在企业数字化转型与信创国产化替代的背景下,寻求可靠、高效的分布式搜索引擎解决方案成为许多开发者和架构师的共同需求。INFINI Easysearch 作为一款基于开源生态构建的国产分布式搜索引擎,以其轻量级、高安全性和良好的兼容性受到关注。本文将为你梳理一条从零开始,系统掌握 INFINI Easysearch 的实战学习路线。
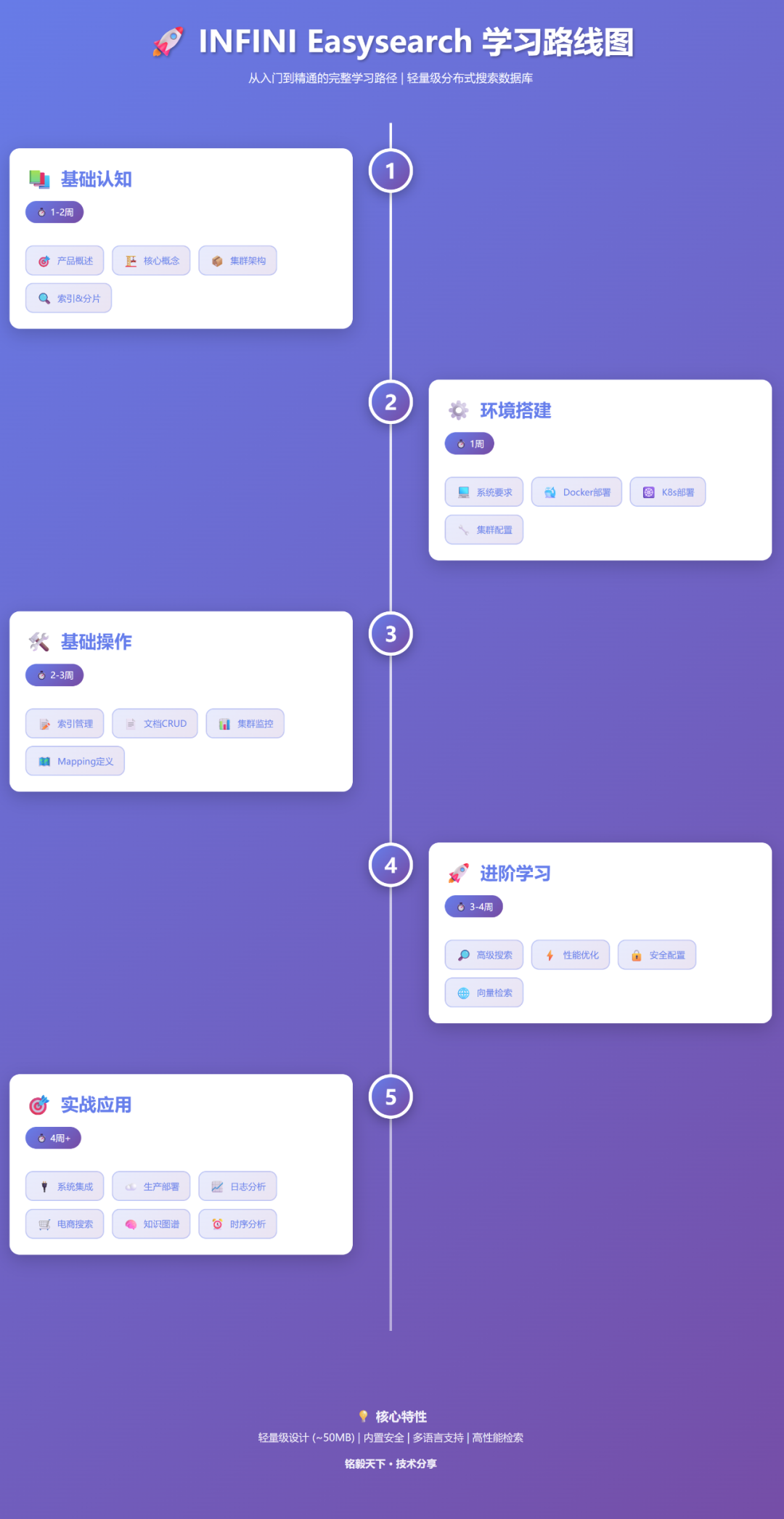
路线图总览
学习过程可分为五个循序渐进的阶段,确保知识体系扎实稳固:
- 第一阶段:基础认知(1-2周) —— 建立产品与核心概念的世界观。
- 第二阶段:环境搭建(1周) —— 动手构建可运行的单机或集群环境。
- 第三阶段:基础操作(2-3周) —— 掌握索引管理与数据增删改查。
- 第四阶段:进阶学习(3-4周) —— 深入高级搜索、性能调优与安全配置。
- 第五阶段:实战应用(4周+) —— 设计生产架构并解决典型业务场景问题。
第一阶段:基础认知 —— 磨刀不误砍柴工
在动手之前,清晰理解产品的定位与核心概念至关重要。
1. 产品概述
Easysearch 的定位主要体现在以下几个方面:
- 国产化替代:致力于成为 Elasticsearch 的轻量级替代方案,符合信创要求。
- 轻量高效:安装包体积小巧(约50MB),启动快速,资源占用低。
- 功能全面:不仅支持全文检索,还原生支持向量检索(适用于AI场景)和地理位置检索。
- 安全内置:原生集成了LDAP等安全功能,无需额外安装复杂的商业或第三方安全插件。
参考链接:产品概述
2. 核心术语
理解以下核心概念是后续所有操作的基础:
- 集群 (Cluster):由多个协同工作的服务器节点组成的逻辑集合。
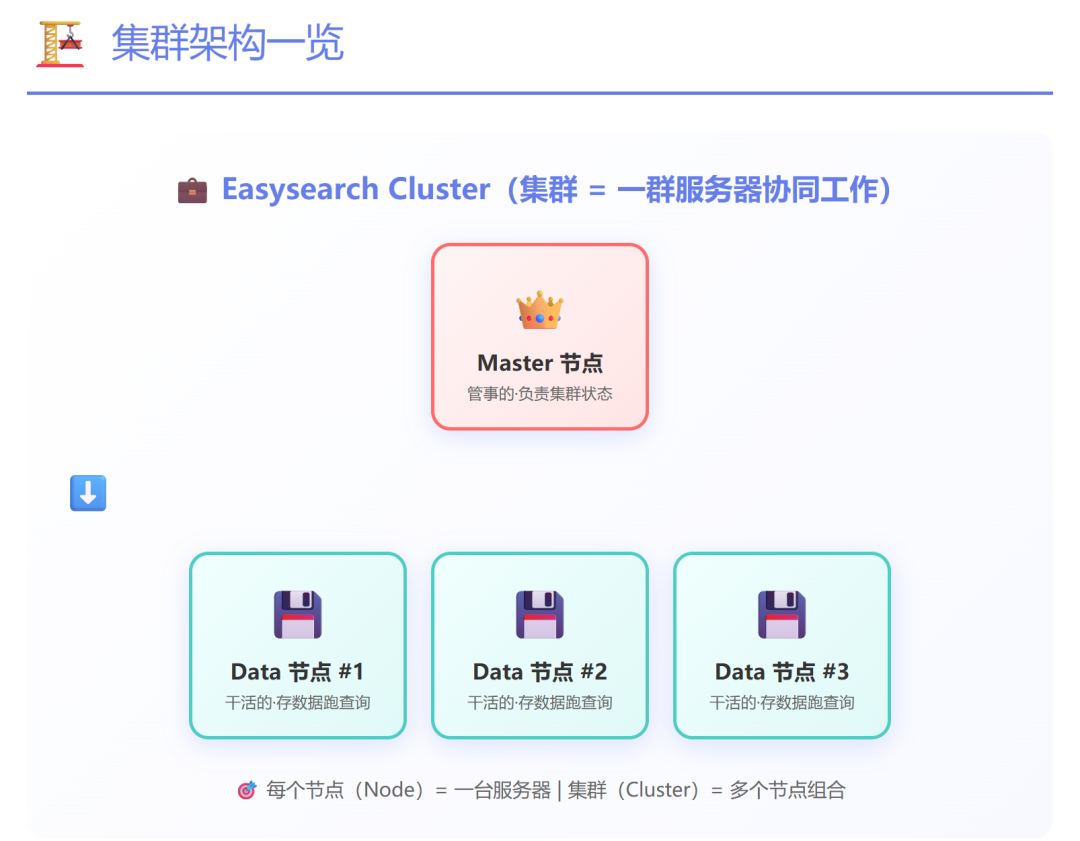
- 节点 (Node):集群中的单台服务器实例,根据角色可分为Master节点(管理集群状态)、Data节点(存储数据和执行查询)等。
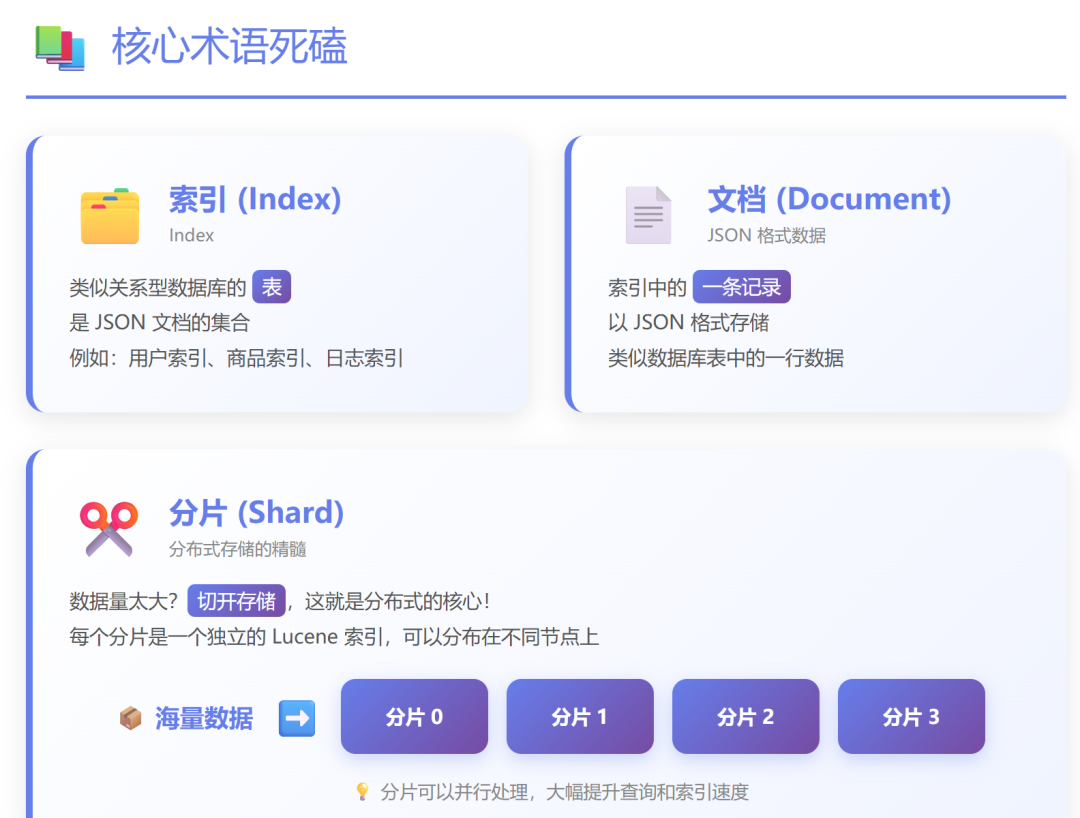
- 索引 (Index):类比关系型数据库中的“表”,是文档的集合。
- 分片 (Shard):索引可以被水平切分成多个分片,分布在不同节点上,这是实现分布式存储与并行计算的核心。
参考链接:核心概念
第二阶段:环境搭建 —— 工欲善其事
理论结合实践,本阶段目标是成功部署一个可用的Easysearch实例或集群。
1. 系统要求与准备
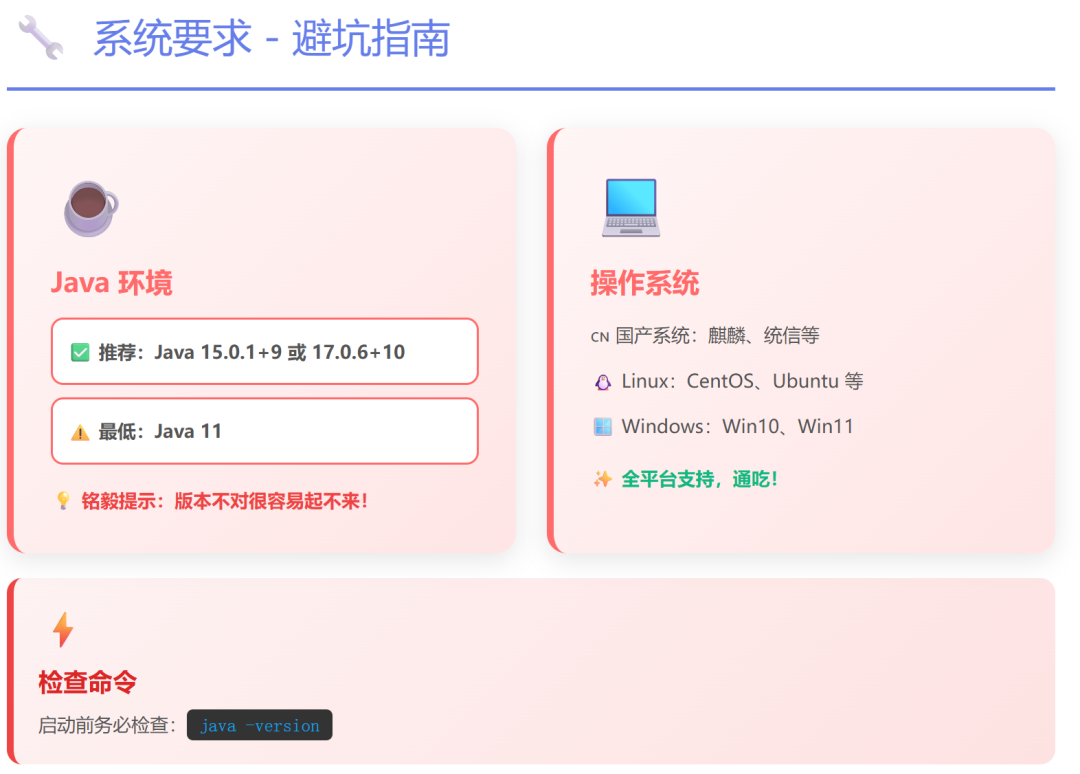
- Java 环境:这是运行Easysearch的前提。推荐使用 Java 15.0.1+9 或 Java 17.0.6+10,最低支持Java 11。务必在安装前通过
java -version 命令确认版本。
- 操作系统:广泛支持Linux(包括麒麟、统信等国产OS)、Windows及macOS。
参考链接:系统要求与配置
2. 多种部署方式
根据你的运维环境和熟悉程度,选择最适合的安装方式:
- Linux 基础安装:下载Tar包,解压后修改配置文件并启动。这是理解其组成的基础方式。
- Docker 容器化:现代运维的标配。可以使用Docker Compose快速编排和启动一个多节点集群,非常适合开发和测试环境。掌握Docker容器化部署是提升效率的关键。
- Kubernetes 部署:生产环境进阶选择,通过Helm Chart进行部署和管理,具备强大的弹性与自愈能力。
参考链接:
3. 初始配置与安全
- 配置文件:重点熟悉
config/easysearch.yml,掌握集群名称、网络绑定、节点角色、内存分配等关键配置。
- 证书配置:为集群启用HTTPS通信,生成和配置TLS证书,保障数据传输安全。
参考链接:集群管理
第三阶段:基础操作 —— 练好基本功
环境就绪后,开始学习最核心的数据操作。
1. 索引与映射管理
- Mapping (映射):相当于数据库的表结构设计。定义每个字段的数据类型(如
text, keyword, date)和分析器(如中文分词器),良好的设计直接决定搜索性能与准确性。
- Index Template (索引模板):用于自动化匹配新创建的索引,统一设置Mapping、分片数等配置,提升管理效率。

参考链接:索引模板管理
2. 数据CRUD操作
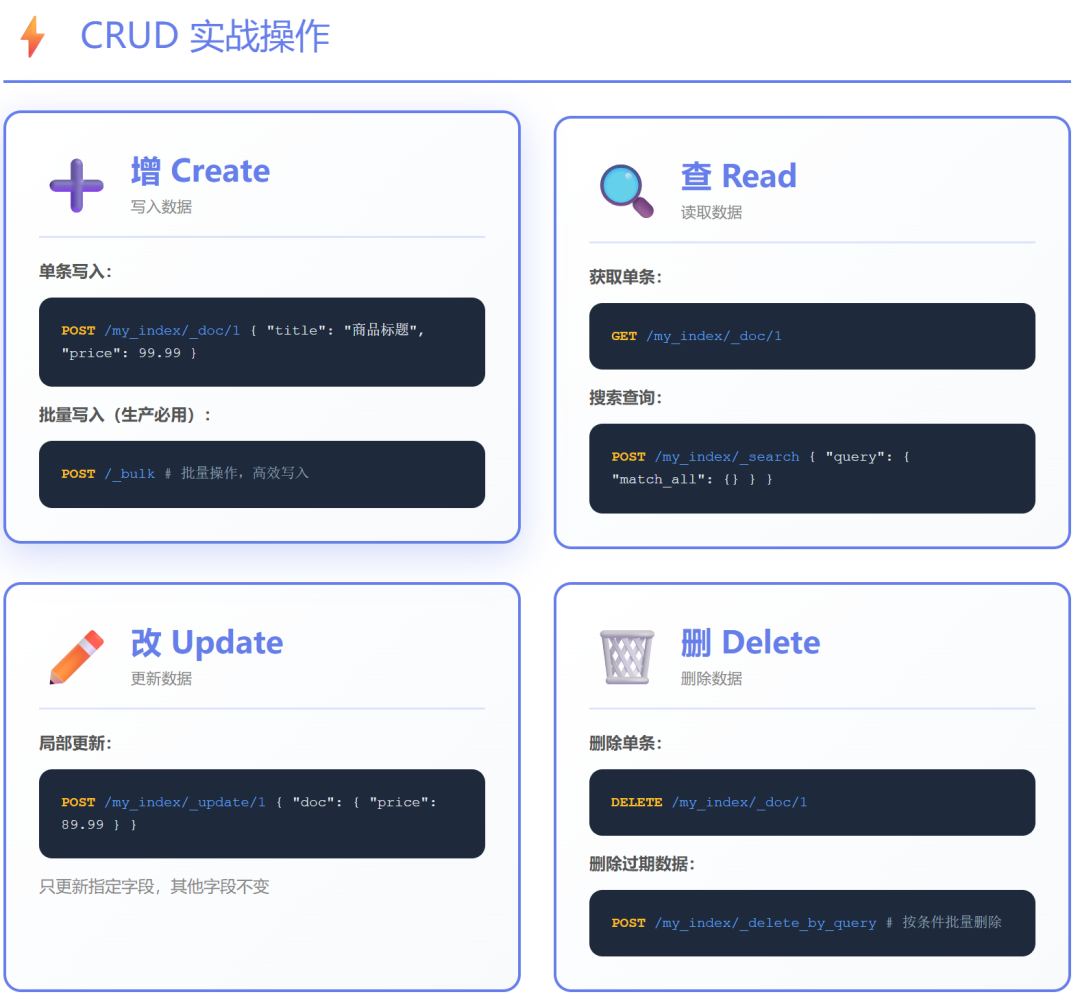
- 写入数据:掌握单文档索引 (
PUT /index/_doc/id) 和高效的批量写入 (_bulk API),后者是生产环境数据导入的标配。
- 查询数据:使用
GET API 根据ID检索文档。
- 更新与删除:学习局部更新 (
_update API) 和删除文档或索引的操作。
参考链接:官方文档 - API参考
3. 集群监控:Cat API
当需要快速查看集群状态时,Cat API 是运维人员的“瑞士军刀”。
GET /_cat/health:查看集群健康状态(green, yellow, red)。GET /_cat/nodes:查看节点列表与状态。GET /_cat/indices?v:查看所有索引的状态、文档数、存储大小等(?v参数用于显示表头)。
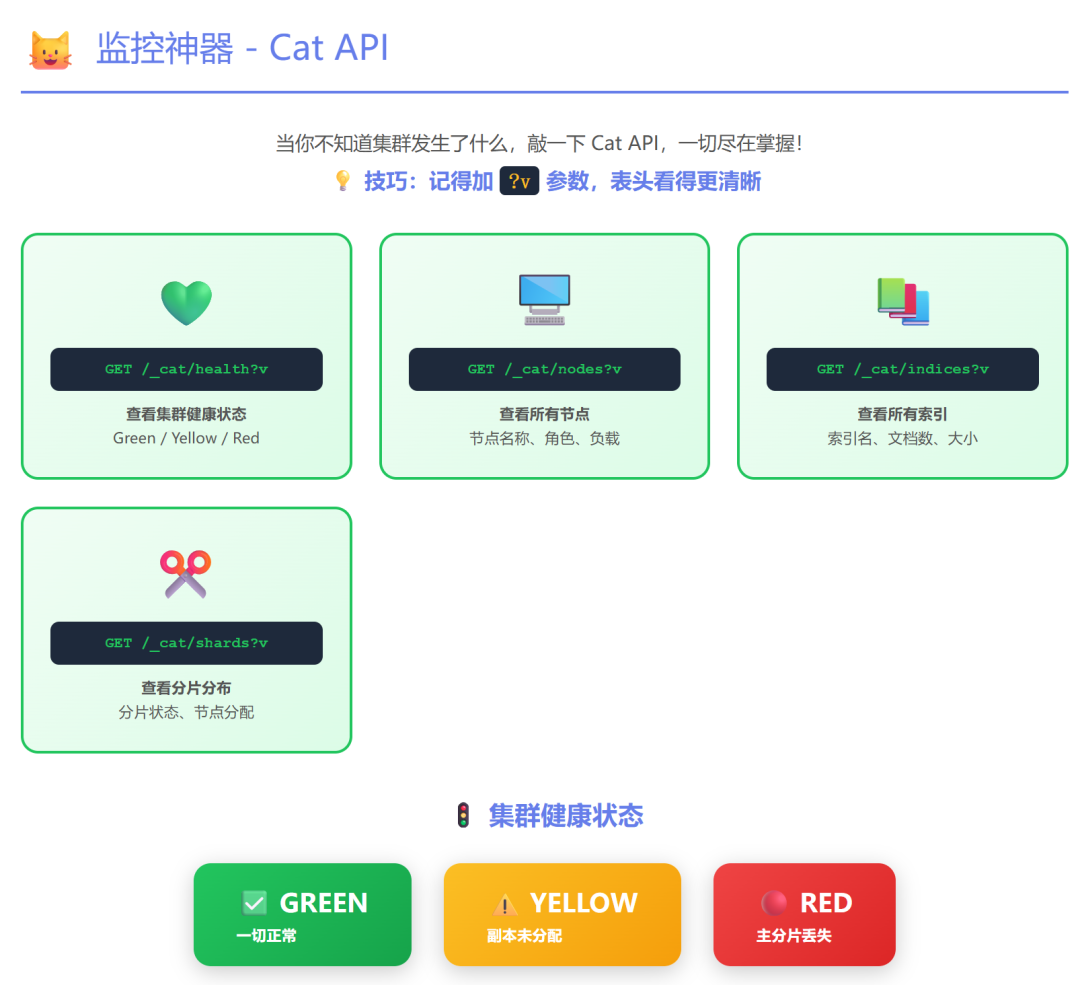
参考链接:Cat API 使用指南
第四阶段:进阶学习 —— 拉开差距的分水岭
掌握高阶功能与优化技巧,解决复杂场景问题。
1. 高级搜索能力
- 全文检索:深入理解查询DSL,掌握
match, term, range 等查询语法,并学习如何通过自定义分词器和权重提升搜索相关性。
- 向量检索:学习如何将文本、图像等数据转换为向量,并使用
knn_search 进行相似性搜索,赋能AI应用。
- 复合查询:熟练运用
bool query,组合 must(必须匹配)、should(应该匹配)、filter(过滤,不参与评分) 等子句构建复杂查询逻辑。
参考链接:搜索API参考
2. 性能调优实践
- 分片策略:根据数据量、节点数量与硬件配置,合理设置主分片数与副本数。分片过多或过少都会影响性能。
- JVM 与内存:调整JVM堆内存大小(通常不超过物理内存的50%),监控GC情况,避免长时间停顿。
- 查询优化:善用
filter 上下文(可利用缓存),避免深度分页,按需返回字段 (_source filtering),以提升查询响应速度。
参考链接:配置与调优
3. 安全架构配置
- RBAC (基于角色的权限控制):创建用户、角色,并为角色精细分配对索引、API的访问权限,实现最小权限原则。
- LDAP/AD 集成:与企业已有的LDAP或Active Directory服务对接,实现统一的用户认证与管理。
参考链接:安全功能指南
第五阶段:实战应用 —— 迈向架构师
将Easysearch融入真实业务系统,并设计稳健的生产环境架构。
1. 客户端集成与数据同步
- 客户端使用:掌握Java High Level REST Client 或官方提供的其他语言客户端进行应用集成。对于Java技术栈的开发者,可以探索与Spring Boot等框架的集成实践。
- 数据管道:学习使用Logstash、Canal或编写定制脚本,实现从MySQL、PostgreSQL等关系型数据库到Easysearch的实时或批量数据同步。
参考链接:Java客户端指南
2. 生产环境架构设计
- 高可用设计:通过配置多个Master-eligible节点和Data节点副本,确保任一节点故障不影响服务可用性。
- 冷热数据分层:根据数据访问频率,将热点索引部署在SSD节点,历史冷数据迁移至大容量HDD节点,优化成本与性能。
- 监控告警体系:集成Prometheus采集集群指标,通过Grafana进行可视化展示,并设置关键指标(如节点离线、集群状态变红)的告警规则,这是现代运维/DevOps的必备环节。
3. 典型业务场景
- 日志分析与监控:作为ELK/EFK栈中的“E”,集中存储和分析应用、系统日志,实现故障排查与运营洞察。
- 站内搜索引擎:为电商平台、内容管理系统(CMS)等提供商品、文章等内容的高性能全文检索、筛选与排序。
- 时序数据存储:适用于物联网(IoT)设备上报的指标数据存储与分析,支持按时间范围的高效查询。
参考链接:官方文档首页
总结与资源
遵循上述从理论到实践、从基础到进阶的路线图,持续学习与动手实验,可以在2-3个月内系统性地掌握INFINI Easysearch,并能胜任多数相关的开发与运维工作。在信创国产化趋势下,掌握这样一款优秀的国产分布式搜索引擎,无疑会增强个人技术竞争力。
核心学习资源:
|  发表于 2025-12-12 22:24:12
|
查看: 261|
回复: 0
发表于 2025-12-12 22:24:12
|
查看: 261|
回复: 0
