你写代码的肌肉记忆,正在写出一份份糟糕的 Skill。
这是 Perplexity Agents 团队 2026-05-01 公开的内部规范《Designing, Refining, and Maintaining Agent Skills》里,第一段就甩出来的判断。他们 review 公司里工程师写的 Skill PR,发现一个反直觉的事实:那些 PEP20 教过你的「Python 之禅」,至少有一半在写 Skill 时是反模式。
「Many useful patterns for writing software become antipatterns in Skill creation.」
这份规范不是面向 Perplexity 内部工程师的吐槽,而是这家公司把 Comet、Computer 等 frontier agent 产品做出来之后,沉淀的一份生产级方法论。中文 AI 圈对 Skill 的讨论还停留在 Anthropic 那篇《Introducing Agent Skills》的概念层,Perplexity 这份直接把工程师踩过的坑摊开了。
下面拆它三个核心反直觉。
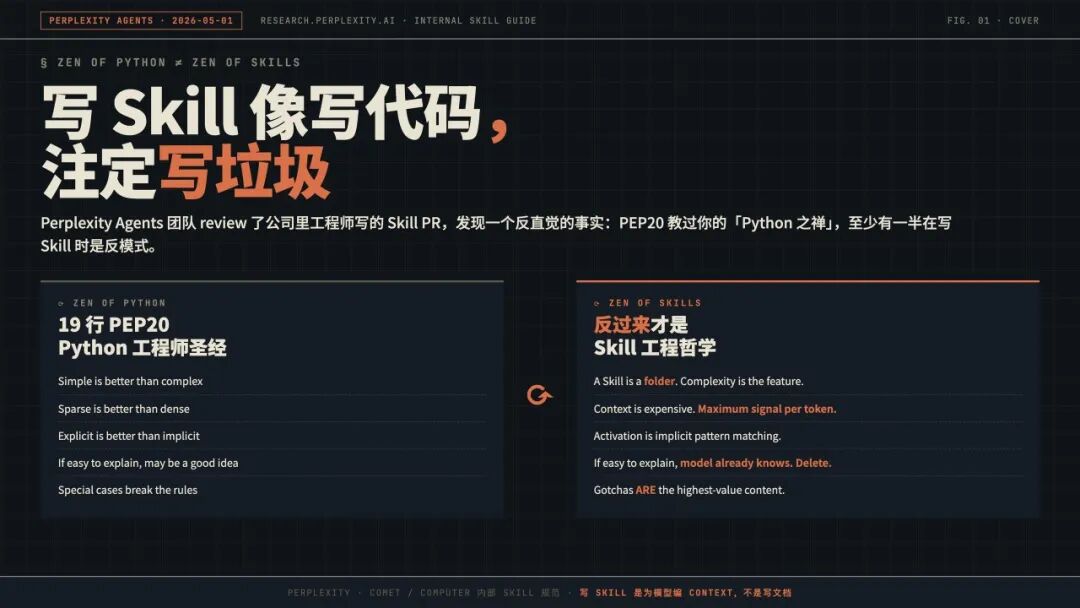
01 写 Skill 不是写代码,PEP20 反过来才是 Zen of Skills
PEP20 是 Python 工程师的圣经,开头那 19 行 import this 决定了一代代 Python 代码的审美。Perplexity 这份规范甩了一张对照表,说「至少 5 条 PEP20 用在 Skill 上是积极地误导」。
挑两条最扎眼的看。
「Simple is better than complex」错。一个 Skill 不是一个文件,它是一个文件夹,里面 SKILL.md 是 hub,scripts/ references/ assets/ 是 spoke。复杂结构本身就是 Skill 的 feature,因为模型需要根据条件按需展开,而不是把所有判断挤进一个 markdown。
「Sparse is better than dense」错。Context 是有定价的,每一个 token 都要榨出最大信号。Skill 的 SKILL.md body 必须密集,每一句都要能扛住一个反问:「模型没看到这句会出错吗?」扛不住就删。
「If the implementation is easy to explain, it may be a good idea」也彻底反过来。原文给出的反 PEP20 版本是这样的:
「If it's easy to explain, the model already knows it. Delete.」
工程师写 README 的肌肉记忆,是把每一步 git checkout main && git checkout -b clean-branch && git cherry-pick <commit> 写清楚。对人类同事这是好文档。对模型这是垃圾,因为模型本来就会跑 git。Perplexity 给出的对照写法是:
「Cherry-pick the commit onto a clean branch. Resolve conflicts preserving intent. If it can't land cleanly, explain.」
后一种写法不规定路径,只规定意图。模型在出错时会自己思考替代路径,而前一种写死的 railroad 一旦撞上 conflict 就崩了。
02 一个 Skill 是一份文件夹,不是一份文件
Skill 在 Perplexity 的标准结构是这样的:
SKILL.md 是 frontmatter + 主指令;scripts/ 放代理要跑而不是临时拼凑的代码;references/ 放重型文档,按条件加载;assets/ 放模板、schema、数据;config.json 处理首次运行的用户设置。

这套结构表面像是程序员熟悉的 hub-and-spoke 模式,但有一个工程上的硬性理由:模型在多选一时的精度,跟选项数量是负相关的。
Perplexity 那篇文章里讲了一个具体的 case,2026 年报税季他们给 Computer 加美国税法支持,第一版做法是把整个 IRS(U.S. Internal Revenue Code)的 1,945 个 section 全塞进一个文件夹给模型。结果反直觉到刺眼:
「Presenting the model a single folder containing all 1,945 sections of the U.S. Internal Revenue resulted in worse performance than not loading the Skill at all.」
单文件夹 1,945 选 1,比根本不加载这个 Skill 还糟糕。模型在巨型 flat 列表里找不到正确条目,干脆开始幻觉。Perplexity 改成三层 hierarchy 之后才把 tax 任务做稳。
这给所有写 Skill 的人一个工程教训:分层不是审美问题,而是模型选择能力的物理边界。超过 20‑30 个 sibling 的目录,模型就开始跌精度,而不是慢慢退化。
03 三层 context 税:每一个 Skill 都在向所有 session 收税
这一节是这份规范里最值钱的部分。Perplexity 把 Skill 的 context 成本拆成三层:
| 层级 |
加载内容 |
单 Skill 预算 |
何时付费 |
| Index |
每个 Skill 的 name + description |
~100 tokens |
每个 session、每个用户、永远在付 |
| Load |
完整 SKILL.md body |
~5,000 tokens |
只有当 agent 决定 load_skill() 时 |
| Runtime |
scripts/ references/ assets/ 子文件 |
unbounded |
只有当 agent 真的去读时 |
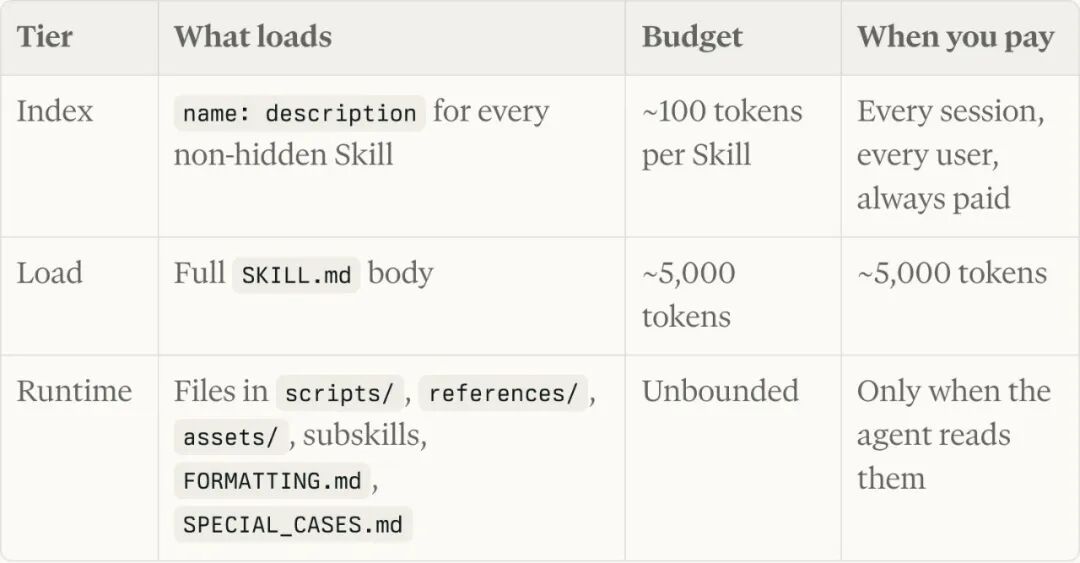
Index 层的 100 tokens 是最贵的,因为它是「常驻税」,每个 session 起手就要付。Perplexity 内部进 index 的门槛极高:你的 Skill 要么足够通用、要么足够关键,否则你这 100 token 是在给所有 session 上税。
「Every Skill is a tax」在原文里反复出现。规范甩了一句 Pascal 的法语原话作为收尾:
「Je n'ai fait celle-ci plus longue que parce que je n'ai pas eu le loisir de la faire plus courte.」
Pascal 在 1657 年的《致外省人书》里说,「这封信我写得长,是因为我没有时间把它写短」。短的 Skill 不是省力做出来的,是花更多时间打磨出来的。如果你能一小时一 PR 地批量产 Skill,那这些 Skill 大概率都是垃圾。
更狠的一句来自 Perplexity 引的一篇 2026 年初论文(arxiv 2602.12670)的实证结论:
「Self-generated Skills provide no benefit on average, showing that models cannot reliably author the procedural knowledge they benefit from consuming.」
让 LLM 自己写 Skill,平均下来没用。模型能消费 Skill 但不能可靠地生产 Skill,因为它没有「我作为这个域的专家有什么独到判断」这层东西。
04 Description 是路由器,不是文档
Perplexity 把 description 称为「the hardest line in the Skill」,整篇规范里反复强调一件事:description 不是写给同事看的功能介绍,而是写给模型的路由信号。
合格 description 的写法是「Load when...」,不是「This skill does...」。前者描述触发场景,后者描述功能本身。
举一个原文给的例子:假设你在写一个监督 PR 流程的 Skill。坏写法是描述这个 Skill 在做什么,好写法是去问工程师在受挫时会用什么词来描述需求——比如「babysit my PR」、「watch CI」、「make sure this lands」——再把这些真实意图揉进 description。
四条硬性 checklist:
描述要以「Load when...」开头;总长 50 词以内;描述用户的真实意图(最好直接来自生产 query);不要总结 workflow。
最反直觉的一条来自维护建议:「如果你 Skill 上线后还在改 description,说明你跑偏了。」description 是路由器,改 description 等于改路由表,会把其他相邻 Skill 的命中也带歪。要改,也要先写 evals、确认 spillover 风险,再小步改。
这跟工程师的本能完全相反。工程师改 README 像呼吸一样自然,但 Skill 的 description 改一个词,整个 agent system 里其他 Skill 的命中率都会随之漂移。
05 Gotchas 才是最值钱的内容,工程师却最舍不得写
最后一条反直觉,是关于 Skill body 该写什么。
工程师写 Skill 的本能是写「步骤清单」:第一步做 X,第二步做 Y。Perplexity 说这是 Skill 写作里最常见的浪费,因为这些步骤模型本来就会。真正稀缺、真正值钱的内容是「gotchas」——也就是「这里会摔跤」的负面例子。
「Gotchas ARE the special cases (they're the highest-value content).」
Skill 的维护策略是 append‑mostly:
- agent 失败一次 → 加一条 gotcha
- agent 把 Skill 加载错了 → 收紧 description + 加 negative eval
- agent 该加载没加载 → 加关键词 + 加 positive eval
- 系统 prompt 改了 → 检查跟 Skill 有没有内容冲突
Skill 不是一次性写完,而是从一个最小可用版本开始,跟着 agent 真实的失败一条一条 append。这套飞轮的核心不是「我设计得多周到」,而是「我在生产中真摔过多少次」。
文章里还有一个轻轻提到、但我觉得很重要的点:Perplexity Computer 同时支持 GPT、Claude Opus、Claude Sonnet 三个 orchestrator 家族,写 Skill 时必须跨模型跑 eval。Sonnet 和 GPT 在 Skill 路由上的行为差异显著,单模型测过不代表跨模型稳健。这个细节中文圈基本没人讨论。
写到最后
这份规范读完,最大的认知更新有三个。
Skill 不是文档,是为模型编 context。读者不是同事,而是一个会因为没读过这段文字而出错的模型。
Skill 是负债而不是资产。每写一个就是在给所有 session 上税,写之前先问一句:模型没有它会出错吗?答否就别写。
Skill 的质量跟时间投入正相关。Pascal 那句话不只是装饰,而是工程现实。一小时一个 Skill 的批量产出,平均质量低于不写。
如果你的工作里存在任何重复性流程——每周 standup 前的总结、每个 sprint 末的 retro、每次 onboard 新员工的步骤——Perplexity 这份规范的最后一段建议可以直接照搬:把这些事写成 Skill,从最小可用版开始 ship,让它在用的过程中长 gotchas。
更多前沿 Agent 与 Skill 实践,可在 云栈社区 深入探讨。
 发表于 2026-5-11 20:57:17
|
查看: 137|
回复: 0
发表于 2026-5-11 20:57:17
|
查看: 137|
回复: 0
