回顾过去一年,企业界的AI热潮可谓风起云涌。一个绕不开的核心动作就是——重金采购GPU。今天,我们不妨来做一次复盘:那些当初砸钱狂买GPU的客户,后来都怎么样了?
差不多的“砸钱”力度,结局却天差地别。
调研下来我们发现,过去一年投入大模型与算力建设的客户,根据其建设成效和业务融合深度,基本可以划分为三个鲜明的段位。

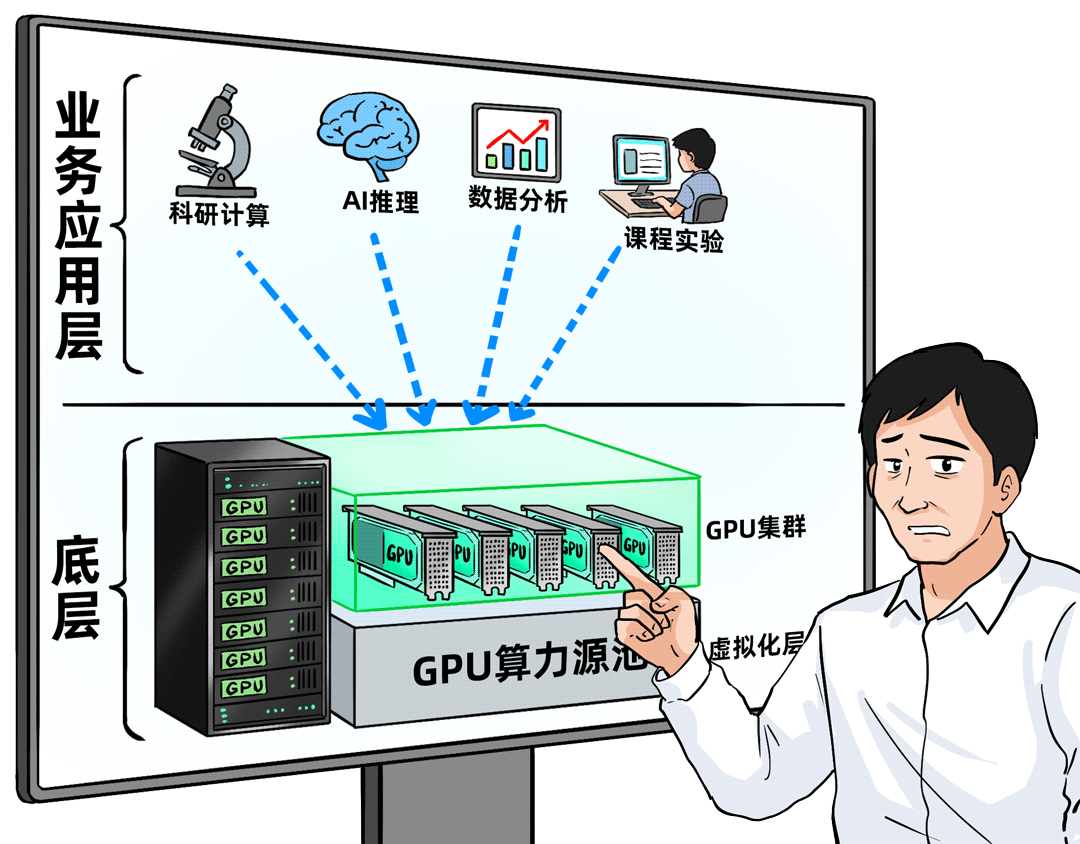
初阶段位:建成的仍是「算力中心」
以北京某高校为例,其建设思路与传统的高性能计算(HPC)集群非常相似。核心关注点在于GPU资源本身:建了多大的资源池,总算力达到多少FLOPS,精度如何。算力池建成后,便开放给各个院系使用。

资源主要用于原有的科研计算与教学任务,部分师生也会进行一些基础的模型推理。但这种模式下,资源利用率往往不均衡,申请流程复杂,用户还普遍反映使用成本偏高。
中阶段位:升级为「服务中心」
某三甲医院是这一阶段的代表。他们已经开始关注大模型服务本身,能够直接对外提供统一的模型API,临床和科研科室可以直接调用。

然而,在多部门协作、模型生命周期管理以及行业智能体的开发上,他们仍在摸索。业务部门反馈,AI对核心业务流程的赋能感仍不明显,投入产出比有待提升。
高阶段位:终成「能力中心」
某大型装备制造企业走在了前面。他们的核心已经超越了单纯的算力和模型,转向了构建智能体开发工具链与业务深度融合的生态。
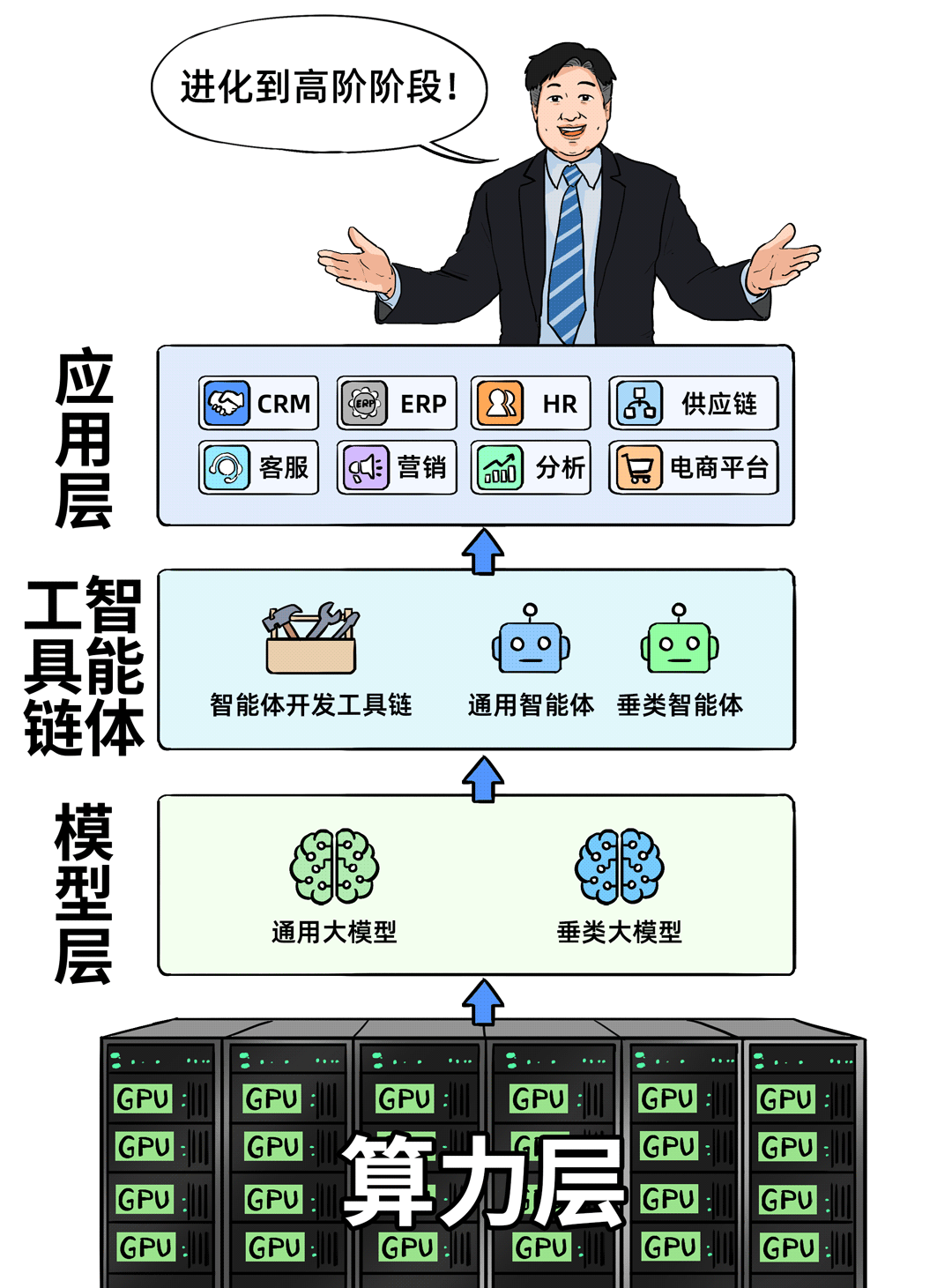
按照他们的说法,底层AI基础设施已经非常成熟稳定,现在的重点在Agent Infra层面。令人惊喜的是,其业务部门基于平台工具,自主开发的一些专用智能体和AI应用已经真正跑在了业务线上。
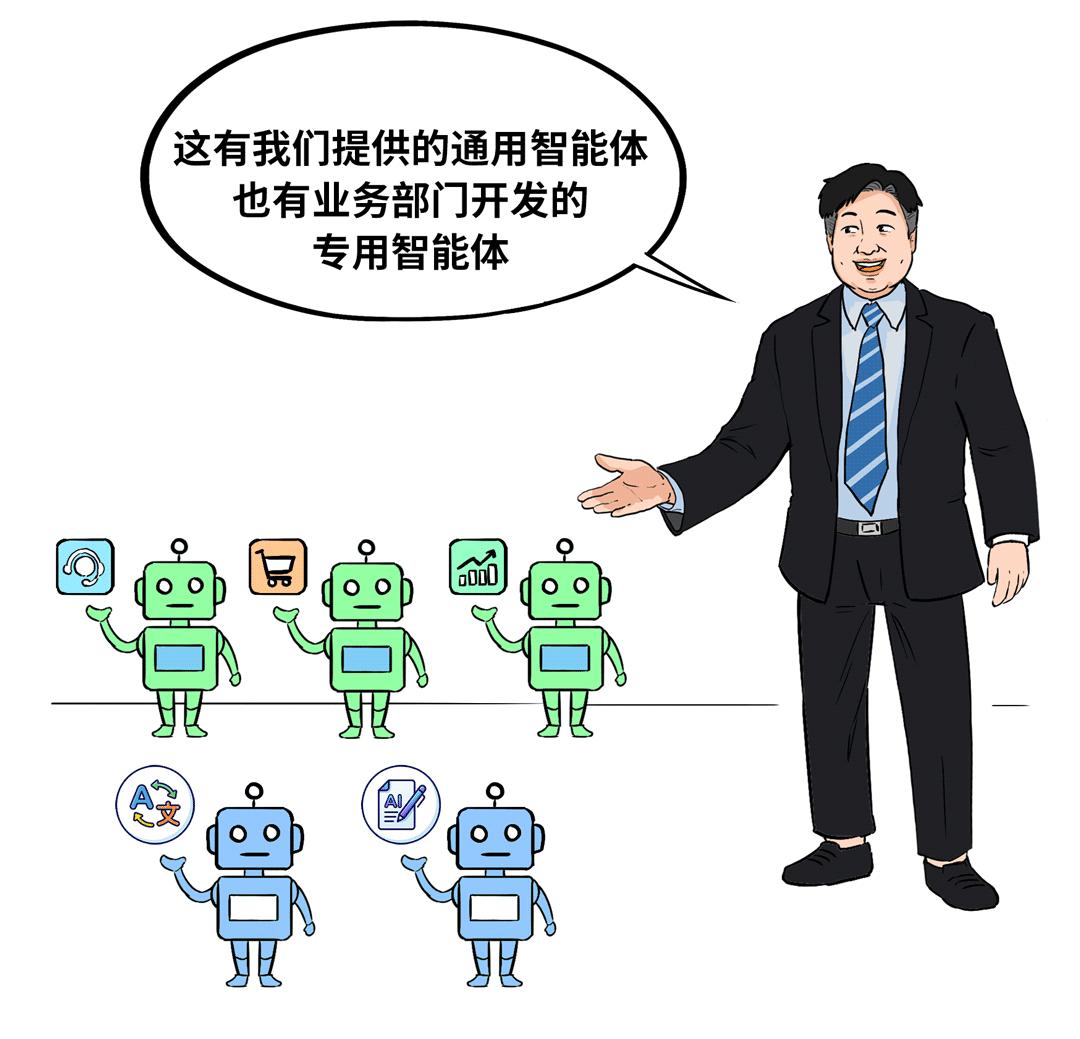
你看,同样是巨额投入,结果却大相径庭。做得好的,算力池化、模型即服务(MaaS)、应用赋能,整合顺滑,业务与运维部门双双点赞。
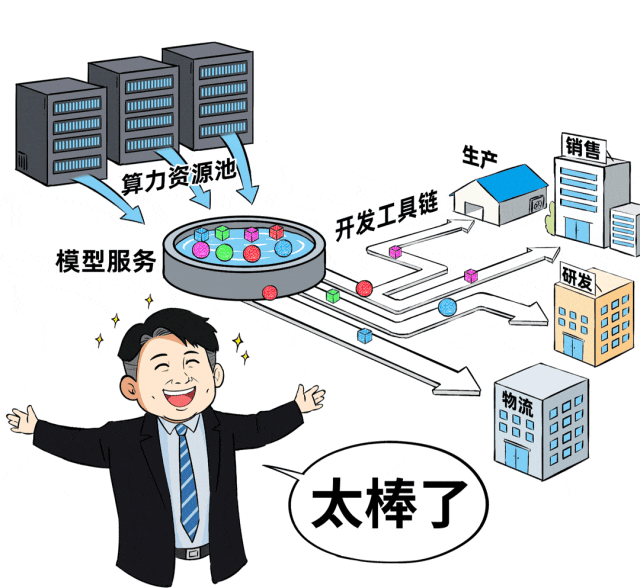
做得差的,即便身处大模型时代,却依然陷入“烟囱式”建设的旧坑。AI资源割裂,算力浪费严重,模型性能不达预期,业务价值难以体现。

差距背后:AI建设的四大共性挑战
那么,造成这种巨大差距的根源究竟是什么?我们认为,关键在于是否成功跨越了AI建设的四大典型挑战。
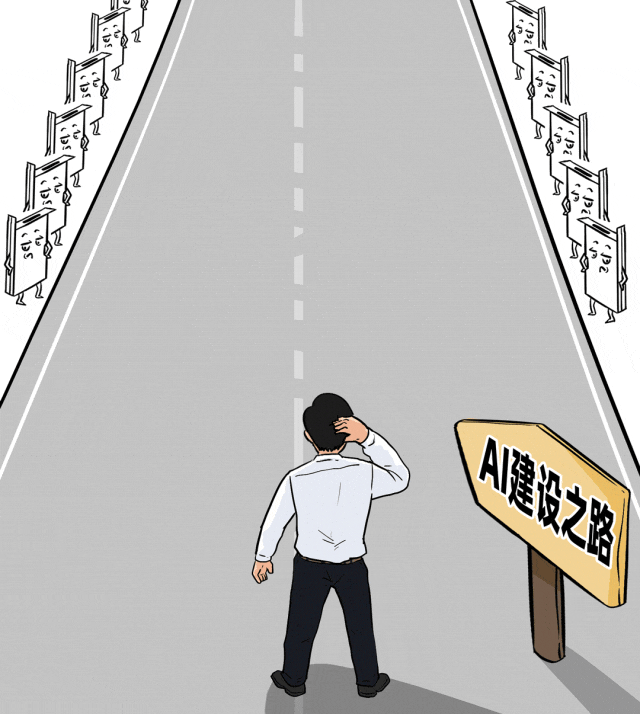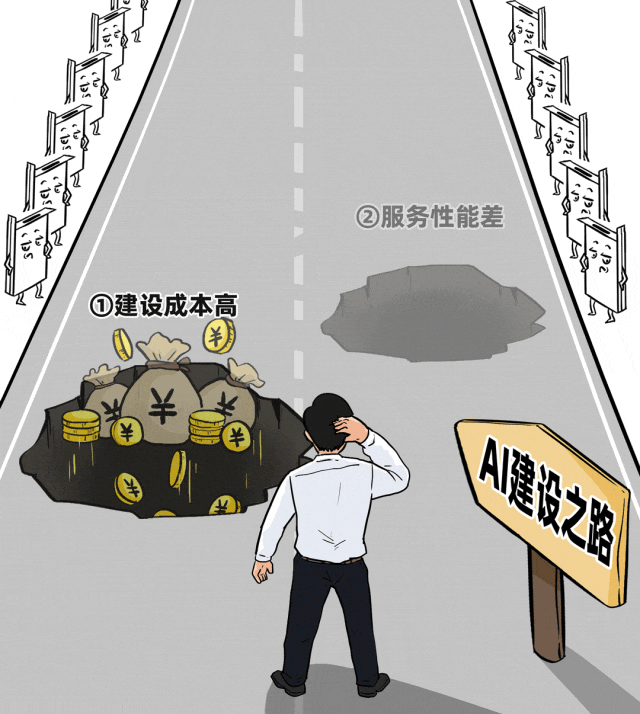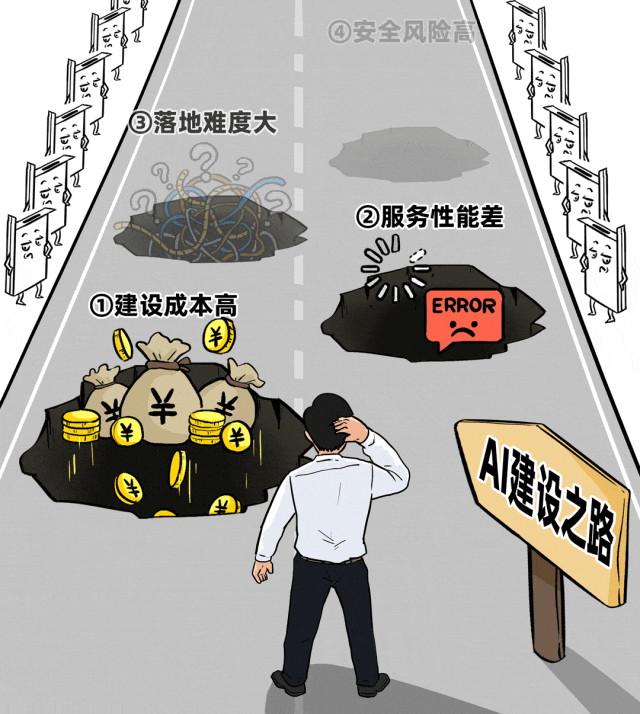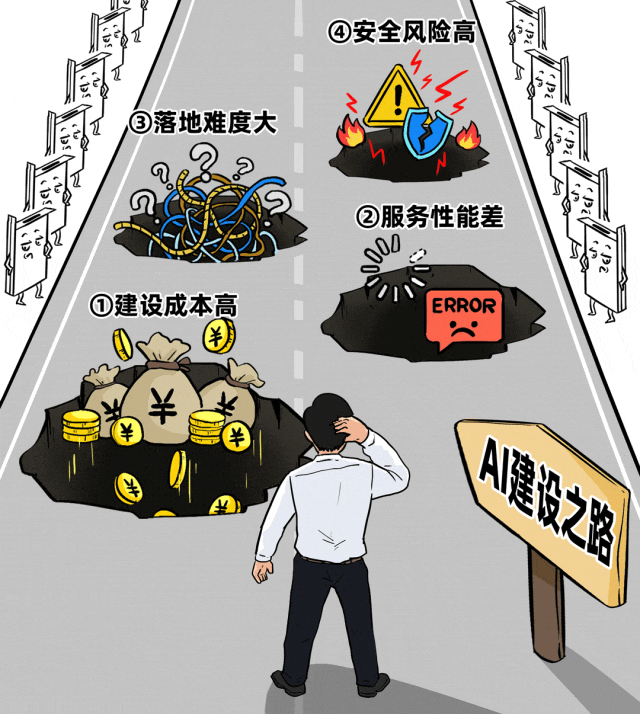
- 建设成本高:硬件投资巨大,但不同项目、部门间的GPU资源无法灵活共享,整体利用率极低,可谓“花大钱办小事”。

- 服务性能差:面对高并发业务场景时,响应延迟高、吞吐量低,导致业务卡顿,用户体验差,难以支撑规模化应用。

- 落地难度大:从模型管理、评估、部署到行业智能体的开发、上线,链条长且复杂,业务部门望而却步,转型速度缓慢。
- 安全风险高:数据在推理过程中可能泄露,面临提示词攻击等新型安全威胁,模型自身也存在稳定性风险。

如何填平这些深坑?核心在于需要一个能够打通算力、模型、数据、业务,并提供统一管理运维能力的AI基础设施平台。它就像一位经验丰富的向导,能带你避开陷阱,快速抵达目的地。
破局关键:从更多GPU到一套“AIOS”
更准确地说,这个理想的AI基础设施平台,应该成为大模型时代的底层操作系统(AIOS)。回想一下,传统IT时代我们有Windows/Linux等通用OS,云计算时代诞生了云OS(如OpenStack、Kubernetes),那么AI大模型时代,自然也呼唤专属的AIOS。
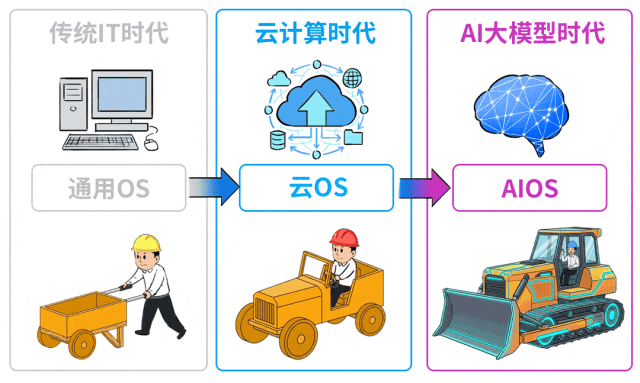
这些操作系统就像是全副武装的“工程装备”,帮助企业在不同技术时代“踏平坎坷成大道”,保障业务列车平稳高速前行。
那么,一个能胜任的AIOS究竟该具备哪些特质?结合众多一线客户的反馈,我们梳理出了几个关键特征。
共识一:AIOS必须构筑在云化基础之上
几乎所有资深的IT负责人都会强调这一点。没有基础设施云化这一步,后续的AI建设就会沦为一座座新的“AI烟囱”,资源割裂、利用率低下将是必然结局。

大家注意到没有?连一直以降本增效著称的云计算巨头AWS,其部分AI/ML专用实例(Capacity Blocks)也传出价格上调的消息。这从侧面印证了,在AI浪潮下,稳定、高效的云化算力需求正在激增,并且价值凸显。

因此,AI建设的第一步(尤其是对数据合规与隐私要求极高的政企客户),是构建一个可平滑演进、自主可控的云底座。完成“云化”筑基之后,才能顺畅地为其添加“AI”的智能料。

核心能力一:一云多芯,灵活兼容异构算力
这是很多大型企业面临的现实困境:芯片采购受到供应链限制,部分存量GPU需要利旧,新购的多种品牌AI加速卡又需要适配。这种异构环境不仅推高了建设成本,更严重拖慢了落地速度。
理想的AIOS应能“开箱即用”,预置对主流AI加速卡(如NVIDIA、海光、沐曦、昇腾、昆仑芯等)的广泛支持能力,快速将新旧、异构的算力资源统一纳管,池化共享。这不仅能极大节约成本和加速上线,更从根本上解决了生态绑定的风险。

核心能力二:追求极致的性能与成本平衡
有客户向我们吐槽:他们内部也对各部门按照Token用量计费,但由于自家平台推理成本过高、速度慢,导致业务部门宁愿去调用昂贵的外部API,也不愿使用内部服务。

AI推理服务是常态化的长期运营,必须兼顾极致性能与严苛成本。这就要求AIOS有能力“榨干”每一颗GPU的潜力:
- 通过算力共享、协同调度、分层量化等技术,极致压缩单次推理的成本。

- 需具备深度优化的自研推理框架。仅靠开源框架往往不够,需要结合KVCache优化、连续批处理(Continuous Batching)、弹性调度等手段,将TPOT(每次输出时间)、TTFT(首Token时间)、并发和吞吐等关键指标全面提升。
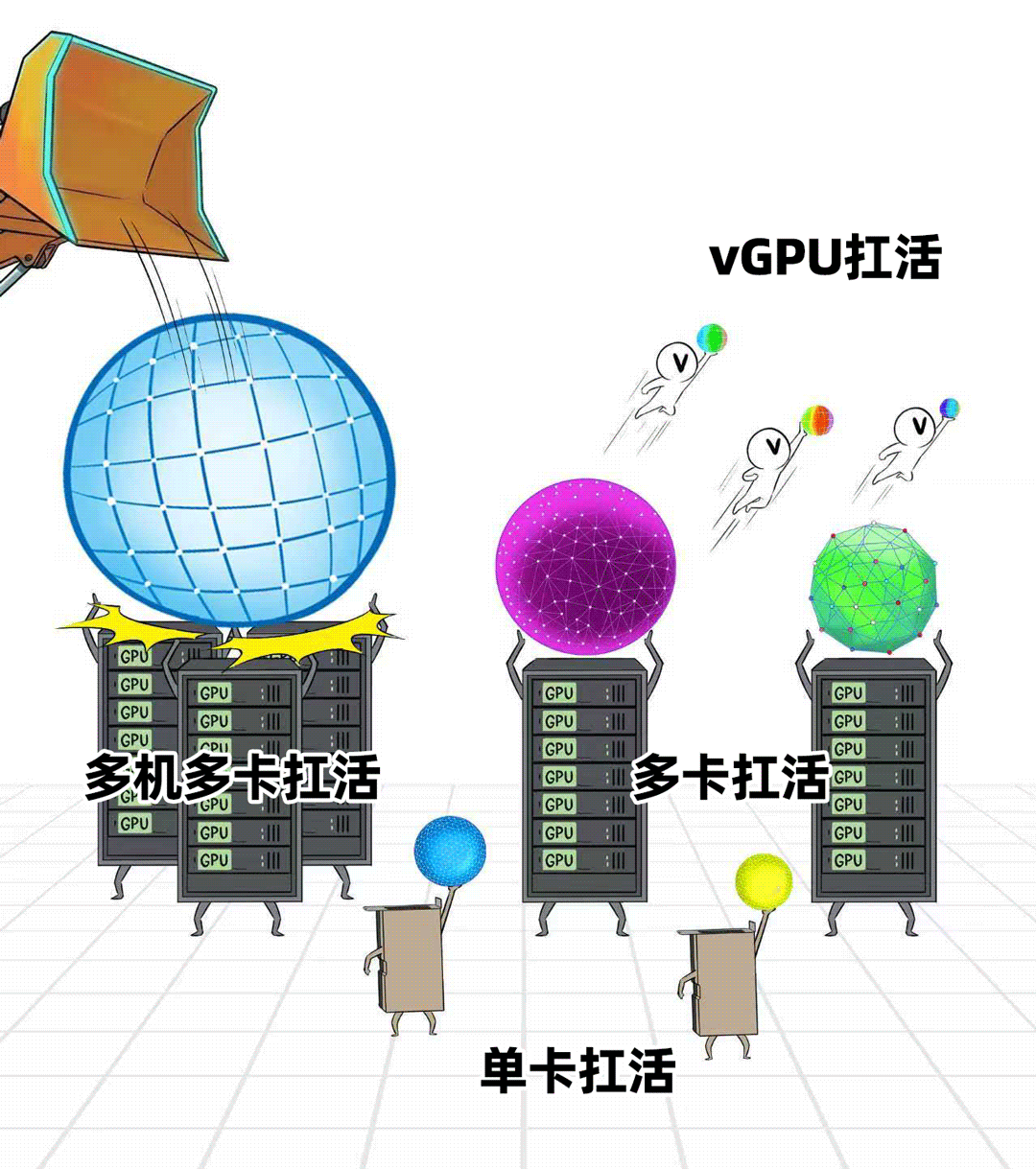
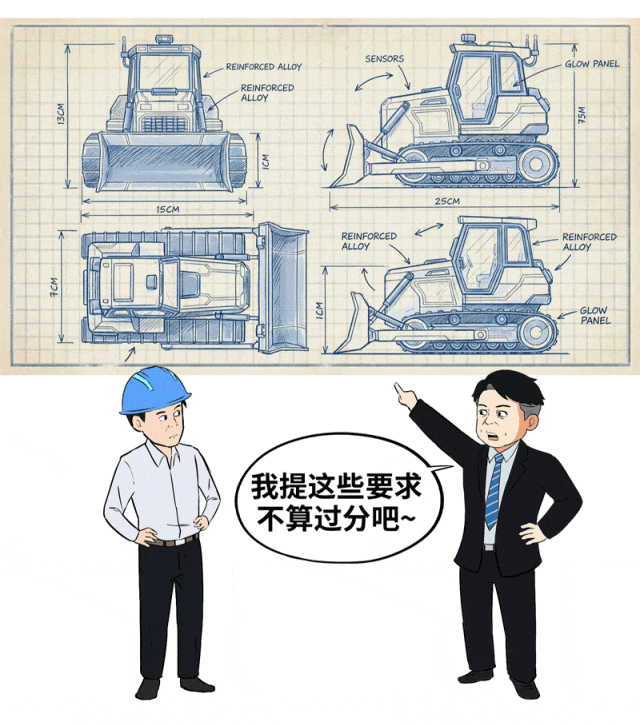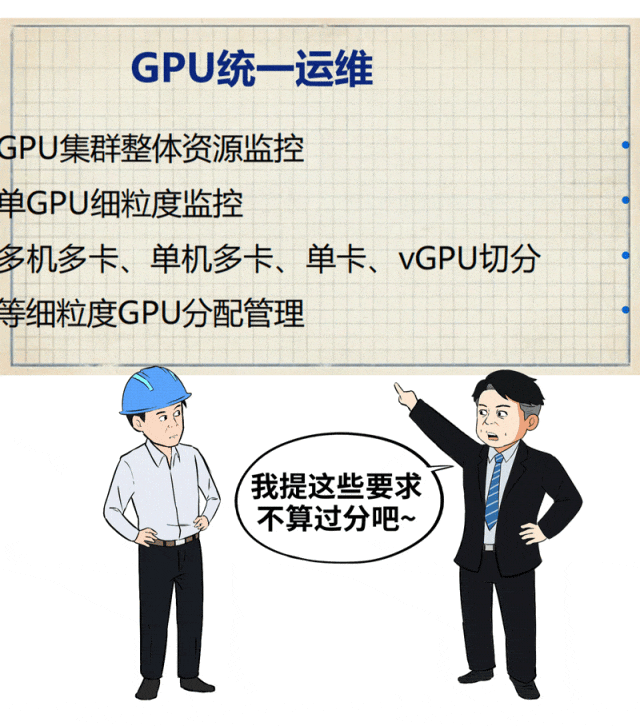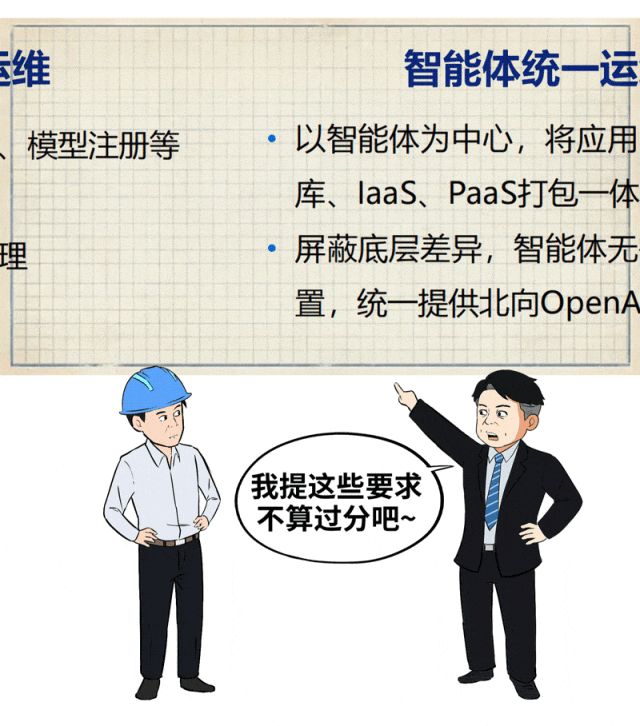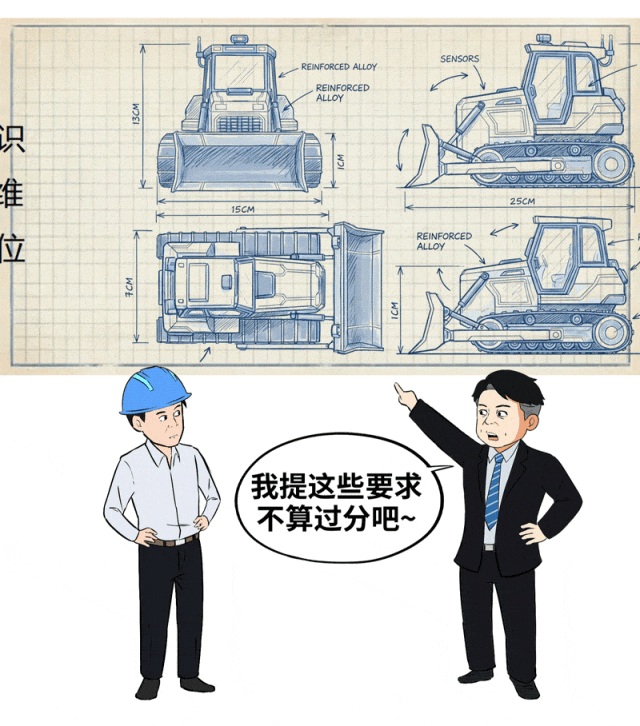
- 支持灵活的算力调度粒度。不仅要服务大模型,也要兼顾中小模型和传统AI任务。AIOS应能实现从多机多卡、单机多卡、单卡到vGPU的细粒度切分与调度,最大化GPU利用率。
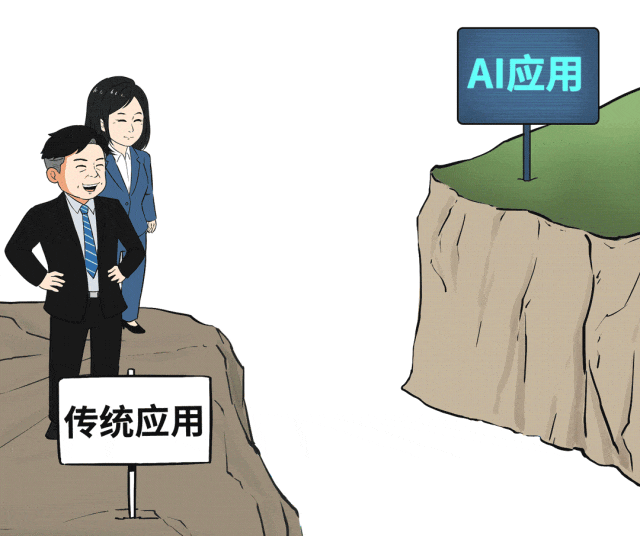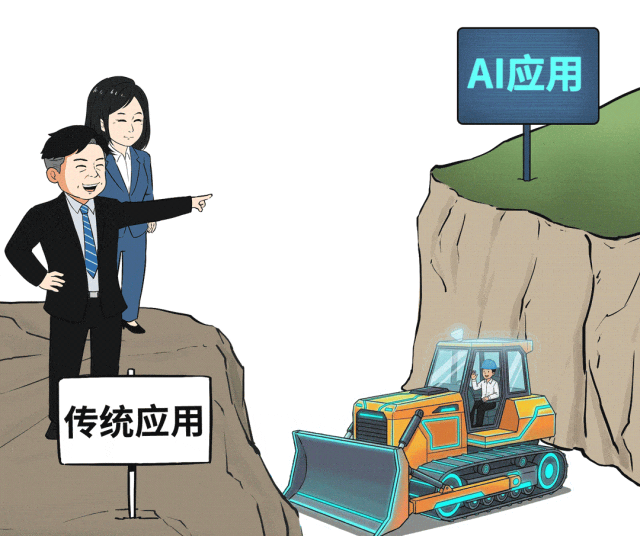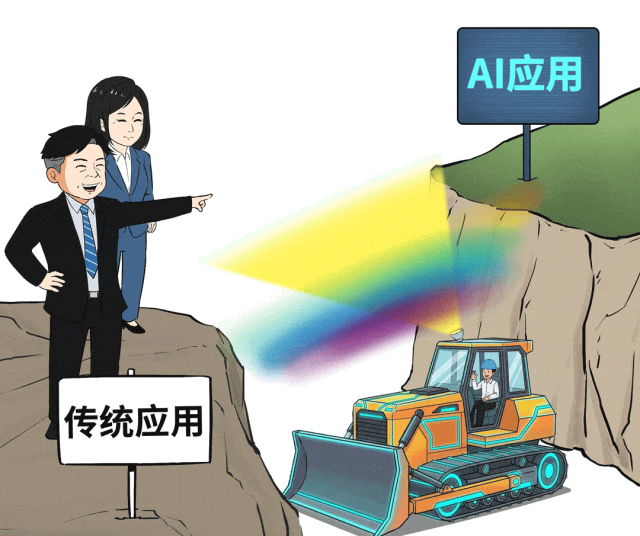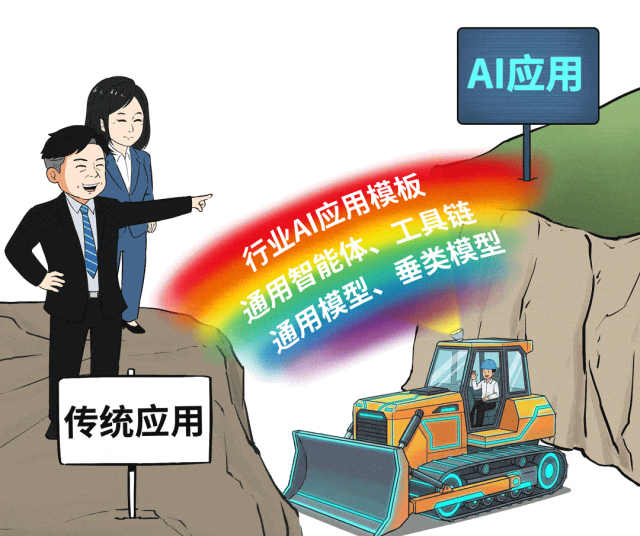
核心能力三:降低开发门槛,简化运维复杂度
业务部门的痛点不止于模型性价比,他们更关心:如何快速将AI能力与我的业务结合?开发一个行业智能体为什么这么难?

因此,AIOS必须为智能体与应用开发“铺平道路”,提供开箱即用的体验。这包括集成完整的智能体开发工具链、丰富的通用智能体库,甚至预制面向金融、医疗、制造等场景的行业AI应用模板,从而将应用上线周期从数月缩短到数周。
同时,作为平台的建设与维护者,运维团队也亟需减负。AIOS需要提供对GPU、模型、智能体的统一运维视角,将复杂的AI资源监控、管理、发布、版本控制等操作标准化、简化,让传统IT运维人员也能快速上手。
核心能力四:构筑坚固的安全与合规防线
在调研中,所有客户无一例外地对大模型服务的安全与合规问题表示高度关切。不出彩或许可以接受,但一旦出现安全事件,责任无人愿意承担。

AIOS必须内建安全能力,守好最后一道关。这包括合规性监测、提示词攻击拦截、上下文数据脱敏、敏感问题拒答(红线代答)等。通过增强型的AI安全网关结合私域知识库的隔离访问,可以大幅降低数据泄露风险,保障服务稳定可靠。

理想照进现实:浪潮云海InCloud AIOS
综上所述,一个理想的、能帮助企业跨越挑战、直通“能力中心”的AIOS面貌已经清晰。那么,市场上有这样的产品吗?答案是肯定的,例如浪潮云海推出的InCloud AIOS——一个专为大模型与智能体场景设计的融合型AI云基础设施平台。

之前客户调研中提出的所有期待:极致成本、极致性能、极致体验、极致可靠…浪潮云海InCloud AIOS给出了清晰的量化回应。

并且,它做得更为深入:
- 算力层面:广泛兼容8款主流CPU和6款主流GPU,解决异构融合难题。
- 模型层面:提供自研的高性能推理框架InLLM,适配全系列主流开源与行业模型。
- 应用层面:内置50+开箱即用的智能体模板和完整开发工具链,大幅降低AI应用开发门槛。

InCloud AIOS支持纯软件与一体机两种交付模式,无论是从零起步、利旧现有资产,还是建设全新智算中心,都能帮助企业快速构建AI能力,极速入场抢占先机。

实践验证:GPU价值得以真正释放
在过去一年的实践中,浪潮云海InCloud AIOS已经助力众多政企客户成功跨越了“只有算力”的初级阶段,让昂贵的GPU投资转化为了实实在在的业务价值。

- 某省级政务云:利用AIOS成功盘活存量的NVIDIA、海光、昇腾等多种算力,统一池化后稳定运行19个大模型,支撑起超过200个智能体应用,为“一网通办”等场景注入智能。
- 某大型装备制造集团:基于平台接入行业知识库与200余条法务经验规则,打造智能合同审核系统,将合同审核周期缩短80%以上,关键风险条款识别准确率超过95%。
可以这样比喻:GPU是动力澎湃的引擎,而AIOS则是高效的传动系统与智能驾驶舱。没有后者,引擎可能空转或闲置;只有配上AIOS,强大的算力才能被精准、高效、安全地输送到每一个业务环节,驱动企业驶入智能化发展的快车道。对于正在或计划进行数字化转型的企业而言,选对平台,往往比单纯堆砌硬件更为重要。如果你对AI基础设施的构建有更多想法或疑问,欢迎来云栈社区与同行们交流探讨。

 发表于 2026-2-1 01:39:11
|
查看: 233|
回复: 0
发表于 2026-2-1 01:39:11
|
查看: 233|
回复: 0
