在大语言模型架构创新中,DeepSeek Engram 以“推理与知识分离”为核心主张,凭借外部 N-gram 记忆表的知识托管、O(1) 检索等特性,被寄予解决 Transformer 原生知识查找缺陷的厚望。其声称通过百亿参数级外部记忆库实现精准记忆读取,一度成为记忆增强架构的热门方向。
然而,本文作者团队的控制变量实验却颠覆了这一认知:将记忆表替换为高斯白噪声、统一共享向量,甚至仅保留单一桶(bucket),模型性能仍显著优于纯训练基线,且与原版效果相差无几。研究揭示,Engram 的性能增益并非来自所谓的知识检索,而是源于门控结构与残差通路带来的优化特性,外部记忆表实则仅扮演正则化“伪负载”角色。
这一发现不仅打破了对 Engram 记忆功能的固有认知,更为 LLM 架构优化提供了新思路——无需复杂的系统级调度与海量显存占用,仅通过结构优化即可实现性能提升,为降本增效的模型开发提供了重要启示。

一、缘起:完美的记忆增强架构
论文里说 Transformer 缺乏原生的知识查找(knowledge lookup)算子,提出把静态知识托管给外部 N-gram 嵌入(embedding),实现 O(1) 检索以解放前序计算层……听起来简直是完美的记忆增强(memory-augmented)架构,是一个好文明!
一个朴素而致命的疑问
一个自然而然的问题是,那个动辄百亿参数、被大书特书富含海量世界知识的外部记忆表(external memory table),真的非要不可吗?里面的知识真的有用吗?
二、控制变量实验:四组模型的记忆真相测试
为了验证,我们设计了一个简单的控制变量实验:
- Real: 原汁原味的 Engram,使用训练好的庞大记忆表。
- Randomize: 把巨大的 N-gram 表全部换成高斯白噪声(随机初始化,冻结不更新)。
- Uniform: 强制所有的哈希(Hash)函数全部映射到同一个桶里,等于所有词元(token)查表查出来的都是同一个共享向量。
- Dense Baseline: 没有任何 Engram 分支的纯训练基线模型。
令人沉默的实验结果
本来只是想测试记忆模块的鲁棒性,结果跑完一看,数据让人不得不重新思考。
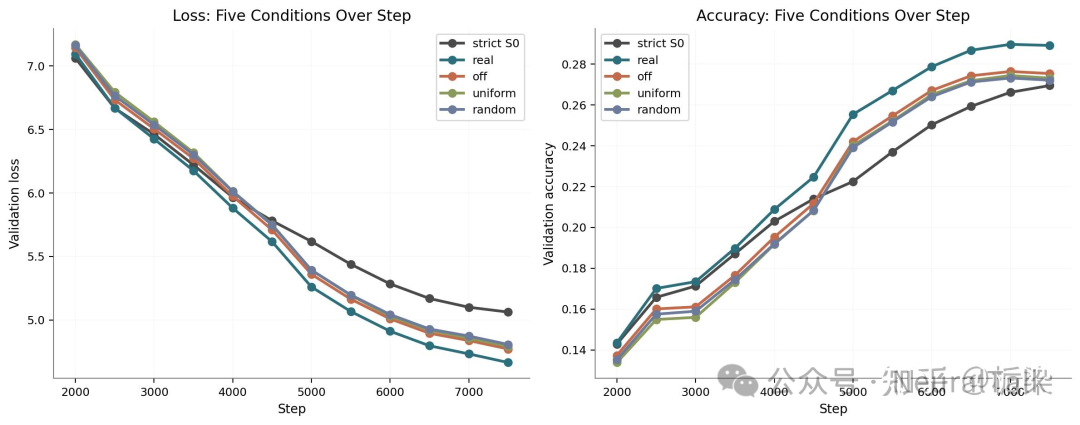
目前结论是:Real > Uniform ≈ Randomize >>>>> Dense Baseline。
三、正则化的外衣:当记忆库变成梯度旁路
你没看错。哪怕往那个被寄予厚望的记忆库里塞满纯纯的随机垃圾(Randomize),或者让所有的词元都共享同一个向量(Uniform),它的效果依然能把纯训练的 Dense baseline 吊起来打! 哪怕我们把记忆表的有效容量破坏得只剩下一个桶,模型依然觉得“真香”。
这就很有意思了。这明明就是一个披着记忆外衣的巨大正则化啊!
微弱的“真记忆”增益
可能有人会争辩:“Real 还是比 Uniform 好一点点,说明知识还是有用的!” 是的,表里的内容确实贡献了一点点微弱的增益。但这就好比你以为自己吃的是十全大补丸(外部知识),其实真正让你强身健体的是每天按时喝水(多了一条残差通路)。所谓的 Engram 增益,绝大部分根本不是来自于精准的细粒度记忆读取,而是来自于架构/通路(architecture/pathway)本身带来的优化性质。 我们可能不需要记忆本身,只需要“幻想”记忆存在就可以。
背后的朴素数学直觉
这背后的数学原因可能极其朴素:Engram 那个看似花哨的 gating * memory_vector 结构,其实只是在原本的梯度流上开了一条额外的旁路(bypass)。
那个上下文感知(context-aware)的门控(gating)才是真正起作用的部分,它根据当前的隐藏状态(hidden state)动态调节特征。而外部的记忆表扮演的不过是一个“伪负载”——哪怕这个负载是一坨随机噪声,只要加上这层非线性的门控,就能给早期网络层提供极好的梯度引导和宏观统计场,让模型更早收敛。
一个启发式的比喻是:你多修了一条高速公路,至于上面跑的是运钞车(真实知识)还是垃圾车(随机噪声),对于缓解主干道交通拥堵(梯度传播)的效果差不多。
四、它到底有没有记忆?答案是否定的
那么它到底有没有记忆的作用?答案是显然的:没有!
直接内容干预实验的失败
如果一个模块真在做较强意义上的检索(retrieval),那么我们对记忆内容做针对性干预时,它应该在输出侧表现得比较“听话”。例如,如果我们选择理论上最有利的桶,故意把捐赠者(donor)内容塞进去,那么模型至少应该在这些位置表现出更强的捐赠者引导(donor steering)、排名(rank)改变,甚至 Top-K 可见性提升。但结果并不支持这种想象。
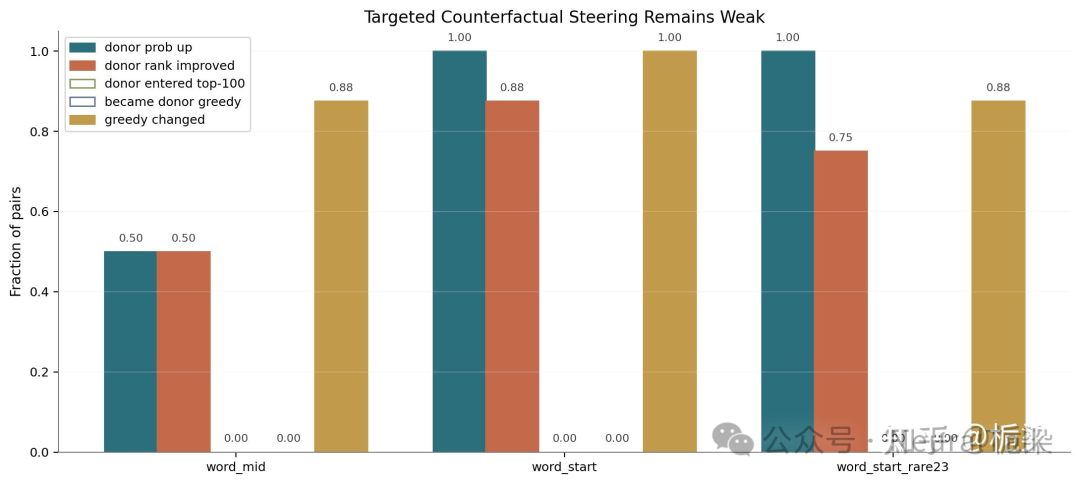
即便是在最强桶上,直接的内容操纵(direct content manipulation)也没有产生那种强、稳定、可编程的、类似检索的控制!这很重要,因为它说明 Engram 里确实有内容信号(content signal),但这个信号的作用方式,并不像论文声称的那样是一个外包的语义记忆库。
事实型提示词下的进一步验证
也许有人会说:可能你们挑的测试还不够“像记忆题”。如果换成更加事实型(factual)的提示词(prompt),也许外部内容的作用就会更明显。这个反驳是合理的,所以我们也做了这一组测试。
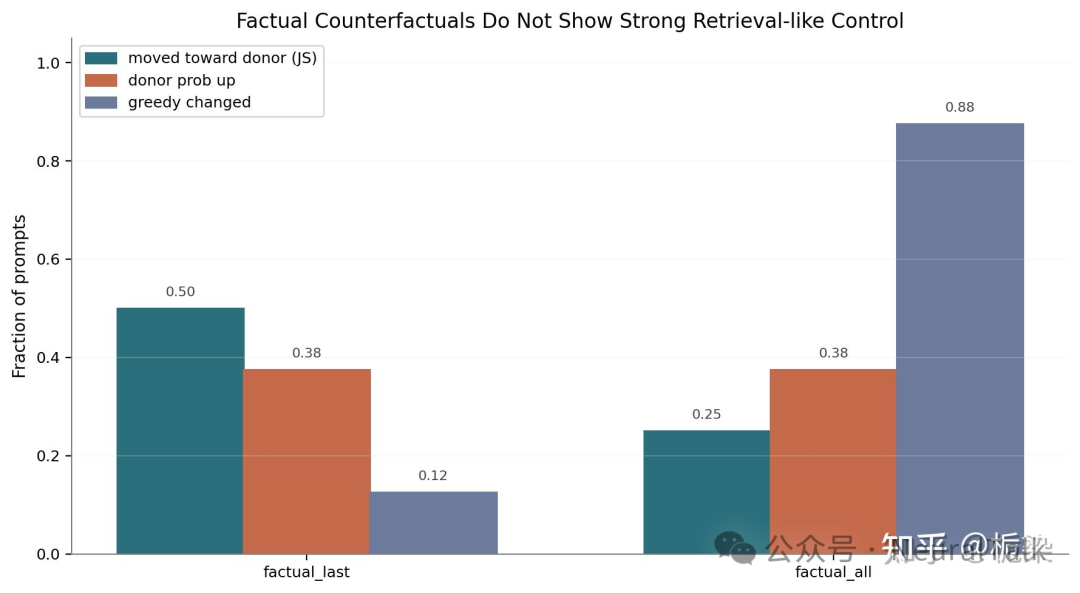
结果依然没有出现我们原本期待中的、类似检索的行为模式。
五、规模扩大后的结论固化:3B 参数模型的验证
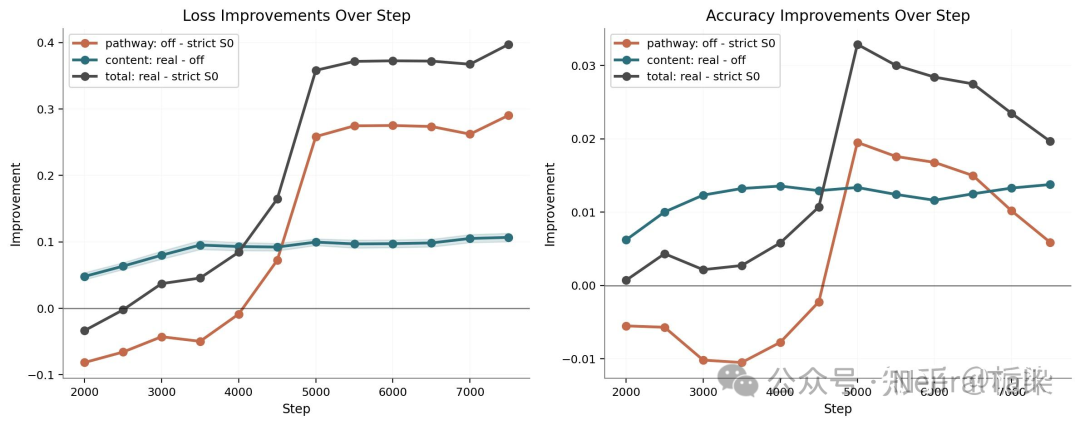
如果有人担心上面的现象只是小模型复现体上的假象(artifact),那么 3B 参数模型的结果就很重要。先看训练轨迹。
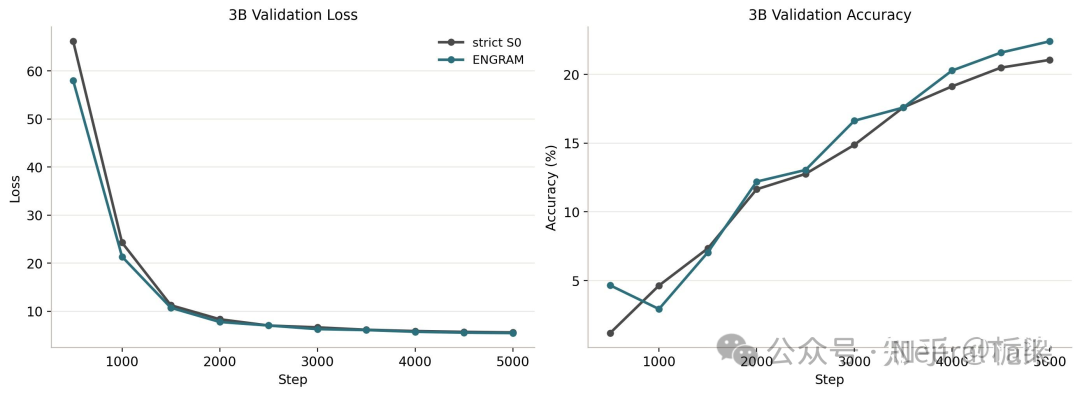
在 3B 规模上,Engram 相比严格基线(strict S0)的优势不是只出现在最终点,而是在训练过程中始终存在(除了早期的部分时刻)。这表明 Engram 的性能优势是真实存在的。
五条件消融的最终结论
但更重要的是最终的五条件消融结果。
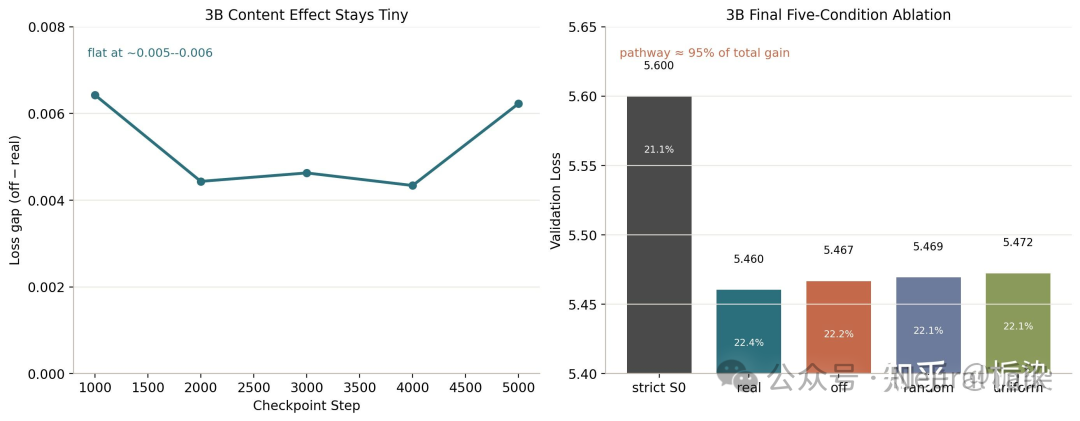
在 3B 模型上,我们看到“Real”条件效果最好,但“Off”、“Random”、“Uniform”条件的效果仍然非常接近,而它们整体又明显优于“strict S0”基线。随着模型规模增大,我们没有看到越来越像检索的趋势,反而看到了更强的“通路主导”(pathway-dominant)模式。这完全不同于我们对 Engram 的原始直觉。
六、工程启示:扔掉记忆库,拥抱随机噪声
换个角度想,其实这也是个天大的好消息。原论文花了大量篇幅去讲算法-系统协同设计(algorithm-system co-design),讲怎么用 CPU 主机内存做 100B 级大表的卸载(offload),讲怎么做 PCIe 异步预取(prefetch)来掩盖延迟……
既然我们发现“Uniform”(全部路由到同一个桶)或者“Randomize”都能拿走绝大部分收益,那其实完全不用让基础设施(infra)团队去开发什么复杂的系统级调度了!
我们只需要在内存里保留一个参数,或者干脆每次前向传播时都 torch.randn 一下,直接广播给所有的层! 不用查表,不用跨 PCIe 通信,更不用搞什么齐夫分布(Zipfian)缓存分层,显存占用瞬间从几百 G 降到几个 Byte,性能还能暴打基线,简直是降本增效的工程奇迹!
结语
总之,你的 DeepSeek Engram 可能根本不需要那个巨大的记忆表。下次再有人跟你吹嘘 LLM 挂载了多大的外部 N-gram 记忆库,或许可以礼貌地问一句:“您这表里装的,不会全是正则化偏置吧?”
 发表于 2026-4-14 03:58:53
|
查看: 131|
回复: 0
发表于 2026-4-14 03:58:53
|
查看: 131|
回复: 0
