最近 DeepSeek V4 发布后,硅谷那边的讨论持续发酵,焦点逐渐集中到了几个更尖锐的层面:模型效率、芯片格局、IPO 时点,以及开源对闭源的挤压。
巧合的是,关于这些话题,业内顶尖的观点竟然在同一天汇聚到了 B 站。咱们先看一场来自硅谷的高质量对谈,回头再看国内昇腾的硬核解读。
首先,是「硅谷101」的一期视频博客,请来了两位重量级嘉宾:ZFLOW AI 创始人兼 CEO、资深芯片架构师肖志斌,以及前 OpenAI 研究员、Leonis Capital 合伙人 Jenny Xiao。
B 站视频入口
然后,就是今晚八点,华为昇腾的专场直播,将详解 DeepSeek V4 与昇腾算力。
直播入口

在这场硅谷对话中,几个核心观点直接点破了当前 AI 竞赛的本质:
- 没有效率,AGI 只能是个 demo。
- DeepSeek 像一把抵在硅谷模型公司背后的枪。
- 硅谷 AI 公司钱太多,反而没动力做效率。
- Anthropic 凭专注反超 OpenAI,估值冲向 1 万亿。
- 芯片不再是一卡打天下,训练、推理、长上下文、Agentic workload 正各自分化。
参与对谈的两位嘉宾背景非常互补:肖志斌是芯片架构的行家,而 Jenny Xiao 则从投资和研究的双重视角提供了犀利的判断。
V4 凭什么这么便宜?
肖志斌研读完 V4 论文后,给出的评价是:方向在预料之内,但工程完成度在意料之外。
V4 论文着重强调了三点核心技术创新:CSA+HCA 的混合注意力机制、mHC 流形约束超连接,以及 Muon 优化器。
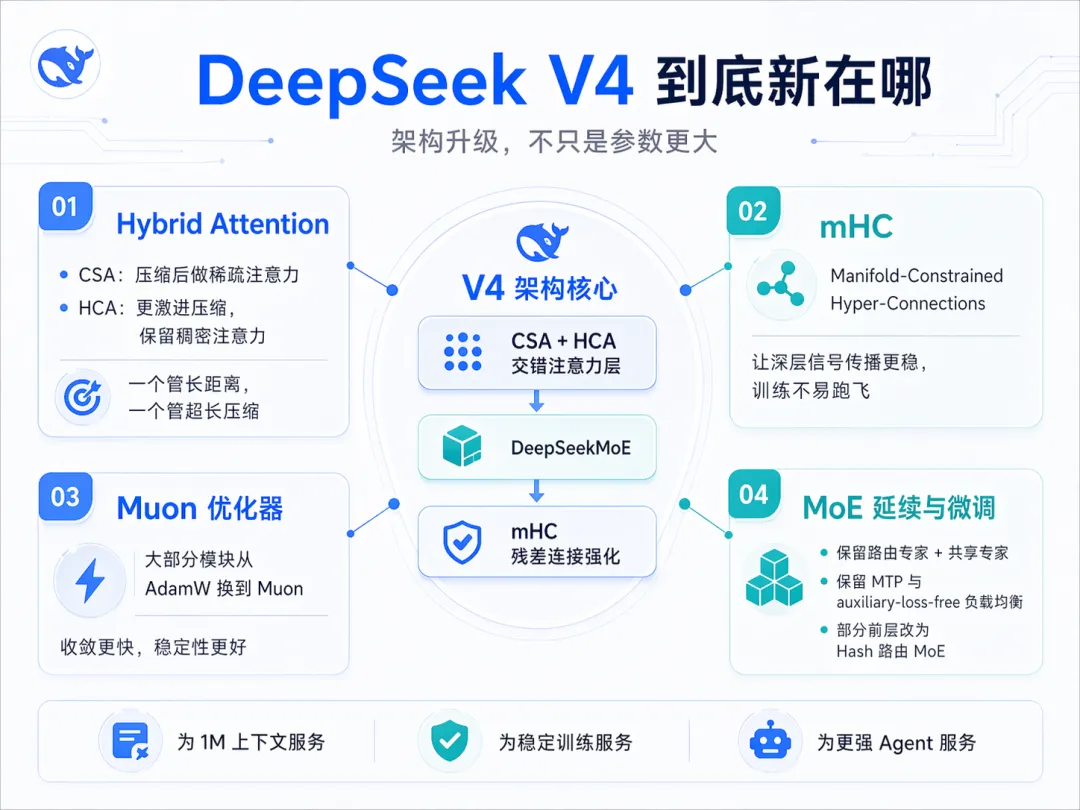
具体来看,CSA(Compressed Sparse Attention) 将多个 token 的 KV cache 压缩成一条 entry,再通过稀疏注意力检索,极大降低了计算量。而 HCA(Heavily Compressed Attention) 则对上下文进行更深度的压缩后进行稠密注意力计算。两者结合,再辅以滑动窗口来保证对最近 token 的强相关性,成功地将长上下文注意力的计算复杂度从平方关系上拉了下来,推理成本自然就降了。
mHC 解决的则是深层模型训练的稳定性问题。它把传统单一的残差连接变成了多条高速通路,并引入流形约束来保证数值稳定,让模型在深层训练时不易发散。
至于 Muon 优化器,这是 Kimi 最早提出的训练方法。V4 并没有完全用它替代 AdamW,而是在部分模块引入,与 AdamW 形成互补,合力将训练收敛速度推向了新高。
这三板斧,指向了一个共同的焦点:Token Efficiency(词元效率)。肖老师甚至认为,大模型架构本身的重要性可能被高估了,数据才是关键。而 V4 所做的,正是让模型架构去匹配硬件架构,让数据流转更高。他甚至提到,V4 论文也给硬件厂商提了建议:GPU 间的带宽并非越高越好,这里存在一个精确的配比,超过阈值反会挤占计算单元的面积。
Jenny 则从应用层面呼应了这个观点:Chatbot 类问答的 token 消耗有限,但到了 AI Agent 时代,长任务、多工具调用和反思规划会让 token 消耗飙升 10 到 100 倍。如果每个 token 都很贵,模型就无法长时间思考,更别提大规模服务用户了。AGI,必须构建在效率之上。
DeepSeek 给硅谷画死亡线
Jenny Xiao 曾提出过一个尖锐的概念叫 kill line(死亡线),指的是开源模型给闭源基础模型公司画出的生存红线。AI 领域的商业模式呈现高度二元性:一旦核心业务能力被开源模型超越,其商业价值就可能直接归零。
就像她拿 Anthropic 举例:如果哪天 Claude 不再是编程最好的模型,那谁会为 Claude Code 买单?
回顾 DeepSeek V4 和 GPT-5.5 在同一天发布的情景,对比尤其鲜明。GPT-5.5 长文本版的价格高达每百万 token 180 美元,是前代的近两倍,而 V4 则便宜得多(还有折上折)。无论闭源模型公司愿不愿意,一场残酷的生存战已经打响。
Jenny 的金句是:“DeepSeek 像一把抵在硅谷模型公司背后的枪。这些公司如果跑得不够快,DeepSeek 会追上来,把它们的业务彻底摧毁。”
当然,肖志斌也理性地补充道,不能说 V4 全面超越了谁,在某些方面它和硅谷模型仍有差距。但 V4 真正引爆的是效率问题,它迫使所有模型厂商都必须回答:你的 token 效率到底够不够高?
一个有趣的插曲是,早在 V3 之前,DeepSeek 在海外技术圈内就已声名鹊起。之前 OpenAI DevDay 期间,有 OAI 的朋友私下称赞道:“DeepSeek is really solid”。
在经历了 V3/R1 的“DeepSeek moment”后,硅谷曾有两种声音:一是了不起的工程突破,二是 benchmark 灌水。而 V4 发布后,后一种声音明显弱了下去,取而代之的是更多的 congratulations 和深刻的自我反思。
Anthropic 凭什么反超 OpenAI
在资本市场,Anthropic 的估值近来反超 OpenAI,达到了惊人的万亿美元级别。Jenny 将其归结为三个字:Claude Code、企业信任与专注。
- 第一,Claude Code。Anthropic 的模型本身已经足够出色,但 Claude Code 这款产品才是真正驱动收入井喷的引擎。
- 第二,企业信任。Jenny 的基金接触的海量企业客户反复传递着一个信号:选择 Anthropic 是看重它的安全承诺。这与其在安全议题上的一贯立场密不可分。
- 第三,专注。相比于 OpenAI 在过去一年经历的人事动荡和多线作战(硬件、自研芯片、购物 App 等),Anthropic 显得更为成熟和克制,始终聚焦于安全、企业与编程。
OpenAI 试图打造一个“所有人的所有东西”的平台,这种分散导致了其技术领先优势的流失。而 Anthropic 的收入高度集中于企业客户,这恰恰是美国投资者眼中优于消费收入的高质量商业模式。
在 Jenny 看来,编程是通向 AGI 最关键的一步,谁拿下了编程,谁就可能成为 AGI 时代的主导者。因为“一旦你能写代码,你就能做大量通用任务”,企业里的 CRM 更新、邮件转发、会议总结,本质上都是通过代码搭起来的。她也借此评价了 Meta 的 Muse Spark 模型,认为它相对其他开源和二线模型并无显著优势,反倒是 Meta 内部将员工工作过程作为训练数据的争议性计划,可能才是其建立数据护城河的少数路径之一。
至于 xAI,Jenny 用“混乱”来形容。Grok 的实时数据查询功能仍有价值,但其他方面乏善可陈。
钱多反而拖累硅谷
这场讨论最反直觉的一个结论是:硅谷 AI 公司正陷入一个怪圈——钱越多,做效率的动力反而越弱。
Jenny 直言:“硅谷 AI 公司钱太多,导致没有动力去思考效率,反而给了 DeepSeek 优势。” 在她基金的内部对比图中,Anthropic 的资本效率显著高于 OpenAI。原因可以追溯到公司哲学:Anthropic 从一开始就保持克制,不在 GPU 等基础设施上过度承诺;而 OpenAI 则习惯 move fast and break things,大肆采购。
如今 OpenAI 向沙特财团、私募股权基金四处求钱,姿态近乎“出于无奈”。Jenny 甚至推测,投资人在 IPO 前可能会对 OpenAI 施压更换 CEO,因为 Sam Altman 在基础设施支出上的大手笔令他们感到不安。毕竟,再砸 100 亿美元下去,边际收益究竟能换来多少新增市场和收入,谁也说不清。
投资人心态已经变了。过去是“曲线还在指数增长,继续投”,现在则变成了“ROI 在哪?”。
而 DeepSeek 用模型给出了另一种回答:无限堆砌基础设施的 ROI,可能已经不划算了。正因为算力受限,反而倒逼出了创新。 这让人感慨,创新都是逼出来的,便宜本身就是技术革命的条件之一。 能真正推动变革的技术,是那些便宜到足以让人们大规模使用的技术。AGI 不仅要足够聪明,更要足够便宜。
80% 任务跑开源模型
在 Jenny 投资组合的公司里,一个惊人的比例已经出现:80% 的任务跑在中小开源模型上,只有 20% 最复杂的任务才上闭源模型。放在一年前,恐怕没人会信。
资本市场也对闭源模型的未来打上了问号。甚至有人在硅谷四处询问:“我们手里有 1000 万美元的 OpenAI 股票,你们基金在买吗,或者认识谁在买吗?”
AI 公司的估值逻辑是二元的。基础模型公司的存在理由就是模型最强,一旦不再最强,被开源模型超越,估值就可能归零,哪怕是 OpenAI。应用层公司处境一样,一旦基础模型公司复制了某个应用功能,那个应用层公司的价值也可能瞬间归零。
英伟达,难守推理江山
短期内,英伟达的地位依然稳固,其 CUDA、NVLink、InfiniBand 和成熟的供应链构成了强大的护城河。但从长期看,根基已开始松动。
V4 通过 CSA+HCA 将长上下文注意力成本打了下来,这直接降低了硬件跑大规模推理的门槛,给了非英伟达芯片承接计算负载的机会。AMD、Google TPU、超大规模云厂商的自研芯片都在这条赛道上。尤其像 Google 这样拥有完整软硬件协同能力的公司,可以用自己的模型、云、数据中心、编译器、芯片做一体化优化,从而降低对英伟达的依赖。当然,这条路也绝非坦途,这正应了黄仁勋那句话:“同样性能的芯片,价格白送也比不过英伟达”。
对于国产芯片而言,要承接 V4、Kimi 这类前沿模型的推理负载,难点并非单点突破,而是一整个 AI infra 软件栈 的建设,具体来说有五个层面:
- 算子:需支持 V4 论文里涉及的 GEMM 之外的各类算子,如 fused MoE attention、Sparse attention、FP4 等。
- 通信:MoE 模型在 dispatch、combine 等环节通信负担极重,算力上去了,通信跟不上照样被拖垮。
- Serving Runtime:像 vLLM、SGLang 上的 continuous batching、PD 分离等技术都需深度适配。
- 训练稳定性:大规模训练需长时间稳定运行,对 fault tolerance、checkpoint 有极高要求。
- 开发者生态:compiler、debug、profile 等整套工具链都得成熟。
最终,芯片格局将走向分化:训练、推理、长上下文、Agentic workload,每一类任务对计算、存储、通信的需求都不再相同。
等等还有……昇腾专场
以上,便是硅谷视角下的精彩观点交锋。而就在今晚 8 点,B 站还有一场华为昇腾技术专场直播,主题是《DeepSeek V4 与国产算力的突围》。

五位嘉宾分别是:
- 赵英俊:华为昇腾产品规划专家
- 刁莹煜:CANN 社区大模型推理优化专家
- 冀元祎:小巧灵应用部署专家
- 张德鹏:CANN 社区大模型训练优化专家
- Git 源宝:B 站 AI 百万粉 UP 主,主持人
硅谷视角看一遍,国产算力视角再看一遍。同一个事件,同一天,同一个平台,都在 B 站。今晚 8 点,去搜「Git 源宝」直接进直播间,相信这两场对话会擦出不一样的火花。在云栈社区,我们也会持续关注类似的前沿技术趋势,和大家一起探讨。
 发表于 2026-4-30 23:51:08
|
查看: 132|
回复: 0
发表于 2026-4-30 23:51:08
|
查看: 132|
回复: 0
