通常是部分字段,直接更新缓存容易导致数据不一致。
- 查询时,使用缓存拦截,避免所有请求都打到数据库,从而提升系统 QPS。
- 关于缓存击穿,指的是本应存放在缓存的大量数据,由于存放偏差或遗漏,导致大量请求穿透到数据库,可能将数据库拖垮。尤其是在需要事务加锁的资源竞争场景,情况会更严重。
四、加锁处理
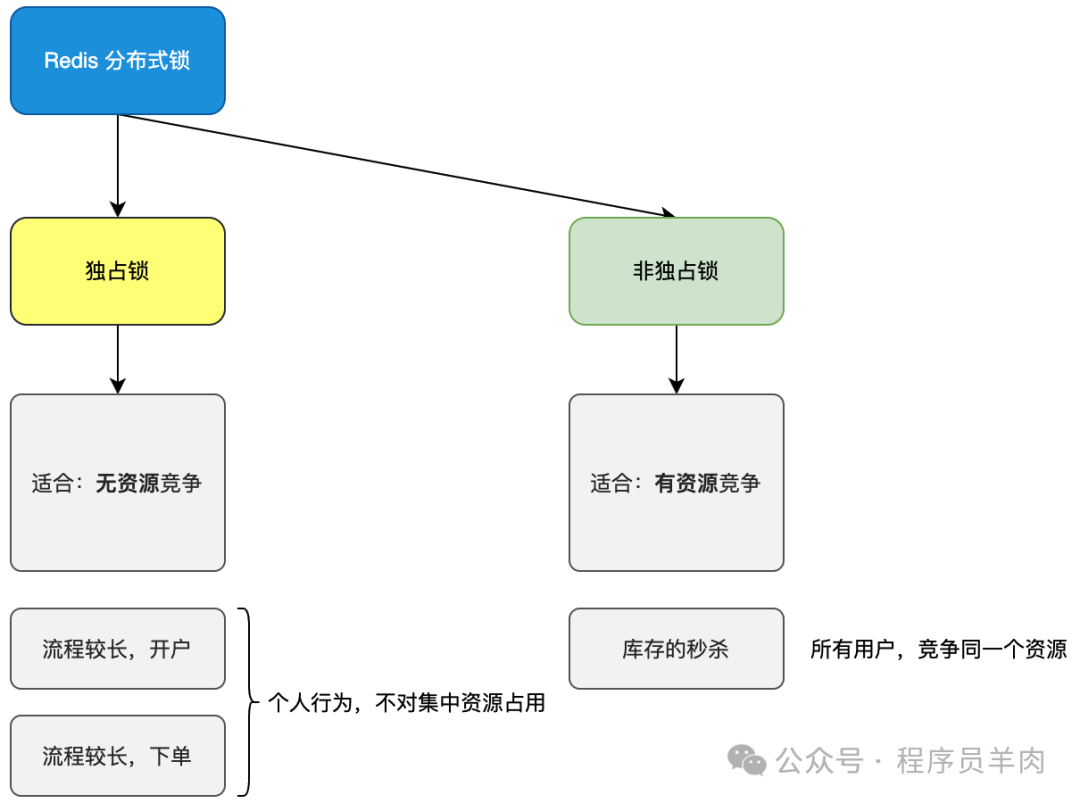
使用 Redis 加分布式锁,是分布式架构设计中非常常用的手段。常用于两类场景:一是流程较长、耗时较多的个人行为,如开户、下单;二是一些资源竞争时的排队处理,如库存占用。但对于资源竞争类的库存占用,如果直接加分布式锁会严重影响系统吞吐量,因为所有用户都需等待上一个用户释放锁。因此,我们需要针对不同场景考虑不同的加锁策略。
/** 独占锁 */
@Override
public String createOrderByLock(OrderAggregate orderAggregate) {
RLock lock = redissonService.getLock("create_order_lock_".concat(orderAggregate.getSkuEntity().getSku()));
try {
lock.lock();
long decrCount = redissonService.decr(orderAggregate.getSkuEntity().getSku());
if (decrCount < 0) return "已无库存[初始化的库存和使用库存,保持一致。orderService.initSkuCount(\"13811216\", 10000);]";
return createOrder(orderAggregate);
} finally {
lock.unlock();
}
}
/** 分段锁,也可以称为无锁化 */
@Override
public String createOrderByNoLock(OrderAggregate orderAggregate) {
UserEntity userEntity = orderAggregate.getUserEntity();
SKUEntity skuEntity = orderAggregate.getSkuEntity();
// 模拟锁商品库存
long decrCount = redissonService.decr(skuEntity.getSku());
if (decrCount < 0) return "已无库存[初始化的库存和使用库存,保持一致。orderService.initSkuCount(\"13811216\", 10000);]";
String lockKey = skuEntity.getSku().concat("_").concat(String.valueOf(decrCount));
RLock lock = redissonService.getLock(lockKey);
try {
lock.lock();
return createOrder(orderAggregate);
} finally {
lock.unlock();
}
}
1. 独占锁
对于第一类场景——独占锁,主要是为了避免用户在一次操作后反复提交申请。系统通过加锁的方式进行防重拦截。如果不加锁,则会进入数据库通过唯一索引拦截,这会给数据库带来较大压力。
上述代码为每个商品 SKU 分配一把锁,锁名格式为 create_order_lock_商品编号。通过 lock.lock() 上锁,其他人看到锁被占用则等待。在持有锁期间,原子性地通过 decr 扣减库存。如果库存扣为负数,说明无货;否则,执行创建订单的逻辑。最后在 finally 块中释放锁,确保不会发生死锁。
假设没有锁会怎样呢?在高并发下,两个用户可能同时查询到库存为1,都判断为可用,先后执行扣减,导致库存变为-1,发生超卖。
时间 | 用户A | 用户B | 库存
--------------------------------------------------
1秒 | 查看库存=1 | | 1
2秒 | 判断够用✓ | 查看库存=1 | 1
3秒 | 扣库存 1-1=0 | 判断够用✓ | 0
4秒 | 创建订单成功 | 扣库存 0-1=-1 | -1 ❌超卖了!
5秒 | 完成 | 创建订单成功 | -1 ❌卖了2个
使用了独占锁之后,流程变为串行,保证了安全性:
时间 | 用户A | 用户B | 库存
--------------------------------------------------
1秒 | 拿到锁🔒 | | 1
2秒 | 扣库存 1-1=0 | 尝试拿锁(等待) | 0
3秒 | 创建订单成功 | 还在等待... | 0
4秒 | 释放锁🔓 | 拿到锁🔒 | 0
5秒 | 完成 | 扣库存 0-1=-1 | -1
6秒 | | 发现<0,返回无库存| -1
7秒 | | 释放锁🔓 | -1 ✓ 没有超卖
独占锁的设计核心是:一个资源一把锁、先来先得、锁内操作原子性、防止超卖、必须释放。
然而,对于像库存秒杀这样的高资源竞争场景,独占锁存在严重性能问题。如果一万个用户抢购100台iPhone,所有人都竞争同一把锁 create_order_lock_iPhone15,那么处理过程将完全串行化。最后一个用户可能需要等待近50秒,系统吞吐量极低,服务器资源大量空闲。问题的根源在于资源高度竞争下的完全串行。
2. 分段锁(无锁化设计)
对于第二类高资源竞争场景——分段锁,采用了分段或自增滑块的锁方式进行处理。它减少了用户对同一把锁的等待,而是生成一组锁供用户使用。
long decrCount = redissonService.decr(skuEntity.getSku()); 这行代码是整个设计的灵魂。decr 是 Redis 的原子操作,它保证了即使在极高并发下,每个用户调用后得到的递减返回值 (decrCount) 也是不同的、唯一的。这相当于给每个并发用户发了一个唯一的“号码牌”。
Redis执行过程(原子性,不可打断):
时刻1: 库存 = 100
↓ 用户1调用decr
执行:100 - 1 = 99
返回:99
时刻2: 库存 = 99
↓ 用户2调用decr(和用户1几乎同时)
执行:99 - 1 = 98
返回:98
...
紧接着,if (decrCount < 0) return "已无库存" 检查是否超卖。当库存递减到0后,后续用户拿到的 decrCount 为负数,直接返回,天然防止了超卖,且不需要额外的锁来保护这个检查逻辑。
然后,利用这个唯一的 decrCount 值来构造唯一的锁Key:
String lockKey = skuEntity.getSku().concat("_").concat(String.valueOf(decrCount));
例如,用户1拿到99,锁Key为 "iPhone15_99";用户2拿到98,锁Key为 "iPhone15_98"。这样,一万个并发用户可能对应一万个不同的锁Key。
因为每个人的锁Key不同,所以后续的 lock.lock() 操作几乎不存在竞争。每个用户都是在锁自己独有的那把锁,可以瞬间成功,从而实现了高度的并发执行。
核心原理:先通过原子操作 decr “占座”(分配唯一标识),再基于这个标识去处理后续非竞争性的业务(如创建订单)。将真正的竞争点(库存扣减)用原子操作无锁化,而将非竞争点(订单创建)用细粒度锁隔离,从用户视角看,系统就像是“无锁”的。
- 原理一:原子操作 + 分段锁 = 无竞争并发。传统思路是用锁保护整个流程(扣库存+业务),导致串行化;新思路是仅用原子操作解决互斥资源(库存)竞争,业务处理部分则可并发。
- 原理二:空间换时间。独占锁是1把锁串行,时间复杂度O(N);分段锁是N把锁并行,时间复杂度O(1),牺牲了少量空间(多创建了锁对象)换来了巨大的性能提升。
- 原理三:锁的粒度细化。锁的粒度越细,冲突概率越低,并发度越高。从锁整个商品 (
iPhone15) 细化到锁商品的一个具体库存位置 (iPhone15_99),冲突概率从100%降到了0%。
五、发布/订阅与动态注入
此场景的案例涉及如何向 Spring 动态注入已经实例化后的 Bean 对象。为什么需要这个?因为 Redis 的发布订阅如果全部硬编码,会非常繁琐。
1. 自定义注解
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.TYPE})
@Documented
public @interface RedisTopic {
String topic() default "";
}
2. 注解的使用
@Slf4j
@Service
@RedisTopic(topic = "testRedisTopic02")
public class RedisTopicListener02 implements MessageListener<String> {
@Override
public void onMessage(CharSequence channel, String msg) {
log.info("02-监听消息(Redis 发布/订阅): {}", msg);
}
}
对需要监听 Redis Topic 的类,只需添加 @RedisTopic 注解并指定 topic 名称即可。
3. 动态注入与自动监听
核心逻辑在之前展示的 RedisClientConfig.redissonClient() 方法中。它通过 applicationContext.getBeanNamesForType(MessageListener.class) 获取所有监听器 Bean,利用反射检查其类上是否有 @RedisTopic 注解。如果有,则根据注解中的 topic 名称从 Redisson 获取 Topic 对象,添加该 Bean 作为监听器,并最终通过 beanFactory.registerSingleton() 将这个 Topic 对象也动态注册到 Spring 容器中。
// 代码片段:动态扫描、注册监听器并注入Topic Bean
String[] beanNamesForType = applicationContext.getBeanNamesForType(MessageListener.class);
for (String beanName : beanNamesForType) {
MessageListener bean = applicationContext.getBean(beanName, MessageListener.class);
Class<? extends MessageListener> beanClass = bean.getClass();
if (beanClass.isAnnotationPresent(RedisTopic.class)) {
RedisTopic redisTopic = beanClass.getAnnotation(RedisTopic.class);
// 根据注解配置获取Topic并添加监听
RTopic topic = redissonClient.getTopic(redisTopic.topic());
topic.addListener(String.class, bean);
// 将Topic对象本身也注册为Spring Bean,便于注入使用
ConfigurableListableBeanFactory beanFactory = applicationContext.getBeanFactory();
beanFactory.registerSingleton(redisTopic.topic(), topic);
}
}
这段代码的精髓在于反射 + 注解 + Spring 容器操作的融合,实现了声明式的监听器注册和依赖注入。
4. 使用注入的Topic对象
@Slf4j
@Repository
public class OrderRepository implements IOrderRepository {
@Resource
private IRedisService redissonService;
@Resource
private IUserOrderDao userOrderDao;
@Resource
private RTopic testRedisTopic; // 硬编码创建的Bean
@Resource(name = "testRedisTopic02") // 动态注入的Bean
private RTopic testRedisTopic02;
@Resource(name = "testRedisTopic03")
private RTopic testRedisTopic03;
@Override
public String createOrder(OrderAggregate orderAggregate) {
// ... 订单创建逻辑
// 发布消息到多个Topic
testRedisTopic02.publish(JSON.toJSONString(orderEntity));
testRedisTopic03.publish(JSON.toJSONString(orderEntity));
return orderId;
}
}
在业务代码中,可以直接 @Resource 注入这些 Topic Bean(无论是硬编码还是动态创建的),并调用 publish 方法发布消息,监听器会自动收到消息。
六、功能测试
1. 分布式锁压测
@Test
public void test_createOrder() throws InterruptedException {
String sku = RandomStringUtils.randomNumeric(9);
int count = 10000;
orderService.initSkuCount(sku, count);
for (int i = 0; i < count; i++) {
threadPoolExecutor.execute(() -> {
// ... 构造订单聚合根参数
long threadBeginTime = System.currentTimeMillis(); // 记录线程开始时间
// 耗时:4毫秒
// String orderId = orderService.createOrder(new OrderAggregate(userEntity, skuEntity, deviceVO));
// 耗时:106毫秒
// String orderId = orderService.createOrderByLock(new OrderAggregate(userEntity, skuEntity, deviceVO));
// 耗时:4毫秒
String orderId = orderService.createOrderByNoLock(new OrderAggregate(userEntity, skuEntity, deviceVO));
long took = System.currentTimeMillis() - threadBeginTime;
totalExecutionTime.addAndGet(took); // 累加线程耗时
log.info("写入完成 {} 耗时 {} (ms)", orderId, took / 1000);
});
}
// ... 等待任务完成并输出总耗时
}
测试前,需修改 count 值以初始化库存容量。压测对比三种方式:
createOrder: 不使用锁(仅作基础性能参照)。createOrderByLock: 使用独占锁,耗时显著增加。createOrderByNoLock: 使用分段锁(无锁化设计),耗时接近直接操作,性能最优。
测试过程中,控制台也会打印出监听器收到的订阅消息。
2. 其他功能测试示例(延迟队列)
本文还提供了读写锁、异步锁、信号量、队列等功能的测试。以下是延迟队列的测试示例:
/**
* 延迟队列场景应用
*/
@Test
public void test_getDelayedQueue() throws InterruptedException {
RBlockingQueue<Object> blockingQueue = redissonService.getBlockingQueue("xfg-dev-tech-task");
RDelayedQueue<Object> delayedQueue = redissonService.getDelayedQueue(blockingQueue);
new Thread(() -> {
try {
while (true){
Object take = blockingQueue.take();
log.info("测试结果 {}", take);
Thread.sleep(10);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
int i = 0;
while (true){
delayedQueue.offerAsync("测试" + ++i, 100L, TimeUnit.MILLISECONDS);
Thread.sleep(1000L);
}
}
通过一个完整的 DDD 订单场景,我们实践了 Redis 在数据缓存、分布式锁(独占锁与分段锁)以及发布/订阅等核心功能。特别是分段锁(无锁化)的设计思想,通过原子操作和锁粒度细化,巧妙地在保证数据一致性的前提下,极大地提升了系统在高并发资源竞争场景下的吞吐量。而利用自定义注解和 Spring 容器管理实现 Redis 监听器的动态注册与 Topic Bean 的注入,则展示了如何优雅地集成和扩展第三方组件,提升代码的可维护性。希望这些实践对你在 云栈社区 中的技术设计与开发有所启发。
 发表于 2026-4-11 03:18:24
|
查看: 142|
回复: 0
发表于 2026-4-11 03:18:24
|
查看: 142|
回复: 0
