今天我们来深入探讨一个在分库分表架构中经常会遇到的经典难题:分页查询。不少开发者在面试或实际工作中都会被这个问题难住,如果思路不清晰,确实容易让人困惑。下面,我们将用最直白的语言,把这个问题的核心和解决方案梳理清楚。
1. 不是所有场景都需要复杂的分页方案
首先需要明确一点:分页查询的复杂度飙升,通常只在 跨库或跨表查询 时才会出现。
举个例子:
- 如果你的查询条件里总是包含 分片键(例如,根据特定的用户ID查询其数据,或者查询某个固定时间片内的数据),那么查询实际上只会落到某一个特定的分片上。
- 这种情况和查询单张数据库表没有任何区别,自然也就不存在所谓的“分页难题”。
所以,面对分页需求时,首先要问自己的是:这次查询到底是不是跨分片的? 如果不是,问题就简单多了。
2. 三种主流的解决方案
当我们确实面临跨分片分页的需求时,业界通常有以下三种主流思路:
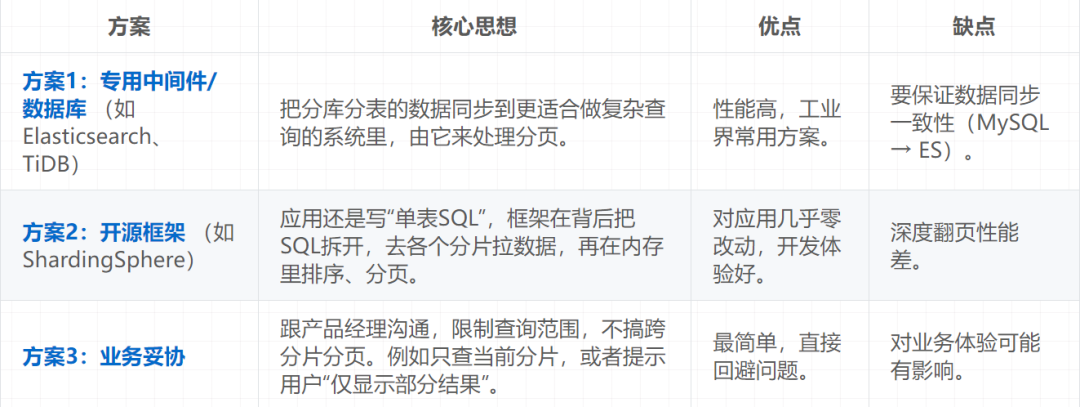
3. 全局查找法的原理与局限
在面试中,面试官最喜欢追问的往往是方案2中提到的 全局查找法(也叫二次归并法)。
原理示意图
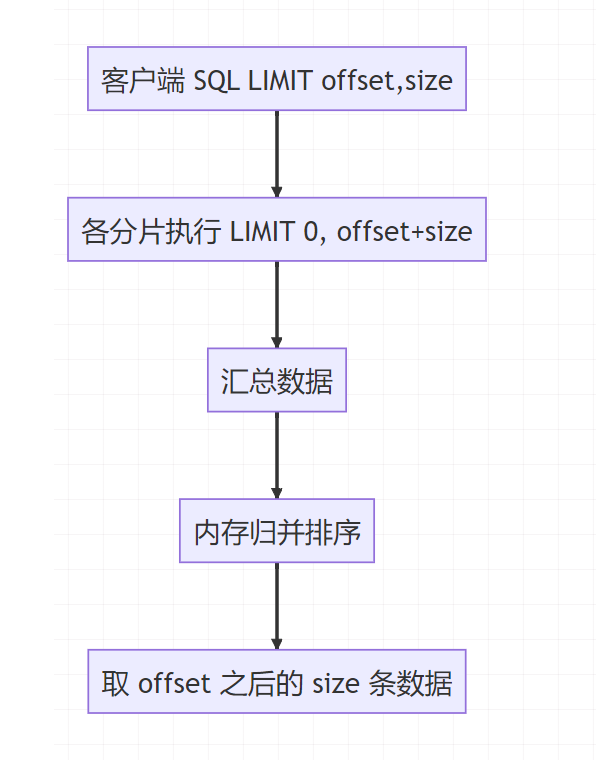
核心问题
这种方法在结果正确性上没有问题,但其性能存在严重瓶颈。试想,如果要查询第 100,000 页的数据:
- 每个分片都需要查询并返回
offset + size 条数据,即几十万甚至上百万条记录。
- 所有分片的数据汇总到内存后,需要进行全局排序,然后才能截取
offset 之后的那一页数据。
- 这个过程极易导致 OOM(内存溢出),并且查询速度会慢到无法接受。
所以结论是:全局查找法能用,但只适用于浅层翻页;一旦涉及深度翻页,系统性能就会急剧下降甚至崩溃。
4. 性能优化:禁止跳页,采用顺序翻页
解决深度翻页性能问题的最佳实践是:基于上一页最大 ID 进行翻页,也被称为“连续分页”或“游标分页”。
具体做法
查询第 1 页:
SELECT * FROM table ORDER BY id LIMIT size;
查询第 2 页及以后:
SELECT * FROM table WHERE id > {上一页最大id} ORDER BY id LIMIT size;
优点
- 每次查询只获取下一页的
size 条数据,性能极佳。
- 查询效率与
offset 的大小完全无关,彻底解决了深度翻页的性能噩梦。
缺点
- 无法直接跳转到任意页码(例如,不能直接跳到第 100 页)。
- 用户只能像刷信息流(如微博、抖音)那样,一页一页地顺序向下翻看。
尽管有跳页的限制,但对于绝大多数信息流、消息列表、订单列表等场景来说,这种方案已经足够优秀,是平衡性能与体验的优选。
5. 一个不推荐的方案:二次查询法
在一些资料中,你可能会看到被称为“二次查询法”的方案。其实现逻辑相对复杂,并且可能会因为数据在各个分片中分布不均匀而导致最终分页结果不准确或丢失数据。
简而言之:不推荐在实际生产中使用。
6. 面试中如何系统性地回答(STAR 法则)
如果在面试中被问到这个问题,可以按照 STAR 模型来组织你的答案,展现你系统性的思考:
- S(情境):在系统进行了分库分表改造后,需要支持跨分片的全局分页查询,这成为了一个技术挑战。
- T(任务):设计一个既能保证分页结果全局正确性,又能满足性能要求的解决方案。
- A(行动):
- 首先评估业务:与产品经理沟通,看能否通过限制查询范围(如按时间、用户维度)来规避跨分片查询,这是最简单直接的方式。
- 如果必须实现全局分页:
- 首选方案:引入像 Elasticsearch 或 TiDB 这样适合复杂查询的专用系统,将数据同步过去,由它们来处理分页。
- 次选方案:在数据库层面解决,使用 ShardingSphere 这类开源中间件的全局查找法。但必须明确指出该方法在深度翻页时存在的性能问题。
- 针对性能优化:提出“基于上一页最大ID的顺序翻页”方案,作为解决深度翻页问题的有效补充。
- R(结果):通过分层级的方案设计,既能满足业务的分页需求,又通过技术选型和优化保证了系统的性能和稳定性。
总结
- 明确问题边界:并非所有分库分表场景都有分页难题,只有跨分片查询时才需要考虑。
- 方案有三类:
- 专用中间件/数据库(如ES):推荐,性能高,但需保证数据同步。
- 开源框架(如ShardingSphere):对开发友好,但深度翻页是性能瓶颈。
- 业务妥协:最简单,直接规避问题,但可能影响体验。
- 警惕性能陷阱:全局查找法可用于浅分页,深度翻页时务必优化。
- 最佳实践:在业务允许的情况下,采用基于ID的顺序翻页(禁止跳页),这是平衡性能与功能的最优解。
一句话总结:能规避就规避,能交给专用系统就别自己硬扛,实在要在数据库层做,就优先使用连续翻页。 在构建复杂的 分布式系统 时,清晰地认识到不同方案的适用场景和权衡点至关重要。 |  发表于 2026-3-15 09:28:23
|
查看: 119|
回复: 0
发表于 2026-3-15 09:28:23
|
查看: 119|
回复: 0
