大模型在变得安全顺从的同时,正陷入创造力枯竭的模式坍塌。东北大学(美国)、斯坦福大学和西弗吉尼亚大学的研究团队发现,这源于人类偏好数据中存在的典型性偏见。他们提出了一种无需训练的口述采样策略,成功在推理阶段解锁了模型被压抑的多样性与潜能。

人类偏好枷锁导致大模型模式坍塌
在大语言模型的发展历程中,我们正面临一个令人困惑的悖论。随着人类反馈强化学习等对齐技术的广泛应用,模型变得越来越听话、安全和乐于助人,但同时也变得越来越“无聊”。当你要求模型讲个笑话或写个故事时,它往往会给出一种极其安全却千篇一律的回答。
这种现象在学术界被称为“模式坍塌”。它不仅限制了模型在创意写作中的表现,更严重影响了社会模拟的真实性以及合成数据生成的质量。过去,研究人员倾向于将此归咎于算法局限,认为是奖励模型不完善或优化过程过拟合所致。
然而,研究团队在最新工作中推翻了这一惯性认知。他们指出,导致模型丧失多样性的罪魁祸首并非算法本身,而是深植于人类认知中的一种基础属性:典型性偏见。

典型性偏见源于认知心理学。人类天生倾向于喜爱熟悉的、流畅的、可预测的内容。当这种心理机制被带入大模型的偏好数据标注时,灾难便发生了:人类标注者系统性地偏好那些符合大众刻板印象、平庸但挑不出错的文本。
为了量化这一影响,研究人员引入了Bradley-Terry模型来解构奖励函数,将其分解为真实任务效用和典型性偏见两部分。在创意任务中,当存在多个质量相当的潜在回答时,典型性偏见成了打破平局的决胜因素,迫使模型在训练中将概率分布极度尖锐化,集中在最符合人类刻板印象的模式上。
实证数据证实了这一假设。在HelpSteer数据集的验证中,研究人员发现人类评分与基础模型的对数似然概率之间存在显著正相关。这意味着,即便拥有完美的奖励模型和优化算法,只要使用包含这种人类偏见的数据进行对齐,模型就必然会滑向模式坍塌的深渊。
口述采样还原概率分布
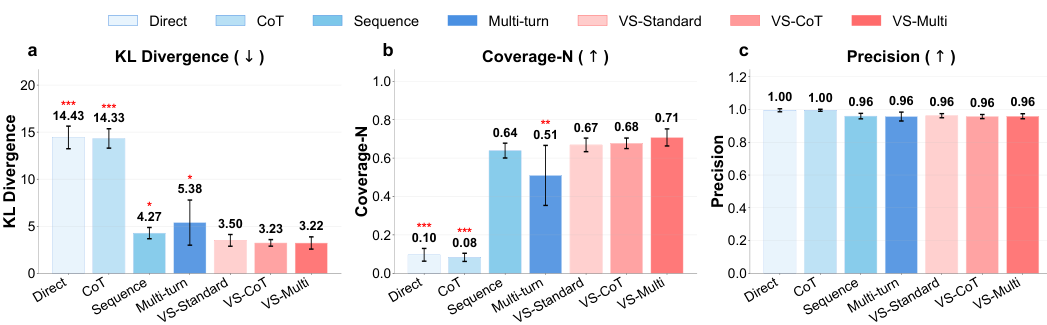
既然问题的根源在于人类偏好数据迫使模型坍缩到单个典型实例上,那么解决的关键就在于打破这种点对点的映射,回归到分布本身。研究团队提出了一种名为口述采样的策略。
这是一种无需重新训练、即插即用的推理期提示方法。其核心理念极其简洁:不要直接询问模型“这一个答案是什么”,而是要求模型“口述”出它在预训练阶段习得的概率分布。

在传统直接提示下,指令是“讲一个关于咖啡的笑话”。由于受过对齐训练,模型会倾向于输出那个它认为最安全、最符合预期的回答,结果往往是同一个老梗。
口述采样则重构了提示词,例如:“生成5个关于咖啡的笑话,并附带它们相应的概率。”这个微小的改动在模型内部引发了质变。当任务目标从寻找唯一最佳答案转变为展示可能性分布时,模型被迫调用其在预训练阶段学习到的丰富世界知识。

该方法衍生出两种高阶变体以适应不同任务:
- VS-CoT:结合思维链技术,要求模型在列出分布前先进行逐步思考,确保逻辑连贯性。
- VS-Multi:将生成任务拆解为多轮对话,每一轮生成一部分带有概率的响应,适合长文本生成。
研究证明,唯有这种分布级提示,能够引导模型逼近基础模型在预训练阶段习得的真实分布,从而恢复内容的多样性,并提供一个观察模型内部置信度的窗口。
创意写作与社会模拟中的多样性复苏
在创意写作领域,研究团队在诗歌续写、故事生成和笑话创作三个任务上对口述采样进行了全面测试,采用语义多样性作为核心度量标准。
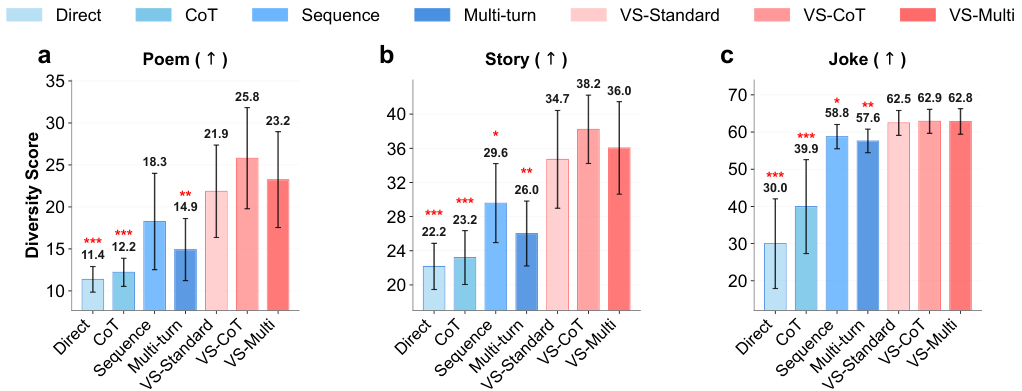
实验数据表明,口述采样在创意多样性上实现了显著提升。与直接提示相比,使用标准口述采样方法的输出多样性提高了1.6到2.1倍。更令人振奋的是,这种多样性的爆发并未牺牲质量。结合了思维链的VS-CoT方法在提升多样性的同时,还保持甚至略微提升了内容质量。
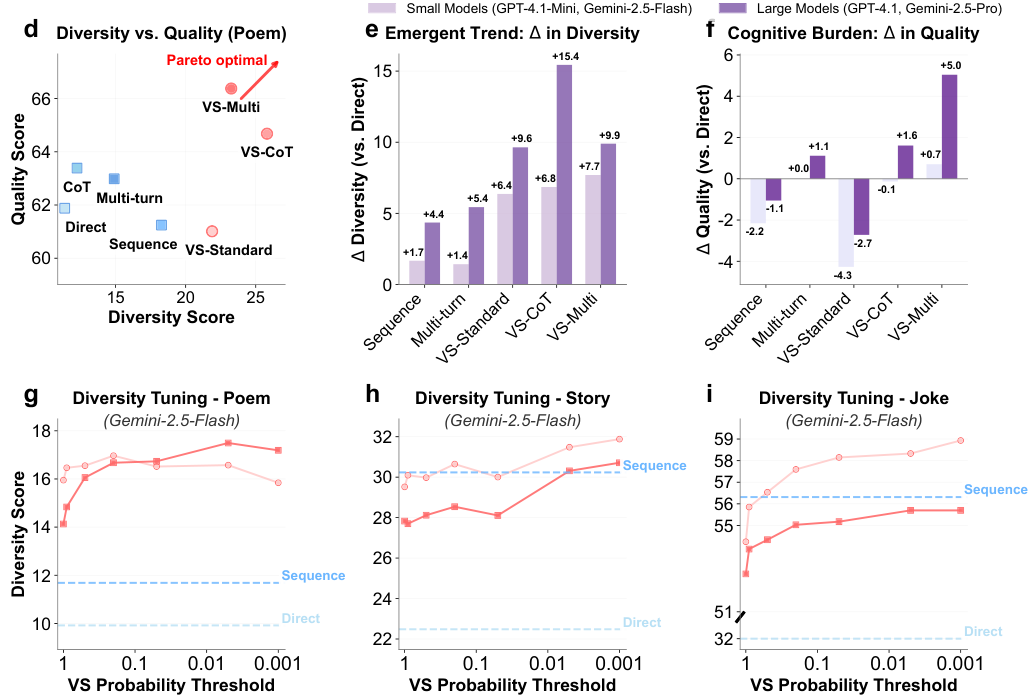
GPT-4的评估结果与人类盲测高度一致,评审员认为口述采样生成的内容在创意上显著优于传统方法。
在社会模拟任务中,经过严格对齐的模型往往表现得过于理性,无法还原人类互动中的犹豫、抗拒等行为。在“劝说捐款”的对话模拟中,传统提示下模型模拟的捐款金额分布极其单一。
应用口述采样后,情况发生逆转。模型模拟出的捐款金额分布与真实人类数据高度一致,且生成的对话内容更具真人特质,展现了抗拒、怀疑和犹豫等复杂行为模式。
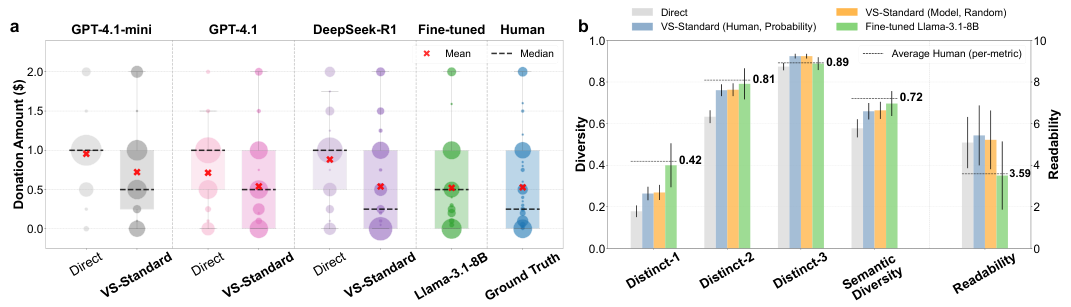
覆盖率与合成数据价值
在需要列举事实的开放式问答任务中,口述采样同样展现了强大价值。例如,要求“列举美国的一个州”,模式坍塌下的模型会反复输出高频答案。利用口述采样要求模型生成多个答案及其概率后,输出分布与预训练语料库中的真实分布惊人吻合,覆盖了更多正确答案。
口述采样还是生成高质量合成训练数据的利器。研究团队使用GPT-4.1等模型通过口述采样生成数学竞赛题目,并用这些数据微调较小的模型。
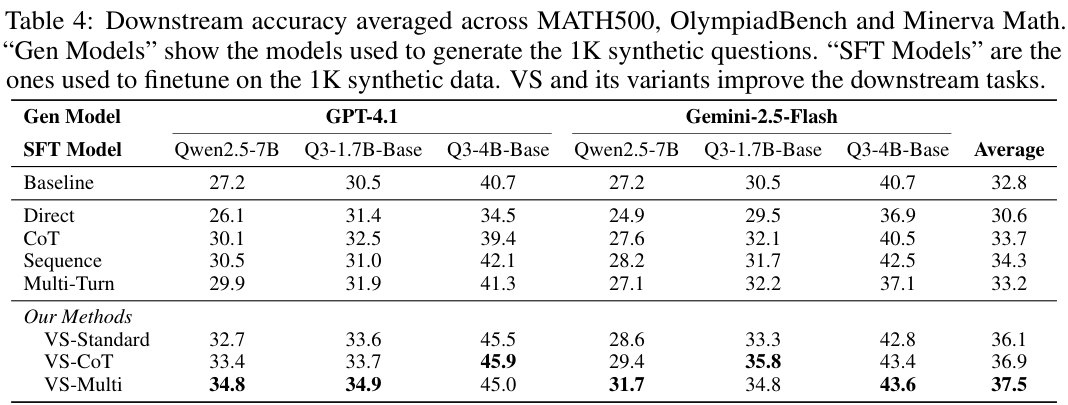
实验结果显示,使用口述采样生成数据微调的模型,在高难度数学基准测试中的平均准确率达到37.5%,显著优于使用直接提示生成数据训练的模型(30.6%)。这证明了口述采样在提升合成数据多样性及下游模型性能方面的巨大潜力。
模型规模扩展带来的涌现趋势
研究发现了一个极具深意的涌现趋势:模型能力越强,从口述采样中获得的收益越大。在创意写作任务中,GPT-4.1等大模型通过口述采样获得的多样性增益,是其轻量级模型的1.5到2倍。
这表明,更强大的模型在预训练阶段习得了更丰富的知识分布,但由于更严格的对齐训练,这些知识被封印得更深。口述采样恰好是一把与之匹配的钥匙。
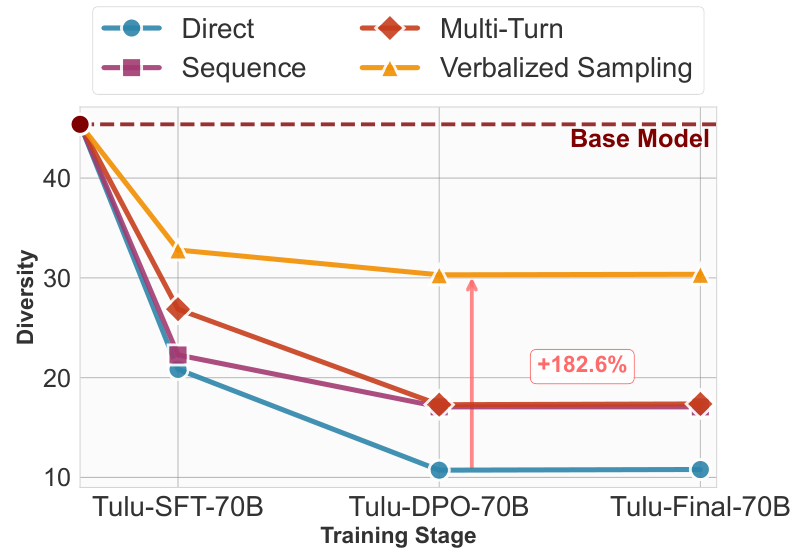
消融实验进一步证实了口述采样的鲁棒性。
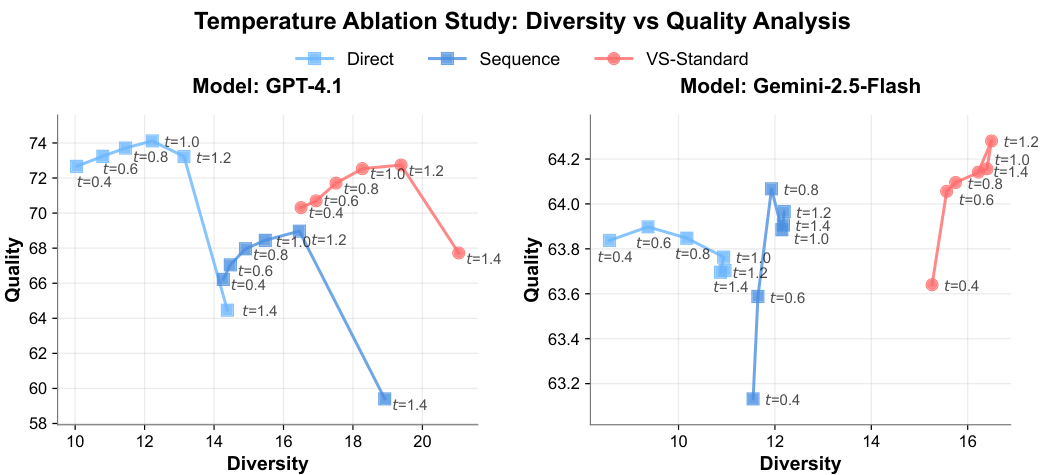
无论是在不同的温度系数下,还是在不同的后训练阶段,口述采样都能始终如一地提升多样性。特别是随着对齐阶段的深入,直接提示的多样性急剧下降,而口述采样却能维持较高水平。
这项研究没有发明复杂的新算法,而是回归数据本质。它揭示了模式坍塌是人类心理偏见在机器反馈回路中的投影,并提供了一种低成本、无训练的推理期解决方案。通过简单的提示词改变,让模型口述出其眼中的概率世界,我们得以在保持模型安全的同时,重新找回在对齐过程中丢失的广阔可能性。这为利用Python等工具进一步探索和优化大模型行为提供了新的思路。
参考资料:https://arxiv.org/abs/2510.01171
 发表于 2025-12-13 04:42:17
|
查看: 179|
回复: 0
发表于 2025-12-13 04:42:17
|
查看: 179|
回复: 0
