在 Apache Doris 集群的日常运维中,内存管理问题往往是影响稳定性的核心挑战。查询突然OOM、BE节点内存占用持续高位、频繁GC导致查询卡顿等现象,不仅威胁业务连续性,其复杂的成因也常令运维人员感到棘手。
作为一款高性能的 MPP架构 OLAP引擎,Doris的卓越性能很大程度上依赖于高效、精准的内存管理机制。无论是数据的流式计算、中间结果的缓存,还是算子的并行执行,都需要对内存资源进行周密的规划与控制。本文将从 “内存结构 → 跟踪监控 → 控制策略 → 实战排查” 四个维度,系统性地剖析Doris的内存管理体系,旨在帮助读者理解其底层逻辑,并掌握解决实际问题的能力。
一、Doris BE的内存全景图
解决问题始于洞察。要根治内存问题,首要任务是弄清楚Doris BE进程的内存究竟消耗在何处。整体上,Doris BE的内存被划分为 “被跟踪内存” 和 “未被跟踪内存” 两大类,每一类下又包含多个细分的模块。
1. 整体内存结构拆解
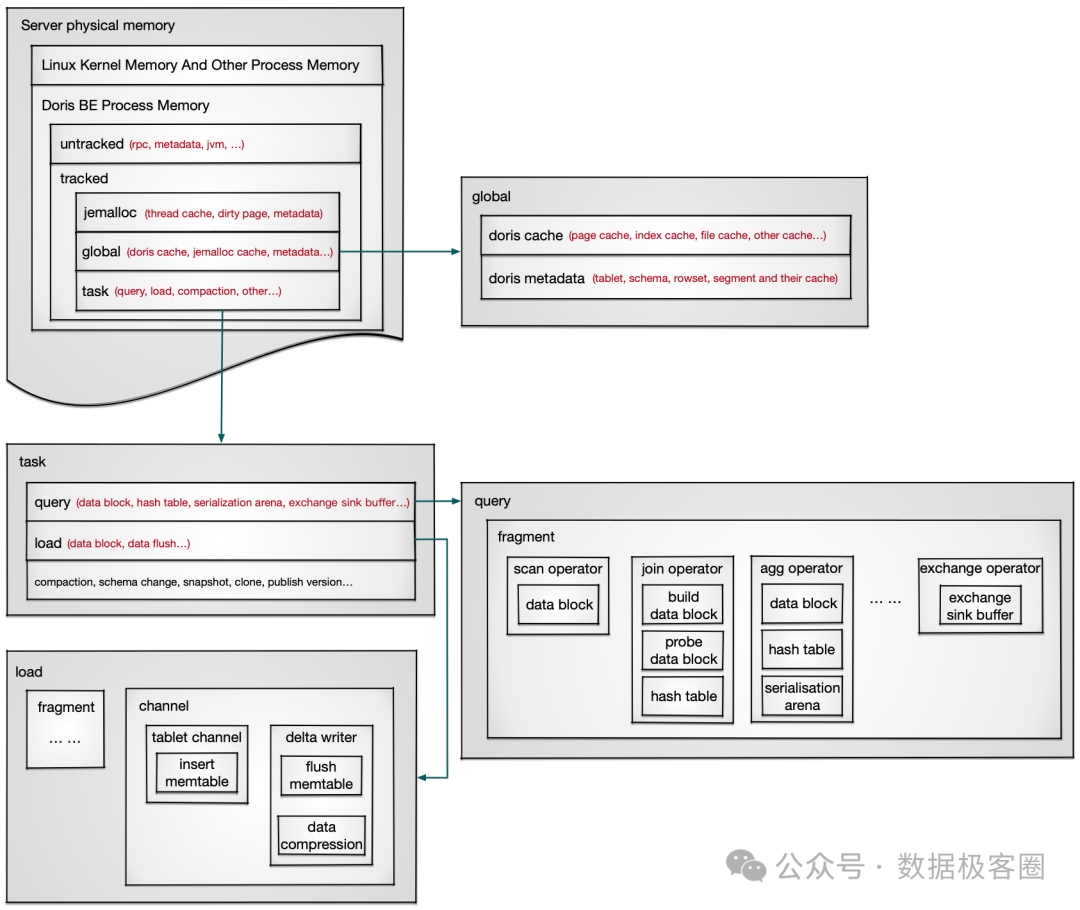
服务器物理内存
├─ Linux内核 + 其他进程内存
└─ Doris BE进程内存
├─ 未被跟踪内存(Untracked):无需手动管控,占比通常较小
│ ├─ RPC通信内存
│ ├─ JVM内存(用于访问外部表、执行Java UDF等场景)
│ └─ 部分元数据(统计可能不完全)
└─ 被跟踪内存(Tracked):核心管控对象,支持监控与回收
├─ Jemalloc管理内存:内存分配的“中央枢纽”
│ ├─ Jemalloc缓存(线程缓存、脏页等)
│ └─ Jemalloc元数据
├─ 全局共享内存(生命周期与进程一致)
│ ├─ Doris内部缓存(数据页缓存、索引缓存、文件缓存等)
│ └─ 全局元数据(表结构、Tablet元数据、RowSet元数据等)
└─ 任务级内存(随任务结束而释放)
├─ 查询内存(数据块、Hash表、序列化缓冲区等)
├─ 导入内存(数据块、MemTable、刷盘缓冲区等)
├─ Compaction内存(多版本合并时产生的中间数据)
└─ 其他任务内存(Schema Change、副本克隆等)
2. 关键内存模块详解
- Jemalloc:自 Doris 1.2.2 版本起,Jemalloc 取代 TCMalloc 成为默认的内存分配器。它在高并发场景下表现更优,负责管理线程本地缓存和内存块的分配与回收,有效减少向操作系统申请内存的系统调用开销。
- 全局缓存:可通过参数调节大小,当内存紧张时会触发自动回收机制,例如过期的 Segment Cache 和数据页缓存。
- 查询内存:这是内存占用波动最剧烈的部分。Join、聚合、排序等算子会消耗大量内存,例如 Hash Join 算子构建的哈希表、Sort 算子使用的排序缓冲区。
- 导入内存:数据写入时首先被暂存于 MemTable(内存中的临时数据结构),达到设定阈值后触发刷盘操作,此部分内存可通过参数进行限制。
二、内存跟踪器(Memory Tracker):内存的“火眼金睛”
Doris 通过 Memory Tracker 机制实现了对内存使用的精准追踪。无论是进程整体的内存消耗,还是单个查询、导入任务的具体内存占用,都能被实时监控和记录,是排查内存异常的核心工具。
1. 全链路跟踪的实现原理
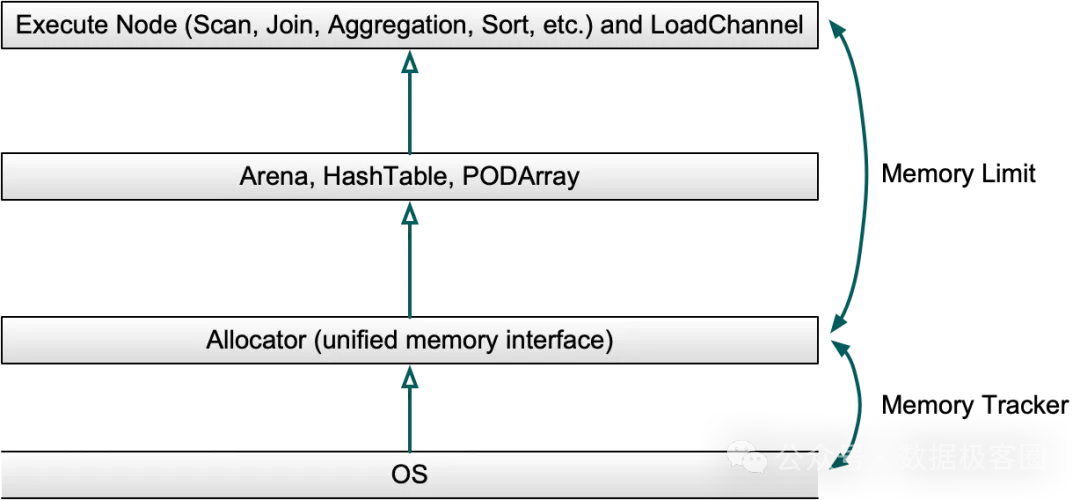
- 统一分配入口:Doris 的核心数据结构(如 Arena、HashTable)均继承自统一的
Allocator 基类。所有内存的申请与释放都经由 Allocator 处理,并自动记录到关联的 Memory Tracker。
- 线程本地绑定:每个查询、导入等任务在初始化时,都会创建专属的 Memory Tracker,并将其绑定到线程本地存储中。任务执行过程中产生的所有内存分配,都会自动关联到该 Tracker。
- 算子级细粒度跟踪:对于 Join、Aggregation、Sort 等关键算子,Doris 会创建独立的子 Memory Tracker,从而精确定位到具体是哪个算子占用了过高内存。
2. 两种核心的 Tracker 类型
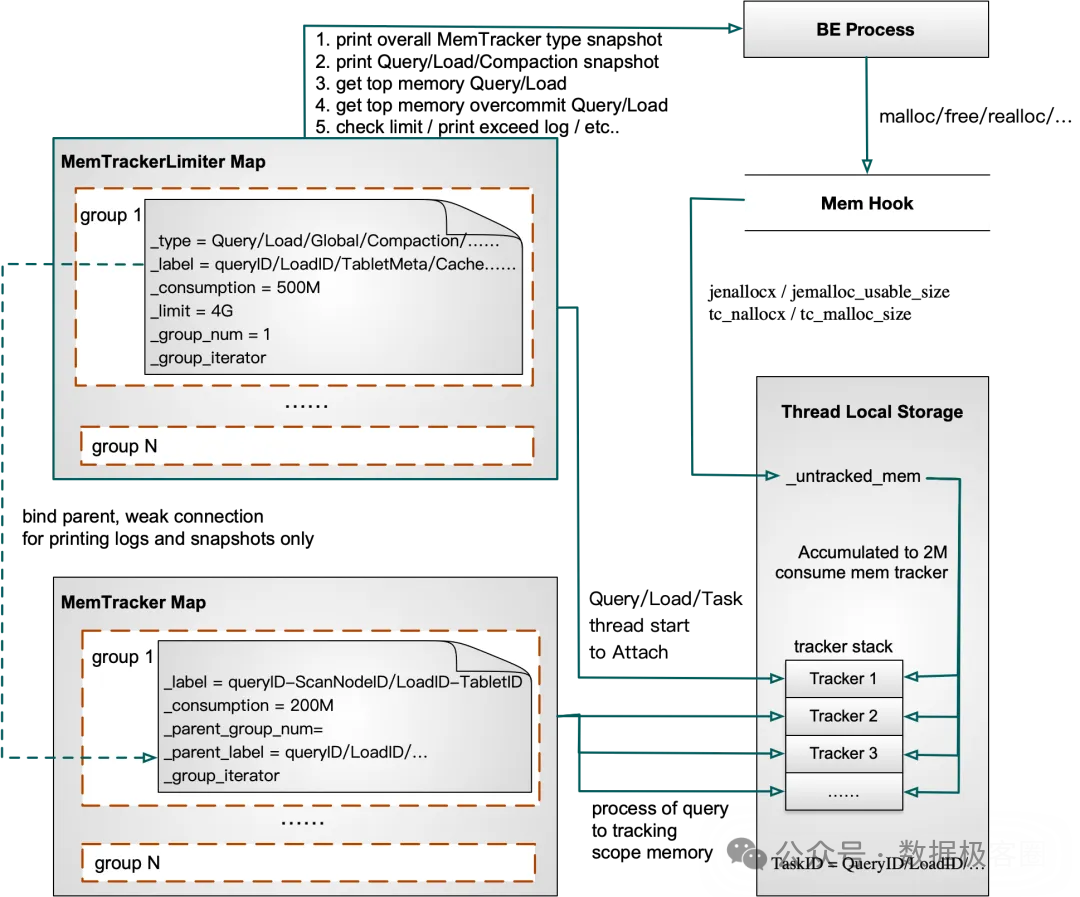
| Tracker 类型 |
核心作用 |
典型应用场景 |
| Memory Tracker Limiter |
内存限制 + 监控 |
用于单个查询、导入任务、全局缓存等,支持设置明确的内存使用上限。 |
| Memory Tracker |
跟踪内存热点 |
用于算子级别的内存使用统计(如 Hash Join 的哈希表),或导入数据下刷时的内存控制。 |
二者采用“软关联”设计:父子关系主要用于日志打印和快照展示时的层级呈现,生命周期彼此独立,避免了复杂的依赖链问题。
3. 如何查看内存跟踪数据?
(1)实时内存统计(Web 页面,最常用)
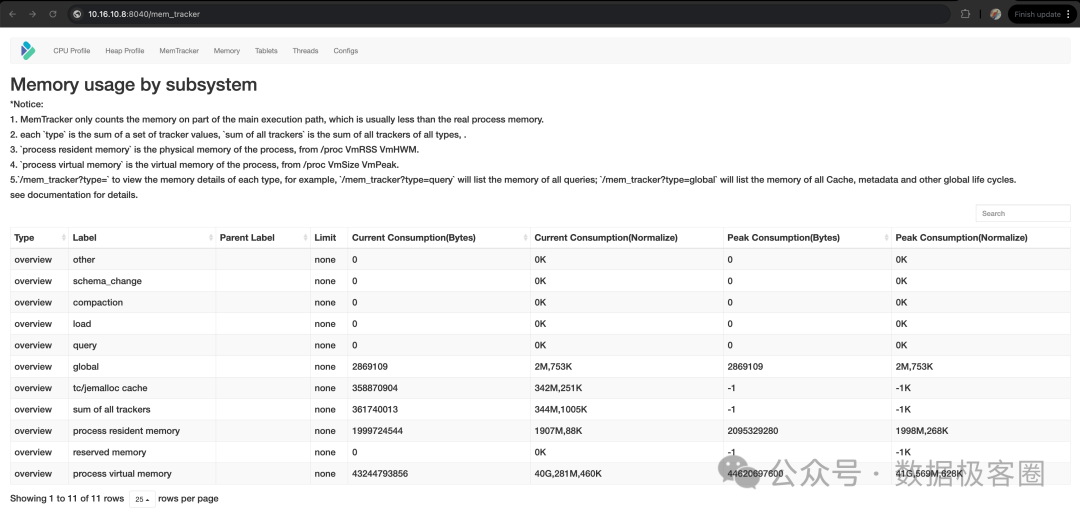
- 访问地址:
http://{BE_HOST}:{BE_WEB_PORT}/mem_tracker (默认 WEB 端口为 8040)
- 核心指标解读:
process resident memory:BE 进程实际占用的物理内存(数据来源于 /proc 文件系统,最为准确)。sum of all trackers:所有 Memory Tracker 统计的内存总和(通常小于物理内存,因存在未跟踪内存)。query/load/compaction:分别对应查询、导入、Compaction 任务类型的总内存占用。global:全局共享内存(包括缓存和元数据)。
- 查看详情:在 URL 后添加
?type=xxx 参数,例如 ?type=query 查看所有查询的内存消耗详情,?type=global 查看全局缓存详情。
(2)历史内存趋势(Bvar 页面)
- 访问地址:
http://{BE_HOST}:{BRPC_PORT}/vars/*memory_* (默认 BRPC 端口为 8060)
- 主要用途:观察某类内存指标随时间的变化趋势,常用于定位内存泄漏或内存突增问题。
(3)日志中的内存快照
- 当进程内存超限或可用内存不足触发告警时,BE 日志文件(
be.INFO)中会打印完整的 Memory Tracker Summary。这份快照包含了所有核心 Tracker 的当前内存占用,是事后排查的重要依据。
4. 常见问题:Tracker 统计缺失怎么办?
- 现象:
process resident memory 与 sum of all trackers 的差值过大(如超过30%),或 Orphan Tracker 的数值异常偏高。
- 原因:部分内存未通过统一的
Allocator 接口分配(例如直接的 RPC 缓冲区、部分元数据结构),或可能存在内存泄漏。
- 排查步骤:
- 对于 Doris 2.1.5 之前的版本,优先检查 Segment Cache(其统计可能不准),可尝试关闭该功能进行测试。
- 查看
doris_column_reader_num 指标,若数值巨大,则可能是 Segment Cache 的内存占用。若同时在后续的 Heap Profile 中看到大量与 Segment、ColumnReader 相关的调用栈,则可基本确认。
- 使用 Jemalloc Heap Profile 生成内存分配快照,深入分析未被跟踪的内存去向:
a. 修改
be.conf 中 JEMALLOC_CONF 的 prof_active:false 为 prof_active:true,重启 BE。
b. 执行 curl http://be_host:8040/jeheap/dump,在 ${DORIS_HOME}/log 目录下会生成 profile 文件。
c. 执行 jeprof --dot ${DORIS_HOME}/lib/doris_be ${DORIS_HOME}/log/profile_file,将输出文本粘贴至在线 dot 绘图工具,生成可视化内存分配图。
三、内存控制策略:在性能与稳定间寻求平衡
Doris 通过 “统一分配 + 智能仲裁 + 自动回收” 三层机制,确保内存使用处于可控状态,核心目标是平衡查询性能与系统稳定性。
1. 内存分配:三大核心数据结构
Allocator 作为统一接口,其底层依赖于三个关键数据结构来优化内存分配效率:
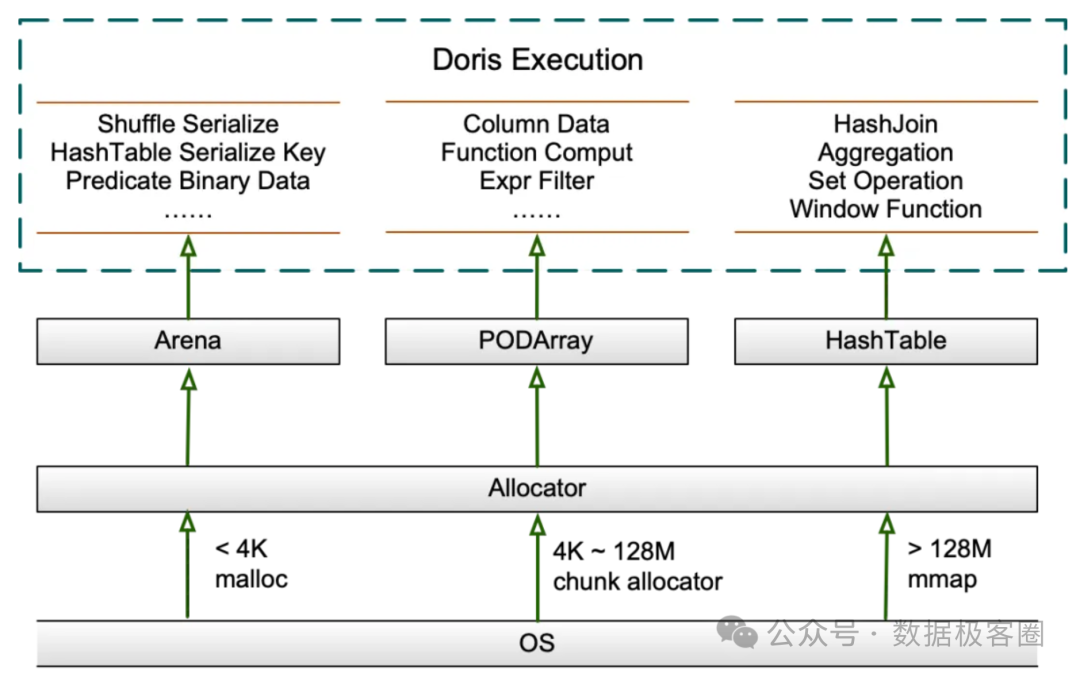
- Arena(内存池):维护多个 Chunk(内存块),通过批量申请来减少系统调用次数。广泛用于序列化数据、Hash 表 Key 存储等场景。Chunk 大小动态增长,最大为 128MB。
- HashTable:用于实现 Join、聚合、窗口函数等操作。支持并行扩容,在大内存场景(> 2GB)下,扩容因子从 50% 提升至 75%,以减少内存碎片和浪费。
- PODArray(动态数组):用于存储字符串等列式数据。其特点是不初始化元素,析构时直接释放整块内存,分配与释放效率更高。
2. 内存复用:提升效率的关键技巧
Doris 在执行层设计了多种内存复用机制,旨在避免频繁的内存申请与释放:
- 数据块(Block)复用:查询执行时预分配一批空闲 Block,扫描数据时循环使用,任务结束后统一释放。
- Shuffle 双 Block 交替:在 Sender 端使用两个 Block 交替进行数据接收和网络传输,规避了为每个批次创建新 Block 的开销。
- MemTable 预聚合:在向聚合模型表导入数据时,当 MemTable 达到阈值后,会先进行预聚合以收缩内存占用,然后继续接收新数据,从而降低峰值内存使用。
3. 内存不足时的自动垃圾回收(GC)
Doris 设有专门的 GC 线程,定时监控内存状态。当内存使用超限或系统可用内存告急时,会触发不同级别的自动回收。
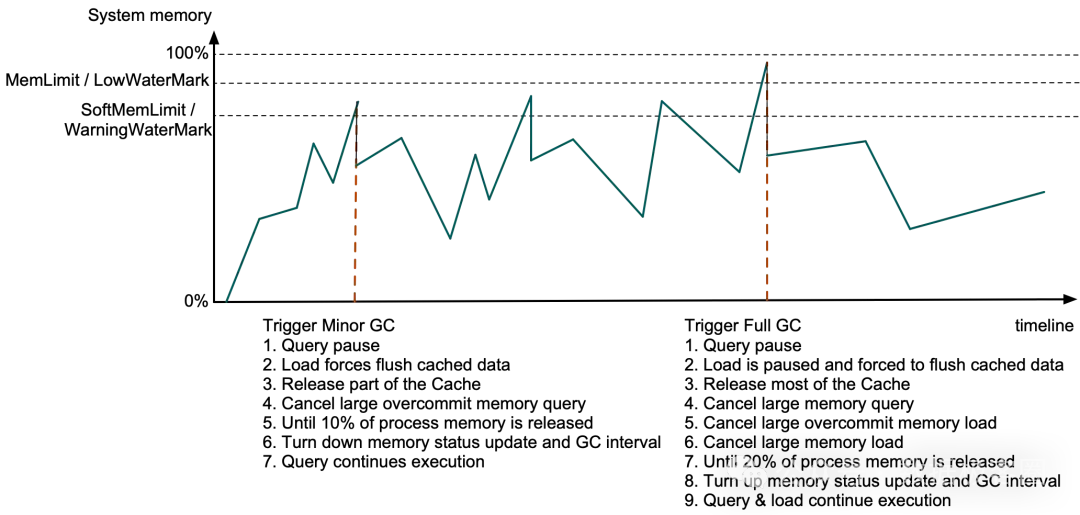
(1)Minor GC(轻度回收)
- 触发条件:BE 进程内存超过
SoftMemLimit(默认= mem_limit * 0.9),或系统可用内存低于 Warning 水位线(在 64GB 机器上约为 6.4GB)。
- 执行动作:
- 暂停所有查询的内存分配。
- 强制进行中的导入任务刷盘(释放 MemTable 内存)。
- 尝试释放部分可回收的缓存(如过期的 Segment Cache、数据页缓存)。
- 若释放的内存不足总内存的 10%,则取消那些内存“超发”比例较大的查询。
- 恢复查询的继续执行。
(2)Full GC(完全回收)
- 触发条件:BE 进程内存超过
MemLimit(硬上限),或系统可用内存低于 Low 水位线(在 64GB 机器上约为 3.2GB)。
- 执行动作:
- 暂停所有查询和导入任务。
- 强制所有导入任务刷盘并暂停接收新数据。
- 释放全部数据页缓存和大部分全局缓存。
- 取消内存占用最大的查询和导入任务,直至释放至少 20% 的内存。
- 恢复剩余任务的执行。
4. 核心内存参数速查表
| 参数名 |
默认值 |
核心作用 |
mem_limit |
90% |
BE 进程可使用的内存上限(相对于系统物理内存的百分比)。 |
soft_mem_limit_frac |
0.9 |
计算 SoftMemLimit 的系数,SoftMemLimit = mem_limit * soft_mem_limit_frac。 |
max_sys_mem_available_low_water_mark_bytes |
-1 |
系统可用内存低水位线绝对值(字节),设为-1则自动计算。 |
write_buffer_size |
100M |
单个 MemTable 的内存上限,也是导入数据刷盘的阈值之一。 |
load_process_max_memory_limit_percent |
50% |
所有导入任务总内存占用不得超过 BE 总内存的此比例。 |
五、总结:Doris内存管理的核心逻辑
Doris 的内存管理本质是一套 “精细化管控” 与 “智能化回收” 相结合的体系。它通过 Memory Tracker 实现全链路监控,利用 Allocator 统一内存分配入口,并依赖自适应的 GC 机制在资源紧张时主动干预,从而在保障查询性能(通过内存复用与缓存)的同时,最大程度规避 OOM 风险。
对于运维人员和开发者而言,掌握以下三个核心要点至关重要:
- 善用工具:熟练使用 MemTracker 页面进行实时监控,利用 Bvar 观察历史趋势,结合日志快照进行事后深度排查。
- 理解参数:明确
mem_limit(进程总闸)、exec_mem_limit(查询内存限制)、write_buffer_size(导入缓冲区)等关键参数的含义与影响。
- 区分场景:认识到查询、导入、Compaction 等不同任务类型的内存使用特征各有不同,需针对性地进行调优与监控。
|  发表于 2025-12-13 01:06:58
|
查看: 262|
回复: 0
发表于 2025-12-13 01:06:58
|
查看: 262|
回复: 0
