

理解大模型(LLM)推理的底层原理,是进行性能调优和工程实践的基础。本文系统梳理了推理过程中的关键术语、性能指标、采样概念以及主流推理框架的核心参数,旨在为开发者构建清晰的知识脉络。
性能指标
评估推理系统的能力,通常围绕Token的生成速率与服务质量展开。以下是几个核心指标:
- TTFT(Time To First Token): 生成第一个Token所需的时间。该指标主要用于衡量预填充(Prefill)阶段的性能,反映了系统对用户输入Prompt的初始响应速度。
- E2EL(End-to-End Latency): 端到端请求时延。指从用户提交完整提示词开始,到模型生成全部结果并返回给用户为止所经历的总时间。
- ITL(Inter token Latency): 解码(Decode)阶段生成单个Token的平均时间。一般计算公式为:
(总生成时间 - TTFT) / (输出Token总数 - 1)。
- TBT(Time Between Tokens): 相邻Token之间的生成时间差,通常指某个特定Token的生成耗时。
- TPOT(Time Per Output Token): 所有输出Token(包括首个Token)的平均生成时间。计算公式为:
总生成时间 / 输出Token总数。
注意: 在不同实现中,这些指标的计算方式可能略有差异。例如,在vLLM等框架中,ITL有时会采用TBT的计算逻辑,而TPOT则可能沿用ITL的定义。
- QPS(Queries Per Second): 每秒能够处理的请求数量。
- TPS(Tokens Per Second): 每秒生成的总输出Token数,是衡量吞吐量的关键指标。计算公式为:
输出Token总数 / 总请求耗时,单位是 tok/s。

- QPM(Queries Per Minute): 每分钟处理的请求数量。
- TP90/Top Percentile: 至少有90%的请求满足的延迟条件(如低于某个值)。类似的还有TP50、TP99,常用于定义服务质量的SLA(服务等级协议)。
- RPS(Requests per Second): 每秒注入的请求数,在压力测试中用于控制负载速率,也是评估吞吐能力的重要参考,单位req/s。
- Ramp Up: 爬坡测试,指逐步增加RPS以观察系统性能变化、寻找瓶颈的测试方法。
- SLO(Service Level Objective): 服务质量目标,是保障用户体验的关键量化指标。例如,可要求99%的请求TP99延迟低于200ms,且平均TPS不低于20 tok/s。
- MFU(Model Flops Utilization): 模型浮点运算利用率,是衡量模型实际消耗的算力占GPU峰值算力比例的指标,用于评估算力资源的利用效率。
采样相关概念
在生成文本时,模型通过采样策略从概率分布中选择下一个Token,相关参数直接影响生成内容的多样性与质量。
- Temperature(温度): 用于调整Logits概率分布的平滑程度。值越高(>1),分布越平缓,输出越随机、多样;值越低(<1),分布越尖锐,输出越确定、保守。
- TopK: 采样时,仅保留概率最大的K个候选Token。取值范围为1~词表大小(-1通常表示禁用此策略)。
- TopP(核采样): 对概率从高到低排序并累加,仅保留累积概率达到P的最小候选集。例如,TopP=0.9意味着保留概率和刚超过90%的那些高概率Token。取值范围0~1。
- MinP: 保留所有概率不低于最高概率一定比例(P倍)的候选词。即保留所有满足
概率 >= (最高概率 * min_p) 的Token。
- Frequency Penalty(频率惩罚): 根据Token在已生成文本中出现的频率来降低其Logits值,出现越频繁,惩罚越重,用于抑制重复。
- Presence Penalty(存在惩罚): 对已经出现过的Token,无论次数多少,统一在Logits上减去一个固定惩罚值,每个Token只惩罚一次。
- Repetition Penalty(重复惩罚): 对重复出现的Token进行衰减,与频率惩罚类似,但具体实现可能不同。
- Beam Search(束搜索): 一种启发式搜索算法,在每个时间步保留概率最高的K个序列(束宽),通过剪枝减少搜索空间,旨在找到整体概率更高的输出序列。
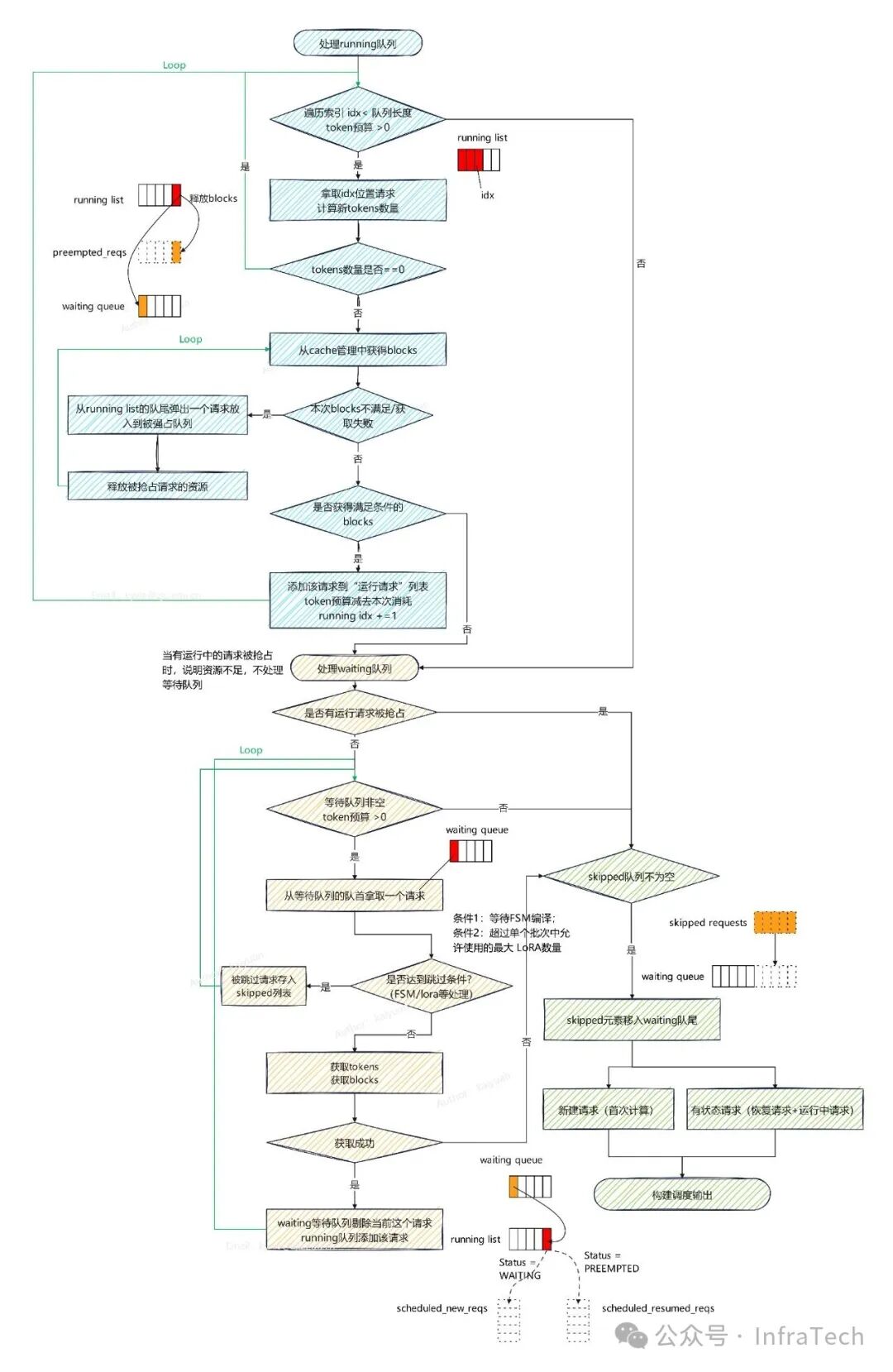
主流推理引擎与框架
选择合适的推理框架是LLM应用落地的关键一步。
- vLLM: 由加州大学伯克利分校团队开发的主流LLM推理框架。其核心创新是PagedAttention机制,像操作系统管理内存一样高效管理KV Cache,实现了极高的吞吐量和内存利用率。它以功能全面、生态活跃著称。
- SGLang: 同样源于伯克利与斯坦福的研究,是另一款高性能推理框架。它基于RadixAttention开发,通过高效缓存和复用计算中间状态来加速复杂提示词的执行,特别在交互式、有结构化约束的场景下表现突出。
- Dynamo: NVIDIA推出的分布式推理系统解决方案,深度整合其硬件与软件栈,旨在为超大规模模型推理提供高性能、可扩展的平台。
- AIBrix: 字节跳动开源的LLM推理云原生解决方案,提供了完整的Kubernetes Operator和调度器,专注于在云原生环境下实现高效的资源管理与推理服务部署。
核心服务参数详解
以下以vLLM和SGLang为例,介绍常见且关键的引擎参数。
vLLM 常见参数:
--max-num-seqs: 调度器每次迭代处理的最大请求序列数。--max-num-batched-tokens: 每次迭代允许处理的最大Token总数,用于控制批量大小。--max-model-len: 模型支持的最大上下文长度(输入+输出Tokens)。若不指定,则从模型配置自动推断。--dtype: 指定模型权重和激活值的数据类型,如float16, bfloat16, float32等,直接影响内存占用和计算速度。--gpu-memory-utilization: 为模型执行器预留的GPU显存比例(范围0~1)。注意:这并非推理进程的总显存占用。--tensor-parallel-size(-tp): 张量并行的副本数量,用于将模型参数拆分到多个GPU上,是人工智能分布式训练与推理的常用技术。--block-size: KV Cache中一个内存块(Block)容纳的连续Token数量,是PagedAttention的核心参数之一。
SGLang 内存与调度参数:
SGLang的配置同样关注内存、批处理与并行度。其参数设计旨在优化RadixAttention的执行效率,具体包括缓存策略、批处理大小、并行 workers 数量等,需根据实际负载进行调整。
引擎模块浅析(以vLLM为例):
- 调度器(Scheduler): 负责根据GPU内存、计算资源以及请求状态,决定哪些请求的哪些Token块进入本次计算循环。
- KV Cache管理: 基于PagedAttention,将逻辑上的连续KV序列映射到物理上非连续的内存块中,极大减少了内存碎片,提升了人工智能大模型服务的内存效率。
- 引擎核心(Engine Core): 执行调度器分配的计算任务,包括KV数据的传输、模型层的具体前向计算等。
提示:不同版本的引擎参数可能存在差异,建议以官方文档为准(vLLM Engine Args, SGLang Server Arguments)。
|  发表于 2025-12-12 20:03:34
|
查看: 377|
回复: 0
发表于 2025-12-12 20:03:34
|
查看: 377|
回复: 0
