“QLib 量化投资平台的实战系列,参考官方代码,设计新的应用场景,手把手带你玩转Qlib”

本文将通过一个完整的案例,演示如何使用 Qlib 平台构建并回测一个港股市场的 AI 选股策略。大纲如下:
- 环境和安装
- 数据准备
- 日频量价因子生成
- 绩效分析
🔧 Qlib安装与环境配置
Qlib的安装可能是新手遇到的第一个“坑”。官方教程有时会绕过一些实际部署中的细节。以下步骤基于实操经验,建议初学者按顺序执行。
📊 数据准备:自定义港股数据
Qlib 支持官方测试数据和用户自定义数据。为了贴近实战,我们使用自定义的港股日频数据。核心步骤是将 CSV 格式的原始数据,通过 dump_all 指令转换为 Qlib 内部的二进制格式。
为何选择港股通标的? 港股市场结构集中,头部公司主导,且存在大量低流动性“仙股”。港股通标的覆盖了总市值约85%、成交额超90%的公司,代表性更强,数据质量也相对更好。
提示:港股通标的名单会定期调整,最新列表需从港交所官网获取。
步骤 1:准备 CSV 数据格式
你需要为每只股票准备一个独立的 CSV 文件。将所有文件放入一个文件夹,例如命名为 hk_data。文件名应为股票代码,例如 HK00700.csv(腾讯控股)。
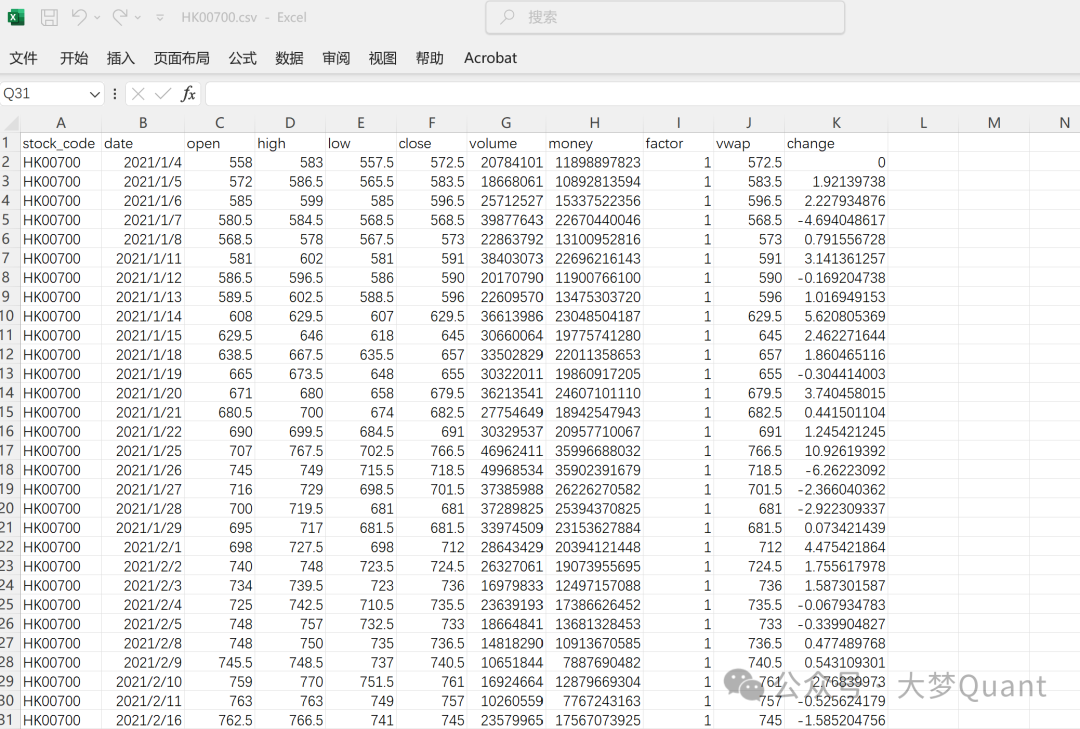
每个 CSV 文件必须包含以下字段:
| 字段名称 |
说明 |
注意事项 |
stock_code |
股票代码(与文件名一致) |
示例:"HK00700" |
date |
日频日期 |
格式:"2020-01-02" |
open/high/low/close |
复权价格 |
必须使用复权价(推荐后复权) |
volume |
成交量 |
单位:股 |
money |
成交额 |
单位:港元 |
factor |
复权因子 |
无复权时填 1.0 |
vwap |
复权均价 |
计算公式:(成交额 / 成交量) |
change |
涨跌幅(%) |
相对于前一交易日 |
特别注意两个“坑”:
- 必须使用复权价格:否则回测时的收益计算会严重失准。
- 必须有
factor 或 change 字段:否则策略净值可能出现异常(官方文档未明确说明,实操中遇到的坑)。
数据示例如下(Excel视图):
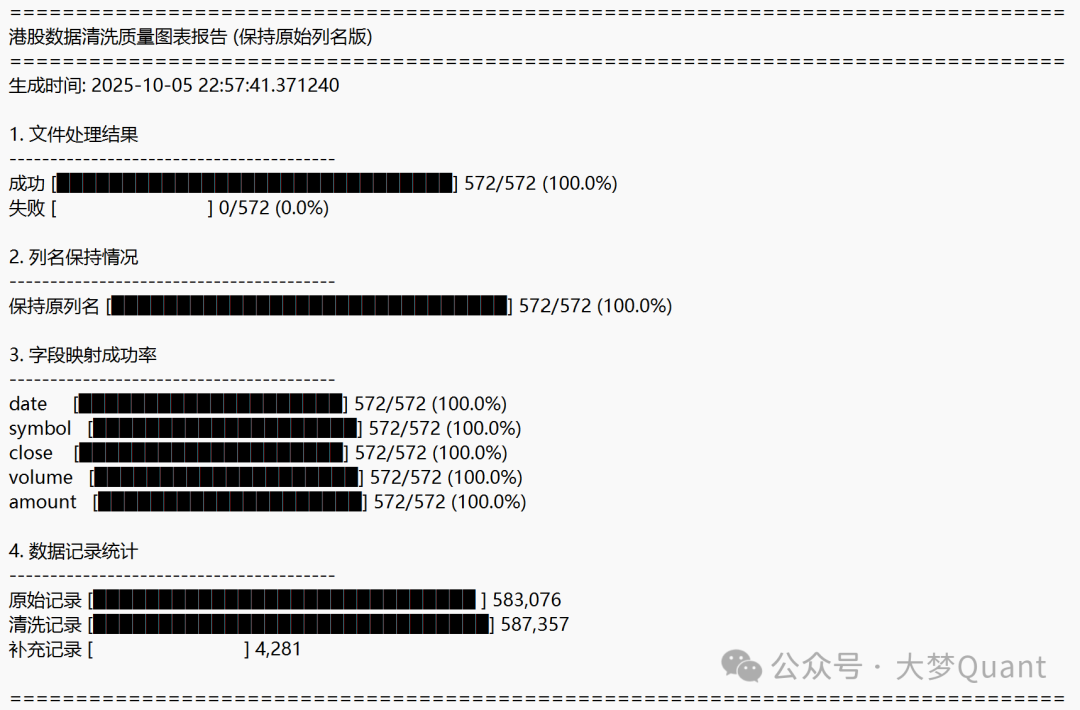
步骤 2:数据清洗(可选但推荐)
如果你的数据源非常可靠,此步骤可以忽略。但对于来自网络或API的数据,清洗至关重要。Qlib为A股提供了标准的清洗脚本,对于港股,我们可以借鉴其思路编写自定义脚本。
一个完善的清洗流程应包括:基于指数数据生成交易日历、缺失值填充、异常值修正(如价格跳变)、以及最终的数据完整性校验。这能有效解决原始数据中“错、漏、杂”的问题。
例如,以下是一个清洗脚本运行后生成的质检报告摘要:
步骤 3:使用 dump_all 转换数据格式
运行以下命令,将 hk_data 文件夹中的 CSV 数据转换为 Qlib 的二进制格式。
python scripts/dump_bin.py dump_all \
--data_path ./qlib/data/csv_data/hk_data \ # 你的CSV数据路径
--qlib_dir ./qlib/data/hk_data \ # 转换后的数据保存路径
--symbol_field_name stock_code \ # CSV中股票代码的列名
--date_field_name date \ # CSV中日期的列名
--include_fields open,high,low,close,volume,money,factor,vwap,change # 包含的字段(逗号后无空格!)
转换成功后,目标目录(本例中为 ./qlib/data/hk_data)下会生成三个子文件夹:
calendar/day.txt:港股交易日历。features/:二进制格式的行情数据(例如 open.day.bin)。instruments/all.txt:所有股票代码列表。
步骤 4:数据健康度检查
在投入实战前,强烈建议进行数据健康度检查。
python scripts/check_data_health.py check_data --qlib_dir ./qlib/qlib/data/hk_data
检查报告可能会提示缺失值或数据跳变。这通常是正常现象。例如,缺失值很可能是由于股票停牌;价格跳变则可能源于除权除息或重大市场事件。
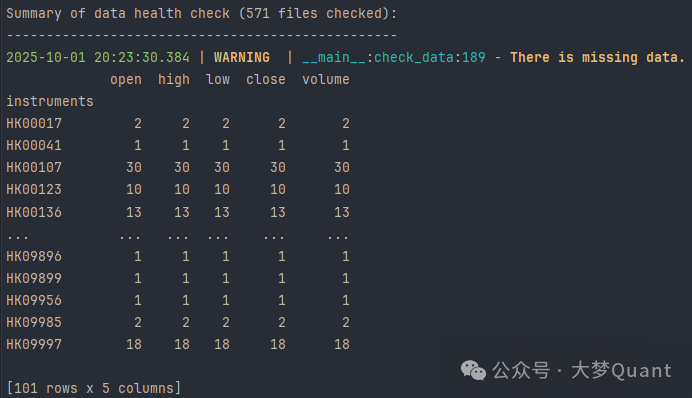
以报告提示有2行数据缺失的 HK00017 为例,查询港交所公告可以发现,该股票在相应时间段内确实有过停牌记录。因此,这类缺失属于正常情况。关键在于,在后续构建策略时,要合理利用 Qlib 提供的缺失值处理机制,最大限度地降低其对模型的干扰。
⚡ 港股日频量价因子AI策略实战
下面这个完整的脚本,清晰地展示了 Qlib 量化研究的标准流程:从数据准备、模型配置、训练到回测与绩效分析。每一个环节都紧密相连。
策略核心配置:
- 因子模型:Alpha158(提供158个量价因子)
- 预测模型:LightGBM
- 交易策略:TopK Dropout(每日持有 top K 只股票,并淘汰最差的 N 只)
- 初始资金:200,000 HKD
- 回测周期:2024-01-01 至 2025-09-29
- 基准指数:恒生指数 (HSI)
"""
港股Alpha158因子策略测试脚本
本脚本实现了一个完整的量化交易策略测试流程:
1. 数据准备:使用Alpha158因子处理港股数据
2. 模型训练:使用LightGBM模型进行因子预测
3. 回测执行:使用TopKDropout策略进行投资组合回测
4. 绩效分析:计算并展示策略的绩效指标
注意:需要提前准备好港股数据文件
"""
import qlib
import pandas as pd
from qlib.data import D
from qlib.contrib.data.handler import Alpha158
import time
from qlib.utils import init_instance_by_config
from qlib.workflow import R
from qlib.contrib.evaluate import risk_analysis
from qlib.workflow.record_temp import SignalRecord, PortAnaRecord
from qlib.contrib.report import analysis_position
import os
import webbrowser
from plotly.offline import plot
# 初始化港股数据环境
qlib.init(provider_uri="D:/DM_Project/DM_QuantBox_V3.0_Qlib/qlib/qlib/data/cleaned_hk_data")
# 生成股票池
instruments = D.instruments(market="all")
if __name__ == '__main__':
# ==================== 第一阶段:数据准备 ====================
# 配置Alpha158因子处理器参数
data_handler_config = {
"instruments": instruments, # 股票池:港股通标的
"start_time": "2017-01-01", # 数据开始时间
"end_time": "2025-09-30", # 数据结束时间
"fit_start_time": "2017-01-01", # 模型训练数据开始时间
"fit_end_time": "2021-01-31" # 模型训练数据结束时间
}
# 初始化Alpha158因子处理器
h = Alpha158(**data_handler_config)
# 提取因子特征和标签数据
factors = h.fetch(col_set="feature") # 158个Alpha因子特征
labels = h.fetch(col_set="label") # 标签:t+2日收益率(t日发信号,t+1开仓,t+2平仓)
# ==================== 第二阶段:模型配置 ====================
# 配置LightGBM模型和数据集
task = {
"model": {
"class": "LGBModel", # 使用LightGBM模型
"module_path": "qlib.contrib.model.gbdt",
"kwargs": {
"loss": "mse", # 均方误差损失函数
"colsample_bytree": 0.8879, # 特征采样比例
"learning_rate": 0.0421, # 学习率
"subsample": 0.8789, # 样本采样比例
"lambda_l1": 205.6999, # L1正则化系数
"lambda_l2": 580.9768, # L2正则化系数
"max_depth": 8, # 树的最大深度
"num_leaves": 210, # 叶子节点数量
"num_threads": 20 # 并行线程数
}
},
"dataset": {
"class": "DatasetH",
"module_path": "qlib.data.dataset",
"kwargs": {
"handler": h, # 使用Alpha158因子处理器
"segments": {
"train": ("2017-01-01", "2021-01-31"), # 训练集:2017-2021年
"valid": ("2021-02-01", "2023-12-31"), # 验证集:2021-2023年
"test": ("2024-01-01", "2025-09-30") # 测试集:2024-2025年9月
}
}
}
}
# 初始化模型和数据集实例
model = init_instance_by_config(task["model"])
dataset = init_instance_by_config(task["dataset"])
# ==================== 第三阶段:模型训练 ====================
# 记录训练开始时间
t_start = time.time()
# 启动实验记录器
with R.start(experiment_name="hk_lgb_strategy"):
# 训练模型
model.fit(dataset)
# 保存训练好的模型
R.save_objects(model=model)
# 获取实验ID用于后续回测
exp_id = R.get_recorder().id
# ==================== 第四阶段:回测配置 ====================
# 配置投资组合分析参数
port_analysis_config = {
"strategy": {
"class": "TopkDropoutStrategy", # 使用TopK淘汰策略
"module_path": "qlib.contrib.strategy.signal_strategy",
"kwargs": {
"signal": "<PRED>", # 使用模型预测信号
"topk": 5, # 每日持仓5只股票
"n_drop": 2 # 每日淘汰2只表现最差的股票
}
},
"backtest": {
"start_time": "2024-01-01", # 回测开始时间:测试集开始
"end_time": "2025-09-29", # 回测结束时间:提前一天避免索引越界
"account": 200000, # 初始资金:20W港元
"benchmark": "HSI", # 基准指数:恒生指数
"exchange_kwargs": {
"limit_threshold": None, # 港股无涨跌停限制
"deal_price": "close", # 以收盘价成交
"open_cost": 0.0015, # 开仓手续费率:0.15%
"close_cost": 0.0015, # 平仓手续费率:0.15%
"min_cost": 20 # 最低交易费用:20港元
}
}
}
# ==================== 第五阶段:信号生成和回测 ====================
# 获取实验记录器
recorder = R.get_recorder(experiment_name="hk_lgb_strategy")
# 生成交易信号
sr = SignalRecord(model, dataset, recorder)
sr.generate()
# 加载预测结果并更新策略配置
pred = recorder.load_object("pred.pkl")
port_analysis_config["strategy"]["kwargs"]["signal"] = pred
# 执行回测并生成绩效分析
par = PortAnaRecord(recorder, config=port_analysis_config)
par.generate()
# ==================== 第六阶段:结果展示 ====================
# 加载并展示回测绩效报告
report = recorder.load_object("portfolio_analysis/report_normal_1day.pkl")
print("=" * 60)
print("港股Alpha158因子策略回测结果(2024.01-2025.09)")
print("=" * 60)
print(risk_analysis(report))
print("=" * 60)
# 绘制IC/Rank IC图
label = dataset.prepare("test", col_set="label")
label.columns = ["label"]
pred_label = pd.concat([label, pred], axis=1, sort=True).reindex(label.index)
# 生成IC图表并保存
ic_fig = analysis_position.score_ic_graph(pred_label, show_notebook=False)[0]
ic_html_path = os.path.abspath("ic_graph.html")
plot(ic_fig, filename=ic_html_path, auto_open=False)
print(f"IC图表已保存至: {ic_html_path}")
# 生成报告图表并保存
report_fig = analysis_position.report_graph(report, show_notebook=False)[0]
report_html_path = os.path.abspath("report_graph.html")
plot(report_fig, filename=report_html_path, auto_open=False)
print(f"报告图表已保存至: {report_html_path}")
# 在默认浏览器中打开图表
webbrowser.open(f"file://{report_html_path}")
webbrowser.open(f"file://{ic_html_path}")
# 计算并显示总运行时间
t_end = time.time()
print(f"总运行时间: {t_end - t_start:.2f} 秒")
说明:以上为完整代码。原文中提到“代码只能显示为一行”,此处已正确格式化为多行代码块,便于阅读和复制。
📊 结果可视化与绩效分析
脚本运行完毕后,会自动在浏览器中打开两份图表:report_graph.html(综合绩效报告)和 ic_graph.html(IC分析图)。
1. 综合绩效报告
这份报告包含多组子图,是评估策略的核心:
- 累计收益率曲线:策略净值 vs 基准净值。
- 滚动最大回撤曲线:展示历史上任一时刻开始可能发生的最大亏损。
- 超额收益率曲线:策略收益超越基准的部分。
- 换手率序列:反映策略的交易频率。
- 超额收益回撤曲线:专门观察超额收益的回落情况。
在本案例的回测周期(2024/01/01 ~ 2025/09/29)内,该策略的累计收益率达到了约81%。图中可以清晰看到,最大回撤发生在2025年4月初,这与当时市场的特定事件相吻合。
2. IC (Information Coefficient) 分析图
IC值衡量了模型预测(因子)与未来实际收益率之间的相关性,是判断因子预测能力的关键指标。
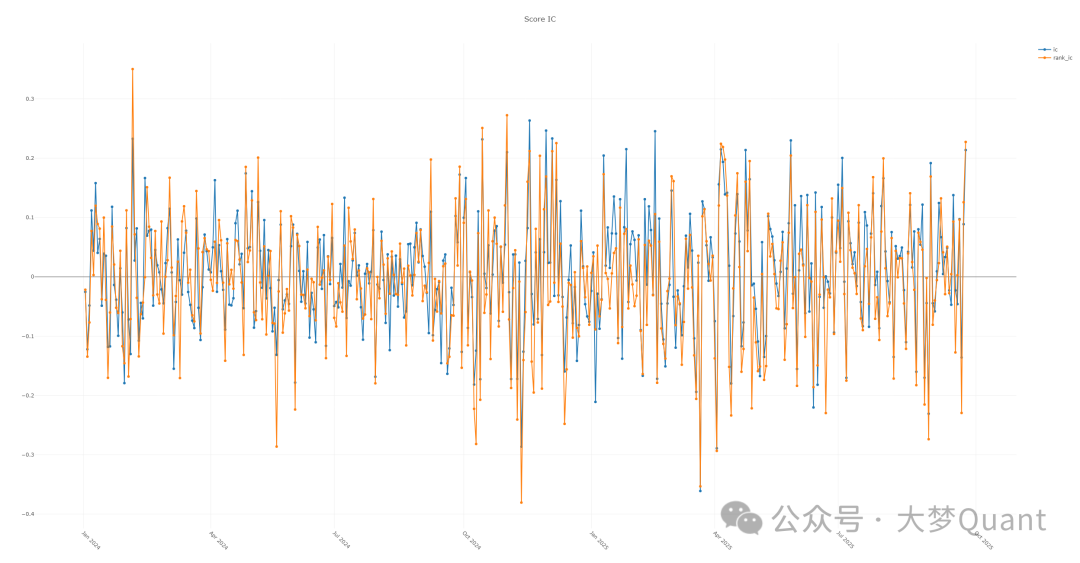
参考标准:IC均值大于0.05通常认为因子具有预测能力。本例中,IC均值约为0.08,Rank IC均值约为0.09,表明所使用的Alpha158因子在港股测试集上具有一定的选股能力。
📚 总结与思考
本次实战演示了从零开始,利用 Qlib 平台构建一个港股AI选股策略的全过程。其中,数据准备是基石,特别是数据格式、复权处理和清洗校验;模型与回测配置是核心,需要根据市场特点(如港股无涨跌停)调整参数。
一个有趣的发现是:本策略使用2017年至2021年的数据训练,却在2024年至2025年的测试集上取得了不错的效果。这或许暗示着这两个时间段的市场逻辑存在某种相似性,例如可能都处于由估值修复、资金流向驱动的市场阶段。
当然,任何量化模型都是对历史规律的总结。市场风格会切换,消息面冲击无法预测。因此,这个策略案例更重要的价值在于提供了一套可复现、可迭代的研究框架。你可以尝试更换因子集、调整模型参数、或者引入新的数据处理方法,在 云栈社区 与更多开发者交流想法,不断优化属于你自己的量化策略。
记住,回测表现不代表未来收益,实战中务必谨慎,做好风险控制。

 发表于 2026-4-11 08:35:58
|
查看: 736|
回复: 0
发表于 2026-4-11 08:35:58
|
查看: 736|
回复: 0