随着大语言模型(LLM)参数规模突破千亿级、上下文长度扩展至32K甚至更长,激活着巨量显存已成为大模型训练的核心瓶颈。激活数据量随序列长度呈二次方增长,极易超出GPU内存容量,这一问题在多模态、强化学习等场景中尤为尖锐。传统解决方案如完全重计算或增大并行度,往往带来显著的计算开销或通信成本,导致整体训练效率低下。
为了在内存占用与训练效率间取得最佳平衡,技术团队提出了细粒度激活卸载方案(Fine-grained Activation Offloading)。该方案在 Megatron-Core 框架中实现了模块/算子级别的激活卸载,完美兼容流水线并行(PP)、虚拟流水线并行(VPP)及细粒度重计算,最终达成内存节省与性能损失的联合最优。本文将从问题背景、实现原理、兼容性设计、性能验证到最佳实践,对该方案进行全面解析。
本文介绍的工作已集成至 Megatron-LM 仓库,可供开发者直接使用。

在标准的大语言模型训练过程中,激活数据(前向传播产生、用于反向传播梯度计算的中间结果)的内存开销与序列长度、特征维度成正比。当序列长度或特征维度持续增长时,动态内存开销急剧增加,可能直接触及GPU内存上限。
此类问题主要出现在以下两种典型场景:
- 长序列训练场景:例如在多模态模型或强化学习训练中,序列长度可达几十K甚至上百K,导致激活动态显存开销急剧膨胀。此时,相比于同时影响模型参数和激活的“增加并行度”方案,我们更需要一种类似重计算、专门针对激活值的显存优化技术,并期望获得性能优势。
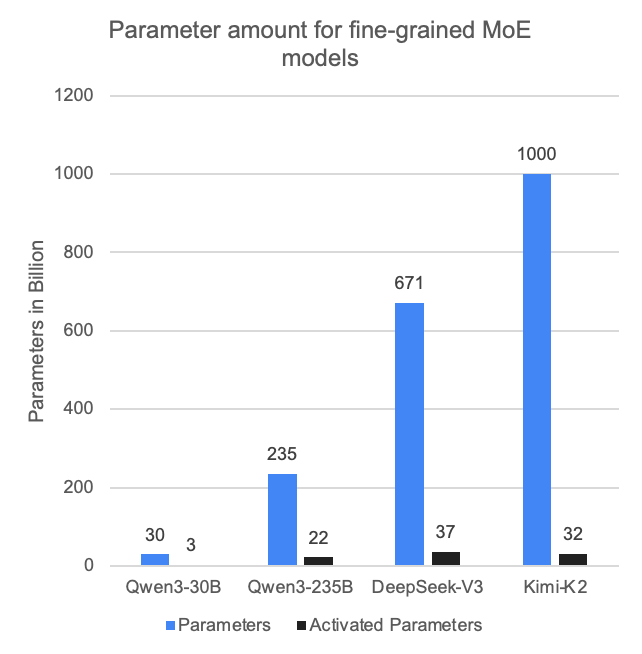
- 细粒度MoE模型训练场景:以DeepSeek-V3、Kimi-K2为代表的先进MoE模型,其总参数量与激活量的比值非常悬殊(分别约为18和31)。这意味着与同等参数量的稠密模型相比,MoE模型的计算密度大幅降低。若不进行额外显存优化,每张卡分配的计算量过少,不仅会降低核函数效率,还会放大通信开销并暴露主机端瓶颈,对性能优化构成巨大挑战。
针对上述挑战,本文提出的细粒度激活卸载方案支持模块级(module-level)和算子级(operator-level)的卸载。类似于细粒度重计算,用户可指定卸载特定模块的激活,并与重计算功能组合使用,实现精准、高效、全面的内存管理。
本文介绍的工作已集成至 Megatron-LM 仓库,可供开发者直接使用。

2.1 方案核心思想
细粒度激活卸载的核心设计遵循三大原则:按需卸载、重叠计算、全场景兼容。
- 粒度精细化:以模型模块(如
qkv_linear, core_attn, moe_act)为单位进行激活卸载,而非以整层或整块为单位。
- 计算-卸载重叠:前向卸载、反向重载操作与后续计算并行执行,通过异步传输隐藏数据搬运开销。
- 全场景兼容:支持PP=1、PP>1及VPP>1等各种并行配置,兼容BF16、Blockwise-FP8、MXFP8、NVFP4等多种精度格式,同时适配MoE、MLA等复杂模型结构,并可结合1F1B A2A重叠、CUDA Graph等Megatron-Core的最新优化。
2.2 前向传播的卸载逻辑
前向传播中,激活卸载的关键是“模块计算完成后立即卸载,且不影响后续计算”。
- 卸载触发时机:当一个模块(如
core_attn)完成计算后,立即将其输入激活和中间激活卸载至CPU内存。具体哪些张量需要卸载,取决于其是否通过 save_for_backward 保存以供反向阶段使用。
- 计算-卸载重叠:卸载操作与下一个模块(如
attn_proj)的计算并行执行,通过独立的CUDA流(D2H流)实现异步传输。

- 特殊规则:对于在时间线上前向传播块与反向传播块相邻的情况,该块内部的最后一层激活将不进行卸载(如下图所示标红部分)。因为该层激活在反向传播阶段会立即被使用,若卸载则需立刻重载,反而可能增加延迟。

2.3 反向传播的重载逻辑
反向传播过程中,重载激活需与前向卸载操作对称且错峰,避免局部时刻内存开销翻倍。
- 隔层重载:当前模块(如
expert_fc2)完成反向计算后,再重载下一层对应模块(如 expert_fc1)的激活。
- 避免内存翻倍:通过“计算完成后再重载”的时序设计,确保同一时刻GPU上仅保留一层激活的峰值数据,无需维护2倍的激活数据量。
- 计算-重载重叠:重载操作与下一个模块的反向计算并行执行,通过独立的CUDA流(H2D流)隐藏传输开销。

2.4 同步机制
激活的卸载/重载操作与计算核函数存在数据依赖,必须通过同步机制保证正确性。本方案设计了四条核心同步规则:
- 启动卸载时,必须确保当前模块已完成前向计算。
- 启动重载时,必须确保当前模块已完成反向计算。
- 启动重载时,必须确保对应的卸载操作已完成(即CPU端的张量已准备就绪)。
- 启动反向计算前,必须确保其所需的所有激活值已完成重载(即GPU端的张量已准备就绪)。
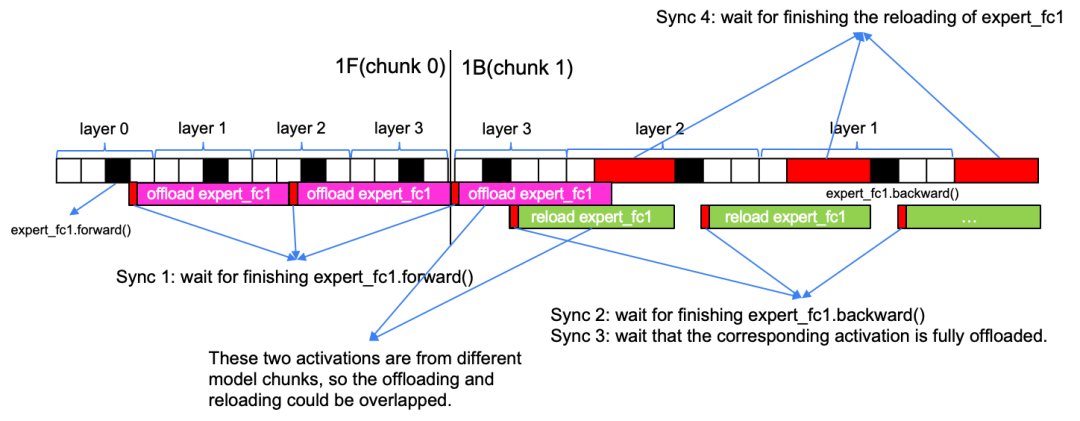 需要说明的是,上图中相邻的前向块与反向块属于两个不同的模型块(model chunk),因此layer2的卸载操作可以与反向时layer2的重载操作重叠。若属于同一模型块,则依据第3条规则,这两个操作必须是串行的。
需要说明的是,上图中相邻的前向块与反向块属于两个不同的模型块(model chunk),因此layer2的卸载操作可以与反向时layer2的重载操作重叠。若属于同一模型块,则依据第3条规则,这两个操作必须是串行的。

3. 兼容性设计
3.1 兼容流水线并行
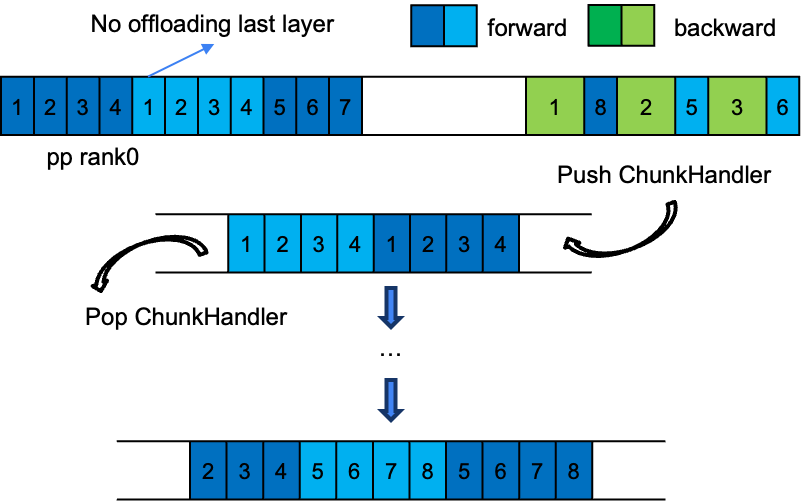
细粒度激活卸载在PP/VPP场景下的核心挑战是“块间数据依赖与顺序管理”,解决方案如下:
- 模型块内原生兼容:单个PP/VPP块内的模块,其激活卸载逻辑与PP=1场景完全一致,无需特殊修改。
- 队列管理器:通过单例
PipelineOffloadManager 维护一个 ChunkOffloadHandler 双端队列。每个PP/VPP块的每个微批次都对应一个独立的 ChunkOffloadHandler,负责管理本块内所有的卸载/重载逻辑。
- 队列维护逻辑:
ChunkOffloadHandler 以“VPP stage逆序、micro batch正序”的顺序入队,其出队顺序即为反向传播时VPP块的执行顺序。
- 重叠优化:不同VPP块间的激活卸载与重载操作可以并行执行,以减少传输延迟。
- 特殊规则:同2.2节,对于前向与反向相邻的块,其内部最后一层激活不进行卸载。
3.2 兼容细粒度重计算
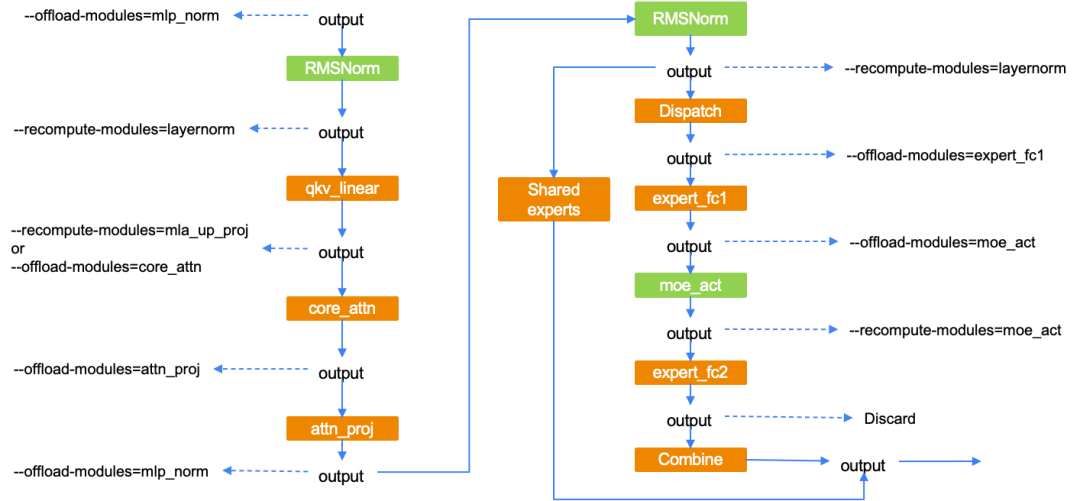
细粒度激活卸载与细粒度重计算可以形成互补,协同增效。
- 差异化策略:
- 轻量算子/模块(如
layernorm, moe_act):其重计算开销低,而激活显存开销与重量级算子相当。对它们使用卸载带来的开销相对更大,因此采用重计算性价比更高。
- 高计算量算子/模块(如
core_attn, expert_fc1):其重计算开销巨大。采用卸载技术,并通过与计算重叠,可以在节省内存的同时,实现吞吐性能的无损或微损。
- 内存完全释放:对同一模块,结合“重计算释放中间变量和输出”与“卸载释放输入和中间变量”,可以实现对该模块动态显存占用的全覆盖,达到模块级别的内存完全释放(memory-free)。
在现有实现中,重计算和卸载可以覆盖一个Transformer层的所有激活。用户可按需选择配置,在极限情况下可以释放整个Transformer层的所有激活。
3.3 与完全重计算的对比
完全重计算通常存储每个Transformer层的输入,释放层内的中间变量。因此,最终的显存峰值包括一层layer的临时中间变量以及前面所有层的输入。
而细粒度激活卸载+重计算的组合方案可以释放掉一个完整Transformer层的所有激活显存,其最终显存峰值仅为一层layer的临时中间变量。因此,在极限情况下,该方案比完全重计算具有更高的显存优化潜力。
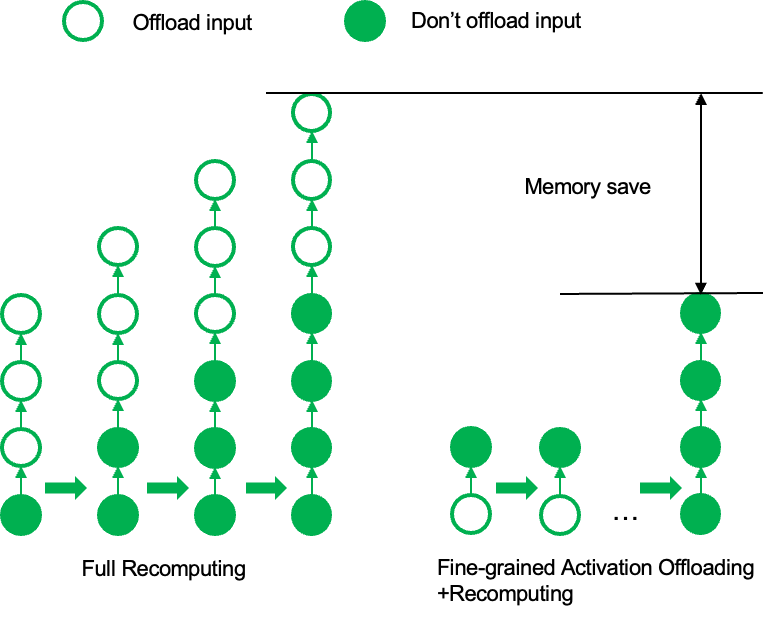

4.1 实验配置与核心指标
实验基于Megatron-LM框架,选取DeepSeek-V3、Qwen3-235B和Dots2.llm等典型大模型,围绕吞吐量和峰值内存开销两大核心指标进行评估:
- 在已启用部分重计算的基线基础上,对比开关卸载功能对指标的影响,目标是以极少的吞吐损失换取较大的内存收益。
- 在全层重计算的基础上,将部分子模块替换为卸载,其余采用部分重计算,对比组合策略与全层重计算在指标上的差异,目标是在保证极致内存收益基本不变的同时,获取显著的吞吐收益。
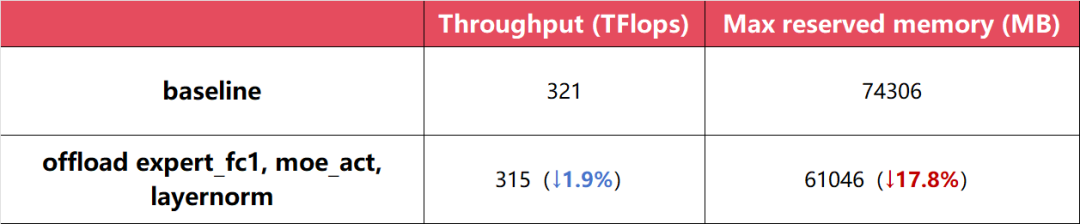
4.2 实验1: DeepSeek-V3-proxy (64卡)
- 配置:14层MoE,专家数64,采用TP1PP4EP6VPP1策略,MBS1GBS512,BF16精度。
- 策略:基线不使用卸载;对比实验对
expert_fc1、moe_act和layernorm启用卸载。
- 结论:以极少的吞吐量损失换取较大内存收益。
4.3 实验2: DeepSeek-V3 (256卡)
- 配置:完整DeepSeek-V3模型,采用TP1PP8EP32VPP4策略,MBS1GBS2048,MXFP8精度。
- 策略:基线不使用卸载;对比实验对
moe_act启用卸载。
- 结论:以极少的吞吐量损失换取较大内存收益。

4.4 实验3: Qwen3-235B长序列训练 (256卡)
- 配置:Qwen3-235B模型,64K序列长度,BF16精度。
- 策略:
- 基线:TP4PP8EP8VPP4CP4,重计算
layernorm和moe。
- 卸载实验:在基线基础上,将CP4改为CP1,并对
qkv、layernorm、core_attn、attn_proj启用卸载。
- 结论:在保证极致内存收益基本不变的同时,获取了吞吐收益。

4.5 实验4: Dots2.llm (512卡)
- 配置:完整Dots2.llm模型(小红书自研MoE文本模型),MBS1GBS4096。
- 策略:采用卸载+重计算组合策略:
- 卸载:
moe_act
- 重计算:除
moe_act外的所有子模块,包括attention module, router, moe_fc2等。
- 结论:在保证极致内存收益基本不变的同时,获取了吞吐收益。

4.6 开销分析与优化
实验中发现两类潜在开销,可通过优化降至最低:
- PCIe带宽竞争:H2D/D2H传输可能与跨节点的A2A通信竞争PCIe带宽。首先,可利用Megatron-Core的A2A Overlapping特性,将A2A通信隐藏在计算kernel中,降低其变慢对整体的影响;其次,在具备较大NVLink域的集群中,可将A2A通信控制在NVLink域内,避免受H2D/D2H影响。
- CPU开销:张量打包/解包、钩子回调会带来额外CPU负担。可通过开启CUDA Graph来降低CPU开销对整体性能的影响。此外,卸载节省的显存可用于增加GPU计算密度,从而进一步降低训练中CPU开销的占比。

5.1 步骤1:诊断内存瓶颈
5.2 步骤2:计算最大可卸载张量大小
需确保卸载/重载的传输时间能被计算完全掩盖。关键公式:最大可卸载字节数 = 单模块计算时间 × H2D/D2H带宽
- 带宽测试:使用NVIDIA nvbandwidth工具测试硬件实际带宽。
- 计算时间:通过NSys报告获取单个Transformer层或目标模块的计算耗时。例如,若单层计算耗时为2ms,硬件D2H带宽为40GB/s,则最大可卸载字节数为
2ms × 40GBps = 80MB。
- 前反向不均衡:通常只需考虑前向阶段,因为反向计算时间约为前向的2倍,且H2D带宽通常略快于D2H,因此反向传播时的重载比前向的卸载更容易被隐藏。瓶颈主要集中在前向阶段。
5.3 步骤3:配置卸载并验证
- 参数配置:通过
--offload-modules 参数指定要卸载的模块,例如 --offload-modules=core_attn,expert_fc1。
- 验证指标:
- NSys时序图:检查D2H/H2D传输是否与计算kernel完全重叠。
- Memory Snapshot:确认目标模块的激活已按预期释放。开发者可仔细查看memory snapshot中的每次显存分配与释放记录,验证节省的显存量是否达到预期。
5.4 步骤4:迭代优化
- 调整卸载模块:若内存仍不足,可增加卸载模块(如
attn_proj);若性能损失过大,可将部分卸载模块切换为重计算(如保留layernorm重计算)。
- 并行度适配:结合上一步的显存节省量,利用显存估计器等工具,重新调整TP/CP/PP等并行度配置(例如降低TP以提升计算强度)。
- 重复上述步骤,直至在内存与性能间找到满意平衡点。
6. 未来工作展望
当前方案仍有优化空间,未来将重点推进以下方向:
- 支持CUDA Graph捕获卸载操作:解决当前CUDA Graph无法捕获卸载/重载操作的限制,进一步降低CPU开销。
- 优化FP8张量卸载:减少FP8张量在CPU-GPU间传输时的类型转换与打包开销。
- 兼容Megatron-FSDP:实现细粒度卸载与完全共享数据并行(FSDP)的协同,适配更大规模模型训练。
- 支持分层差异化卸载策略:当前为全局统一策略,未来将允许不同层采用不同的卸载配置,以适应流水线并行在warm-up阶段与steady阶段可掩盖的数据搬运量差异。
- 支持跨PP Rank的显存均衡:使卸载策略能感知不同流水线阶段(PP rank)的显存消耗差异,控制消耗较大的rank减少非必要卸载操作,最大化整体显存利用率并降低性能影响。
Megatron Core中的细粒度激活卸载方案,通过“模块级粒度、计算-传输重叠、全并行兼容”的核心设计,在长上下文、大模型训练中成功实现了“峰值内存收益”与“吞吐性能收益”的联合最优。实验表明,该方案可使DeepSeek-V3、Dots2.llm等先进模型以仅1%-2%的吞吐损失,换取10%-35%的峰值内存降低;或在保证极致内存节省的同时,获得7%-10%的吞吐提升。这为千亿参数模型、超长序列训练提供了高效、实用的内存解决方案。
结合本文提供的最佳实践指南,开发者可以快速将这一方案落地到实际的训练任务中,进一步突破大模型训练的内存瓶颈,推动更大规模、更长上下文模型的研发进程。
本工作由Rednote HiLab与英伟达技术专家共同完成。感谢项目相关同事Zhuran、Wenliang、Guangsu、Hongxiao、Zijie、Xin、Yan及David等提供的支持与帮助。本工作的开展受到快手与英伟达合作的GTC Talk启发,特此向该分享团队致谢。
Yimeng, Rednote HiLab
小红书大模型训练框架开发工程师,目前从事小红书大模型训练框架的开发与优化工作。
Hongbin, NVIDIA Devtech
NVIDIA加速计算专家,专注于大语言模型训练的功能开发及性能调优,深度参与Megatron-Core的相关开发,目前主要负责MoE模型的通信及显存优化工作。
 发表于 2025-12-12 22:45:35
|
查看: 262|
回复: 0
发表于 2025-12-12 22:45:35
|
查看: 262|
回复: 0
