Andrej Karpathy 有个挺有意思的习惯:他习惯把论文、推文、截图、笔记随手丢进一个名为 /raw 的文件夹里。而 graphify 这个工具,就像是专门为这种使用模式量身定做的——你在 Claude Code 里输入 /graphify .,它就能读取你的文件,构建出一张知识图谱,帮你发现那些原本隐藏在文件之间、你未曾察觉的关联。
说实话,“知识图谱 + AI”这个方向的项目并不少,但大多数方案要么只在推理阶段做 RAG,要么简单粗暴地把所有文件内容都丢给大语言模型(LLM)处理。graphify 的做法则有些不同:它对代码文件使用 tree-sitter 进行 AST(抽象语法树)提取,这个过程是完全确定性的,不消耗任何 LLM 的 Token。只有文档、论文、图片这类非结构化内容,才会交给 Claude 进行语义提取。读完源码后,我觉得这种工程上的取舍做得很务实。
graphify 能做什么?
它的输入可以是任意文件夹,输出则是三个核心文件:
graph.html —— 一个可交互的知识图谱可视化界面,支持点击节点、搜索、按社区筛选。GRAPH_REPORT.md —— 一份纯文本的审计报告,会列出图中的“核心节点 (God Nodes)”、“意外关联 (Surprising Connections)”以及“建议进一步分析的问题”。graph.json —— 持久化的图谱数据文件。几周后你想再查询时,直接读这个文件就行,无需重新处理原始文件,实现了“长期记忆”。
工具支持超过 20 种编程语言(包括 Python、JS/TS、Go、Rust、Java、C/C++、Ruby、C#、Kotlin、Swift 等),对于文档、PDF、截图、甚至包含其他语言文本的图片,它都能处理。
安装很简单:
pip install graphifyy && graphify install
注意 PyPI 上的包名是 graphifyy(双 y),很容易打错。安装完成后,在你的项目根目录输入 /graphify . 即可开始分析。
核心:两阶段提取架构
graphify 的核心设计在于 “确定性提取 + 语义推断” 的双通道处理流程。
第一阶段,基于 tree-sitter 的 AST 遍历,完全不依赖 LLM。它从代码文件中提取类、函数、import 关系、调用图、文档字符串(docstring),以及以 # NOTE:、# WHY: 等特殊标记的设计注释。这一步是确定性的,同样的输入永远产生同样的节点和边,这些边会被标记为 EXTRACTED。
第二阶段,Claude 子代理并行处理非代码文件。文档、论文、截图中的概念和关系被提取出来,形成的边会被标记为 INFERRED(并附带一个 0-1 的置信度分数)或 AMBIGUOUS(需要人工审查)。
两个阶段的结果会被合并到一个 NetworkX 图数据结构中,然后使用 Leiden 算法进行社区检测,最终导出 HTML、JSON 和报告文件。
它的聚类完全基于图的拓扑结构,不需要向量嵌入。因为 Claude 提取出的语义相似边(例如 semantically_similar_to)已经作为边存在于图中,直接参与了社区划分。图结构本身就成了衡量相似度的信号——省去了单独的嵌入(embedding)步骤和向量数据库。
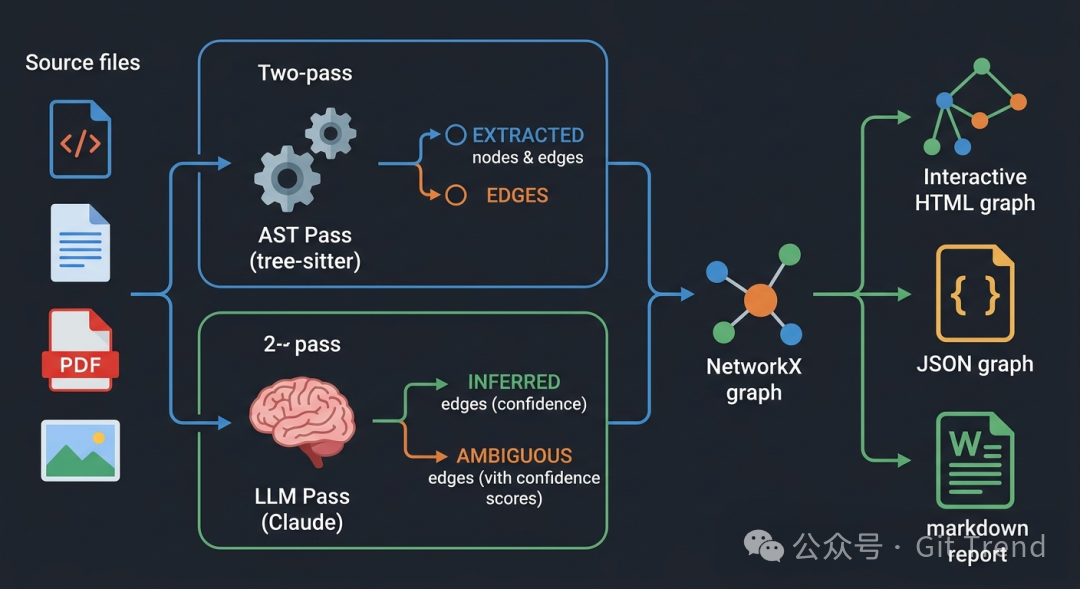
graphify 完整的数据处理管线:两阶段提取、社区检测与三种输出格式
贯穿始终的“诚实审计”
这是 graphify 与多数 GraphRAG 方案的一个关键区别:它为图谱中的每一条边都明确标注了来源。这条设计原则贯穿了整个项目:
EXTRACTED:直接从源代码或文件中发现的确定性关系,置信度为 1.0。INFERRED:基于语义的合理推理,附带 confidence_score。AMBIGUOUS:信号较弱,被标记为需要人工审查的关系。
你始终能清楚地区分哪些是事实,哪些是模型的猜测。例如,调用图边从 AST 直接解析,标记为 EXTRACTED;跨文件的语义关联由 LLM 推理得出,则标记为 INFERRED/0.7。绝不混为一谈。
报告中的“意外关联 (Surprising Connections)”功能也体现了这一思路:它会将跨社区的连接按复合分数排序,像“代码-论文”这类跨模态的边会比“代码-代码”边排名更高,并且每条结果都附有一段自然语言解释,说明“为什么认为它们相关”。
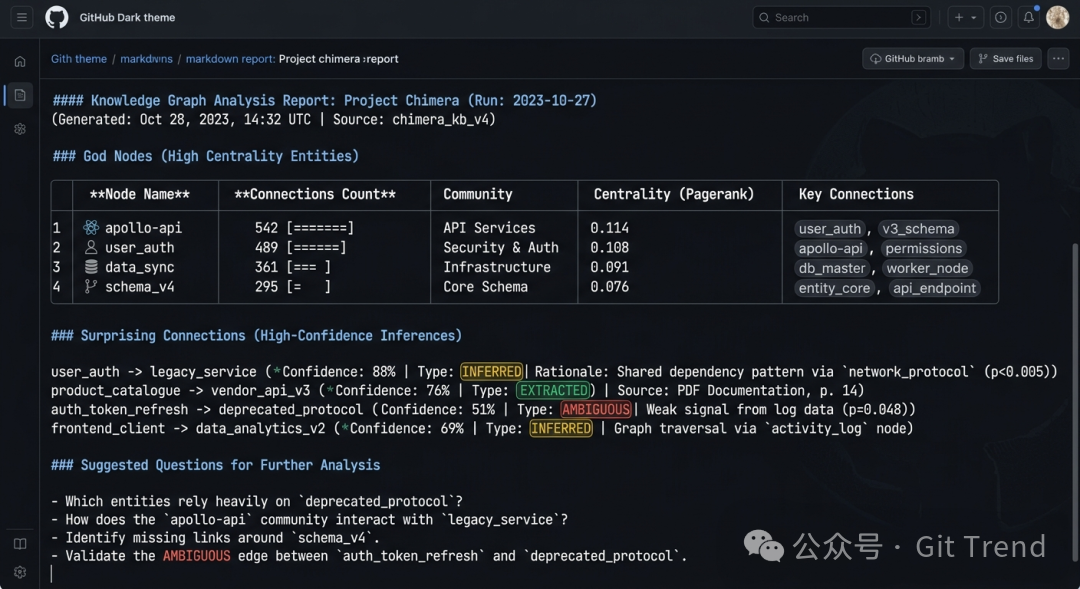
GRAPH_REPORT.md 的典型内容:核心节点列表、高置信度的意外关联及其详细标注
高达 71.5 倍的 Token 压缩效率
graphify 每次运行结束后会自动打印 Token 消耗对比。在一个混合了 Karpathy 的代码仓库、5 篇论文和 4 张图片的语料库(共 52 个文件)上测试,实现了 71.5 倍 的 Token 节省。
原理很简单:第一次运行需要消耗 Token 来提取信息并构建图谱,但之后的所有查询都直接读取压缩后的图谱文件,而非原始文件。SHA256 缓存机制确保了重新运行时只处理变更过的文件,你可以使用 --update 参数进行增量更新。
对于只有 6 个文件的小项目,压缩比可能接近 1:1,此时图谱的价值更多体现在对代码结构的清晰呈现上。而对于 50 个文件以上的混合型大项目,graphify 在效率上的优势才会真正凸显——项目规模越大,使用它越划算。
覆盖九大 AI 编程助手平台
这一点令人颇感意外。graphify 并非只能安装到某一个 AI 助手中——它支持 Claude Code、Codex、OpenCode、Cursor、Gemini CLI、OpenClaw、Factory Droid、Trae 等八个平台,并为每个平台准备了独立的技能(skill)文件和安装逻辑。
更重要的是,这里的“安装”不是简单复制一段提示词就完事。以 Claude Code 为例,graphify claude install 会做两件事:
- 向
CLAUDE.md 写入一条规则,告诉 Claude 在回答架构类问题前,先阅读 GRAPH_REPORT.md。
- 向
settings.json 安装一个 PreToolUse 钩子(hook)——每次你触发文件全局搜索(Glob)或内容检索(Grep)时,如果图谱存在,Claude 会先看到提示:“graphify: Knowledge graph exists. Read GRAPH_REPORT.md for god nodes and community structure before searching raw files.”
为 Codex 安装的是 Bash 工具的 PreToolUse 钩子,为 OpenCode 安装的是 tool.execute.before 插件,为 Cursor 则是在 .cursor/rules 中写入规则并设为 alwaysApply,Gemini CLI 用的是 BeforeTool 钩子。每个平台都使用了其原生的拦截机制,适配得非常到位。
此外,它还支持 Git hooks:运行 graphify hook install 可以安装 post-commit 和 post-checkout 钩子,这样每次提交代码或切换分支后,都会自动重建图谱(代码文件走快速的 AST 解析,无需调用 LLM)。

graphify 目前已支持的八个主流 AI 编程助手平台
几个实用的功能亮点
命令行直接查询图谱,无需通过 AI 助手:
graphify query “auth flow 是怎么走的” --dfs
graphify path “DigestAuth” “Response”
graphify explain “SwinTransformer”
query 命令支持 BFS(广度优先搜索,适合了解上下文)和 DFS(深度优先搜索,适合追踪特定路径),还可以用 --budget 参数限制输出的 Token 数量。
内置 MCP 服务器,让 AI 助手能够直接对图谱进行结构化查询:
python -m graphify.serve graphify-out/graph.json
这会暴露 7 个工具:query_graph、get_node、get_neighbors、get_community、god_nodes、graph_stats、shortest_path。
Watch 模式:可以在后台运行,监控文件变动。代码文件改动会即时触发 AST 重建(无 LLM 消耗),文档或图片改动则会提示你手动执行 --update。
Obsidian 库导出:使用 --obsidian 参数,可以为图谱中的每个社区生成一篇 Markdown 文章,并附带一个 index.md 入口文件,你可以直接将其导入已有的 Obsidian 知识库。
对于 Neo4j 用户,可以导出 Cypher 脚本或直接将图谱推送到运行中的 Neo4j 实例。
它适合你吗?一些使用建议
如果是我来用,我会首先在刚接手的陌生项目上运行一遍 graphify,通过“核心节点 (God Nodes)”和社区划分来快速把握项目骨架——这比盲目翻阅文件要高效得多。
graphify 尤其适合以下几类场景:
- 快速接手新代码库:先跑一遍图谱,直观了解核心模块和架构分区。
- 维护混合知识库:当你的项目混杂了论文、笔记和代码时,图谱能帮你发现文本与代码之间的隐性关联。
- 大型项目的日常导航:安装 always-on hook 后,AI 助手在每次执行搜索前都会先查看图谱摘要,减少盲目
grep 带来的上下文缺失。
当然,也有一些需要注意的地方:
- 首次运行成本:语义提取依赖 LLM API 调用,首次运行有成本,文档和图片越多越贵。不过代码文件的处理是免费的(走 AST)。
- 包名易错:PyPI 包名
graphifyy 是双 y,安装时需留意。
- 对小项目效果有限:社区检测的质量依赖于图中边的密度,文件太少(例如少于 10 个)时,效果可能不明显。
- 项目迭代迅速:它在 2026 年 4 月初进行了密集迭代,两天内发布了十多个版本(修复了 Windows 兼容性、NetworkX 版本适配等问题),API 可能处于快速变化期。
总的来说,graphify 正处于一个快速成熟的阶段。如果你经常使用 Claude Code 或其他它支持的编程助手,并且日常工作中需要处理跨文件、跨文档的理解任务,那么这个工具值得你花时间尝试一下。它的设计理念,尤其是将确定性提取与概率推断明确分离的思路,对于构建可靠、可解释的AI辅助工具很有启发。更多类似的开源实战工具和深度解析,你可以在 云栈社区 找到。
 发表于 2026-4-13 02:49:53
|
查看: 427|
回复: 0
发表于 2026-4-13 02:49:53
|
查看: 427|
回复: 0
