在MySQL数据库设计中,当字段允许为空时,是保存NULL值还是设置默认值,这是一个常见但关键的决策。许多开发者在实际开发中容易忽视这一细节,有时直接存储NULL,有时则赋予业务相关的默认值。本文将深入探讨这一话题,从存储机制到性能影响,帮助您做出更优的设计选择。
1. 行数据存储机制分析
MySQL在保存一行数据时,不仅存储数据本身,还会记录额外的元信息。InnoDB存储引擎作为MySQL的默认引擎,支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。自MySQL 5.7版本起,默认使用DYNAMIC行格式,它是COMPACT格式的改进版,具有更好的可变长度列存储和大索引键前缀支持。
以下是官网对四种行格式的简要说明:
| 行格式 |
紧凑存储 |
增强可变长度列存储 |
大索引键前缀支持 |
压缩支持 |
表空间类型支持 |
文件格式 |
| REDUNDANT |
否 |
否 |
否 |
否 |
system, file-per-table, general |
Antelope or Barracuda |
| COMPACT |
是 |
否 |
否 |
否 |
system, file-per-table, general |
Antelope or Barracuda |
| DYNAMIC |
是 |
是 |
是 |
否 |
system, file-per-table, general |
Barracuda |
| COMPRESSED |
是 |
是 |
是 |
是 |
file-per-table, general |
Barracuda |
DYNAMIC和COMPRESSED格式均基于COMPACT结构优化。我们以COMPACT格式为例,了解其行存储布局:

创建一张示例表:
CREATE TABLE `t_user` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(16) DEFAULT NULL,
`email` varchar(32) DEFAULT NULL,
`address` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
插入两行数据后,行存储格式如下:
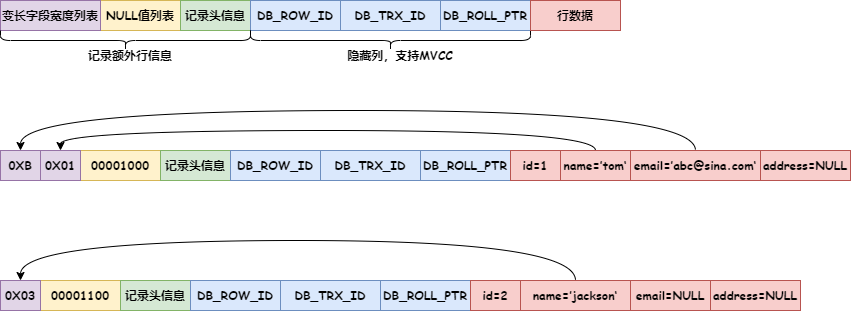
- 变长字段宽度列表:逆序保存非空变长字段的长度。如果表中所有列均为NOT NULL且长度固定,则此部分不存在。
- NULL值列表:同样逆序保存,用二进制1标记NULL值,0标记非NULL值。若所有列定义为NOT NULL,此部分将被省略。
记录头信息占用5字节,包含以下关键数据:
- delete_flag:标记记录是否被删除(MySQL采用异步清理机制)。
- record_type:记录类型,如普通记录或索引节点。
- next_record:指向下一条记录的指针。
- n_owned:记录该组数据的数量。
隐藏列:
- DB_TRX_ID:事务ID,记录最后修改此数据的事务。
- DB_ROLL_PTR:回滚指针,指向历史版本以实现MVCC。
- DB_ROW_ID:当表无主键时,自动生成聚簇索引的ROW ID。
2. NULL值的处理与影响
基于上述存储分析,将字段直接定义为NOT NULL具有以下优势:
- 节省存储空间:NULL值本身不占数据空间,但NULL值列表需要额外1-2字节。若所有字段非空,可省略此列表。
- 减少空指针异常:应用程序中无需频繁处理NULL检查,降低
NullPointerException风险。
- 优化统计操作:例如
COUNT(字段)会忽略NULL值,非空字段统计更直观。
- 提升索引效率:索引不存储NULL值,非空字段能提高索引查询性能。
- 简化比较操作:非空字段可直接使用
=、!=、>等比较运算符,而NULL字段只能通过IS NULL或IS NOT NULL判断。
- 避免范围查询问题:使用
IN或NOT IN时,NULL字段可能导致返回空结果集。
然而,使用NULL值也有其适用场景:
- 语义清晰:NULL明确表示“无值”或“未知”,逻辑上更准确。
- 筛选灵活:在WHERE子句中,
IS NULL条件能快速过滤空值。
- 数据一致性:在JOIN操作中,NULL与任何值比较均返回NULL,有助于保持数据完整性。
实际项目中,开发者常为NULL字段设置默认值(如“-”、“N/A”等),以避免空指针问题。但这也可能引发上下游系统因默认值不一致而产生的业务逻辑错误。因此,在设计表结构时,不应过度纠结存储空间的微小差异,而应优先考虑系统整体规范与一致性,确保处理逻辑的健壮性。 |  发表于 2025-12-12 20:11:55
|
查看: 230|
回复: 0
发表于 2025-12-12 20:11:55
|
查看: 230|
回复: 0
