项目卡片
- 项目:awesome-codex-skills
- 状态:2862 Star / 206 Fork / 创建于 2026-01-12 / 最近更新 2026-04-27
- 一句话判断:目前 Codex 生态中覆盖面最广的 skill 合集,本质上是一份“可执行的工作流配方清单”。
Codex Skills 是什么
OpenAI Codex CLI 在 2026 年初开放了 skill 机制。每个 skill 就是一个文件夹,其核心是一个 SKILL.md 文件。这个文件包含了 YAML frontmatter(name + description)和 Markdown 格式的执行指令。你可以把它理解为一份“可执行的工作流配方”——它直接告诉 AI agent,在遇到特定任务时应该遵循何种流程来操作。
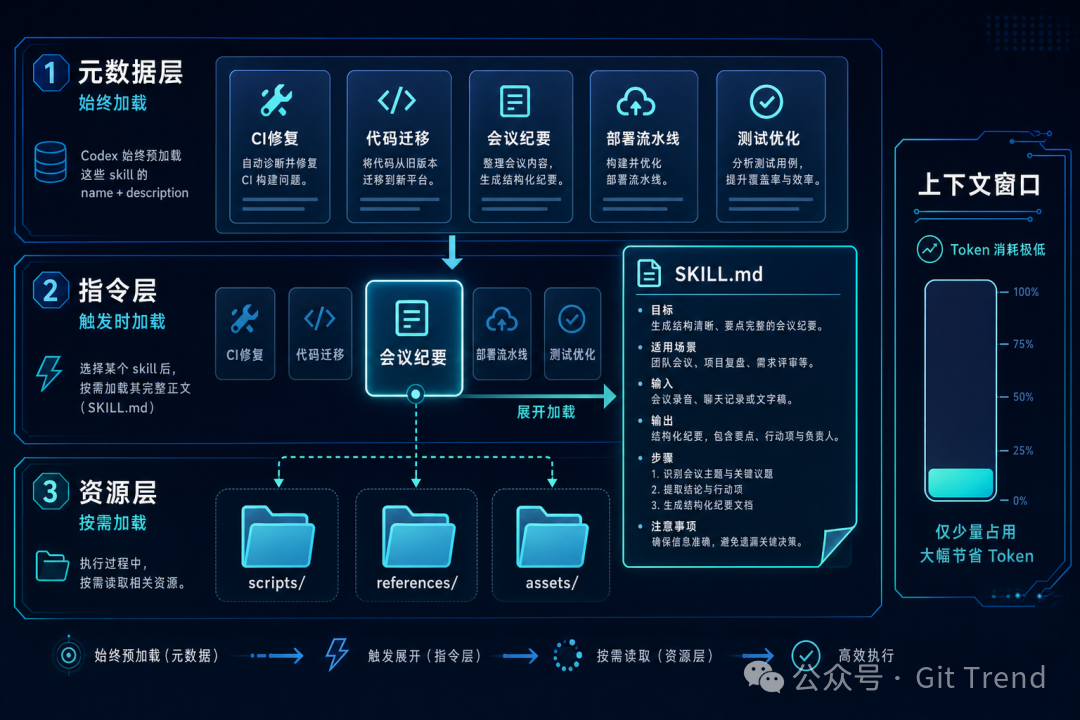
它的工作机制被巧妙地分成了三级,这是一种非常务实的 技术文档 中才常见的精妙设计:
- Metadata 常驻:Codex 会始终加载所有 skill 的 name 和 description(总共也就约 100 词),用来快速判断是否触发某个 skill。这部分对资源的消耗微乎其微。
- Body 按需加载:只有当某个 skill 被触发后,系统才会去读取
SKILL.md 里的完整正文指令。官方建议这部分内容别超过 500 行,以保持响应速度。
- Resources 延迟加载:像
scripts/、references/、assets/ 这类附加资源,只在 skill 执行过程中,真正用到的时候才去读取。
这个渐进式加载的设计思路非常清晰,也解决了我的一个核心疑虑:即使装了 50 个 skill,也不会撑爆上下文窗口。只有真正被触发的那个才会占用宝贵的 token。实话说,我一开始本能地认为它会像 .cursorrules 那样,规则越多跑得越慢,但在看完这套三级机制后,才意识到这种设计有多合理。
这个 awesome-list 收录了什么
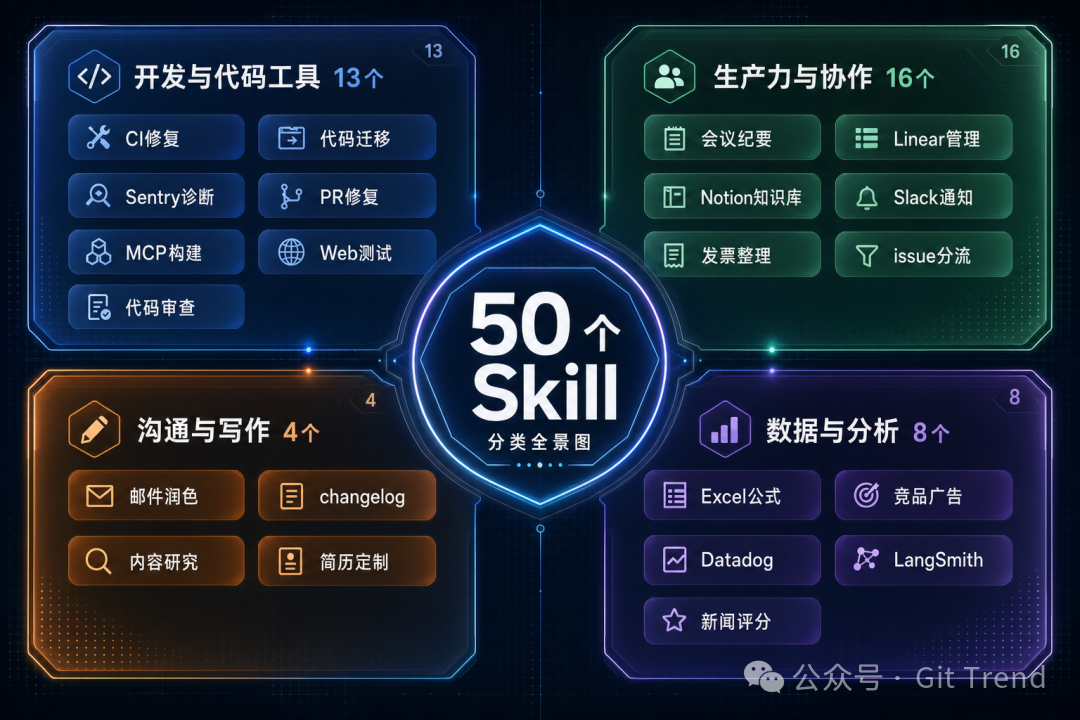
ComposioHQ 维护的这个仓库收录了大约 50 个 skill,并清晰地划分为了四大类别:
开发与代码工具(13 个):涵盖代码审查、CI 修复、Sentry 错误诊断、大规模代码迁移、PR 自动修复、MCP Server 构建、Web 应用测试等。在这之中,codebase-migrate 是信息密度最高的一个——它用 done.list 文件来跟踪已完成的部分,每 25 个文件拆分成一个 PR,并且每批都独立可验证、可回滚。这让“修改 200 个文件”这种高风险操作,变成了一个可审查、可验证的自动化流水线。
生产力与协作(16 个):包括 Linear/Jira issue 管理、会议纪要生成、向 Notion 知识库写入内容、发票整理、Slack 通知等。这个分区是 skill 数量最多的,也最能体现从“生成文本”到“执行具体动作”的能力跨越——通过 Composio CLI,Codex 能够直接在 GitHub 创建 issue、在 Notion 写入页面、在 Slack 发送消息。
沟通与写作(4 个):专注于邮件润色、changelog 生成、内容研究写作和简历定制。
数据与分析(8 个):提供了 Excel 公式辅助、竞品广告分析、Datadog 日志分析、LangSmith 数据拉取、新闻偏倚评分等实用技能。
和 Cursor Rules / Claude Skills 的本质差异
把 Codex Skills 与 Cursor Rules、Claude Code Skills 放在一起比较,各自的差异点就非常明确了:
Cursor Rules 本质上是一段纯文本指令,会被系统注入到每次对话的 system prompt 里。它没有触发机制,也没有渐进加载,只是一个全局生效的 .cursorrules 文件。规则配置得多了,就会稀释每一次对话中的有效信息密度。
Claude Code Skills 则是通过 settings.json 中的 hook 配置来触发,具备了条件执行能力。但它骨子里仍然是“提示词增强”的思路——教 AI 怎么做事,其执行手段也主要依赖于文件读写和命令行。
相比之下,Codex Skills 的设计哲学有所不同:它预设 AI agent 本身已经具备了足够的基础能力,不需要你去教“怎么做”,而是只需要教它“做什么”以及“按什么流程做”。比如 codebase-migrate 这个 skill,它不会教 Codex 如何写正则表达式,它教的是“先做范围评估、再分批处理、再验证、最后合并”这套工作流顺序。gh-fix-ci 也不教你怎么读日志,它教的是“先用脚本拉取失败的检查项,再进行问题总结,最后调用 plan skill 生成修复方案”的流程。
这里的一个核心差异点在于 bundled resources——一个 skill 可以把 Python/Bash 脚本、参考文档和模板资源打包在一起。这意味着那些确定性强的操作可以直接交给脚本去执行,而 AI 只需负责高层次的判断和流程编排。gh-fix-ci 里的 inspect_pr_checks.py 就是个典型用例:它负责拉取 CI 日志并整理成结构化输出,Codex 拿到的就不再是杂乱的原始日志,而是处理过后的清晰摘要。
安装和使用
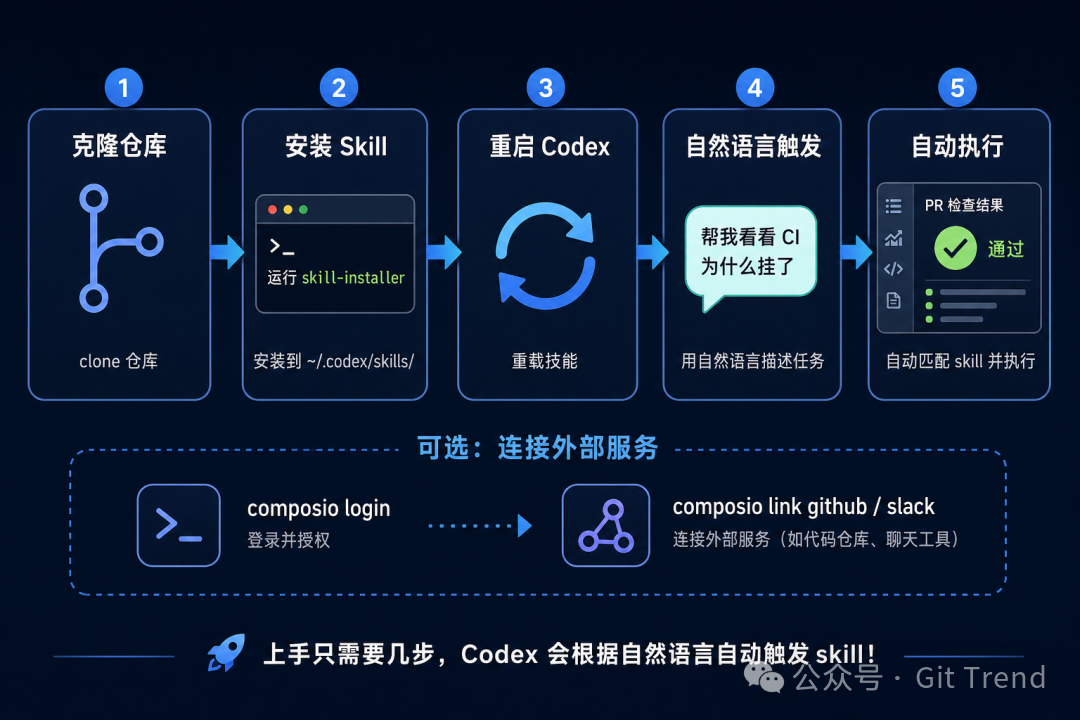
安装方式有两种。最推荐的是使用内置的 skill-installer:
git clone https://github.com/ComposioHQ/awesome-codex-skills.git
cd awesome-codex-skills
python skill-installer/scripts/install-skill-from-github.py \
--repo ComposioHQ/awesome-codex-skills \
--path meeting-notes-and-actions
当然,你也可以选择手动将具体的 skill 文件夹复制到 ~/.codex/skills/ 目录下,然后重启 Codex 使其生效。
安装完成后,你并不需要显式地去调用它。Codex 会根据你用自然语言描述的任务,自动匹配 skill 的 description 字段。比如,你随口说一句“帮我看看这个 PR 的 CI 为什么挂了”,Codex 就会自动触发 gh-fix-ci 这个 skill。
如果你需要让 skill 与 GitHub、Slack、Notion 这类外部服务进行交互,那么就需要额外安装 Composio CLI 并完成 OAuth 授权:
curl -fsSL https://composio.dev/install | bash
composio login
composio link github
composio link slack
创建自己的 Skill
这个仓库不只是提供现成的 skill,它还配套了完整的脚手架工具来辅助你进行二次创作。其中,skill-creator 本身就是一个“元 skill”,它会一步步教你如何从零开始创建一个新的 skill,并且要求你遵循以下几个核心设计原则:
简洁至上:请时刻记住,上下文窗口是公共资源。在写下每一行指令之前,都应该反问自己一句:“如果 Codex 不读这段话,就真的干不好这件事吗?”
自由度分级:为不同风险等级的操作提供不同粒度的指令。
- 高自由度(纯文本指令):当解决问题的路径有多种且都可行时,只给出方向性指导,不限定具体细节。
- 中自由度(伪代码):有推荐的最佳实践模式,但允许执行时根据具体情况发生变体。
- 低自由度(确定性脚本):当操作本身很脆弱、容错率很低时,就直接给出一个可执行的脚本,将模糊性降到零。
渐进披露:SKILL.md 文件里应该只保留核心流程。详细的参考文档应当放入 references/ 目录,模板文件放入 assets/ 目录。所有内容都遵循“按需加载,绝不预加载”的原则。
一个完整的创建流程是:先深入理解应用场景 → 然后规划所需资源 → 运行 init_skill.py 脚手架脚本 → 编辑具体的 skill 实现 → 运行 package_skill.py 打包 → 最后在实际使用中反复迭代优化。
商业层面:Composio 的策略
这个仓库由 ComposioHQ 维护,而 Composio 的核心产品是一个能够让 AI agent 调用超过 1000 种外部服务的 CLI/SDK。不难发现,仓库中至少有 6 个 skill 直接依赖 Composio CLI 作为执行层(如 connect、connect-apps、codebase-migrate、deploy-pipeline、pr-review-ci-fix、datadog-logs)。其背后的策略意图相当清晰:先让自己成为 Codex skill 生态中的标准基础设施,然后再想办法将用户转化为付费客户。
不过,值得庆幸的是,大部分 skill 并不强依赖 Composio 也能独立工作,这种商业植入并没有削弱 skill 本身在 开源实战 中的实用性。如果是我自己来用,我会优先挑选那些不依赖外部 CLI 就能独立运行的 skill 来上手。
值得关注的几个 Skill
以下几个 skill 的设计思想,尤其值得仔细琢磨:
codebase-migrate——堪称大规模代码迁移的教科书级范例。它把“修改 200 个文件”这种庞杂任务,拆解成每 25 个文件组成一批的 PR,确保每批都能独立验证与回滚,并通过一个 done.list 文件来防止重复工作。在架构上,它依赖 Composio CLI 的 execute 命令来对接 GitHub API 创建 PR,本地则使用 rg 加上 codemod 工具来执行具体的代码变换。
deploy-pipeline——提供了一个端到端的发布流水线方案。从 Stripe 修改价格,到 Supabase 执行数据库迁移,再到 Vercel 部署、冒烟测试、最后在 Slack 发出通知,整个过程都编排在一条 composio run --file scripts/ship.ts 命令中。它的回滚策略也考虑得很周全:按反向顺序操作,并且明确指出 Stripe 的价格只能“deactivate”而不能直接“delete”。
gh-fix-ci——构建了一个 CI 修复的完整闭环。它先用 inspect_pr_checks.py 拉取失败日志并生成摘要,接着让 plan skill 介入生成修复方案,待用户确认后执行。这彻底把“看看 CI 为什么挂了”这种模糊需求,变成了一个可重复、标准化的处理流程。
mcp-builder——这是一份 MCP Server 构建指南,设计思路同样很超前。它指导你先研究 API 文档,再规划工具集,在实现阶段还特别强调要区分“面向 agent 的设计”和“面向人类 API 的设计”,最后用一套包含 10 个评估问题的清单来验证实际可用性。
一句话判断
如果你正在使用 OpenAI Codex CLI,那这个仓库绝对是你当前最值得花时间浏览的 skill 合集——其价值不仅在于收录了 50 个 skill,更在于它清晰地展示了“AI agent 工作流”应该怎样被设计:分级加载、脚本执行、渐进披露。就算你最终不打算安装其中任何一个 skill,skill-creator 和 mcp-builder 里蕴含的设计理念,也值得每一个正在构建 AI agent 系统的人从头到尾读一遍。
引用链接
[1] awesome-codex-skills: https://github.com/ComposioHQ/awesome-codex-skills
 发表于 2026-5-3 19:42:20
|
查看: 634|
回复: 0
发表于 2026-5-3 19:42:20
|
查看: 634|
回复: 0
