前几天我写过一篇文章,提到有人用 23 万条工具调用数据证明 Claude Code 的质量确实在下降:thinking 深度暴跌 75%,Read:Edit 比例从 6.6 降到 2.0,三分之一的修改属于“盲改”。
当时的判断是问题出在 thinking token 被削减了,不过 Anthropic 那边一直没动静。
现在,Anthropic 官方终于正式回应了。
4 月 23 号,Anthropic 发布了一篇事后分析(postmortem),确认了三个各自独立的问题——时间跨度从 3 月初一直延续到 4 月中,且全部已在 4 月 20 号修复。同时,他们还宣布重置所有订阅用户的使用额度。
下面我们就来逐一拆解这三个问题,顺带对照一下之前社区那份数据分析,看看彼此能对上多少。
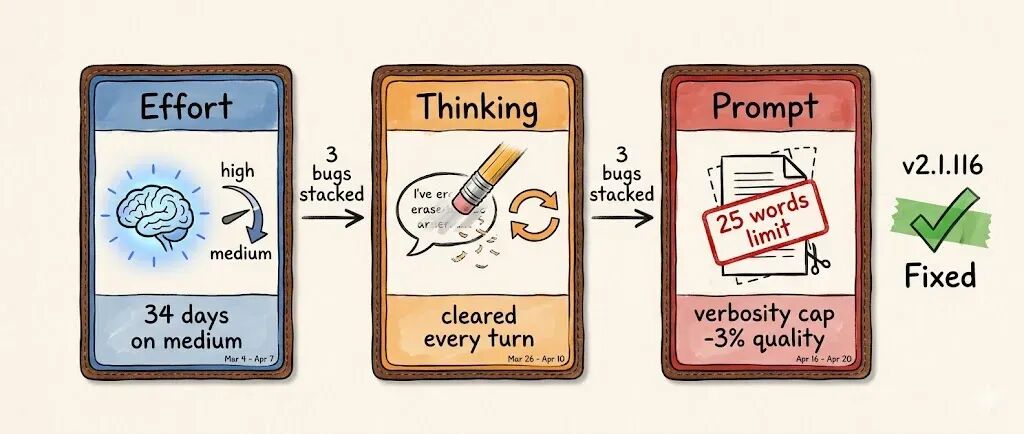
问题一:默认推理深度从 high 悄悄改成了 medium
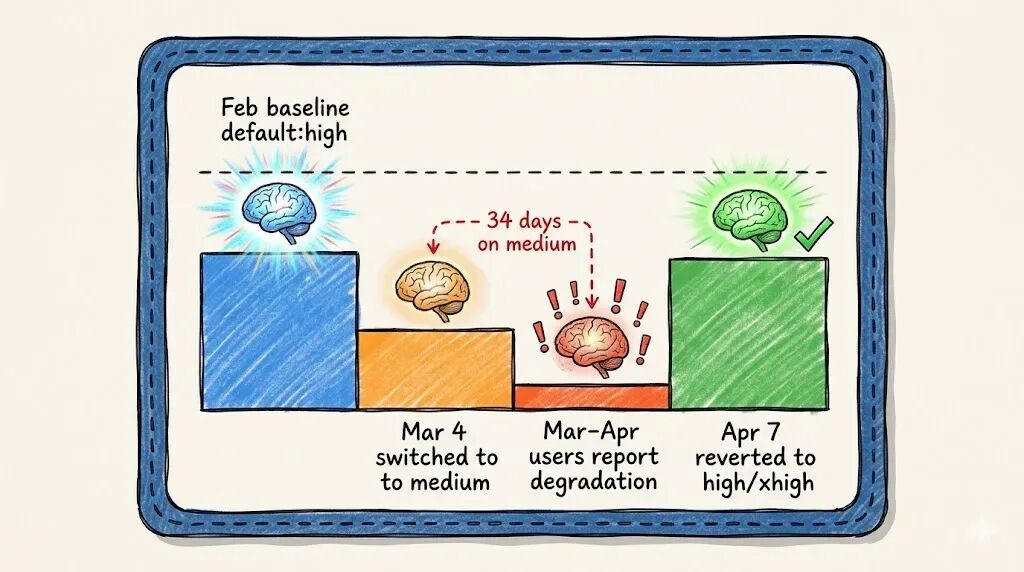
3 月 4 号,Anthropic 把 Claude Code 的默认推理努力(reasoning effort)从 high 调低到了 medium。
原因是什么呢?有用户反馈 Opus 4.6 在 high 模式下偶尔思考时间过长,UI 看起来像假死,token 消耗也不成比例。Anthropic 内部测试后得出结论:medium 模式只损失极少的智能,但延迟能显著降低,还能帮用户节省配额。这个改动当时看来很合理,他们也在弹窗里说明了理由。
但问题随之而来——用户开始普遍反映 Claude Code “变笨了”。
Anthropic 的应对策略倒是挺有意思:他们增加了启动提示、加入了 effort 选择器、恢复了 ultrathink 选项,潜台词就是“我们改了默认值,但你完全可以自己切回去”。可现实是,绝大多数用户根本不会去动默认设置。
一直到 4 月 7 号,在收到更多客户投诉之后,Anthropic 才把默认值改回高推理模式。现在 Opus 4.7 默认是 xhigh,其他模型默认是 high。
受这个问题影响的,主要是 Sonnet 4.6 和 Opus 4.6。
社区数据怎么说
之前提到的那份 GitHub Issue(#42796)中,用户数据显示 thinking 深度在 2 月下旬开始断崖式下跌——从 2200 字符掉到 720 字符。从时间点来看,这与 Anthropic 此次披露的调整完全吻合。
不过,社区报告还抛出了一个更尖锐的观点:thinking 深度下降的幅度,远远超出了 high 到 medium 这一档能解释的范围。2200 降到 720,那可是 67% 的跌幅,绝不像只是换一档 effort level 就能产生的效果。
Anthropic 这次的复盘并没有直接回应该数据差异。他们承认了默认值的改动,但没能解释为什么 thinking 深度的实际变化幅度会如此剧烈。这个缺口,恐怕要留给社区继续追问了。
问题二:缓存优化的一个 Bug,导致 thinking 持续丢失
三个问题里,我认为这一个才是真正的“罪魁祸首”——它技术上最复杂,影响也最深远。
Claude Code 在对话过程中会保留历史 thinking,这样每一轮新对话时,模型都能回顾之前的推理过程:它为什么做了那些编辑、为什么选了那些工具。
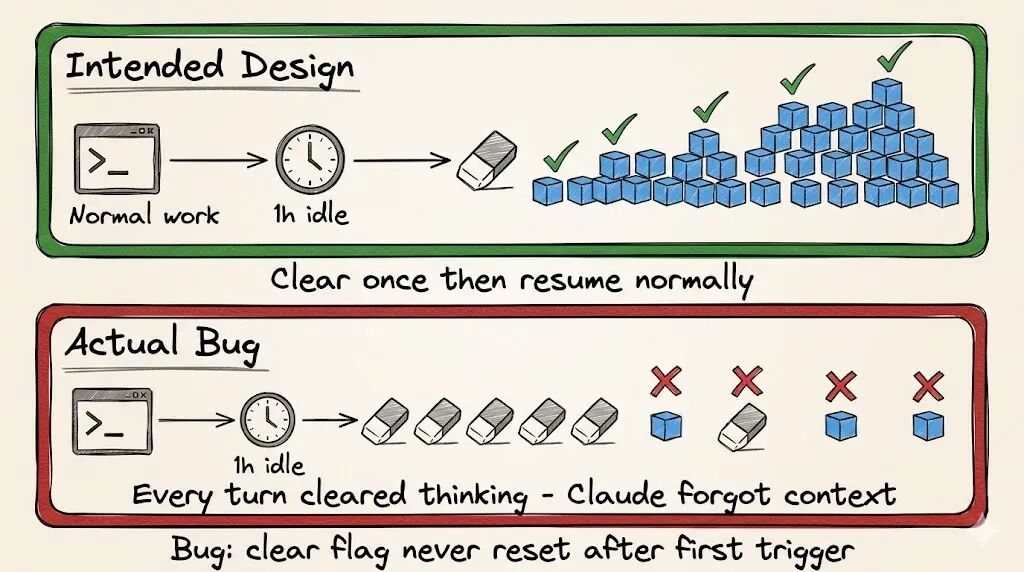
3 月 26 号,Anthropic 做了一个缓存优化:如果某个 session 空闲超过 1 小时,就在恢复时清除旧的 thinking,以降低未命中缓存时的 token 传输量。技术实现上,它依赖 clear_thinking_20251015 API header 加 keep:1,只保留最近一个 thinking block。
设计意图本身没毛病,但代码却写出了一个严重 Bug。
清除操作原本该只执行一次,实际上却在 session 的每一轮对话中都触发了。
这意味着一旦 session 触发了空闲阈值,后续的每一个请求都会告诉 API 只保留最近一个 thinking block,之前所有的推理历史被一并抛弃。
更要命的是,如果你在 Claude 执行 tool use 的过程中发了一条新消息,那会开启一个新 turn。而这个新 turn 也带着那个“故障标识”,导致当前 turn 的 thinking 也被扔掉了。
Claude 依然在继续执行着命令,但它越来越不记得自己为什么要做这些事。
用户这边看到的症状,就是“健忘、重复、奇怪的工具选择”。这些和之前社区报告的描述,几乎完全一致。
配额消耗加快,原因也在这里
清除 thinking 意味着后续请求不再命中缓存(因为内容变了)。每次都得重新写入,这对于 96 万 token 的上下文窗口来说,每一次 cache miss 都是一笔巨额开销。
这也跟之前社区另一份关于 cache TTL 从 1 小时被砍到 5 分钟的发现直接相关。那份报告发现 Pro Max 用户的配额消耗速度异常快,现在看来有部分答案了:不光是 TTL 变了,这些被持续清除的 thinking 也在制造大量的 cache miss。
为什么这个 Bug 花了两周才被发现?
Anthropic 自己给出了原因:有两个不相关的内部实验干扰了复现。一个是服务端的消息队列实验,另一个是 thinking 显示方式的改动。后者在大多数 CLI session 中压制了这个 Bug 的表现,导致内部测试外部版本时也未能触发。
所以,即便这个 Bug 过了多轮代码审查(人工加自动)、单元测试、端到端测试、自动验证和内部试用,它依然没有被揪出来。最终还是靠用户持续反馈才定位到了问题。
他们在 4 月 10 号修复了这个 Bug(版本 v2.1.101)。
问题三:系统 Prompt 限制了输出长度
4 月 16 号,这个问题随 Opus 4.7 一同上线。Anthropic 在系统 prompt 里加了一行:Length limits: keep text between tool calls to 25 words or less. Keep final responses to 100 words or less unless the task requires more detail.
初衷是治一治 Opus 4.7 的啰嗦毛病——这个模型话确实多,用过的人应该深有体会。
他们内部测试了好几周,跑了一批 eval,没发现任何异常。于是 4 月 16 号就正式上线了。
结果,在更广泛的 eval 集合上测试时,那行 prompt 直接导致 Opus 4.6 和 4.7 的编码质量下降了 3%。4 月 20 号,他们赶紧回滚了该改动。
这个问题影响了 Sonnet 4.6、Opus 4.6 和 Opus 4.7,总共持续了 4 天。
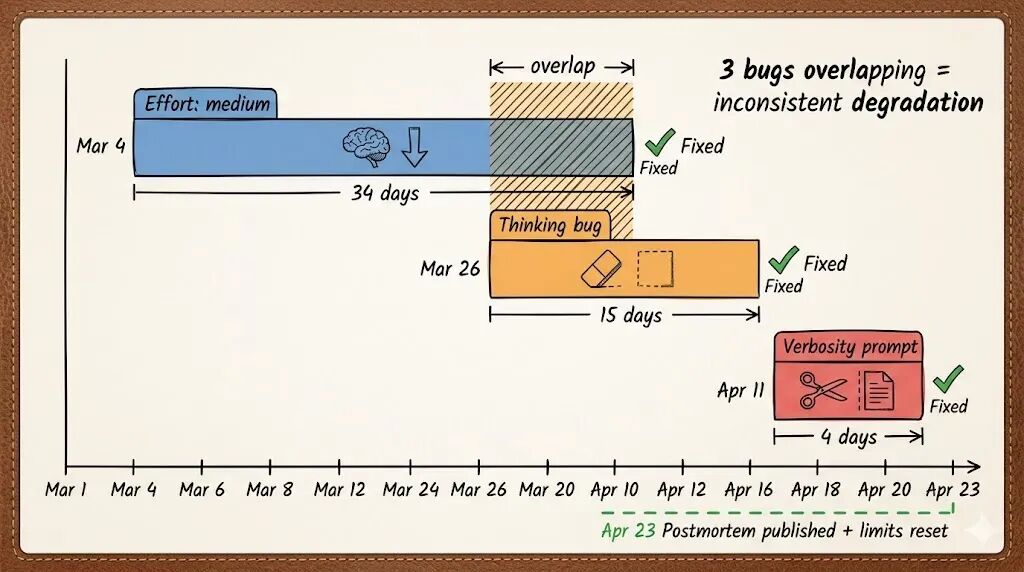
三个 Bug 叠在一起,是什么效果?
单独拎出来看,每个问题都不至于造成灾难性后果。但它们凑在一起,影响着不同的用户群体,又在不同时间段各自生效,其叠加的最终效果就是:整个 3 月到 4 月中旬,Claude Code 看起来在广泛地、且非常不一致地变差。
为什么说“不一致”很关键?因为有一部分用户完全没受影响(他们没触发空闲阈值、手动切了 high effort、没更新到新 prompt),而另一部分用户三个问题全中。这也就解释了为什么社区里的争论常常是“我没感觉变差啊” vs “明明就明显变差了”。
现在有了官方解释,这些争议终于水落石出:你们说得都对,只是碰上的 Bug 组合不一样罢了。
Anthropic 说以后会怎么改进?
- 让更多内部员工使用公开版本。之前内部用的是一个包含新功能测试的特殊版本,导致部分 Bug 只在公开版本上触发。
- 系统 prompt 的任何改动,都要跑更广泛的 eval 矩阵。每个模型、每条 prompt 改动都必须过一遍,并加入消融测试(ablation),还要新增一个发布浸泡期。
- 改进 Code Review 工具。他们回测了那个有 Bug 的 PR,用 Opus 4.7 做代码审查能发现问题,而 Opus 4.6 却发现了不了。后续会让 Code Review 支持引入更多仓库作为上下文。
- 建立公开沟通渠道。新开了
@ClaudeDevs X 账号,用来解释产品决策,GitHub 上也会同步更新。
现在你该做什么?
如果你之前受到了影响,好消息是三个问题都修复了,更新到 v2.1.116 或更新的版本就行。另外,别忘了 Anthropic 已经重置了所有订阅用户的使用额度。
几个实操建议供你参考:用 claude --version 确认一下你的 Claude Code 版本是否 ≥ 2.1.116。检查一下默认 effort level,如果之前手动改过,可以重新设一下。Opus 4.7 现在默认 xhigh,其他模型默认 high。还有,长 session 不必再刻意断开了,thinking 清除的 Bug 已修复,空闲恢复后再也不会弄丢推理历史了。
Anthropic 事后分析原文: https://anthropic.com/engineering/april-23-postmortem
在这个充斥着 AI 模型快速迭代的周期里,类似的“静默退化”现象其实并不少见。如果你对 AI 模型性能分析、智能体行为变化这类话题感兴趣,可以多关注 人工智能 板块内的相关讨论。
 发表于 2026-5-1 00:13:01
|
查看: 121|
回复: 0
发表于 2026-5-1 00:13:01
|
查看: 121|
回复: 0
