推测解码(Speculative Decoding, SD)通过利用大语言模型推理过程中因内存与芯片间数据传输而闲置的计算资源来加速生成,但在主流采用连续批处理(continuous batching)的系统中,其效率受到显著限制。批处理已大幅压缩空闲算力,使得传统依赖大规模草稿树的SD方法难以充分发挥优势。现有草稿模型普遍存在位置依赖参数过多的问题,导致在有限草稿预算下生成质量低、扩展性差,且难以适应大批量场景。
为此,小米联合武汉大学提出SpecFormer,放弃传统自回归草稿模型,转而设计一种基于双向注意力、参数位置无关、专为短序列草稿生成优化的新架构,从而实现更高效、更准确的推测解码。该设计摒弃了对大型前缀树的依赖,即使在大批量场景下也能实现稳定的加速。通过对多种规模模型进行无损推测解码实验,证明SpecFormer以更低的训练需求和更少的计算开销,为大语言模型推理的可扩展性树立了新标准。

方法
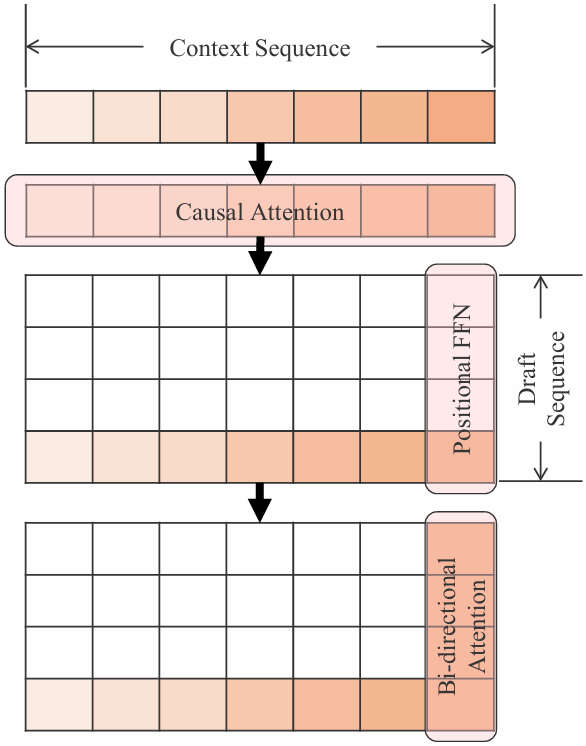
SpecFormer推测解码方法如图2所示,结合了上下文和草稿序列内部两个维度上的单向和双向注意力,如图3所示。
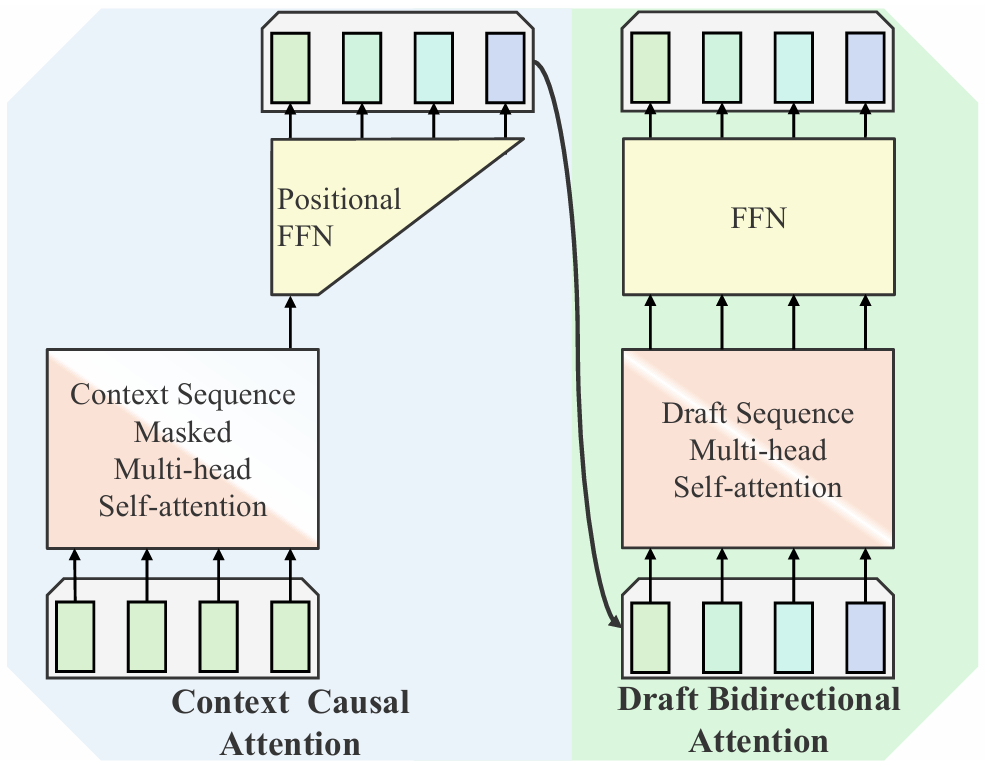
(1)上下文因果注意力(Masked Self-Attention, MSA)
首先,通过Hook融合LLM多层隐藏状态,并将它们拼接成一个张量。接着,在最后一个维度上应用分组RMS归一化,归一化后的张量被重塑后作为下采样器的输入。
下采样器是一个无偏置的线性层,将维度投影回隐藏维度,输出增强表示输入MSA模块。
MSA可视为原LLM的第L+1层,其设计便于与现有的KV缓存管理框架无缝集成。形式化表达如下:
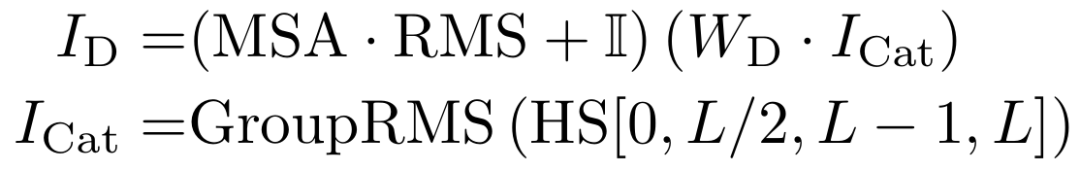
最后,位置前馈网络(Positional FFN)通过一个线性投影,为草稿序列的每个位置生成专属表示。设计在表达能力和效率之间取得平衡:既避免了过于简单的掩码式位置编码,又比为每个位置使用完整MLP更节省参数。最终输出张量计算方式如下:
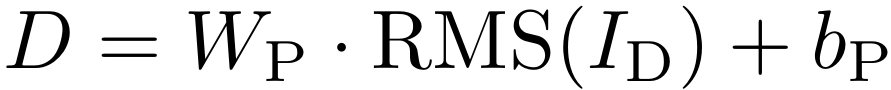
(2)草稿双向注意力(Draft Bi-directional Attention)
草稿双向注意力是SpecFormer中用于并行生成草稿token的核心模块。
通过对其内部应用标准的自注意力(带残差连接)和SwiGLU前馈网络,所有组件均使用RMS归一化,输出张量。该注意力沿草稿token维度计算,因此有效批大小为草稿长度。
为了让推测解码在真实硬件和大规模部署场景下更高效、更稳定、更易训练,分别针对推理效率、模型对齐性和训练显存开销设计了优化策略:
- 高效的分组RMS归一化:在SpecFormer的实现中,分组RMS归一化若采用常规的Python循环或低效CUDA实现,会因频繁的CPU-GPU协同开销成为性能瓶颈。为此,研究者使用Triton编写了定制化的GPU kernel,将整个归一化操作完全并行化地运行在GPU上,显著提升了计算吞吐并降低了延迟,尤其在大批量推理或处理长上下文时效果突出。
- 自蒸馏训练策略:为确保草稿模型的预测分布与主语言模型高度对齐,避免因使用外部数据导致接受率下降,SpecFormer采用自蒸馏训练策略:仅保留原始样本中的问题部分,并用主模型自身生成对应的回答作为训练目标。
- 批内梯度累积:由于现代大语言模型词表规模庞大,若同时对所有草稿位置计算softmax和损失,会产生巨大的logits张量,极易超出GPU显存限制。SpecFormer通过批内梯度累积策略,逐个位置计算损失与梯度,在释放logits后将梯度暂存回隐藏状态,待所有位置处理完毕后再统一执行后续反向传播,从而大幅降低峰值显存占用,支持更长草稿序列的训练。
评估
κ是一个优化系数,用于衡量草稿模型在计算资源受限条件下,以最小开销实现最大加速效果的能力。
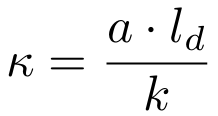
其中,a是每步被主模型接受的草稿token数量,ld是草稿模型设计的最大生成长度,k是实际消耗的草稿token预算。在一些其他研究中k通常被忽略或固定为一个相对较大的常数,但研究者将k作为分母,强调在真实部署(尤其是大批量场景)中,可用的草稿预算k是有限的。
表1:在不同批大小和设置下,SpecFormer与基线方法的对比
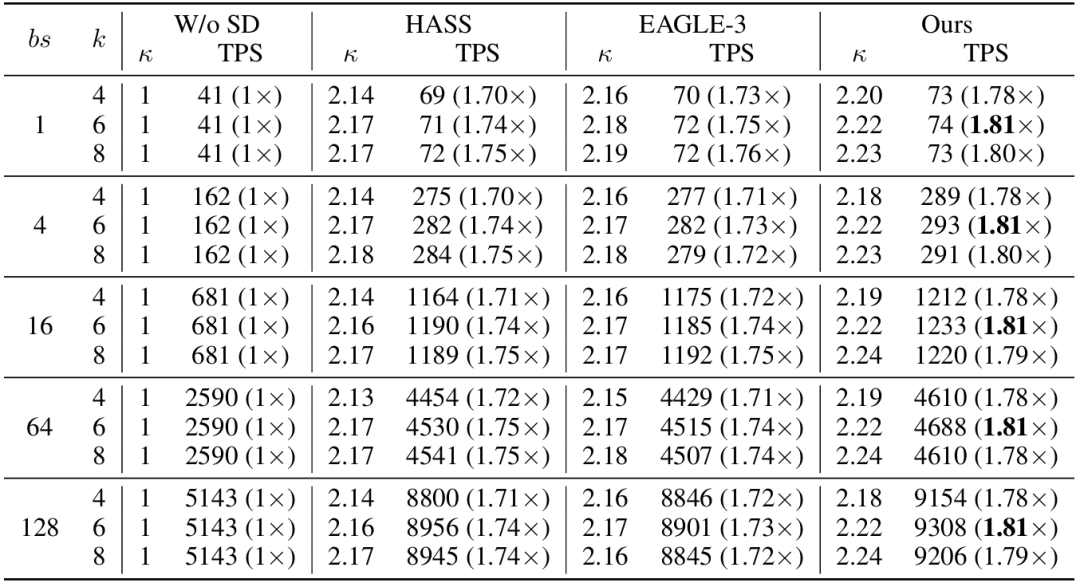
如表1所示,SpecFormer在严格限制草稿预算的条件下,凭借更强的预测能力和更高效的双向注意力架构,实现了比现有方法更高的实际吞吐(TPS),并且能更有效地将理论效率(κ)转化为系统性能。
表2:是否使用自蒸馏结果对比

如表2所示,自蒸馏虽减小了训练数据量,却因确保草稿模型与主模型输出对齐,成为实现有效推测解码加速的关键前提。
表3:SpecFormer与基线方法在不同LLMs规模下的比较
为探究SpecFormer在不同模型规模下通过推测解码所能获得的性能提升,在Qwen-3系列上进行了实验,包括4B、8B和14B三种参数量的模型——覆盖了当前常用模型规模的典型范围。κ-to-TPS转换比率θ用于衡量草稿模块本身对整体效率的影响。
实验结果表明:随着模型规模增大,草稿模型准确预测未来token的能力有所下降,导致加速收益减少。例如,4B模型实现了1.56×的加速比,而14B模型的加速比则降至1.47×。此外,更大的模型具有更低的θ值,即草稿模块引入的相对开销更小。这主要归因于两点:更大模型层数更多,使得草稿模块所占参数比例更小;大模型中更大的权重矩阵“稀释”了调度和执行草稿模块所带来的额外开销。
总体而言,SpecFormer在各种模型规模下均适用,但在较小模型上展现出尤为显著的加速优势。
表4:消融实验结果

研究者分别对每个模块进行独立修改并开展相应实验,结果如表4所示。
双向注意力确实提升了模型性能,但提升幅度不大。然而,考虑到它对推理时间的影响几乎可以忽略不计,仍选择保留该结构。
Positional FFN带来了显著的性能提升,因为它占据了草稿模块中较大参数量。
扩大草稿模型规模带来了明显的性能增益。这表明,通过扩展草稿模型的规模,可以抵消因基础LLM总参数量更大而导致的草稿模块参数占比下降所带来的负面影响。
 发表于 2025-12-13 05:06:57
|
查看: 211|
回复: 0
发表于 2025-12-13 05:06:57
|
查看: 211|
回复: 0
