Hermes Agent 近期的迅速走红,在 AI 圈内掀起了一阵热潮。由 Nous Research 推出的这个 AI Agent 项目,以其强大的技能生态与自我进化能力,在短短几周内便吸引了开发者的广泛关注。
然而,在其风光无限之时,来自中国的 EvoMap 团队公开发声,指控该项目涉嫌抄袭其早先开源的 Evolver 项目核心设计与架构。
争议时间线:从发布到指认的关键节点
要理解这场争议,首先需要厘清两个项目公开的时间脉络。
Hermes Agent 的发布节奏非常快:2月25日发布 v0.1.0 版本,3月12日就推出了包含70多个预置技能的完整技能生态系统,并声称具备自主创建新技能的“自进化”能力。
但 EvoMap 团队给出的时间线揭示了一个更早的故事。他们的 Evolver 项目早在 2月1日 就已开源,并迅速登上 GitHub 热门榜。该项目围绕其自研的 GEP(基因组进化协议),构建了一套完整的 Agent 自进化基础设施,包括 Gene/Capsule/EvolutionEvent 三级资产体系、基于信号的选择器、因果记忆图等。这些核心理念在 2月中旬 已通过多篇深度技术文章系统性地向公众阐述。

一个关键的时间差由此浮现:Evolver 的核心概念与架构在 2月1日至16日 已全部公开。而 Hermes 的“技能生态”在 3月12日 才发布,其“自进化”代码仓库则在 3月9日 才创建。两者间隔了 24至39天。
架构对比:从概念到实现的“翻译”级相似
EvoMap 团队提出的最核心指控,在于两个项目在架构设计层面表现出惊人的相似性,几乎达到了一一对应的程度。
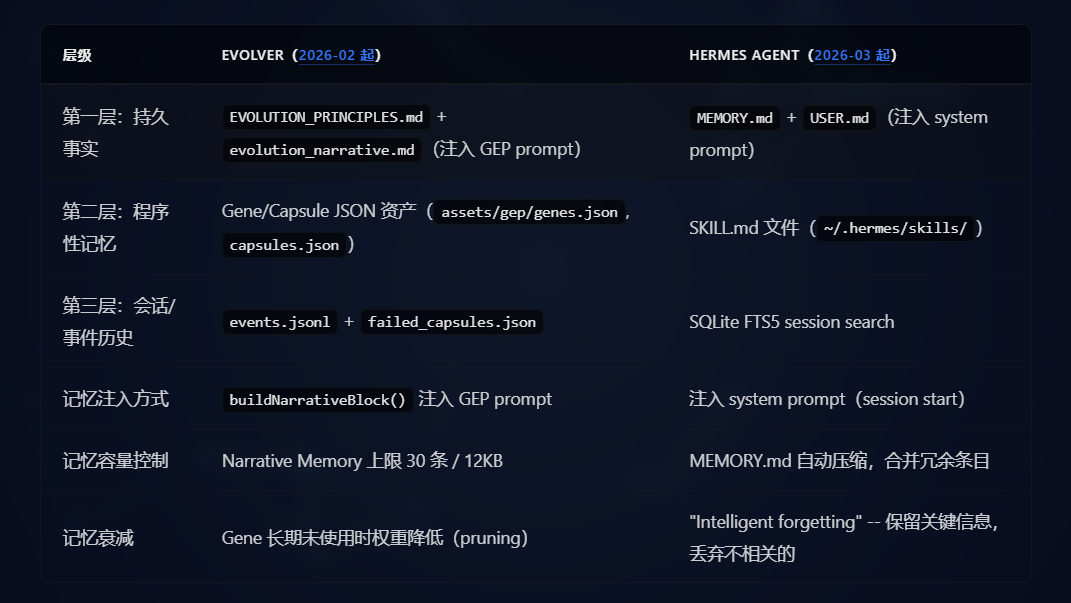
三层记忆体系
两个项目均采用了三层记忆结构:持久事实层 + 程序性记忆层 + 会话/事件历史层。每一层的具体实现虽在形式上有所不同(如 JSON 资产 vs SKILL.md 文件),但其功能定位与设计意图高度吻合。
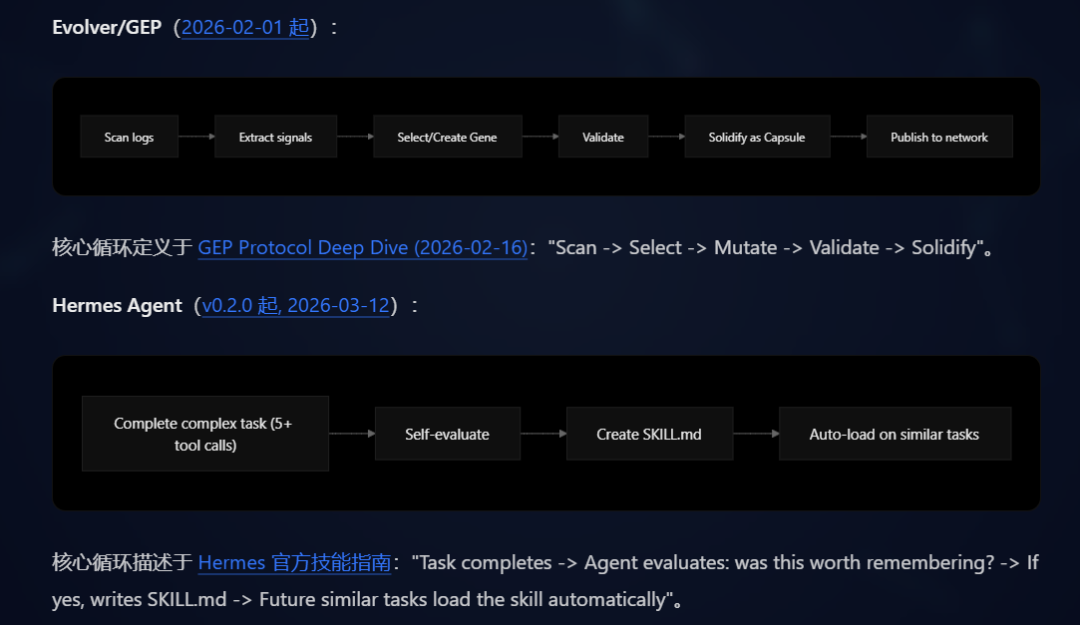
核心进化循环
两者都遵循“任务完成后自动提取可复用知识并持久化”的核心范式。Evolver 通过 Scan → Extract → Select/Create → Validate → Solidify 的流程将经验固化到 Gene/Capsule JSON 资产中;Hermes Agent 则在任务完成后通过 Self-evaluate → Create SKILL.md → Auto-load 的流程生成技能文件。其底层逻辑高度同构。
周期性反射机制
Evolver 设计了每5个进化周期触发一次的战略性自我评估(reflection)。Hermes 则设定了每15次工具调用(tool call)运行一次自我评估检查点(self-evaluation checkpoint)。尽管触发条件不同,但其目的完全一致:从执行经验中提取模式并进行持久化。
技能/能力发现机制
两者均实现了“运行时能力发现 + 按需加载”的模式。Evolver 通过信号匹配(signals_match)数组和选择器(Selector)来动态触发最相关的 Gene/Capsule;Hermes 则通过技能列表(skills_list())和按需查看(skill_view())来渐进式加载所需技能。

单独看某一个设计点,或许可以解释为“英雄所见略同”。但当多个维度的设计,包括三层记忆、核心循环、周期性反射、能力发现等,在如此短的时间内同时收敛到一个高度相似的结构,这很难用巧合来解释。
源码结构:功能等价的模块映射
超越架构层面的相似,深入到源码文件组织,也能发现功能上高度对应的模块。
以下是 Evolver 的核心模块结构:
src/gep/
selector.js # 基因选择引擎(信号匹配+漂移)
signals.js # 三层信号提取(正则/关键词/LLM)
solidify.js # 固化引擎(验证+回滚+发布)
mutation.js # 突变构建器(repair/optimize/innovate/explore)
reflection.js # 反射机制(周期性战略分析)
memoryGraph.js # 记忆图谱(JSONL追加, Jaccard相似度)
skillDistiller.js # 技能蒸馏器(Capsule -> Gene蒸馏)
assetStore.js # 资产存储(genes.json/capsules.json/events.jsonl)
executionTrace.js # 执行跟踪(脱敏后的跨agent共享)
narrativeMemory.js # 叙事记忆(进化故事摘要)
prompt.js # GEP提示词构建器
而在 Hermes Agent 中,可以找到功能几乎一一对应的模块:
# 主仓库 hermes-agent/
agent/memory_manager.py # 记忆管理(MEMORY.md + USER.md)
agent/context_engine.py # 上下文引擎(压缩/会话管理)
agent/prompt_builder.py # 提示词构建(系统提示+技能索引)
agent/skill_utils.py # 技能元数据工具(frontmatter解析)
agent/skill_commands.py # 技能命令(运行时发现+激活)
tools/skill_manager_tool.py # 技能CRUD(create/edit/patch/delete)
tools/memory_tool.py # 持久记忆工具(MEMORY.md CRUD)
# 自进化仓库 hermes-agent-self-evolution/
evolution/core/fitness.py # 适应度评估(LLM-as-judge评分)
evolution/core/constraints.py # 约束验证(大小/增长/结构)
evolution/skills/evolve_skill.py # 技能进化主循环(10步编排)
这种映射关系并非臆测,EvoMap 团队绘制了详细的对比表格:

更值得注意的是术语的“系统性替换”。在 Hermes 的代码仓库中进行全文搜索,无法直接找到 “Evolver”、“GEP”、“capsule” 等原始术语。
然而,每个 Evolver 的核心概念都在 Hermes 中找到了一个术语不同、但功能等价的对应物,形成了清晰的“翻译”对照表:

这种成体系的、一对一的术语替换,而非零散的概念借鉴,是此次争议中一个非常值得关注的细节。这也引出了开源社区中最看重的原则之一:对前人工作的引用与尊重。
“零引用”与开源礼仪的缺失
在 Hermes Agent 及其自进化仓库的所有公开文档、代码注释及论文中,对 Evolver、GEP 协议 或 EvoMap 的引用次数为 零。
Hermes 团队在材料中引用了 GEPA / DSPy(来自斯坦福/伯克利)和 Darwinian Evolver(来自 Imbue AI),这些是正当且规范的学术引用。然而,对于在整体自进化架构上与其最为相似的先行项目——于 2026年2月1日开源、获得大量关注的 EvoMap Evolver——却只字未提。
作为对比,EvoMap 团队在争议发生后,主动发布了对 Hermes Agent 的对比分析文章,客观承认了 Hermes 项目的技术价值与实现优点。
在健康的开源生态中,相似项目间的相互引用和致谢是一种常见且被鼓励的实践。例如 LangChain 会引用 DSPy,CrewAI 会与 AutoGen 进行对比。这种做法不仅是对创新源头和“先前技术”(Prior Art)的尊重,也帮助社区更清晰地理解技术谱系与发展脉络。
AI 时代的“代码洗稿”与开源伦理困境
此次事件折射出一个更深层且日益严峻的问题:AI 辅助下的“概念洗稿”或“架构洗稿”。EvoMap 团队在其公开信中提到了“AI 洗代码”的概念——在这个时代,抄袭可能不再需要逐行复制。将他人的开源项目丢给高级 AI 模型,让其深入理解核心逻辑与架构,然后换一套变量命名、调整文件结构、用另一种编程语言重写,便能产出一个表面上“完全不同”、但核心设计几乎 100% 一致的新项目。文本相似度可能极低,但灵魂却被完整“移植”。
这就像将一部小说翻译成另一种语言,再转译回来,文字全变了,但人物关系、情节结构和核心思想依旧。这种形式的“借鉴”界定困难,维权成本极高。
这也部分解释了为何一些创新团队在遭遇类似事件后,会选择从宽松的 MIT 协议转向更具传染性的 GPL 协议,甚至对核心模块进行混淆处理。一个原本拥抱开放协作的团队,被迫采取防御姿态,这本身就是一个值得整个技术社区警惕的信号。
今年以来,类似案例已多次发生:从大厂产品被指直接使用个人开发者代码,到独立开发者的项目在开源后极短时间内被“AI 重写”并以“原创”名义发布。当“洗稿”的成本因 AI 而急剧降低,原创者与“借鉴者”之间的博弈天平正在发生倾斜。
平心而论,Hermes Agent 本身在工程实现上是一个优秀的项目。它技术栈选型严谨(基于 Python 生态)、实现扎实,并提供了良好的用户体验。其团队提出的某些辩护理由(如遵循行业已有的 Agent Skills 规范)也并非毫无根据。
然而,这些理由无法充分解释其在整体架构层面与 Evolver 表现出的、跨越多个维度的“同构性”。在开源世界里,有个朴素的底线:你可以站在巨人的肩膀上,但请至少提及巨人的名字。选择性地引用部分知名工作,而对另一部分高度相关的前沿工作完全沉默,这种“选择性失明”配合架构的“翻译级对应”,正是让许多社区参与者感到不适的根源。
反思:我们如何守护开源精神?
这场争议或许不会有法律意义上的“抄袭”判决,但它抛出了一个必须面对的问题:当 AI 工具日益强大,“灵感借鉴”与“创意剽窃”的边界究竟在哪里?
开源的本质是知识的共享与协作,而不是无偿的“架构外包”。如果每一位创新者在公开其核心设计后,都要担心明天就被AI“洗稿换皮”,甚至可能被反指为“后来者”,那么还有多少人愿意持续开源其真正的创新?
EvoMap 团队在公开信中的诉求颇为克制:“我们不要求许可费、不要署名权——只希望事实被记录,历史被尊重。” 这或许正是开源社区赖以生存的朴素底线:尊重创新源头,尊重事实与历史。
对于关注此类开源实战中伦理与法律边界的开发者来说,这场讨论具有重要意义。它不仅关乎两个具体的 AI 项目,更关乎在技术快速迭代的浪潮中,如何构建一个既鼓励创新又尊重原创的良性生态。
技术的发展,尤其是 人工智能 领域的突破,不应以牺牲协作诚信为代价。这场风波也成为了近期 开发者广场 上热议的话题,引发了关于创新、版权与 AI 伦理的广泛思考。
现在,问题抛回给了 Hermes 团队:既然坚称架构不同,为何不大方地进行公开、细致的对比分析?既然确信是独立创新,为何在做出官方回应后又迅速删除并拉黑讨论?答案,或许隐藏在那些尚未被仔细审视的 commit 历史与设计决策过程中。
相关链接:
 发表于 2026-4-16 21:46:51
|
查看: 192|
回复: 0
发表于 2026-4-16 21:46:51
|
查看: 192|
回复: 0
