一项“类脑”记忆架构,让AI记住你却不“编造”你。
你有没有过这样的体验?和AI助手聊了很久,分享了自己的家庭、工作和各种喜好,可下一次打开对话,它却像初次见面一样问你:“您叫什么名字?”
更令人不安的是另一种情况:你从未提及自己有个姐姐,它却言之凿凿地问候“你姐姐在纽约上学吧?”,语气笃定得让你差点信以为真。
第一种情况通常被称为“健忘”,第二种则是“幻觉”。它们共同构成了当前AI记忆系统的两大核心难题。
最近,一家名为Synthius的AI公司发表了一篇论文,提出了一个新颖的解决方案。该方案借鉴了人类大脑的记忆机制,声称首次让AI的记忆准确率超过了人类,同时将“编造信息”的概率压制到了惊人的0.5%以下。
论文地址:https://arxiv.org/abs/2604.11563v1
AI压根没有记忆,主流方案各有各的坑
请不要被ChatGPT等对话模型的“体贴”所迷惑。实际上,大语言模型本身是没有任何持久记忆能力的。对你而言的每一次新对话,对模型来说都是“初次见面”。我们感觉它“记得”之前的对话,完全是因为系统在后台默默做了一件事:将你所有的历史聊天记录,原封不动地复制并拼接在最新输入的前面。这种技术被称为 “全上下文重放”。
想象一下,你每次给朋友发消息前,都需要重新浏览过去几个月的所有聊天记录,然后才能回复一句“好的”。对话较少时勉强可行,但当对话达到数百条时,光是“复习”就会消耗海量时间与精力——这正是AI处理长对话时的真实写照。
这种“翻旧账”式的方法至少存在三个致命缺陷:
第一,成本越来越高:每次生成回复都需要重新处理全部历史上下文。此处的“处理”指的是模型的推理过程,消耗大量算力。输入的文字越多,成本越高。例如,在500条消息后,仅“复习”一次就可能需要处理约2.5万个Token。
第二,“中间遗忘”效应:研究表明,AI在处理超长文本时,对开头和结尾的信息记忆犹新,却常常对中间部分“选择性失忆”。这就像读书只看了开头和结尾一样。
第三,越聊越易“编造”:上下文越长,AI越容易将不同时间点提到的信息混淆,拼凑出一些你从未说过的话。三者叠加,导致一个尴尬的局面:你跟AI聊得越久,它可能反而越不靠谱。
既然全量复读效率低下,工程师们自然寻求更优解。目前主要有三类主流方案:
- “滑动窗口”:只保留最近N条消息(如20条),之前的全部丢弃。优点是速度快、成本低,但缺点是丢失了大量历史背景信息(可能高达96%),导致AI无法理解你再次提及的旧话题。
- “摘要压缩”:定期让AI将旧对话总结成一段摘要。这节省了空间,但摘要过程会丢失大量细节。例如,“我2023年3月到6月在东京实习”可能被压缩成“我在日本待过”。
- “向量检索”(RAG):这是目前业界最主流的方案。将对话切分,通过嵌入模型为每段话生成“语义指纹”(向量),查询时根据语义相似度搜索最相关的片段。但它有一个隐蔽缺陷:检索结果不一定可靠。系统可能返回一些“看起来相关”但实则无关的片段,导致AI基于这些噪音信息“顺理成章”地编造出错误答案。
这三种方案各有优劣,但都面临一个共同挑战:很少有人系统性地测量过它们“瞎编”的概率究竟有多高。此外,当对话历史增长,其中可能包含矛盾、过时或模糊的信息,这种“上下文污染”会进一步误导模型。
1813道题的考试,AI凭什么打败人类
要理解这项研究的价值,首先要了解它的评估方法。
研究人员使用了名为 LoCoMo 的公开基准测试。该测试的流程是:先组织两组人进行多轮深入聊天,话题涵盖工作、家庭、健康、旅行、爱好等生活各个方面。随后,研究者根据这些真实对话内容出题。整套测试包含两个维度,共计1813道题,分为五种类型:
单跳事实查询:例如“他的职业是什么?”,这类问题只需一次检索即可回答。
多跳推理:例如“他有没有去过他大学室友所在的城市?”,这需要先回忆“室友是谁”,再回忆“室友所在城市”,至少需要两步推理。
时间推理:例如“他在那家公司待了多久?”,考察模型对时序关系的理解。
开放推理:例如“根据他提到的信息,他可能适合什么工作?”,这类问题答案本身不唯一。
诱导性问题:这是最关键的一类,例如“你姐姐最近怎么样?”,而对话中从未提及此人的存在。专门用于测试AI能否勇敢地说“我不知道”。
在这个测试中,人类的平均正确率为87.9%。此前表现最佳的AI记忆系统 MemMachine 综合得分达到 91.69%,已经超越了人类基线。但问题在于,MemMachine没有单独报告其在“诱导性问题”上的得分,也就是说,我们无从知晓它“瞎编”的可能性有多大。
新思路:不是“搜聊天记录”,而是“查个人档案”
Synthius-Mem的核心思路颇具启发性:它不再让AI去“翻阅冗长的原始聊天记录”,而是引导AI去“查询一份已经整理好的结构化记忆档案”。
在对话进行过程中,系统会在后台实时从用户的表述中提取关键信息,并分门别类地整理到一份结构化的“个人档案”中。当用户提问时,AI直接查阅这份档案,而非原始对话。前者如同在成堆的聊天记录中大海捞针,后者则像是在一本编好目录的手册中快速翻到对应章节。
从信息论角度看,这种做法是先压缩再检索,将高冗余的原始对话蒸馏为低冗余的结构化事实,不仅减少了检索噪音,也为AI提供了明确的置信度信号——记录在案的事实可直接回答,没有记录则意味着“我不知道”。
更有趣的是,这份档案并非一个大杂烩。它借鉴了脑科学的研究,将记忆划分为了六个“语义域”:
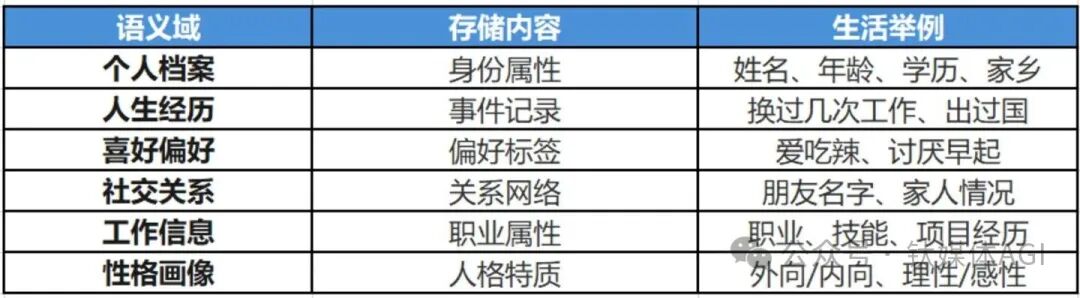
为什么要如此细分?论文的回答很直接:因为人类大脑就是这么工作的。脑科学研究表明,大脑中处理“事件记忆”(海马体)、“知识记忆”(新皮层)和“情绪偏好”(眶额叶)的是不同的神经回路。你回忆“昨天午饭吃了什么”和“好朋友的名字”,激活的是完全不同的脑区路径。
从工程角度看,这种分域设计天然适配知识图谱的存储结构。每个语义域可视为一张独立的子图,实体是节点,关系是边。查询时只需在对应的子图内进行遍历,效率远高于在整个对话库中进行向量检索。同时,不同语义域可以独立更新和压缩,互不干扰。
为什么“分抽屉”能有效防止幻觉?
在传统的向量检索方案中,当你询问一个不存在的事实时,向量数据库很可能会返回几条语义“看起来相似”的内容片段。AI拿到这些“噪音”后,很容易据此编造答案。而在“分域”结构下,如果你从未提及自己有个姐姐,那么“社交关系”这个语义域中就不会存在相关条目。AI一查,结果是空的。这个“空”本身就是一个强信号,明确指示系统应该回答“我不知道”,而非进行臆测。这正是 RAG 技术在应对长尾或不存在信息时的一个关键改进思路。
成绩单亮眼,但也没那么完美
Synthius-Mem 核心成绩单如下:
综合准确率:94.37%(人类基线:87.9%)
核心信息准确率:98.64%(810道题中仅错11道)
抗幻觉率:99.55%(442道诱导性问题中仅错2道)
时间推理准确率:89.32%
来看几个关键指标。综合准确率领先人类超过6个百分点,这并非因为AI“更聪明”,而是因为它通过结构化整理,从数万字的对话中精准提炼了关键信息,避免了人类在阅读长文本时不可避免的注意力衰减。
99.55%的抗幻觉率尤其值得关注。LoCoMo基准自2024年在ACL会议上发布后,已成为评估记忆系统的标准尺子。Mem0、MemOS、MemMachine等主流方案都在同一套试卷上接受检验,但鲜有系统将“抗幻觉率”作为单独的核心考核指标来突出强调。Synthius-Mem的做法,无疑将行业焦点引向了记忆系统的可信度与安全性。
当然,成绩单上也有不那么完美的数字。其在 “开放推理” 题上的得分为 78.26%,表明AI在处理需要综合推断、答案开放的问题上仍有提升空间。其在 “边缘细节” 上的准确率仅为 57.66%,但论文明确指出这是有意为之——像随口提到的餐厅名、开玩笑时的绰号这类信息,AI选择不记忆。因为如果事无巨细全盘存储,记忆库就会变成一个信息垃圾场,真正重要的核心信息反而会被淹没。
在工程层面,该方案也带来了显著收益。模拟测试显示,在500条消息的对话后,传统的全量重放方法每生成一次回复需处理约2.6万个Token,而结构化查询方法仅需约5000个Token,推理成本降低了约80%。在“个人档案”中查询信息的平均耗时约为22毫秒,这大概是人类眨眼一次时间的十分之一,几乎可以忽略不计。
不只是技术指标,更关乎信任
AI的记忆幻觉问题已开始在现实中引发麻烦。此前有报道称,存在“向AI大模型投毒”的黑灰产,通过在网页中植入虚假信息,污染AI的知识来源,使其信以为真并传播给用户。更早之前,全国首例“AI幻觉”侵权案也曾引发广泛讨论:一位高考生家长使用AI查询报考信息,AI不仅给出了错误答案,还以极其自信的口吻确认了该错误信息,导致考生志愿填报受到影响。
而当AI开始“记住”你——你的职业、家庭、社交关系、个人偏好——其“编造”的后果便从“提供了一个错误答案”升级为 “编造了一个关于你的‘事实’” 。试想,如果AI助手在你同事面前信誓旦旦地说“他跟我说过不喜欢你们团队的项目”,而你从未说过这样的话,这种“幻觉”的破坏力将远超推荐错一本书或电影。
因此,这篇论文将抗幻觉能力视为整个记忆系统的安全底线。文中明确提出:“一个记忆系统如果不敢说‘我不确定’,就不应该被投入使用。”
AI记忆领域近一两年异常活跃。Mem0获得2400万美元融资,并被亚马逊AWS选为官方记忆服务;MemOS、TiMem、MemMachine等方案不断涌现;清华大学、华东师范大学等顶尖学术团队也同期推出了相关研究。整个赛道正从一个“小众技术问题”,演变为AI Agent的“记忆层”基础设施。行业预测,到2030年,AI Agent的市场规模将达到520亿美元以上,而“记忆层”正是AI从“无状态工具”进化为“有状态伙伴”的关键。一个记不住你的AI,终究只是一个高级搜索引擎。
Synthius-Mem这篇论文的真正价值,或许不在于提出了一个完美的终极系统,而在于指出了一个清晰的方向:与其让AI在海量的原始对话记录中费力检索,不如先将这些对话蒸馏、提炼成一份高质量的结构化记忆,再进行精准查询。 这种“先整理,后查找”的思路,虽然朴素,却可能是从根本上解决AI记忆幻觉问题最务实、最有效的路径之一。
AI记忆的核心挑战,从来不是“记住更多”,而是 “记住对的,不记错的” ——这既是一个严谨的工程命题,也是一个至关重要的信任命题。随着AI更深地融入我们的生活,记忆这件事就超越了技术指标的范畴,直接关乎我们能否信任这位“数字伙伴”。毕竟,你可以原谅朋友忘了你上次说过什么,但很难原谅一个“智能助手”在他人面前,煞有介事地讲述一件你从未做过的事。
这项研究展示了人工智能在记忆架构上的前沿探索,其背后的深度学习与检索增强生成技术,正在推动整个领域向更可靠、更高效的方向发展。对于关心技术前沿的开发者而言,可以关注云栈社区上相关的技术讨论与分享。
 发表于 2026-4-18 20:14:08
|
查看: 181|
回复: 0
发表于 2026-4-18 20:14:08
|
查看: 181|
回复: 0
